前言
在阅读论文之前,我们首先要具备一定的知识储备,包括人脸建模、表情制作、旋转转换等,为了方便我们对论文的理解,所以先解释一下一些关键的知识点。
- Flame模型的作用?
Flame是一个3D人脸的通用模型,举个例子,你现在有一个特定人的3D人脸扫描序列,那么我便可以通过Flame模型拟合,构建个性化的模型,然后通过改变表情参数,动作参数,从而生成一些新的表情,动作的3D数据,以进行动画制作等。除此之外,因为扫描数据的误差和缺失,我可以通过Flame模型,对数据进行拟合平滑,得到较为完善,完美的3D数据。除此之外,我还可以使用通用的模板T,从而实现对人脸较为粗糙的3D重建。比如Deca中,通过深度学习与Flame结合,可实现输入一张图片,输出人物的3D数据。
- SMPL模型是什么?
SMPL模型是一个对身体进行3D建模的通用模型。而Flame的模型结构便是参照了SMPL模型结构,Flame除了增加了表情参数,其他基本一致。
- Registration是什么意思?
Registration中文翻译为注册,但在3D建模中,Registration的意思是将模型拟合采集到的3D数据。
- BlendShape是什么?
BlendShape在表情制作中,是一种通过预定义的表情组合,生成新的表情的技术。举个例子,我先定义一份微笑的表情的人脸3D点A,再定义一份无表情的人脸3D点B。那我们当我想生成一个稍微微笑的表情的3D点时,我只需要计算0.2*A+0.8*B(其中0.2,0.8为可调系数),那么就合成一份新的3D点。而A和B,我们称为表情基,就像坐标系中的x轴y轴,在表情制作中,往往也需要经过PCA进行主成分分析,防止出现表情打架的情况。
- 蒙皮blend是什么?
Maya里面把模型绑定到骨骼上的技术叫做蒙皮,其外,骨骼驱动模型运动的算法,也称为蒙皮算法。而蒙皮算法有Linear Blend Skinning(线性蒙皮),对偶四元数蒙皮等。
除此之外,论文排版结构为一二章节主要是当前领域,数据集的介绍,可以比较粗略的阅读,第三章是讲Flame模型的公式,如何通过shape,exp,pose参数计算出mesh。第四节是讲数据集的registration。后面几节就分别讲数据集,模型评估等内容,所以重点在于第三四节。其外,哪里不懂的也可以留言,我尽量解答。哪里我理解错误的,也麻烦留言指出。谢谢。
ABSTRACT:
当前人脸3d建模模型,在高级的和低级的方法中,存在比较大的差距。对于高级人脸建模方法,模型与真人很相似,但往往需要人工介入。而对于低级的建模方法,用户通过深度传感器进行3d建模,但其没有足够的能力去精细表现面部形状和表情的变化。于是,作者通过成千的精细的3d人脸扫描数据,寻求一个中间地带,创建了Flame模型。Flame能很好的适用当今的图形软件并拟合数据。Flame模型从3800帧人脸头部的扫描数据学习线性shape空间,铰链结构下颚,脖子,眼球,以及依赖pose进行修正的bleedshapes,和全局的表情blendshapes。整个Flame模型总共使用了33000数据进行学习得到。Flame比FaceWarehouse和Basel Face Model更具有表现能力。
1 INTRODUCTION:
