一点就分享系列(理解篇5)SwintransformerV2的使用理解分享
前阵子在我Github的V5仓库中更新了swintransformerV2的代码,训练存在些问题(主要还是堆叠起来的全骨干段时间难以训练。晚一些更新剩余的内存优化计算,对于一个全新的backbone我一般使用adm,减小初始学习率还是存在陷入局部最优问题,但是如果只训练某几层结果还是正常的,于是我绝对回炉重修一下)借此机会今天抽时间再研究一下,顺便补一补博客的更新,所以废话不多说,关于 SwinV1的讲解网上太多了,写的都很好,我就不去解析了。今天的重点是一些思考和记录!
引文部分:论文叙述!
论文-Swin Transformer V2: Scaling Up Capacity and Resolution–
一、Swin Transformer v2: 扩展容量和分辨率(简述,看过swin2介绍的可略过这一节)
1. 动机
- Swin要在足够大的模型上验证自身,故引发了问题:训练的不稳定性,导致模型无法完成训练;
- 下游任务的扩展:需要更高的分辨率导致了性能下降;GPU显存消耗加大;
- 过大的FLOPs
2. 作者团队提供的改进:
- Post Normalization 。(回归经典,真的能解决嘛?)
- Scaled Cosine Attention 。
- 对数连续位置编码技术等。
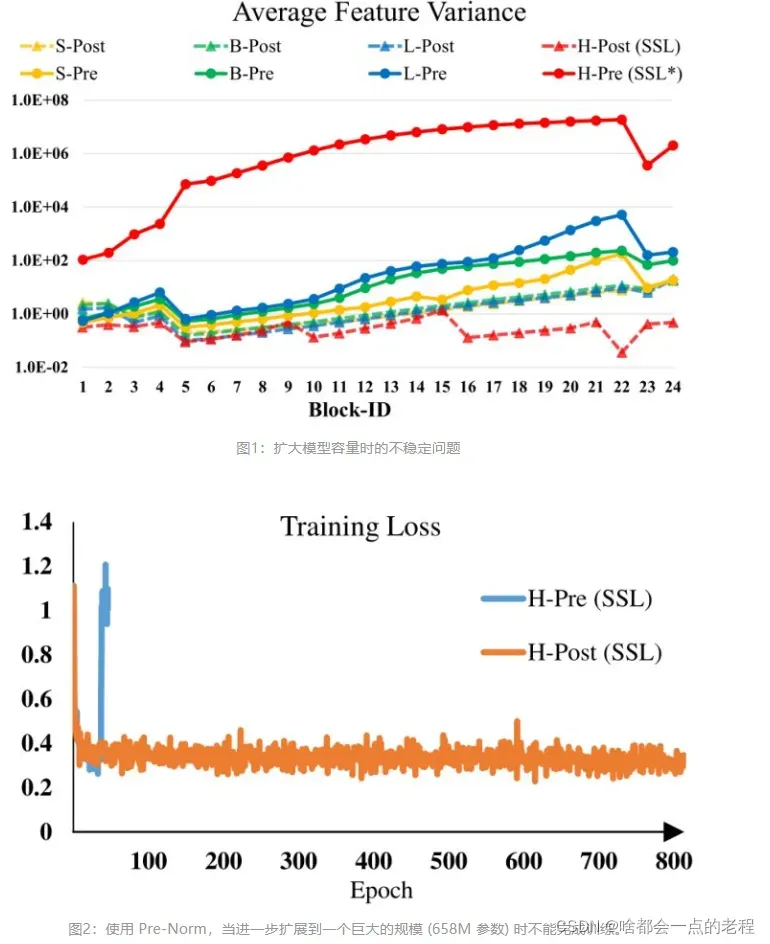
训练中的不稳定性问题。在大型模型中,跨层激活函数输出的幅值的差异变得更大。激活值是逐层累积的,因此深层的幅值明显大于浅层的幅值。如下图1所示是扩大模型容量时的不稳定问题。
当我们将原来的 Swin Transformer 模型从小模型放大到大模型时,深层的 activation
值急剧增加。最高和最低幅值之间的差异达到了104。当我们进一步扩展到一个巨大的规模 (658M 参数) 时,它不能完成训练
