
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦!

🉑 Google 推出轻量级开源模型 Gemma:这是想开源闭源双线作战?

2月21日,Google 宣布推出轻量级开源系列模型 Gemma,包含 Gemma 2B 和 Gemma 7B 的预训练和指令微调版本。在发布模型权重的同时,Google 还同步推出了一系列的支持工具 ⋙ 官方中文公众号
Gemma 再次证明,只要数据量足够多 (Gemma 7B用到了6万亿Token),数据质量足够好 (增加数学、代码、科学论文等增强模型推理能力的数据),小模型的能力仍然能够得到持续提升。
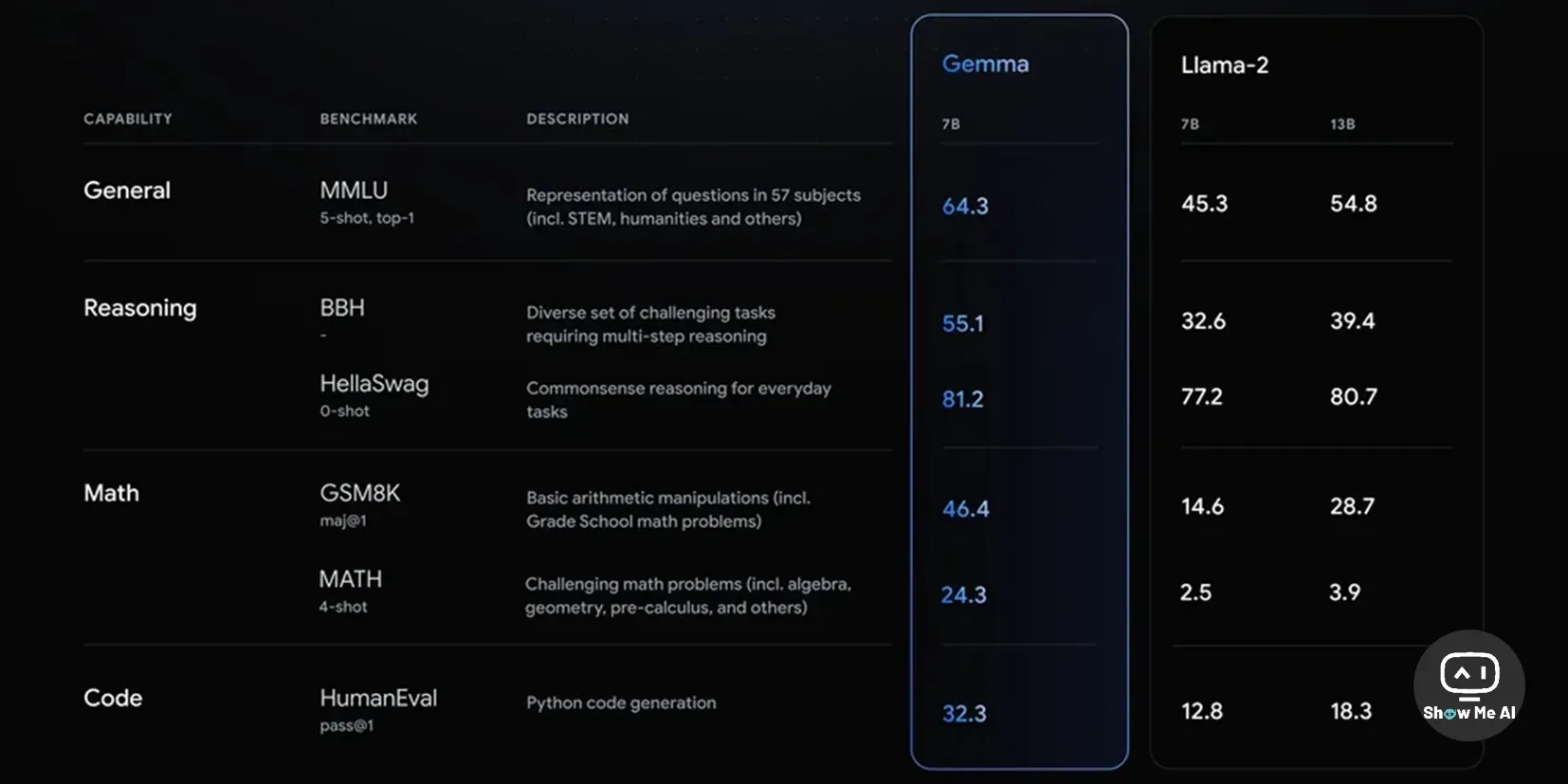
关于 Gemma 的实际表现,AI社区正在测试中并陆续有一些分享。不过,业内对于 Google 此时推出 Gemma 开源模型,有一些解读观点非常有洞察力:
Gemma 是针对开源届的,也就是针对 Meta 和 Mistral 的。这侧面说明 Meta 的 LLama 3 很快就要发布了,或者 Mistral 最近会有新品发布。
谷歌被迫再次切入开源领域,重返开源赛场是大好事,虽然很明显是被迫的。Gemma 代表谷歌大模型策略的转变——兼顾开源和闭源:,开源主打性能最强大的小规模模型,希望脚踢 Meta 和 Mistral;闭源主打规模大的效果最好的大模型,希望尽快追上 OpenAI。
目前大模型巨头的打压链:OpenAI → Google & Anthropic & Mistral → Meta → 其它大模型公司。
Gemini 1.5 其实是很强的,但在宣发策略上被 OpenAI 临时拿Sora出来打哑火,没有获取应该获取到的足够公众关注。OpenAI应该储备了一个用于打压对手的技术储备库,即使做得差不多了也隐而不发,专等竞争对手发布新产品的时候扔出来,以形成宣传优势,而这种打压策略很明显还会继续下去。
👀 世界上速度最快的大模型 Groq 登场:天下武功,真的唯快不破吗?