在人脸3d建模的领域,其中一种方法是针对个人数据进行建模,具有高精度,真实的特点。另一种方法是通用的,可以拟合图像,视频及3d数据,但具有缺乏真实性,完整性的缺点。作者目标是从4d数据(3d数据序列)中学习模型,能达到高端模型的精度,真实性等。
早期数据主要来自于欧洲年轻人的中性表情。最近,FaceWarehouse模型使用了一份新的数据,来自150个不同年龄层和种族的,20种不同姿势的人脸数据。虽然数据得到广泛的应用,但由于数据数量的限制,导致模型的shape表现能力有限。
为了解决上述问题,作者使用了3份混合数据集,一共33000帧3d数据集。Flame模型将个人身份和pose,expression空间耦合分离开。为了保持模型的简单、计算效率以及与现有游戏和渲染引擎的兼容性,定义了一个基于顶点的模型,它的多边形数量、关节数和blend蒙皮相对较少。Flame包含个人特性的shape空间,下巴,脖子,及眼球。此外,从样本中学习姿态pose对下巴,脖子的blendshapes的影响。最后,再学习表情的blendshapes去捕捉脸的非刚性变化。
我们使用4000帧来自于CAESAR的身体扫描的头部数据学习个人shape空间。使用超过400份来自D3DFACS的4D人脸数据以及额外我们自己采集的4D数据进行学习pose跟expression空间。模型的参数学习目的是最小化重建后的3d误差。为了达到这个目标,我们对所有数据进行拟合注册。(论文中registration,中文翻译为注册,意思是将模型拟合采集到的3d数据,因为采集到的3d数据可能存在误差或遗漏,所以registration可以实现修复弥补数据)
CAESAR数据被广泛的应用于3D身体建模,但是其没有对面部进行精细建模。作者采用了了类似SMPL的模型方法,并应用到人脸,脖子,头部建模。SMPL是一个参数化的,结合了个人shape空间,铰链pose,根据pose进行blendshapes矫正的混合蒙皮身体模型。
FaceWarehouse是当今唯一公开的具有大量人脸表情,并且数据已对齐模板。D3DFACS数据具有高质量的扫描数据,但却缺少对齐网格。因此,我们使用了co-registration和通过3d数据的纹理求出对应高质量的对齐网格。在模型中加入眼球,可以提高眼球的对齐准度。整个注册,模型学习过程是全自动的。
Flame通过构建blendshapes的全局线性模型来捕捉面部的相关性,在表情,个人和姿势都使用标准的正交分解(PCA),这有利于拟合不完全,稀缺的,噪声的数据集。
不同以前的模型,我们一起对头部和颈部进行建模,这是得头部允许跟随着颈部旋转,并学习依赖pose变化的blendshapes进行捕捉pose旋转导致的颈部变化。
作者主要贡献在于公布了一个比现在模型更精准,更具有表达力的Flame模型,并且能适用图形软件。与现有的模型相比,FLAME精准的模拟了头部姿势和眼球旋转,并且通过注册数据集D3DFACS将其对齐,使D3DFACS数据集可用于其他模型的训练。
2 RELATED WORK:
Generic face models:Blanz and Vetter在1999年提出了第一个通用的3d人脸模型,使用PCA找寻shape跟texture的线性组合空间。其意义非凡,是BFM(2009)模型的研究灵感。