先来看一下整体的V1和V2的BLOCK修改对比图,红色部分: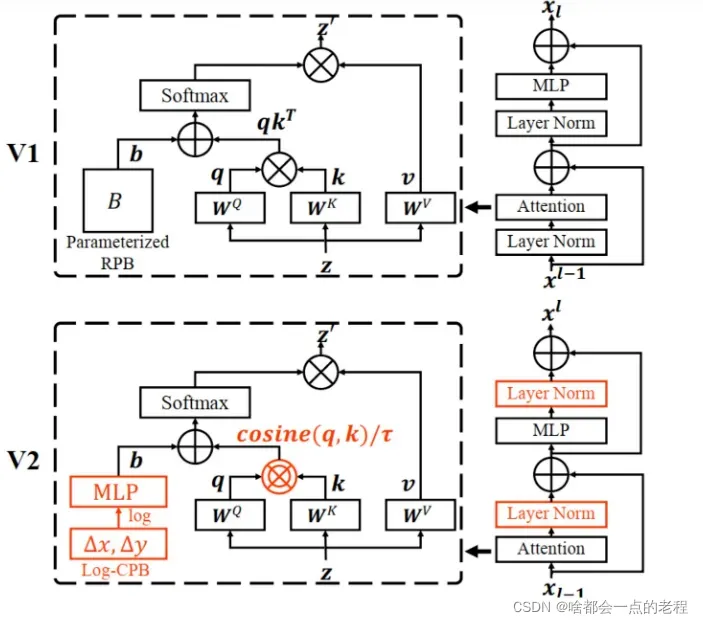
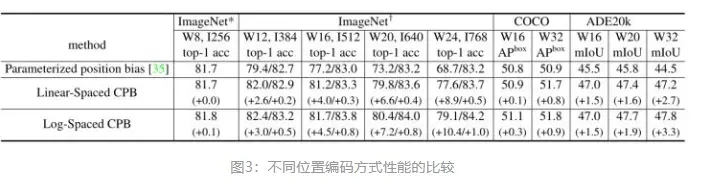
许多下游视觉任务需要高分辨率的图像或窗口,预训练模型时是在低分辨率下进行的,而 fine-tuning
是在高分辨率下进行的。针对分辨率不同的问题传统的做法是把位置编码进行双线性插值 (bi-cubic
interpolation),这种做法是次优的。如下图3所示是不同位置编码方式性能的比较,当我们直接在较大的图像分辨率和窗口大小测试预训练的
Imagenet-1k 模型 (分辨率256×256,window siez=8×8) 时,发现精度显著下降。
于是针对不稳定问题提出了改动1:Postnormalization
二、 改进点1:post normalization 改动的理解浅谈:
这个很简单:把LN层放在了后面,之前属于pre-norm,熟悉Transformer的朋友大概都有一个印象LN一直放在后面,而在SwinV1.0中的设计是pre_layer_norm的形式,那么为什么这么做呢?(我的V5里已经移植了V2版本的改进,但是发现还是很难训练),给的解释大概是:
把 Layer Normalization 层放在 Attention 或者 MLP 的后面,这里来和大家掰扯一下我的调研结果:
作者团队指出:在大型模型中,跨层激活函数输出的幅值的差异变得更大。激活值是逐层累积的,因此深层的幅值明显大于浅层的幅值:这样每个残差块的输出变化不至于太大,因为主分支和残差分支都是 LN 层的输 出,有 LN 归一化作用的限制。如上图所示,这种做法使得每一层的输出值基本上相差不大。在最大的模型训练中,每经过6个 Transformer Block,就在主支路上增加了一层 LN,以进一步稳定训练和输出幅值.
