作者‖ cocoon
编辑‖3D视觉开发者社区
导读
相较于32位的浮点数神经模型,二值化神经网络通过将权值和隐藏层激活值二值化为1或者-1,达到更高的速度和更小的存储空间,从而使神经网络在移动设备上运行成为可能,其研究意义与价值不可言喻。而该篇论文作为BNN领域的开山之作,提供了一种训练二值化神经网络的方法,并通过实验证明该方法可达到接近SOTA的结果。代码开源,值得一读!
论文链接:https://arxiv.org/pdf/1602.02830.pdf
代码链接:https://github.com/itayhubara/BinaryNet
概述
该论文是2016年的“老”文章,源于Bengio大神等人,是BNN领域的经典文章。BNN相比起普通的32位的浮点数神经网络模型而言,内存占用理论上缩减至,且由于参数二值的性质,可以将多数运算转变为按位运算,进而有着对移动端非常友好的优势。尽管BNN有着巨大的优势,其特性也带来了网络精度降低以及难以训练的问题。该论文则提供了一种训练BNN的方法,并通过实验证明该方法可以在MNIST,CIFAR-10以及SVHN上面获得接近SOTA的结果。NNI(Neural Network Inteligence)是著名的开源AutoML工具,其对该BNN论文已进行了复现,用户可方便地对其进行调用。
方法
确定性二值化和随机二值化
所谓的确定二值化,指使用一种固定的方式将实值转为二值(+1或-1),转换公式为:
所谓随机二值化转换公式为:
其中的指 “hard sigmoid” 函数,具体为:
虽然随机二值化看起来更有吸引力,但在具体实现中需要硬件来生成随机位。因此,除了一些具体的实验,文章主要采用确定性二值化的方法。
梯度计算和累积
尽管BNN的训练方法使用的是二值的权重以及激活函数,但是参数的梯度的计算以及累加,是需要高精度的浮点数的。其实有存在很极端的二值网络连梯度也二值化,但是显然在该论文中是没有这么做的。
对于SGD这类的优化算法来说,浮点的梯度值很可能是必要的。SGD总是会用很小又带有噪声的步子去探索参数空间,而普遍认为这种噪声是服从正态分布的,因而可以在梯度的累加过程中消除掉噪声。也就是说,我们希望梯度的累加是足够细腻的,换句话说,高精度似乎是必须的。此外,这样的噪声可以被认为是某种正则化,进而会有助于泛化。本文中训练BNN的方式可以看做是“Dropout”的一个变种,只不过不是随机的对部分激活函数置为0,而是将所有的激活以及权重二值化。
离散梯度传播
符号函数的导数几乎处处为0,这使得其难以进行常规的反向传播。因此,我们只能寻找一种方式对其进行“松弛”。Bengio(2013)等人的研究表明STE(straight-through estimator)有着快速训练的优势,STE实质上就是将二值参数的梯度直接作为对应的浮点数的梯度。
STE 过程简介:
假设我们现在有一个浮点模型,它每次都更新浮点权重的梯度。在前向推理中,我们将浮点模型二值化,得到推理结果,然后反向传播二值参数的梯度,直接将二值参数的梯度作为浮点数的梯度,用来更新浮子的重量。训练结束后,将浮点类型的参数最后一次直接二值化,形成最终的二值网络。
因此,该论文也借鉴了STE的思想。考虑到符号函数的表达为:
假设为
的梯度,计算方式为
,其中
为损失函数,如果
已知,那么
的STE就可以简单地表达为:
这样做将保持梯度的信息,解决掉符号函数导数都为0的问题。且这样做可以在实数过大(具体指绝对值大于1的时候)时取消掉梯度,因为如果当
太大时不取消梯度的话,会对训练造成恶劣的影响,而对于实数
的绝对值在1以内的时候,实数
的梯度与
一致。
可以被认为是使用一种
hard tanh的方式对梯度进行传播,相当于逐段的线性激活函数:hard tanh 的图形表示为: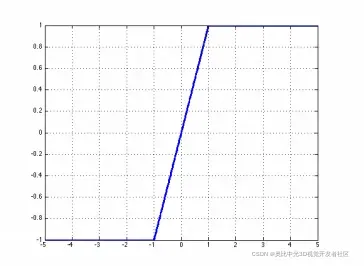
对于隐藏单元,我们使用非线性符号函数来获得二元激活函数。另外,对于权重的二值化,还有两个小点需要注意:
- 限制每一个实值的权重在
的范围内,对于那些数值在
,将其投影到1或者是-1的两个值上;
- 对于真实权重
。
具体地,这样的STE的方法在前向传播时,有:
在反向传播期间,我们有:
值得注意的是,在伪代码中已经清晰表明梯度并非二值的,这在“2.2 梯度计算以及累加”中也进行了强调。其中,将二值化也看做一层,因此需要先求得二值化层的梯度,此外,网络所求得的梯度尽管是高精度的浮点数,但其作用的对象是二值后的权值,并非二值化前的浮点数。
关于参数梯度的累积,有:
乘法优化
基于位移(shift)的BN
BN层加速了训练速度并且减小了权重尺度的整体影响。这种归一化的噪声或许有助于模型的正则化,然而,在训练时,BN层需要许多的乘法运算,尽管说这种乘法运算的数量与网络中的神经元数量一致,但是对于许多网络来说,这个数量还是相当大的。举个例子,对于这篇文章中所使用的网络架构,第一层卷积包含了的卷积掩膜,也就是说,它将一个大小为
的影像转换为
,这个量级已经是权重量级的数倍了。为了得到BN层所能达到的效果,文章提出了一个所谓的