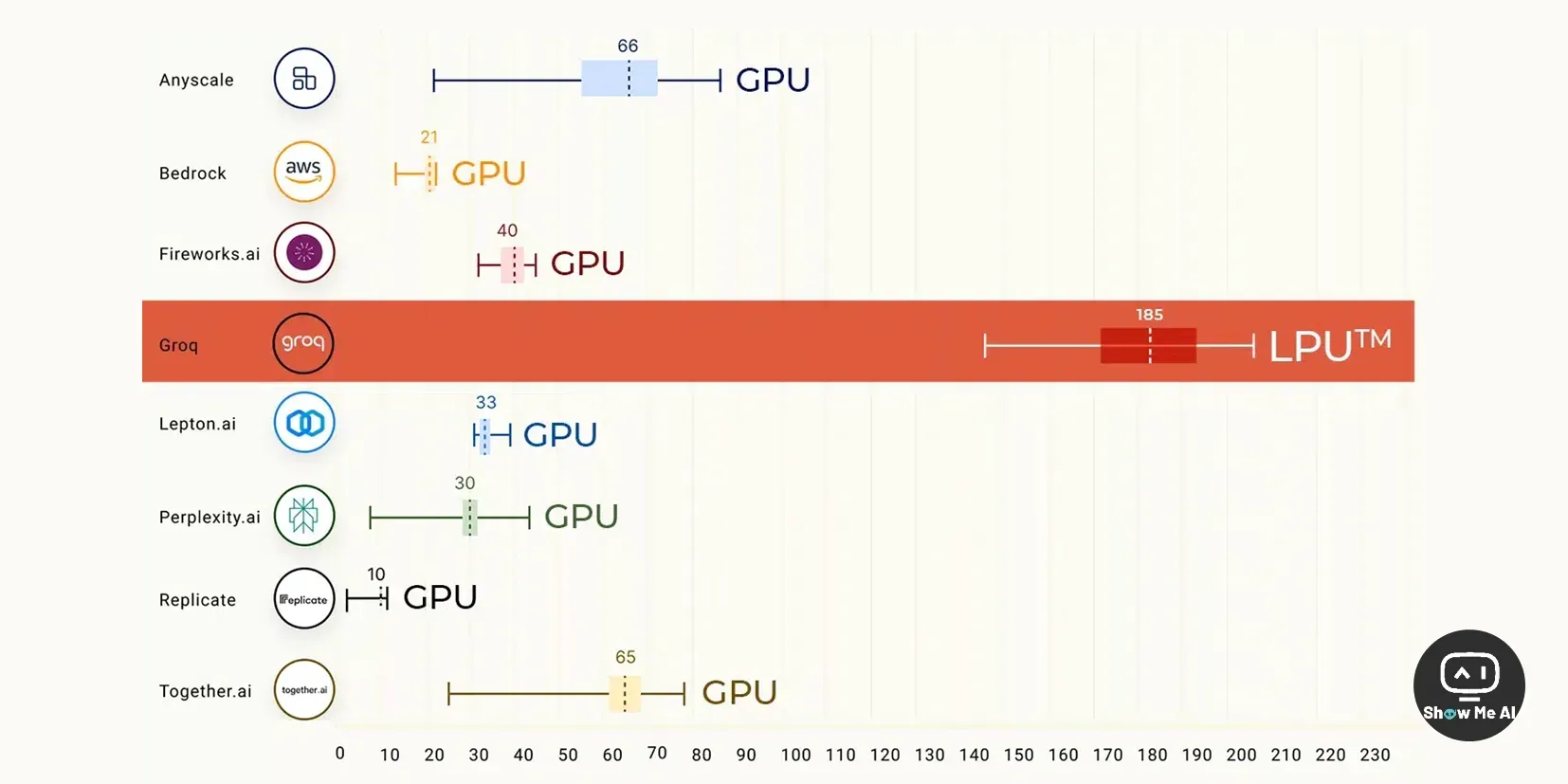
一觉醒来,每秒能输出 500 个 token 的 Groq 模型刷屏全网,堪称「世界上速度最快的LLM」!相比之下,ChatGPT-3.5 每秒生成速度仅为40个 token。
在 Groq 的第一个公开基准测试中 👆,Meta AI 的 Llama 2 70B 在 Groq LPU™ 推理引擎上运行,其输出令牌吞吐量快了 18 倍,优于所有其他基于云的推理提供商。