插曲:先说一下一种有趣的解释 Pre-norm和Post-norm的区别,来源于《On Layer Normalization in Transformer Architecture》:
pre-LN:在每一次输入中,
output[i+1]=input[i]+Attention(layer_norm(input[i]))
你可以发现Layer_norm将输入的方差控制住了,也就是和层数无关,那么只有前部分的input的方差会随着层数累加那么就有如下的比喻:
模型其实是做了一次伪Deep加深,虽然也是变大了,这种恒等思想也许可能是这样导致模型更易训练的原因,但是网络性能其实就会有降低,应该接触NLP的都知道,原版transformer就是这样的post的设计。( 结合的第一幅图我们可以发现,深浅层的输出值差距明显,特别是:Pre-LN在底层的梯度往往大于浅层,因而导致接近梯度爆炸的可能,不稳定的梯度造成了和 Post-LN相比性能下降))
output[i+1]=input[i]+(i+1)Attention(layer_norm(input[i]))
post-LN:在每一次输入中, output[i+1]=layer_norm(input[i]+ Attention(input[i])), 这样对每一次的输出都进了norm,那么Input的方差受到了极大的改变,所以这个公式无法变换成上面pre-LN的简化版本,梯度就难以控制,但是训练出来性能会更好。如果按照个角度去理解,那么这里的”大模型“,在pre-LN某种意义上是”宽“,而不是“深”,所以post-norm其实只是缓解了宽模型的训练问题,因为从一种意义上去理解,它是往“Deep”的程度?
对于改进点1 的理解
言归正传!简单总结下我对V2版本的学习理解以便给自己一个合理的解释!不然我真的寝食难安~
pre-ln 结构虽然更易训练,但是存在BLOCK堆积后,产生的前馈输出差异值变大,导致的训练“不稳定”问题:
主要是模型性能的下降以及高分辨下的甚至无法收敛,当然这个是实验结论,至于为什么不如post-layer_ln,如果上述恒等成立,那么同时可以帮助解释:因为这并不是真正意义的加”深”模型,因为深层和浅层的梯度差距,训练无法继续收敛。
post-ln其实是尝试解决了训练中的“不稳定问题”,具体来说,只是解决了堆积Block产生的通道维度增加带来的训练问题,控制梯度,而并没有解决和发现真正的深层模型的训练问题,并且通用上述对于post-LN的分析成立前提下,post-LN确实会带来更好的性能,仍然存在着梯度爆炸或者消失现象以及更深层的训练问题,这里埋个坑,因为只看swinv2你的了解只是到这里。
故这两种LN方式都会出现训练不稳定的现象,在此前提下,pre-LN也许更容易在大模型中收敛,但是性能下降;而Post方式可能更难训练(为什么呢?明明已经抑制模型的梯度问题了),但是效果会更好,当扩大到超大规模的深层模型,这两个方式同时存在缺陷.一般深模型的训练困难源于梯度消失或者梯度爆炸,但是在深度transformer中仍旧再存在更多的问题,那么Pre或者说Post方式都不能解决的最大问题是什么呢?在swintransformer中真正的问题到底是什么?如果说Pre-是梯度没有控制住,那么Post-LN的训练在一定深度上仍然出现的不稳定问题还要归咎于梯度嘛?
