近期在学高翔老师的《视觉SLAM14讲》并记了笔记,期待和大家多多交流!
初识SLAM
SLAM框架
1.传感器获取信息
- 单目相机:成本低,但无法知道环境的尺度(就像人闭上一只眼睛就失去了对环境的三维感)
单目相机移动后对远处和近处的物体产生的视差(Disparity)可以获得深度,后续的SLAM初始化正是依赖单目相机的移动。 - 双目摄像头:双目摄像头由两个摄像头组成,与人眼一样,两个摄像头之间的距离(基线)是已知的。两个摄像头产生的视差巧妙地赋予了双目摄像头感知环境深度的能力。
- 深度相机:又称RGBD相机,其中的D代表depth深度,即深度相机既可获得彩色画面,也可获得由深度构成的深度图,区别于双目相机的stereo模式,深度相机的原理可分为结构光(Structured-light)和TOF(time of flight)两种。
什么是结构光:通过近红外激光,投射出具有一定结构特征的激光散斑。这种散斑在照射到物体上时会因为物体的形状而发生畸变,然后计算单元会将这种结构变化转化为深度信息。
TOF呢:就是测量光的飞行时间,像激光测距一样来计算距离,通过探测光脉冲的飞行往返时间来获取深度信息。
2.视觉里程计
- Visual Odometry,简称VO,是一种用计算机视觉的方式来推算出相机走的路程。
人们在行走时,无论是向前行走还是转弯,都可以通过眼前场景的变化,轻松获得自己的姿态。一台只有一个摄像头的小电脑只能采用这种方法。通过获取当前图像帧并匹配之前的场景,计算机可以了解它正在采取什么运动(例如,图像在倾斜,表明相机本身在旋转),已经累积构成里程表。
3.后端优化
- 当摄像头工作在较暗的环境下,会影响图像之间的匹配,就像人在大雾中迷失了方向,诸如此类会影响SLAM系统精准工作的因素还有非常非常多,所以后端一直进行优化是很有必要的,即利用滤波器或非线性优化,将运动主体自身和周围空间环境不确定性表达出来并加以修正。
4.回环检测
- 传感器再好,也会有误差。错误将在每一帧中累积。相机的估计位置会随着时间的推移而漂移,最终的地图会很可怕。但如果相机走着走着走回曾经去过的地方,就会发现已经偏离了初衷,无法回到过去。此时,环回检测机制会将位置估计拉回。可以显着消除累积误差,使定位和测绘更加准确。
5.建图
- SLAM系统全称就是
Simultaneous Localization and Mapping
,即实时定位和建图,所以建图也是不可缺少的部分。相机在运动过程中通过特征点和关键帧构建二维或三维地图、稀疏或密集点云地图等,用于机器人。导航、避障或场景重建等。
SLAM问题的数学表述
- 系统运行时,其主要作用可以抽象为两种行为,即运动和观察。本书使用两个简洁的方程式来总结这两种行为
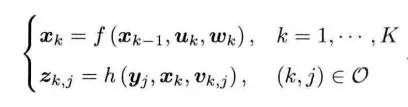
- 在k-1时刻到k时刻,第一个方程主要描述了:机器人通过读取传感器读数,例如IMU,编码盘等来估计当前运动,对应SLAM系统中的定位部分;同理,第二个方程主要描述传感器观测量,如深度相机,激光雷达获取周围环境的路标点(land mark,特征点,关键帧等)来估计外部环境的构建,对应SLAM系统的建图部分。
文章出处登录后可见!
已经登录?立即刷新