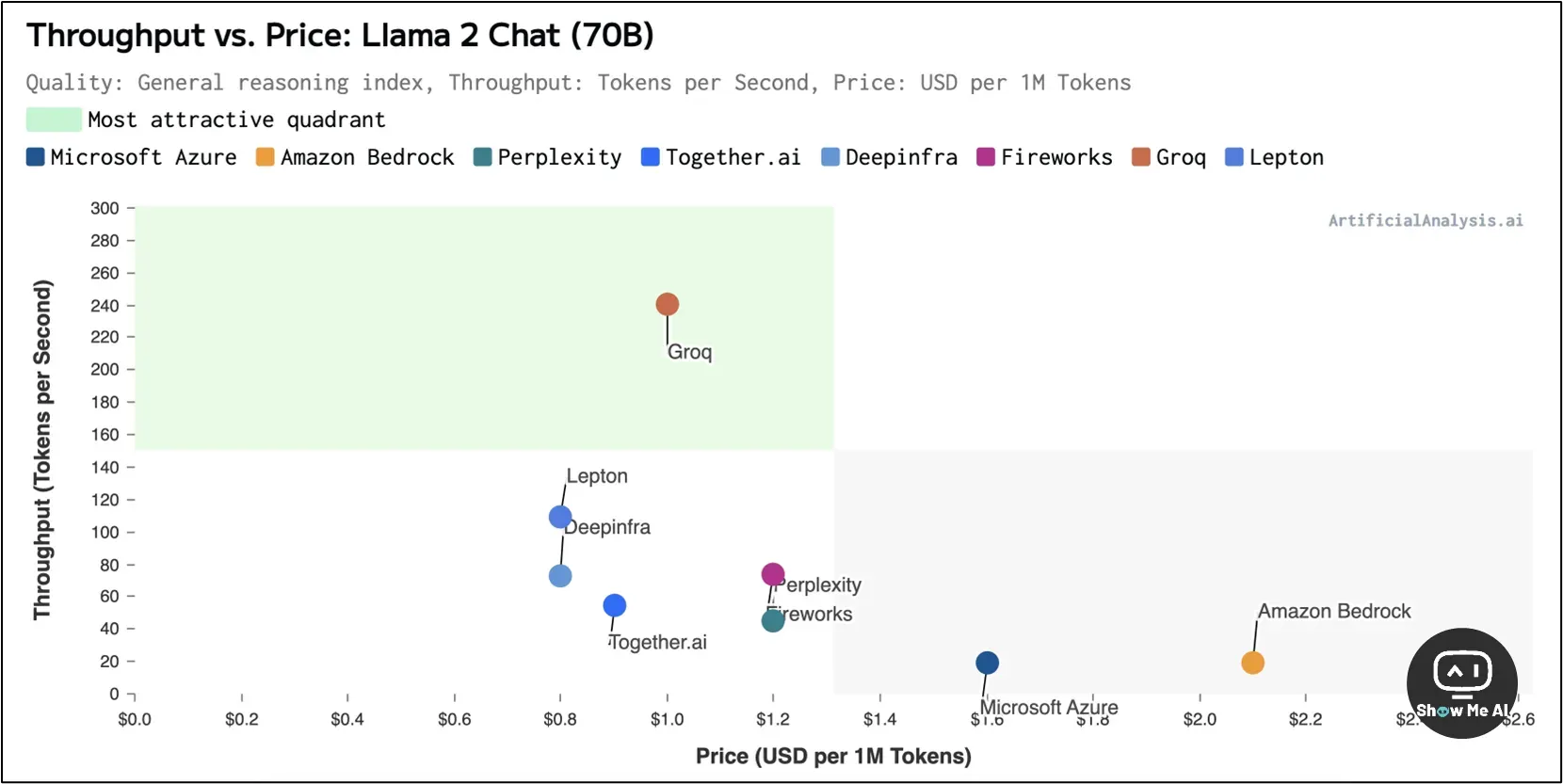
根据 Artificial Analysis 上周公布的第三方测试结果 👆,Groq 每秒能够生成 247 个 token,远远高于微软的 18 个 token。也就是说如果将 ChatGPT 运行在 Groq 芯片之上,其速度将可提高 13 倍有余。
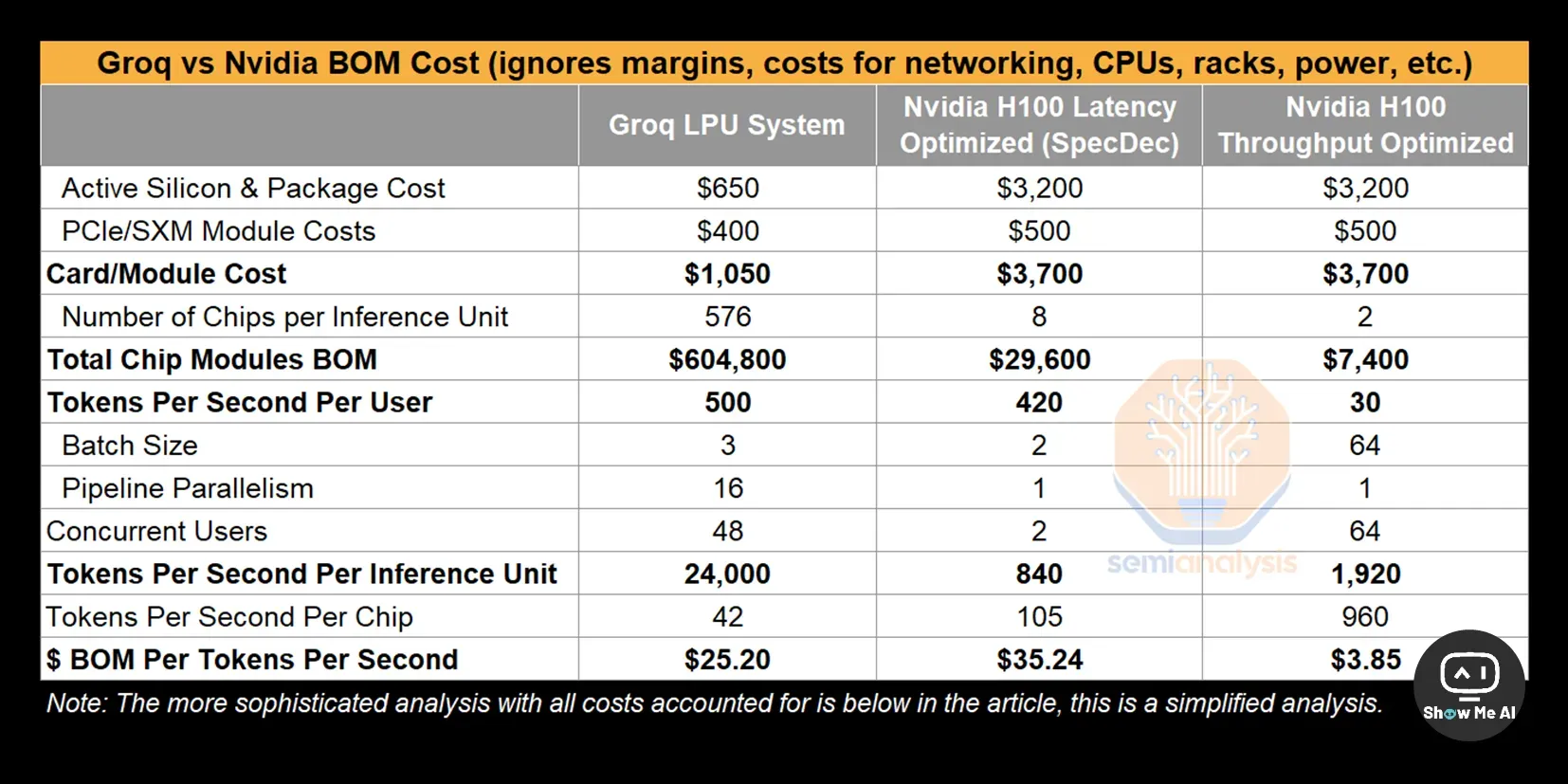