在这里,我会尽量对这个现象给出一个合理的解释,当然,我不能保证完全正确,先看下图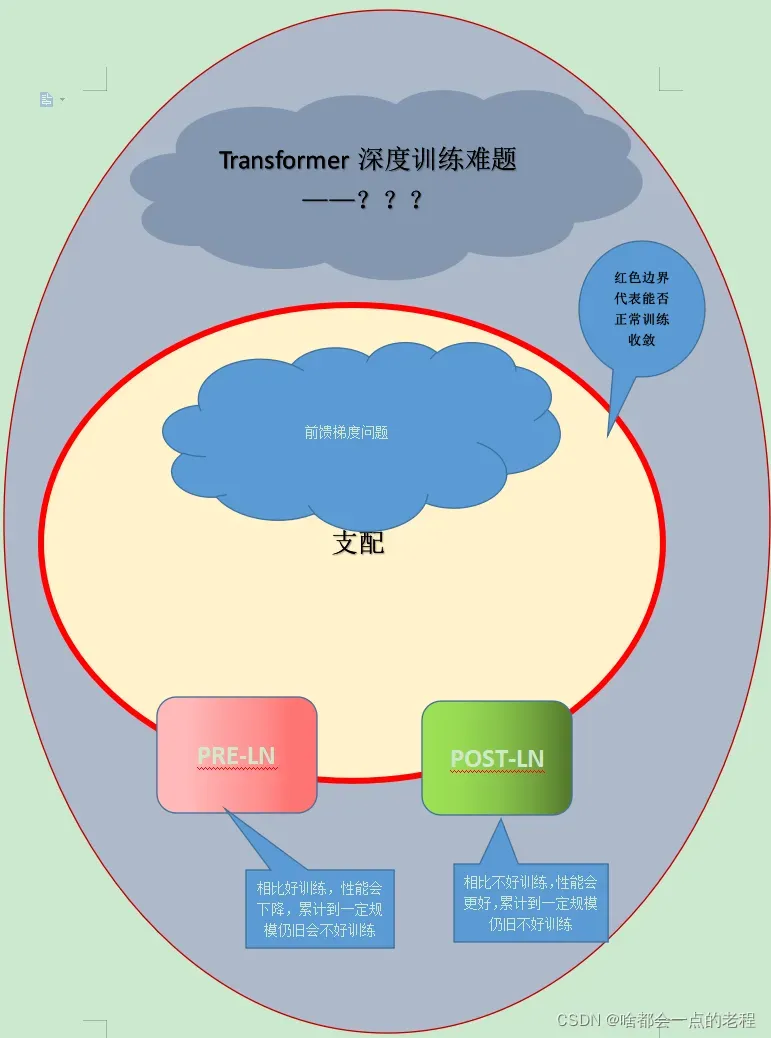
简单来说,SwinV2.0的Post-Norm方式只是针对梯度控制的手段,但是幕后元凶仍然阻挡着大规模深度transformer范式的进展,其实swin的团队目的很明显,他们就是要做出纯trans的新范式,所以他们也要向CNN一样,证明自己具备超大规模的能力,你登月了,我也得登月啊。
三、思考: 训练N层的Transformer问题
最近的微软出品《DeepNet: Scaling Transformers to 1,000 Layers》则沿着这个思路进行模型的归一化和初始化方案,最终成功训练出了1000层的Transformer模型。 DeepNeT的设计可以通过缓解爆炸式模型更新问题来稳定优化过程,具体细节可以自己看看论文。
训练开始时大模型更新:模型越深,更新量越大,这意味着模型在初始阶段越容易进入不好的局部最优,然后训练无法继续收敛,图片中是哪个? ? ? ? ————“增量爆炸”问题。
解决方式一般是初始阶段用更小的学习率然后慢慢增大学习率——warmup;否则需要根据经验手动调参抵去尝试抵消掉最初的增量差距;
方法1:调整初始化
让 Transformer 的训练更稳定。因此,研究者分析了有无适当初始化的 Post-LN 的训练过程。通过更好的初始化,在执行
Xavier 初始化后对第 L层的权重进行 downscale,下降的比例是:
比如,第 l 层的 FFN 的权重初始化为,d‘是输入和输出维度的均值
其中d’是输入和输出维度的平均值。研究者将此模型命名为 Post-LN-init。请注意,与之前的工作(Zhang et al., 2019a)不同, Post-LN-init是缩窄了较低层的扩展而不是较高层。研究者相信这种方法有助于将梯度扩展的影响与模型更新区分开来。此外,Post-LN-init 与 Post-LN 具有相同的架构,从而消除了架构的影响。
该研究在 IWSLT-14 De-En 机器翻译数据集上训练了 18L-18L Post-LN 和 18L-18L Post-LN-init。图 3 可视化了它们的梯度和验证损失曲线。如图 3© 所示,Post-LN-init 收敛,而 Post-LN 没有。 Post-LN-init 在最后几层中具有更大的梯度范数,尽管其权重已按比例缩小。此外,研究者可视化最后一个解码器层的梯度范数,模型深度从 6L-6L 到 24L-24L。
下图 3 显示,无论模型深度如何,最后一层 Post-LN-init 的梯度范数仍远大于 Post-LN 的梯度范数。得出的结论是,深层梯度爆炸不应该是 Post-LN 不稳定的根本原因,而模型更新的扩展往往可以解释这一点。
