Abstract
文章从有效度量空间理论和实验对比两个角度分析了类别属性的实体嵌入的优势,类别属性的实体嵌入不仅可以减少存储、加速神经网络,更重要是将相似值映射到嵌入空间的相似位置,反映出类别属性的内在特性(intrinsic property)。文章基于rossmann-store-sales比赛数据展开实验比对,进一步证明了在数据稀疏和统计量未知的情况下,实体嵌入可以帮助神经网络更好地泛化。因此,它对于具有大量高基数特性的数据集特别有用。
Introduction
作者指出,神经网络在处理结构化数据(结构化数据这里我理解为类别属性)方面效果不佳,不如基于树的方法。原则上,神经网络可以逼近任何连续函数和分段连续函数。但是,它不适用于逼近任意不连续函数,因为它在其一般形式中假定了某种程度的连续性。在训练阶段,数据的连续性保证了优化的收敛性,而在预测阶段,数据的连续性保证了输入值的微小变化,保证了输出的稳定。另一方面,决策树不假设任何特征的连续性。
然而,具有分类特征的结构化数据可能根本没有连续性,即使有,也可能不那么明显。神经网络的连续性限制了它们对分类变量的适用性。因此,简单地将神经网络应用于使用整数表示分类变量的结构化数据并不能很好地工作。解决这个问题的一种常见方法是使用 one-hot 编码,但它有两个缺点:首先,当我们有许多高基数特征时,one-hot 编码通常会导致不切实际的计算资源需求。其次,它完全独立地对待分类变量的不同值,经常忽略它们之间的信息关系。
在本文中,我们展示了如何使用实体嵌入方法来自动学习多维空间中类别特征的表示,使函数逼近问题中具有相似效果(相似的y输出)的值彼此接近,从而揭示数据的内在连续性,并帮助神经网络和其他常见的机器学习算法解决问题。
Method
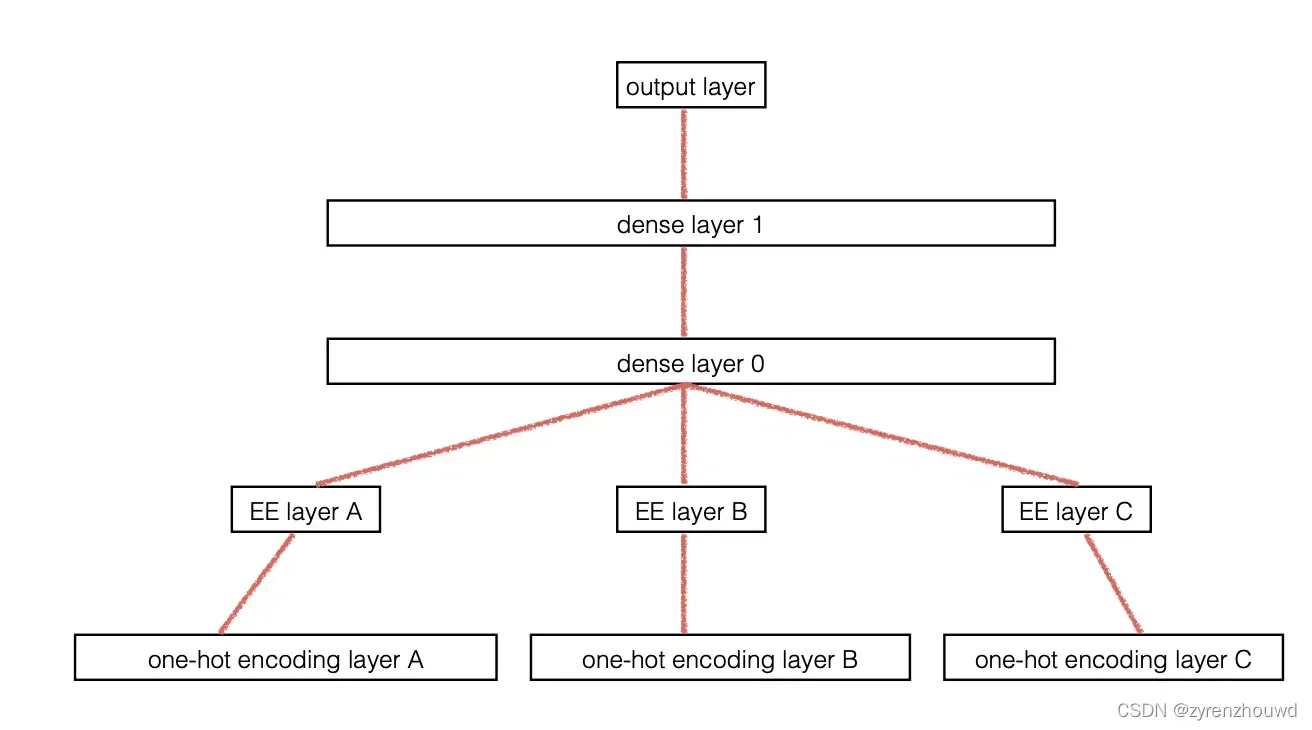
模型结构图如下,实体嵌入层相当于在每一维属性one-hot编码之上加的额外一层,模型有以下两个特征:
1、对每一个类别特征构建一个embedding层。对embedding层进行拼接。
2、有监督学习,根据标签训练embedding层的类别嵌入值,这样的embedding的输出更精确。
Experiments
1,通过模型的预测性能分析类别属性实体嵌入的优势
文章做了两组实验,实验数据来自于2013-2015年德国各州商店的销量,实验一:先混淆数据集,然后分割90%训练,10%测试,打乱的样本的时序信息,实验结果如下图table3;实验二:然后分割90%训练,10%测试,保持样本的时序信息,实验结果如下图table4;商店的销量模型随时间会有一定漂移,实验二能一定程度上检测模型的泛化能力。![[文献笔记]Entity Embeddings of Categorical Variables](https://aitechtogether.com/wp-content/uploads/2022/03/977f5e204e2a4e3ab4f84e69931ecc0f.webp)
2,嵌入空间的物理含义分析
将state的嵌入向量通过PCA降维,使用TSNE可视化如下图,图中state的相对位置关系反应出现实空间中state的关系,可以看出针对state的嵌入反应了其内在属性。其他维(e.g., day of week,month,store_index)的物理含义不明显。关于为何其他维物理含义不明显,是否可以认为其他维对sale的影响不那么大?state属于决定性特征?后期可以通过类似决策树的选择决定性特征的手段进一步分析。
tsne = manifold.TSNE(init='pca', random_state=0, method='exact', perplexity=5, learning_rate=100)
Y = tsne.fit_transform(german_states_embedding)
plt.scatter(-Y[:, 0], -Y[:, 1])
![[文献笔记]Entity Embeddings of Categorical Variables](https://aitechtogether.com/wp-content/uploads/2022/03/2fbfe3a5597c4233a1c12bc13bde642a.webp)