为了更好呈现面部表情的变化,2008年Amberg应用PCA在表情与中性表情的差值上求出表情空间。最近2015提出类似的Face2Face模型。2011提出了针对各个表情单独进行PCA的方法。然而有限的数据集限制了这些模型的表达能力。
为了提高人脸细节,分别有人提出了稀疏线性模型跟大量的局部多线性小波模型。对于动画制作,人脸绑定使用本地,手工的blendshapes对模型进行很好的控制,但是因为过于复杂及冗余的blendshapes,对模型的数据拟合并不适用。
因为通用人脸模型都比较粗糙,于是有几种方法可进行优化,比如针对特定的人,从训练集中提取特定的皱纹映射,比如对特定人,建立无姿态下的shape空间与人工制作的特定表情模型。但这些方法都是针对特定人的,并不通用。
Cao在2015年使用概率图在个性化的blendshapes模型上建立个性化特征,如皱纹。他们使用一个通用模型来估计参与者的粗糙面部形状,并通过将细节与粗糙的个性化blendshapes模型的参数联系起来,构建个性化的精细模型。Xu在2014年通过将人脸分解为多个高分辨率的方法,将细节从一个网格迁移至另一个。他们的方法都是使用预定义的表情blendshapes,这些方法可以作为Flame的一个改进从而提高细节。
2009年推出了一个个性化的模型,通过演员的高精度扫描并使用半自动动画系统跟踪这位女演员的面部。2016年将分离子空间与局部形变子空间相结合,逼真地模拟三个演员的面部表演,类似Flame,下颚也可自由旋转,但他们的方法使用个性化的子空间来捕捉形状细节,因此不适用于任意目标。
个性化blendshape模型在面部表情捕捉经常使用到,但这些方法往往需要人员特定的校准和训练。Bouaziz使用个性化的PCA模型去实现形变转换,Cao使用个性化的多线性模型,Ichim通过自然状态下无pose的图片跟人脸形变记录去实现个性化的blendshapes,这些方法要么使用手工设计的通用blendshapes作为初始化,要么使用低分辨率的局部表情。
我们模型的关键点在于对齐,或者说是注册我们的模板到扫描的3d数据集。我们的重点是对齐3D网格扫描数据,以建立铰接式形状和姿态模型的方法。虽然有很多方法对齐静态的扫描人脸,但很少方法是针对4D数据(3d网格序列)。像Vlasic的方法依赖手工标注关键点,这类方法不能成千的扫描数据,Beeler使用相同表情的重复帧来防止漂移。他们生成了非常精细的网格,但只对三个参与者这样做,并仅在几百帧上定性地展示结果。我们的方法应用在了成千上万帧数据。我们的人脸注册方法使用了共同注册(co-registration),这个方法之前应用在身体注册上。
我们注意到,大多数以前的方法在对齐过程中都会忽略眼睛。这使得眼睑容易解释眼球的嘈杂几何形状,并导致眼部区域出现大量的光度误差。所以我们将眼球添加到我们的网格中,并表明这有助于对齐过程。
3 MODEL FORMULATION:
FLAME将SMPL身体建模方法应用到头部。采用SMPL使我们的模型计算效率更高效,并与现有的游戏引擎兼容。我们使用与SMPL一样的表示方法。
在SMPL模型中,几何变形是由于个体固有的形态变化或者姿势pose的变化。对于脸,大多数形变是由于肌肉激活,这与铰链姿势的改变无关。于是我们扩展SMPL,增加了表情blendshapes如下图图二。Flame包括了人脸,整个头部,颈部。