https://www.semianalysis.com/p/groq-inference-tokenomics-speed-but
那么,Groq 真的可以脚踢英伟达,成为AI芯片行业的变革者么?事实显然并不是这么简单。
👆 这篇文章详细分析了 Groq 架构以及由此带来的场景优劣势:Groq 架构建立在小内存、大算力上,因此有限的被处理的内容对应着极高的算力,导致其速度非常快。或者说,Groq 极高的速度是建立在很有限的单卡吞吐能力上的,要保证和 H100同样吞吐量,就需要更多的卡,这极大拉高了 Groq 的使用成本 ⋙ 这篇文章解释得更清晰

贾扬清也发朋友圈进行了粗略且保守的计算,表达了同样的观点。

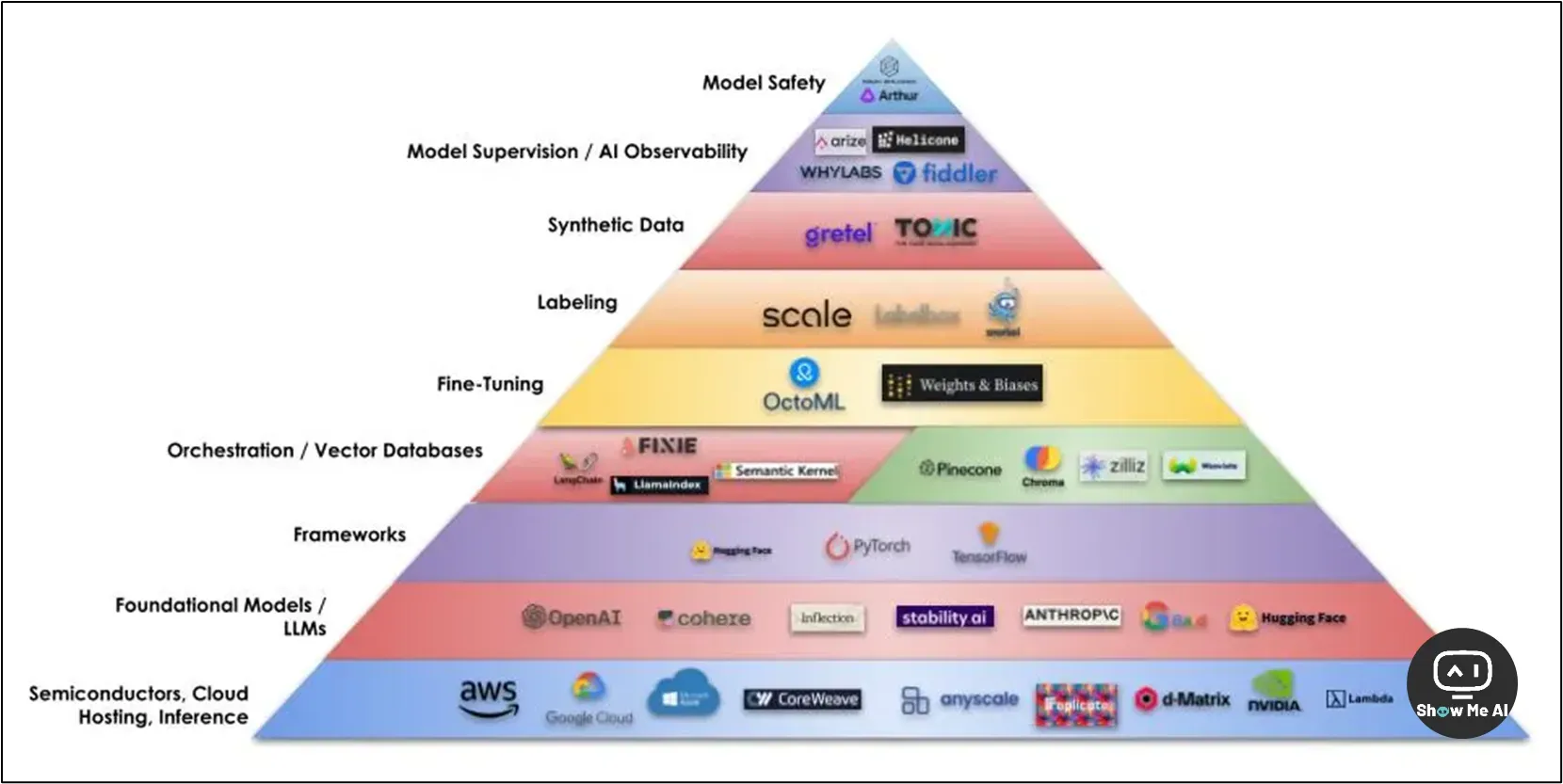
🉑 人工智能基础设施 (AI infra) 行业全景图:是时候将目光放到AI整个产业链了!