3,有监督训练中标签的指导性分析(sales对嵌入向量的影响)
分析(a,b)两个商店只有store_index不同的情况下(同一地点state、同一时间下不同商店的销量),销量sale的差距。下图给出随机10000对商店销量距离与相应嵌入空间距离的对应图。横轴表示销量距离,纵轴表示store_index嵌入向量的距离。
#商店销量的距离
def distance(store_pairs, dictlist):
'''Distance as defined in the paper'''
absdiffs = []
a, b = store_pairs
for key in dictlist[a]:
if key in dictlist[b]:
absdiffs.append(abs(dictlist[a][key] - dictlist[b][key])) #销量的绝对值差距
return sum(absdiffs) / float(len(absdiffs))
#store_index嵌入向量的距离
def embed_distance(store_pairs, em):
'''Distance in the embedding space'''
a, b = store_pairs
a_vec = em[a]
b_vec = em[b]
return(numpy.linalg.norm(a_vec - b_vec)) #向量差的二范数
![[文献笔记]Entity Embeddings of Categorical Variables](https://aitechtogether.com/wp-content/uploads/2022/03/3f47f75659224933b3ec147e2f1f2f33.webp)
4,嵌入矩阵正态性分析
以store_index的嵌入矩阵为例展开分析,store_index的嵌入矩阵大小为(1115,10),该嵌入空间的10维是实验参试出来的,没有明确含义,将其看作10维随机变量,作者采用“先PCA降维,后分析某一维的值分布”思路对嵌入矩阵展开正态性分析。
主成分分析是一种统计方法,它通过正交变换将一组潜在相关的变量转化为一组新的线性不相关变量。对于新变量,其中一些不是那么必要,对我们模型的训练有用的可以去掉。这个过程实际上是一个降维过程,对高维数据集进行降维。
#首先对嵌入矩阵PCA降维,(1115,10)降为(1115,6)
pca = PCA(n_components=6)
X_pca = pca.fit_transform(X_embedded_store) #X_pca是降维后得到的数据,shape为1115*6
print(pca.components_) #返回转换系数shape=(6,10),转换系数相当于转换后空间的基
plot_distribution_along_axis(X_embedded_store, X, pca.components_[0:4])
![[文献笔记]Entity Embeddings of Categorical Variables](https://aitechtogether.com/wp-content/uploads/2022/03/e5fee3647e2b4ad989cc2e73f18b88e0.webp)
图1,pca.components_[0]为转换后空间方差最大的基,将ee投影到基上,1115个嵌入分别投影到ee上,得到转换后新空间(共6个维度)第一维特征的1115个标量值,然后作标量值的分箱图。图2,pca.components_[1]为方差第二大的成分,以pca.components_[1]为基,将ee投影到基上,1115个嵌入分别投影到ee上,得到1115个标量值,然后作标量值的分箱图。图3,图4类似。基于以上分析,转换后的store_index嵌入矩阵前四维的取值分布均大致符合正太分布。此处正太性分析的目的还不是很理解,规范化为正太分布有利于加快神经网络训练速度,防止过拟合。从这个角度来解释嵌入相对于one-hot编码的优越性?
文章出处登录后可见!