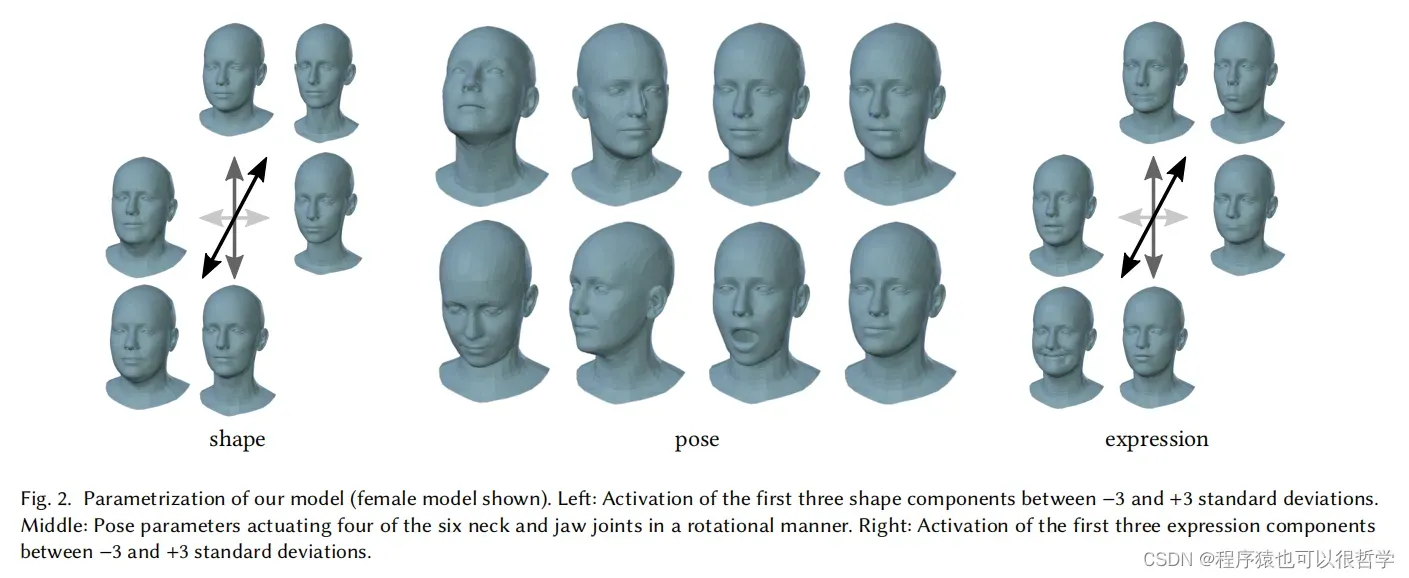
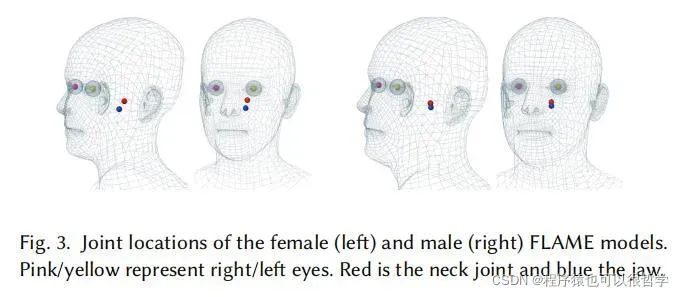
Flame使用了基于线性混合蒙皮(LBS)方法。有N=5023个顶点,K=4个关节(颈部,下巴和两个眼球,正如图3所示),以及可以从数据集中学习到的blendshapes。Flame模型可以表述为公式M(β,θ,ψ),从维度|β|×|θ|× |ψ| 到3N的维度映射。其中shape系数β,pose系数θ和表情系数ψ,输出为N个顶点坐标。其中θ是一个3K+3的向量,包含了K+1个旋转向量。每个关节的三维旋转矢量加上全局旋转向量。
Flame包含一个模板mesh,维度为3N的向量。在pose=0无姿态条件下,shape函数BS(β;S),表示个体的形状变化。
BP(θ;P)表示姿态造成身体变化的矫正,但不能用LBS方法解释。BE(ψ;ε)表示表情变化。
标准函数W(T,J,θ,W)是为了求顶点经过关节旋转后的顶点变化,线性平滑通过与blendweight,维度为k×N矩阵W相乘。
更正式地说,该模型可以定义为以下公式:
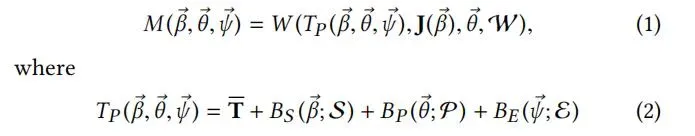
其中Tp为模板mesh加了shape,pose,exp的偏移量。
由于不同的脸型意味着不同的关节位置,所以的关节公式定义为J(β: j,T,S) = j (T+BS(β; S)),其中j为如何从mesh顶点计算关节位置的系数矩阵,可通过训练数据学习得到。Fig3可以看到在头部,自动学习到的关节位置。
Shape blendshapes:Flame中不同个体shape的线性变化公式如下,
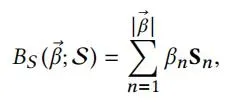
其中β为shape系数,S = [S1,S2….Sβ]为维度3N×|β|,通过PCA标准正交的矩阵。
Pose blendshapes:定义公式R(θ)为|θ|到9K的维度映射,为pose向量θ转换成旋转矩阵。公式定义如下:
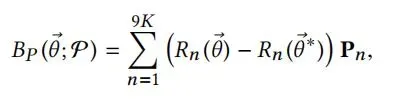
Pn表述为由姿势激活的顶点偏移量。P = [P1,…..P9k]是3N×9K的矩阵。虽然pose blendshapes在R中是线性的,但由于从θ到旋转矩阵元素的非线性映射,它们其实是非线性的。
Expression blendshapes:类似于shape blendshapes,为线性的,公式如下,
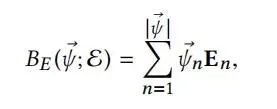
其中ψ为表情系数,ε为标准正交化后的维度3N×|ψ|的矩阵。
Template shape:我们首先使用一个通用的template mesh T,之后不断通过扫描数据,学习修正T,同时,也学习blendWeights W。下文将进行详细讲解。
4 TEMPORAL REGISTRATION
人脸建模要求所有扫描的训练人脸数据的顶点完全对应。对于每个3D扫描序列,都会有个注册对应的对齐模板T。整个注册过程是在注册mesh和训练FLAME模型参数之间交替进行。如图四。
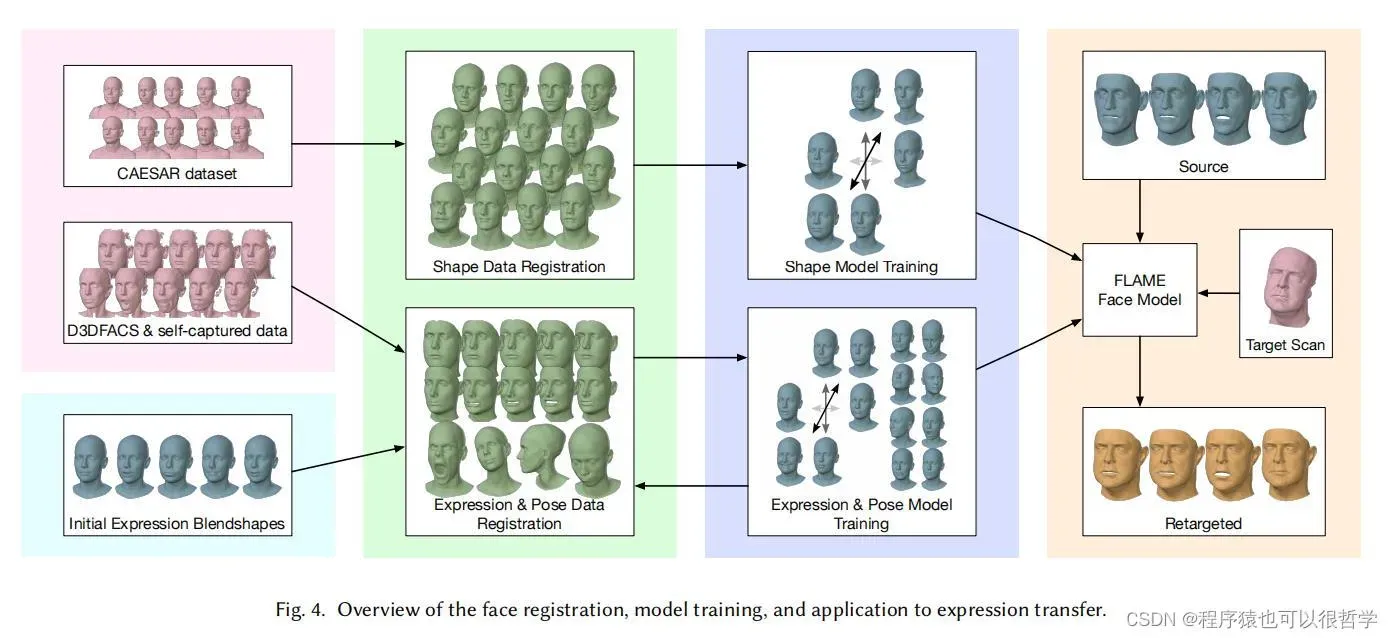
4.1 Initial model