这个网站整理了人工智能行业的基础设计生态,将公司或产品分成了6大类17小类,并且点击每个 Logo 可以看到对应公司的详细信息。以下是这份全景图的分类介绍:
网站支持下载高清原图和PDF文件,当前你可以按照管理在咱们的社区和星球获取~
Application Development 应用开发
Observability & Evaluation / 可观察性与评估
IDE & Workspace / 集成开发环境与工作空间
Agent & Prompt Framework / 代理与提示框架
Testing & Debugging / 测试与调试
Orchestration 编排
Workflow & Pipeline / 工作流与流水线
Gateway & Router / 网关与路由器
Data Management 数据管理
Vector Database / 向量数据库
AI in DB / 数据库中的人工智能
ETL & Data Pipeline / 数据提取、转换与加载与数据管道
Runtime 运行时间
Inference & Deployment / 推理与部署
Finetuning & RLHF / 微调与强化学习与人类反馈
Foundation Model 基础模型
LLM / 大型语言模型
Code / 代码
Audio / 音频
Image / 图像
Hardware & Cloud 硬件与云
Cloud Provider / 云服务提供商
GPU / 图形处理单元
https://medium.com/@shriftman/the-building-blocks-of-generative-ai-a75350466a2f
上方网站没有详细介绍各部分的具体功能。如果你有意继续探索,欢迎阅读 👆 这篇文章。写得非常好~
文章作者 Jonathan Shriftman 先后成功孵化并出售两家AI创业公司,对AI行业发展有着独到的洞察能力。他采访了多名业内顶级公司CEO和CTO,并结合自己的官场绘制了这份「生成式AI的基础设施架构」,并在文章内详细介绍了各部分的功能、技术发展路径、有潜力的公司…… ⋙ 生成式AI基础设施堆栈的初学者指南
半导体 / 芯片 / 云托管 / 推理 / 部署 (Semiconductors, Chips, Cloud Hosting, Inference, Deployment):这一层提供了生成式AI所需的计算能力
编排层 / 应用程序框架 (Orchestration Layer / Application Frameworks):这一层中的应用框架可以加速开发流程,帮助开发者将AI模型与不同的数据源进行集成
矢量数据库 (Vector Databases):向量数据库以数字向量的形式存储数据,这种表示方法更有利于机器理解语义信息
微调 (Fine-Tuning):微调过程中,开发者在预训练好的语言模型的基础上,使用特定的任务数据集进行进一步训练,以提升模型在该任务上的表现
数据标记 (Labeling):准确的标注对模型的成功很关键
综合数据 (Synthetic Data):合成数据可以在真实数据不可用时对模型进行训练和测试,同时保护隐私
模型监督 / AI可观测性 (Model Supervision / AI Observability):模型监控可以检测数据偏差、解释模型行为、发现错误模式等,确保模型的行为符合预期
模型安全 (Model Safety):模型安全措施,如偏差检测、对抗测试等,可以降低模型风险,减少无意的后果
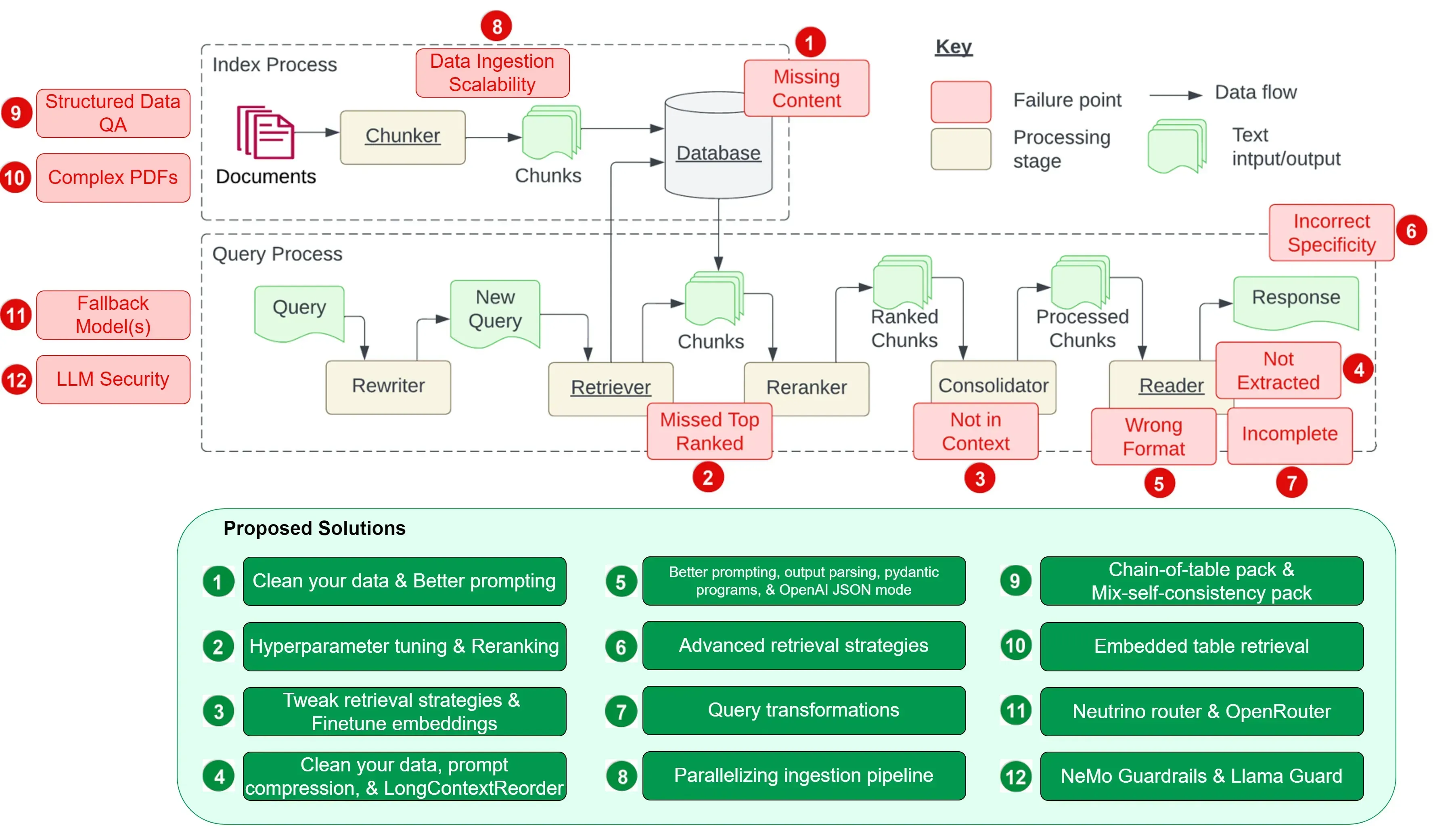
👀 12个 RAG 痛点及解决建议:解决检索增强生成的核心挑战
https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c
这篇文章结合论文与实践经验,整理了12个 RAG 痛点,并给出了每个痛点的一种或多种解决方案,帮助开发者更好地理解和应对 RAG 系统设计和实施中的挑战,从而开发出高质量&可靠的 RAG 系统。
- 内容缺失 (Missing Content)