(shift-based batch normalization)的技巧。具体见以下算法描述:

SBN的好处在于几乎不需要乘法运算。此外,在实验中,发现使用SBN相对于BN而言,几乎没有精度损失。
基于位移的AdaMax
ADAM的优化方式似乎也减小了权重尺度的影响,由于ADAM也需要做许多的乘法运算,文章建议使用基于位移的AdaMax,具体见以下算法描述:
同样地,文章在实验中发现,使用基于位移的AdaMax相对于普通的Adam算法来说,也没有观察到精度损失。
第一层没有二值化
在BNN中,某一层的输出将作为下一层的输入,而所有层的输入,我们会希望它们都是二值的。这里有一个例外,就是第一层,或者说是输入的图像特征的编码并非二值。然而,文章认为,输入的影像通道数相比起网络内部的高维来说是非常少的,即使是彩色影像,也只有RGB三个通道,且往往影像值都在之间,所以可以用8比特来表示。其次,将连续数值的输入视作定点数相对来说是比较简单的,举例来说,常用的8位量化定点输入为:
其中,假设是一个长度为
(
)的向量,其中的每一个元素都是8位的,
是长度为
的一比特的权重,
是最终的权重的加权和。这个技巧在算法中的表现为:

注意到在输入层与第一层隐藏层之间,是8位的,用到了普通的乘法,但其体量较小,对整体影响不大。此外,在算法中,除第一层以外,所有的乘法运算都被替换成了XNOR运算以及popCount的组合,大大地加快了速度。所谓的XNOR指对一对二进制串按位取异或非,而popCount则是用于取得XNOR结果中的个数,而后再通过固定的计算式就可以得到与乘法运算一样的数值结果,这样的运算过程主要是按位运算,对于移动端是非常友好的,这也是BNN的显著优势之一。
实验
论文实验结果
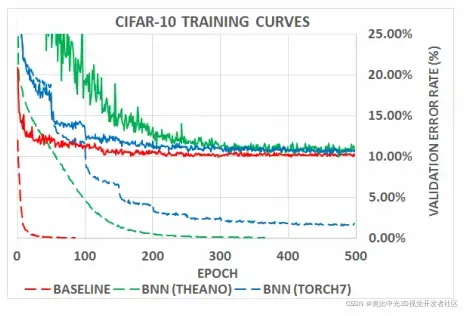
仅介绍在torch7中的实验设置,在训练过程中进行了”stochastically”的二值化,此外,还使用了基于位移的BN和AdaMax。下图是BNN的结果与32位浮点数的结果对比,具体可见蓝色虚线与红色虚线,蓝色虚线为在Torch7平台上的BNN训练情况,红色虚线为32位浮点训练的baseline,可以看到,BNN的损失下降是“阶梯性”的,且相比起baseline而言,训练的速度更慢,然而,最终所达到的精度却能够慢慢逼近32位浮点数的结果。
nni中的调用
NNI对这篇文章进行了复现,用户可以方便地进行调用实验,具体的调用代码为:
from nni.algorithms.compression.pytorch.quantization import BNNQuantizer
model = VGG_Cifar10(num_classes=10)
configure_list = [{
'quant_bits': 1,
'quant_types': ['weight'],
'op_types': ['Conv2d', 'Linear'],
'op_names': ['features.0', 'features.3', 'features.7', 'features.10', 'features.14', 'features.17', 'classifier.0', 'classifier.3']
}, {
'quant_bits': 1,
'quant_types': ['output'],
'op_types': ['Hardtanh'],
'op_names': ['features.6', 'features.9', 'features.13', 'features.16', 'features.20', 'classifier.2', 'classifier.5']
}]
quantizer = BNNQuantizer(model, configure_list)
model = quantizer.compress()
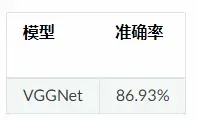
NNI对CIFAR-10上的VGGNet进行量化实验,最终达到的实验结果为:
结语
本文对BNN领域中的经典论文之一进行了简单的介绍,该论文提出了一种BNN的训练方法,且通过实验证明该方法可以得到近似于浮点数SOTA的结果,更为具体的细节推荐读者阅读原论文及代码。
参考
- Bengio, Yoshua. Estimating or propagating gradients through
stochastic neurons. Technical Report arXiv:1305.2982, Universite de Montreal, 2013. - nni 中的BNN官方介绍:https://nni.readthedocs.io/zh/stable/Compression/Quantizer.html
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。点击加入3D视觉开发者社区,和开发者们一起讨论分享吧~
或可微信关注官方公众号3D视觉开发者社区,获取更多干货知识哦。
文章出处登录后可见!