交替注册过程需要一个初始的FLAME模型。包括FLAME由shape参数组成{T,S},pose{P,W,j}和exp{ε},需要初始化,然后我们对其进行优化以适应注册的扫描数据。
shape:通过对CAESAR数据集里面的头部顶点数据进行PCA,得到初始化的shape空间。为了提高注册过程的稳定性和质量,添加了眼球进入我们的shape模型中。
Pose:blendweights W和关节矩阵j,初始化都为人工设计。
Expression:对FACS-based blendshape模型里面的expression blendshapes进行形变转换,获取到我们模型的Expression blendshape。
4.2 Single-frame registration
为了注册对齐3d扫描序列,我们计算获取个性化的模板template和将纹理映射到2048*2048的图片上。
模型注册包括三个步骤。
Model-only:我们通过优化估计模型系数{β,θ,ψ}来拟合扫描数据。
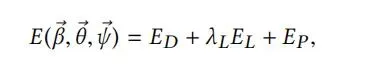
ED测量扫描的顶点vs到模型生成表面的最近的点的距离。λ为数据项的权重。ρ可以使扫描边缘更具鲁棒性。
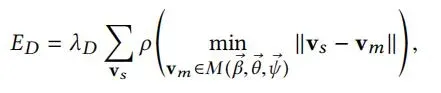
EL测量使用相机校准将扫描数据映射到图像上的关键点与模型模板上相应顶点之间的L2范数距离,总共标注了49个关键点。
EP为参数β,θ,ψ的正则化。
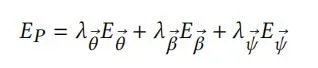
Coupled:第二,这一阶段,我们允许优化模型空间以及模板T。
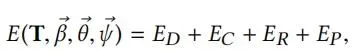
同时优化参数β,θ,ψ以及模板mesh T。对比model-only,ED现在测量的是扫描点到对齐mesh T的距离。EC计算T边缘与当前模型M(β, θ,ψ)边缘的距离,防止偏离过大。
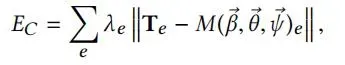
λe为边缘权重,通过边缘优化从而达到临近顶点的优化。为了优化第一阶段model-only中存在误差,这一阶段也允许优化T。正则化项ER为T上的顶点的离散拉普拉斯算子的逼近。
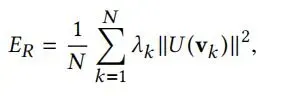
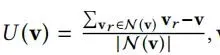
其中N(v)为v周围的顶点集合。正则化项避免了注册过程中顶点的折叠,从而使注册方法对噪声和部分遮挡具有鲁棒性。
Texture-based:第三,我们增加一个纹理项的ET,公式如下:
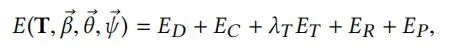
ET测量所有视角下的T渲染的纹理和的真实图像I之间的光度误差。
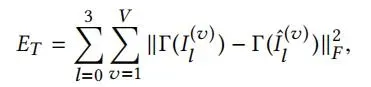
4.3 Sequential registration
我们的序列配准方法使用个性化阶段为数据库中的每个主题构建个性化模板,然后在跟踪面部表征期间保持不变。
Personalization:我们假设每个捕获的序列都以一个中立的姿势和表情开始。在个性化过程中,我们使用公式9进行耦合注册,并对多个序列结果Ti进行平均获取个性化模板。随机选择一个Ti的纹理作为后续注册的纹理。个性化过程提高了注册的稳定性和效果,并且减少了参数优化。