清理数据:确保输入数据的质量,避免冲突信息
更好的提示:设计提示以鼓励模型在不确定时承认其局限性
- 错排应该靠前的文档 (Missed the Top Ranked Documents)
调整参数:通过调整
chunk_size和similarity_top_k参数来优化检索效率和信息质量重新排名:在将检索结果发送到 LLM 之前,使用如 CohereRerank 等工具进行重新排序
- 脱离上下文 (Not in Context — Consolidation Strategy Limitations)
调整检索策略:使用 LlamaIndex 提供的高级检索策略,如基础检索、高级检索和搜索、自动检索、知识图检索器、组合/分层检索器
微调嵌入:微调开源嵌入模型以提高检索准确性
- 未提取准确答案 (Not Extracted)
清理数据:再次强调数据质量的重要性
即时压缩:使用 LongLLMLingua 等技术在检索步骤后压缩上下文
长上下文重排序:使用 LongContextReorder 等工具重新排序检索到的节点
- 格式错误 (Wrong Format)
更好的提示:通过澄清说明、简化请求、举例说明和迭代提示来改进
输出解析:使用如 Guardrails 和 LangChain 等框架提供的输出解析模块
Pydantic 程序:将输入字符串转换为结构化 Pydantic 对象
OpenAI JSON 模式:设置响应格式为 JSON 对象,强制输出格式
- 具体要求不正确 (Incorrect Specificity)
- 高级检索策略:使用从小到大检索、句子窗口检索、递归检索等策略
- 答案不完整 (Incomplete)
- 查询转换:添加查询理解层,如 HyDE 查询转换技术
- 数据摄取可扩展性 (Data Ingestion Scalability)
- 并行化获取管道:使用 LlamaIndex 的并行处理功能提高文档处理速度
- 结构化数据QA (Structured Data QA)
ChainOfTablePack:使用「链表」概念逐步转换表格
混合自洽包:结合文本和符号推理,通过自我一致性机制聚合结果
- 从复杂 PDF 中提取数据 (Data Extraction from Complex PDFs)
- 嵌入表检索:使用
EmbeddedTablesUnstructuredRetrieverPack,即 LlamaPack 从 HTML 文档中解析嵌入表
- 替代模型 (Fallback Models)
Neutrino 路由器:智能路由查询到最适合的 LLM
OpenRouter:提供统一 API,支持多种 LLM,提供后备方案
- LLM 安全性 (LLM Security)
- Llama Guard:通过提示分类和响应分类来确保内容安全 ⋙ 这篇中文翻译版本很不错

🉑 Runway GEN:48 | 第二届48小时AI短片创作比赛结束!来看看世界最前沿的AI视频创作水平
补充一份背景:Runway 是一款强大的、基于AI的图片&视频编辑工具;GEN:48 是 Runway 举办的一个AI短片创作挑战比赛,今年已经是第二次举办
Runway GEN:48 全称是 Runway GEN 48 Hour Short Film Competition,是一场面向全球的线上创作比赛。比赛主题和创作要求在开赛时宣布,届时参赛者需要在48小时内构思并创作一部 1~4 分钟的电影短片。
今年比赛在2月3日-2月5日举办,官网发布了进入决赛的40部小短片,并通过投票等方式决出了最终获胜的8部作品。
鉴于 Runway 的江湖地位以及 Runway GEN:48 比赛的号召力,决赛入围作品和最终获奖作品在相当程度上代表了当前 AI 视频创作的水平。
国内也有小伙伴报名参赛哦!并且积极分享了参赛攻略和创作心得。普雷尔的茶会 这篇主要介绍赛程设置、题目要求和参与体验,数字生命卡兹克 非常详细地记录了创作过程以及遇到的各种挑战。
Runway GEN:48 第一届比赛结束后,@逗砂 对获奖作品进行了逐帧的解析,包括作品使用的视频生成工具、配音工具、创作技巧等,感兴趣可以看 ⋙ 这篇