![[公式]](https://aitechtogether.com/wp-content/uploads/2022/03/26e29049bd394e2bbcd49a10b625eec0.webp)
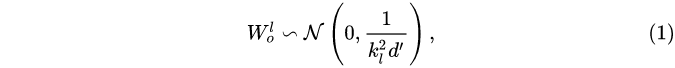
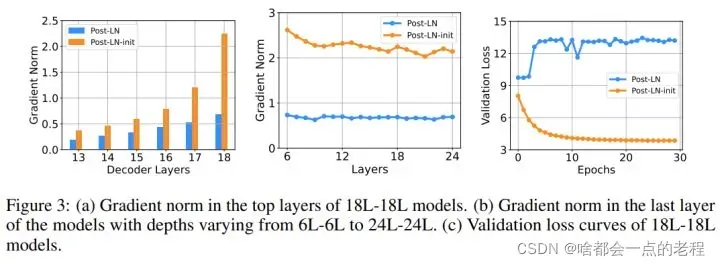
总结一下结论:POST-LN不稳定的根本原因并不是梯度问题
DeepNet:极深的Transformer模型
DeepNET作者以“不要让起始阶段模型参数更新得太快”的思想设计,DeepsNorm:权衡pre-lN和pre
deepnet结合post和pre的形式进行了改进为deep-norm:
其中,α是一个常数,G_l(x_l , θ_l)是参数为θ_l的第l个Transformer子层(即注意力或前馈网络)的函数。DeepNet还将残差内部的权重θ_l扩展了β。接着,研究者提供了对DeepNet模型更新预期大小(expected magnitude)的估计。他们可视化了IWSLT-14 De-En翻译数据集上,Post-LN和DeepNet在早期训练阶段的模型更新情况,如下图5所示。可以看到,相较于Post-LN,DeepNet的模型更新几乎保持恒定。
对比Post-LN形式,模型更加稳定。
然后研究者证明 Post-LN 的不稳定性来自一系列问题,包括梯度消失以及太大的模型更新。如图 4(a) 所示,他们首先可视化模型更新的范数 ||ΔF||在训练的早期阶段:
其中x和θ_i分别代表输入和第i次更新后的模型参数。Post-LN在训练一开始就有爆炸式的更新,然后很快就几乎没有更新了。这表明该模型已陷入虚假的局部最优。 warm-up和更好的初始化都有助于缓解这个问题,使模型能够顺利更新。当更新爆炸时,LN 的输入会变大(见图 4(b) 和图 4©)。根据Xiong等人(2020)的理论分析,通过 LN 的梯度大小与其输入的大小成反比:
相比于没有warm-up或正确初始化的情况,图 4(b) 和图 4© 表明 ||x||的明显大于
这解释了 Post-LN 训练中出现的梯度消失问题(见图 4(d))。
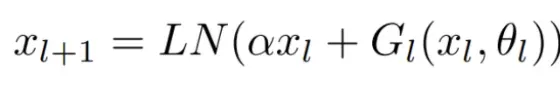
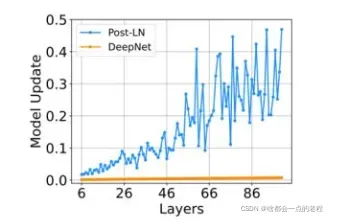
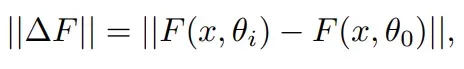
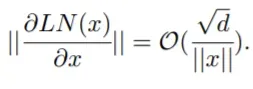
不稳定性始于训练开始时的大型模型更新。它使模型陷入糟糕的局部最优状态,(通过 LN 的梯度大小与其输入的大小成反比)这意味着又增加了每个 LN 的输入量。随着训练的继续,通过 LN 的梯度变得越来越小,从而导致严重的梯度消失,使得难以摆脱局部最优,并进一步破坏了优化的稳定性。相反,Post-LN-init 的更新相对较小,对 LN 的输入是稳定的。这减轻了梯度消失的问题,使优化更加稳定。
至此,DeepNorm告诉我了我们Post-LN梯度不稳定问题的根本原因,接下来言归正传!