Sequence fitting:在序列拟合时,我们将个性化模板替换掉公式一中的模板M,并且将β置为0。对于每一帧,我们从前一帧初始化模型参数,并使用4.2中的单帧注册。对于序列注册,我们通过迭代注册训练Flame,在第四次迭代中,视觉质量不再有明显提升,于是我们停止迭代。
5 DATA
Flame的数据集又可得到的公共数据集和我们自己捕获的数据集两部分组成。
6 MODEL TRAINING
训练的目标FLAME是解耦形状、姿态和表达式变化,计算一组参数Φ = {T,S, P, ε,W, j}。为了实现解耦,采用迭代优化方法对姿态参数{P, W, j}、表达式参数ε和形状参数{T,S}进行一次优化,使训练数据的重构误差最小。
6.1 Pose parameter training
pose参数有两种类型,第一种是每个受试者都有特定的参数,如无姿态下的模板T,以及个人的关节J。第二种是跨越个体的参数,如blendweights W和姿态blendshape P。
这些参数的优化是通过交替求解位姿参数θi,优化个体特定参数{Ti,Ji},以及优化全局参数{W, P, j}。优化函数包含一个重构误差ED和pose blendshapes的正则化误差Ep和一个blendweights与初始值的误差EW,Ep和EW是为了接近训练数据和保持参数通用之间的权衡。
训练θ,我们使用均值的模板Ti作为初始化模板Ti,为了对大形变更有鲁棒性,我们使用模板边缘最小化作为优化方向。
为了避免Ti和Ji受到表情的影响,我们训练Ti和Ji时,在公式五中移除BE项。
6.2 Expression parameter training
训练表情空间ε要求表情从姿态和形状变化中解耦。首先我们先求出pose空间,然后在公式1中M(0,θ,0)。我们将其状态成为无姿势,并且将注册好的顶点坐标记做Vuj。因为我们想要对自然表情进行建模,我们假设为每个个体在无姿势状态下,注册一个自然表情的顶点Vnej。为了将表情的变化与形状的变化解耦,我们计算残差Vuj−Vnej对于每个注册的j。然后我们通过对这些残差应用PCA计算表达式空间E。
6.3 Shape parameter training
形状参数的训练包括模板T和形状混合形状S,用于形状的注册。类似地,从所有训练数据中去除姿势和表情的影响。
6.4 Optimization structure
FLAME的训练是迭代完成的,仅通过优化姿态、表情或形状参数,优化过程中保持其他参数固定。由于表情空间的高容量和灵活性,我们要先训练pose空间,再求表情空间,避免过拟合。
7 RESULTS
7.5 Expression transfer
FLAME可以很容易地用于合成新的运动序列,例如,通过将面部表情从源行动者转移到目标行动者,同时保留目标面部的特定人物细节。这个分为三个步骤,第一,对于原序列,通过章节4.3注册,求出对应的θs和ψs。第二,耦合注册(章节4.2)用于为目标扫描计算个性化模板Tt。最后,Tt替换掉均值模板T,求出目标个体的Mt(β,θ,ψ)。那么表情迁移的结果便是Mt(0,θs,ψs)。
关键代码