两届比赛的获奖作品对照着看,可以看到最近一年的技术、产品和创作水平都发展神速哇 😎

🉑 魔搭社区「七天入门LLM大模型」课程:带你从0基础到亲自完成一个AI应用

过年期间,ModelScope魔搭社区推出的了一门为期7天的大模型带学课程,旨在帮助初学者理解和学习 LLM 的基础概念和实践。
看了一下课程视频 👆,是前段时间在西安交通大学举办的主题训练营录屏,全部视频7个多小时,内容体系覆盖得比较完整。ModelScope 魔搭公众号还整理了视频重点内容的文字版,可以搭配着一起看。
第一天:魔搭社区和LLM大模型基础知识
魔搭LLM大模型开源生态图:基础模型研究、模型定制新范式
LLM类型介绍:Base 模型和 Chat 模型、多模态模型、Agent 模型、Code 模型
使用LLM及优化LLM输出效果:模型推理、Prompt (提示词)、few-shot prompt、LLM+RAG、模型微调、模型量化、模型评估、模型推理加速和部署、模型应用-Agent ⋙
第一天·文字说明
第二天:提示词工程-Prompt Engineering
LLM的超参配置
Prompt Engineering:System message 系统指令、用户提示词 (user prompt)
Agent 最佳实践案例:使用 prompt 实现 agent create、使用 system message+prompt 实现 function call
写好 Prompt 的一些原则
优质的提示词典型框架 ⋙ 第二天·文字说明
第三天:LLM和多模态模型高效推理实践
多模态大模型推理:LLM 的推理流程、多模态的 LLM 的原理
vLLM+FastChat 高效推理实战
多端部署实战
LLM的应用场景:RAGt ⋙ 第三天·文字说明
第四天:大模型微调技术解析和实战
总览介绍:模型/训练/推理、预训练范式、如何确定自己的模型需要做什么训练、模型推理的一般过程、PyTorch框架、设备、PyTorch基本训练代码范例
Transformer结构:Transformer 对比 CNN 和 LSTM、Encoder 和 Decoder、RMSNorm、RoPE、SwiGLU、GQA、ChatGLM2的模型结构
数据的预处理:分词器 (Tokenizer)、模板 (Template)
选择适合自己的方法和模型:方法选型、方法选型
指令微调:微调 (Supervised Finetuning)、重要概念、分布式训练 (Distributed Training) ⋙ 第四天·文字说明
第五天:大模型自动评估理论和实战
LLM评估的方法论:如何评估一个 LLM、自动评估方法、LLM 评估面临的问题和挑战
LLM评估实战:LLMuses 自动评测框架介绍、基于客观题 benchmark 自动评估、基于专家模型的自动评估、LLM 推理性能评估 ⋙ 第五天·文字说明
第六天:大模型量化及低成本部署最佳实践
模型的量化:量化是什么、AutoGPTQ、GGML、AWQ
推理部署:推理及部署、一些推理方法、重要推理超参数、KVCache、VLLM、SWIFT、llama.cpp、FastChat ⋙ 第六天·文字说明
第七天:来,亲手做一个A应用!
目前最好用的AI应用有哪些?
基于AI模型可以做什么应用?
如何走出AI应用创建的第一步?
如何提升AI应用的使用体验?
你也可以做出好用的AI应用! ⋙ 第七天·文字说明
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 👀日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 🎡生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!
版权声明:本文为博主作者:ShowMeAI原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/ShowMeAI/article/details/136245014