四、改进点二——Scaled cosine attention 技术:解决训练中的不稳定性问题。
原来的 self-attention 计算中,query 和 key 之间的相似性通过 dot-product 来衡量,作者发现这样学习到的 attention map 往往被少数像素对所支配。所以把 dot 改成了 cosine 函数,通过它来衡量 query 和 key 之间的相似性。
式中,Bij是下面讲得相对位置编码,T是可学习参数。 余弦函数是 naturally normalized,因此可以有较温和的注意力值。
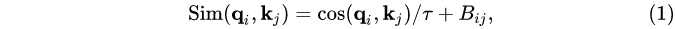
使用Cosine注意力机制,我的理解是改善了整个输出的数值分布,起到了归一化的作用,不使得 attention map 往往被较高的值所支配。
虽然代码不是开源的,但是这些改动还是比较简单的:
#dot 改成cosine ,并初始化一个参数给NET
self.register_parameter("tau", nn.Parameter(torch.zeros(1, num_heads, 1, 1)))
attn= (q @ k.transpose(-2, -1))
attn=attn /torch.maximum(torch.norm(q, dim=-1, keepdim=True) * torch.norm(k, dim=-1, keepdim=True).transpose(-2, -1),torch.tensor(1e-06, device=q.device, dtype=q.dtype))
attn/=self.tau.clamp(min=0.01)
然后接下来需要生成相对位置编码的tensor再继续计算!除了后面的B计算,基本没有区别的了和1.0.
5、改进点3——对数连续位置编码技术:解决分辨率变化导致位置编码尺寸不一致的问题,平滑下游任务!
该方法可以更平滑地传递在低分辨率下预先训练好的模型权值,以处理高分辨率的模型权值。 我们首先复习下 Swin Transformer
相对位置编码技术。
式中,B是每个 head 的相对位置偏差项 (relative position bias),Q,K,V是 window-based attention 的 query,key 和 value。 M 是 window 的大小。
在下游任务上进行 输入分辨率变化,window size 也有可能变化,导致无法直接迁移过来,Swin 的做法和 ViT 一致,采用双线性插值 (bi-cubic interpolation),这种方法并非最优操作,故引入对数空间连续位置偏差: 把上面的relative_position_bias_table 记作 “parameterized biases”,作者的新方法不是直接优化parameterized biases,而是采用了一个小的 meta network (2层 MLP,带有 ReLU 激活函数) 来生成 parameterized biases:
当输入分辨率发生变化时,window size 也会变化,作者采用对数空间的相对位置坐标:
作者称通过 log 函数之后,原本 8×8 窗口的 [-7, 7] * [-7, 7] 相对位置会变成 [-2.079, 2.079] * [-2.079, 2.079],如果扩大一倍 16×16 窗口的 [-15, 15] * [-15, 15] 相对位置会变成[-2.773, 2.773] * [-2.773, 2.773]。log 后位置编码变化是很小使得稳定。
![[公式]](https://aitechtogether.com/wp-content/uploads/2022/03/ef747ebb5c0d483a934bc9318b3af894.webp)
![[公式]](https://aitechtogether.com/wp-content/uploads/2022/03/27b4c2fabbea4578aa3d89ca9e3bbc6d.webp)
![[公式]](https://aitechtogether.com/wp-content/uploads/2022/03/7b487830f560411c80a87e006d101ede.webp)
这也是后续的为编码B计算,完整代码参考:
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,meta_network_hidden_features=256):
#创建一个meta netowrk:2liner +rule
self.meta_network = nn.Sequential(
nn.Linear(in_features=2, out_features=meta_network_hidden_features, bias=True),
nn.ReLU(inplace=True),
nn.Linear(in_features=meta_network_hidden_features, out_features=num_heads, bias=True))
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
#注册可学习参数T
self.register_parameter("tau", nn.Parameter(torch.zeros(1, num_heads, 1, 1)))
# Init pair-wise relative positions (log-spaced)
#根据windowsize给窗口编号,再压平
indexes = torch.arange(self.window_size[0], device=self.tau.device)
coordinates = torch.stack(torch.meshgrid([indexes, indexes]), dim=0)
coordinates = torch.flatten(coordinates, start_dim=1)
#利用广播机制 ,然后进行相减,得到相对位置关系-横纵坐标偏移
relative_coordinates = coordinates[:, :, None] - coordinates[:, None, :]
relative_coordinates = relative_coordinates.permute(1, 2, 0).contiguous().reshape(-1, 2).float()
#对数空间的相对位置坐标计算
relative_coordinates_log = torch.sign(relative_coordinates) \