###### Flame模型起始代码 ##################
tf_trans = tf.Variable(np.zeros((1,3)), name="trans", dtype=tf.float64, trainable=True) #平移变量
tf_rot = tf.Variable(np.zeros((1,3)), name="pose", dtype=tf.float64, trainable=True) #全局旋转变量
tf_pose = tf.Variable(np.zeros((1,12)), name="pose", dtype=tf.float64, trainable=True) #关节旋转变量
tf_shape = tf.Variable(np.zeros((1,300)), name="shape", dtype=tf.float64, trainable=True) #shape系数
tf_exp = tf.Variable(np.zeros((1,100)), name="expression", dtype=tf.float64, trainable=True) #exp系数
smpl = SMPL(model_fname)
tf_model = tf.squeeze(smpl(tf_trans,tf.concat((tf_shape, tf_exp), axis=-1),
tf.concat((tf_rot, tf_pose), axis=-1)))############## Flame第三章节中Mesh生成代码 ###############
#trans 为平移变量,shape = [1,3]
#beta 为shape和exp系数,shape = [1,400]
#theta 为旋转系数,shape = [1,15]
num_batch = beta.shape[0].value
# 计算模板T加上shape和exp的偏移之后的顶点坐标。v_shaped = [1,5023,3]
v_shaped = tf.reshape(tf.matmul(beta, self.shapedirs, name='shape_bs'),[-1, self.size[0], self.size[1]]) + self.v_template
# 计算关节位置,其中J_regressor = [5023,5],J = [1,5,3]
Jx = tf.matmul(v_shaped[:, :, 0], self.J_regressor)
Jy = tf.matmul(v_shaped[:, :, 1], self.J_regressor)
Jz = tf.matmul(v_shaped[:, :, 2], self.J_regressor)
J = tf.stack([Jx, Jy, Jz], axis=2)
# 将旋转向量转换成旋转矩阵,并求出Rs
# 其中batch_rodrigues便是求旋转矩阵,Rs = [1,5,3,3],pose_feature = [1,36]
Rs = tf.reshape(batch_rodrigues(tf.reshape(theta, [-1, 3])), [-1, self.num_joints, 3, 3])
with tf.name_scope("lrotmin"):