* torch.log(1. + relative_coordinates.abs())
self.register_buffer("relative_coordinates_log", relative_coordinates_log)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask = None):
"""
Args:
x: input features with shape of (num_windows*B, Mh*Mw, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
# [batch_size*num_windows, Mh*Mw, total_embed_dim]
B_, N, C = x.shape
# qkv(): -> [batch_size*num_windows, Mh*Mw, 3 * total_embed_dim]
# reshape: -> [batch_size*num_windows, Mh*Mw, 3, num_heads, embed_dim_per_head]
# permute: -> [3, batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
# [batch_size*num_windows, num_heads, Mh*Mw, embed_dim_per_head]
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
attn = torch.einsum("bhqd, bhkd -> bhqk", q, k) \
/ torch.maximum(torch.norm(q, dim=-1, keepdim=True)
* torch.norm(k, dim=-1, keepdim=True).transpose(-2, -1),
torch.tensor(1e-06, device=q.device, dtype=q.dtype))
attn/=self.tau.clamp(min=0.01)
relative_position_bias = self.meta_network(self.relative_coordinates_log)
relative_position_bias = relative_position_bias.permute(1, 0)
relative_position_bias = relative_position_bias.reshape(self.num_heads, self.window_size[0] * self.window_size[1],\
self.window_size[0] * self.window_size[1])
attn = attn + relative_position_bias.unsqueeze(0)
#attn = attn + self.get_relative_positional_encodings()
if mask is not None:
# mask: [nW, Mh*Mw, Mh*Mw]
nW = mask.shape[0] # num_windows
# attn.view: [batch_size, num_windows, num_heads, Mh*Mw, Mh*Mw]
# mask.unsqueeze: [1, nW, 1, Mh*Mw, Mh*Mw]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = torch.einsum("bhal, bhlv -> bhav", attn, v)
return x
六、改进点四 ——GPU memory 降低
Zero-Redundancy Optimizer (ZeRO) from《Zero: Memory optimizations toward training trillion parameter models》:
传统的数据并行训练方法 (如 DDP) 会把模型 broadcast 到每个 GPU 里面,这对于大型模型来讲非常不友好,比如参数量为3,000M=3B 的大模型来讲,若使用 Adam optimizer,32为的浮点数,就会占用 48G 的 GPU memory。通过使用 ZeRO optimizer, 将模型参数和相应的优化状态划分并分布到多个 GPU中,从而大大降低了内存消耗。训练时使用 DeepSpeed framework,ZeRO stage-1 option。
Activation check-pointing from 《Training deep nets with sublinear memory cost》
Transformer 层中的特征映射也消耗了大量的 GPU 内存,在 image 和 window 分辨率较高的情况下会成为一个瓶颈。这个优化最多可以减少30%的训练速度。
Sequential self-attention computation :
在非常大的分辨率下训练大模型时,如分辨率为1535×1536,window size=32×32时,在使用了上述两种优化策略之后,对于常规的GPU (40GB 的内存)来说,仍然是无法承受的。作者发现在这种情况下,self-attention> 模块构成了瓶颈。为了解决这个问题,作者实现了一个 sequential 的 self-attention 计算,而不是使用以前的批处理计算方法。这种优化在前两个阶段应用于各层,并且对整体的训练速度有一定的提升。
在这项工作中,作者还一方面适度放大 ImageNet-22k 数据集5倍,达到7000万张带有噪声标签的图像。还采用了一种自监督学习的方法来更好地利用这些数据。通过结合这两种策略,作者训练了一个30亿参数的强大的 Swin Transformer 模型刷新了多个基准数据集的指标,并能够将输入分辨率提升至1536×1536 (Nvidia A100-40G GPUs)。此外,作者还分享了一些 SwinV2 的关键实现细节,这些细节导致了 GPU 内存消耗的显著节省,从而使得使用常规 GPU 来训练大型视觉模型成为可能。 作者的目标是在视觉预训练大模型这个方向上激发更多的研究,从而最终缩小视觉模型和语言模型之间的容量差距。
其实,SWINV2.0的主要改进就是对模型扩展任务遇到的难点进行了改良,核心内容:梯度控制和降低开销;部分代码适配到了YOLOV5中,无尽调试验证中,部分代码待优化的就是序列注意力计算去降低GPU显存和分辨率的可变
文章出处登录后可见!