# Ignore global rotation.
pose_feature = tf.reshape(Rs[:, 1:, :, :] - tf.eye(3, dtype=self.dtype), [-1, 9*(self.num_joints-1)])
# 计算姿势偏移量,v_posed = [1,5023,3]
v_posed = tf.reshape(tf.matmul(pose_feature, self.posedirs),[-1, self.size[0], self.size[1]]) + v_shaped
# 求关节的系数矩阵,其中parents的值为[-1,0,1,1,1],J_transformed = [1,5,3],A = [1,5,4,4]
self.J_transformed, A = batch_global_rigid_transformation(Rs, J, self.parents)
# W = [1,5023,5]
W = tf.reshape(tf.tile(self.weights, [num_batch, 1]), [num_batch, -1, self.num_joints])
# T = [1,5023,4,4]
T = tf.reshape(tf.matmul(W, tf.reshape(A, [num_batch, self.num_joints, 16])),[num_batch, -1, 4, 4])
# v_posed_homo = [1,5023,4]
v_posed_homo = tf.concat([v_posed, tf.ones([num_batch, v_posed.shape[1], 1], dtype=self.dtype)], 2)
# v_homo = [1,5023,4,1]
v_homo = tf.matmul(T, tf.expand_dims(v_posed_homo, -1))
return tf.add(v_homo[:, :, :3, 0], trans)################### 相关代码 ####################
def batch_skew(vec, batch_size=None, name=''):
with tf.name_scope(name, "batch_skew", [vec]):
if batch_size is None:
batch_size = vec.shape.as_list()[0]
col_inds = tf.constant([1, 2, 3, 5, 6, 7])
indices = tf.reshape(
tf.reshape(tf.range(0, batch_size) * 9, [-1, 1]) + col_inds,
[-1, 1])
updates = tf.reshape(
tf.stack(
[
-vec[:, 2], vec[:, 1], vec[:, 2], -vec[:, 0], -vec[:, 1],
vec[:, 0]
],
axis=1), [-1])
out_shape = [batch_size * 9]
res = tf.scatter_nd(indices, updates, out_shape)
res = tf.reshape(res, [batch_size, 3, 3])
return res
# 通过罗德里格斯公式,将旋转向量转换为旋转矩阵。
def batch_rodrigues(theta, name='', dtype=tf.float64):
with tf.name_scope(name, "batch_rodrigues", [theta]):
batch_size = theta.shape.as_list()[0]
angle = tf.expand_dims(tf.clip_by_value(tf.norm(theta, axis=1), 1e-16, 1e16), -1)
r = tf.expand_dims(tf.math.divide_no_nan(theta, angle), -1)
angle = tf.expand_dims(angle, -1)
cos = tf.cos(angle)
sin = tf.sin(angle)
outer = tf.matmul(r, r, transpose_b=True, name="outer")
eyes = tf.tile(tf.expand_dims(tf.eye(3, dtype=dtype), 0), [batch_size, 1, 1])
R = cos * eyes + (1 - cos) * outer + sin * batch_skew(r, batch_size=batch_size)
return R
# 计算关节的绝对位置和稀疏矩阵。
# Rs为关节的旋转矩阵,Rs = [1,5,3,3],Js为初始关节位置,Js = [1,5,3]
# 返回值Js为新的关节位置,new_j = [1,5,3],A为稀疏矩阵,A = [1,5,4,4]
def batch_global_rigid_transformation(Rs, Js, parent, rotate_base=False, name=''):
num_joints = parent.shape[0]
with tf.name_scope(name, "batch_forward_kinematics", [Rs, Js]):
N = Rs.shape[0].value
root_rotation = Rs[:, 0, :, :]
Js = tf.expand_dims(Js, -1)
def make_A(R, t, name=''):
# Rs is N x 3 x 3, ts is N x 3 x 1
with tf.name_scope(name, "Make_A", [R, t]):
R_homo = tf.pad(R, [[0, 0], [0, 1], [0, 0]])
t_homo = tf.concat([t, tf.ones([N, 1, 1], dtype=t.dtype)], 1)
return tf.concat([R_homo, t_homo], 2)
A0 = make_A(root_rotation, Js[:, 0])
results = [A0]
for i in range(1, parent.shape[0]):
j_here = Js[:, i] - Js[:, parent[i]]
A_here = make_A(Rs[:, i], j_here)
res_here = tf.matmul(results[parent[i]], A_here, name="propA%d" % i)
results.append(res_here)
results = tf.stack(results, axis=1)
new_J = results[:, :, :3, 3]
Js_w0 = tf.concat([Js, tf.zeros([N, num_joints, 1, 1], dtype=Js.dtype)], 2)
init_bone = tf.matmul(results, Js_w0)
# Append empty 4 x 3:
init_bone = tf.pad(init_bone, [[0, 0], [0, 0], [0, 0], [3, 0]])
A = results - init_bone
return new_J, A
文章出处登录后可见!