简介:研一已经结束,感觉动手能力太差,找了一篇优秀的博主的文章,然后进行学习,奈何
科研小白,代码经过各种查找,终于明白了原理。
在此先感谢博主"秋雨行舟",他还有B站对应的讲解,贼良心的一位博主!!
链接:https://blog.csdn.net/qq_38918049/article/details/124992113?spm=1001.2014.3001.5501
对博主中的代码做了稍许修改,添加了大量注释,以此篇博客记录学习过程中的收获。
数据集:凯斯西储实验室的轴承故障诊断(振动加速度采集的)和我的研究对象很很相似,都是一维时间序列的目标,所以拿来练手。
平台:jupyter notebook,把每一行代码所表述的意思完全展示出来了,更加容易理解代码执行过程,相较于pyhcarm更加友好,对跑神经网络,因为能够直观的看到运行过程。
环境:win10,tensorflow2.1(感觉深度学习,版本可以不要太高,要不然很多不兼容,整着好麻烦,我就是从tensorflow版本2.5降到了2.1,目前为止用的还可以,可能以后还有升级,,,)。
代码介绍:从10个.mat文件中经过一系列数据处理(内容是真滴丰富)分为1500个(784,1)的训练集和750个(784,1)的验证集和测试集,搭建CNN模型(函数式)进行训练,通过测试集进行评估。
代码获取:可以从“秋雨行舟”博主上去找资源,也可以找我啊,我基本上把每行代码都注释了,也欢迎研究一维时间序列目标检测,目标识别的小伙伴一块组队学习啊!
目录
一.数据预处理
1.1 从.mat文件中读取数据的字典
# 定义函数把原始数据打包成字典
def capture(original_path):
files = {}
for i in filenames:
file_path = os.path.join(d_path, i)
file = loadmat(file_path) # loadmat()加载.mat函数
file_keys = file.keys() # 获取加载后的.mat文件的键值,也就是‘12k_Drive_End_B007_0_118.mat’这种
for key in file_keys: # 获取所有文件中结构体中含有字符为DE的数据,并将数据写入字典中
if 'DE' in key: # 这个地方‘DE’在这组数据中都有‘Drive_End’所以相当于遍历了,如果是凯斯西储实验室的其他几组数据,要换一下
files[i] = file[key].ravel() # 转换为一维数组
return files
data = capture(original_path=d_path)
data1.2划分训练集和测试集
# 定义参数
rate = [0.5, 0.25, 0.25] # 训练集,测试集,验证集划分比例(测试集和验证集这个步骤在一块)
number = 300 # 每类样本的数量
length = 784 # 样本长度
# 定义划分训练集和测试集的函数
def slice_enc(data, slice_rate=rate[1] + rate[2]):
keys = data.keys()
Train_Samples = {}
Test_Samples = {}
for i in keys:
slice_data = data[i] # 遍历到.mat字典的每个值,也就是data的array部分(用键去遍历)
all_lenght = len(slice_data)
# end_index = int(all_lenght * (1 - slice_rate)) # 感觉这个被山区的注释这一行才对啊,能理解
# 下面是每个.mat数据中的value部分拿出一半做训练集的一部分
samp_train = int(number * (1 - slice_rate)) # 1000(1-0.3) # 不明白这个地方的备注(1000(1-0.3)) 不应该是300*(1-0.5)?
Train_sample = []
Test_Sample = []
# 抓取训练数据放到训练集中
for j in range(samp_train): # (遍历150次)
# 每个.mat数据的训练集的长度
sample = slice_data[j*150: j*150 + length] # (0:784) 也就是每个训练数据为(784,1)
Train_sample.append(sample) # 把每个做训练的部分放到训练集中
# 抓取测试数据
for h in range(number - samp_train): # (遍历150次)
sample = slice_data[samp_train*150 + length + h*150: samp_train*150 + length + h*150 + length] # 每条测试数据为(784,1)
Test_Sample.append(sample) # 把每个做测试的部分放到测试集中
# 遍历的每条数据把划分的训练数据,测试数据放到对应集合中
Train_Samples[i] = Train_sample
Test_Samples[i] = Test_Sample
return Train_Samples, Test_Samples
train,test = slice_enc(data)# 每个.mat数据划分为多少个训练字段,
# 所以总共10个原始数据,每个原始数据划分为150个训练字段
for i in train.keys():
a = train[i]
len(a)
print(len(a))
[out]:
150
150
150
150
150
150
150
150
150
150
1.3训练集,测试集打标签
# 定义添加标签的函数
def add_labels(train_test):
X =[]
Y = []
label = 0
for i in filenames: # 遍历每个.mat数据,(i=0,第一个mat数据中的150条训练数据的标签设为0)
x = train_test[i]
X += x
lenx = len(x)
Y += [label] *lenx
label +=1
return X,Y
# 为训练集制作标签
Train_X ,Train_Y = add_labels(train)
# Train_X,Train_Y中1500条训练数据,每150条训练数据对应一个标签,有0-9个10个不同的标签类型
1.4数据标准化并把测试集再分为测试集和验证集
# 定义标准化函数
def scalar_stand(Train_X, Test_X):
# 用训练集标准差标准化训练集以及测试集
data_all = np.vstack((Train_X, Test_X)) # 数据降为一维平铺
scalar = preprocessing.StandardScaler().fit(data_all) # sklearn.preprcoessing包下的数据标准化函数
Train_X = scalar.transform(Train_X) #调用 .transform函数对数据进行标准化
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
# 测试集再分为测试集和验证集(比例1:1)
def valid_test_slice(Test_X, Test_Y):
test_size = rate[2] / (rate[1] + rate[2])
# n_splits=1,将其分成一组也就是两部分,test_size每组的比例
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size) # 拿出一半做测试集,一半做验证集(test_size=0.5)
Test_Y = np.asarray(Test_Y, dtype=np.int32) # 更新Test_Y
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index] # 把验证集和训练集对应
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
normal = True # 是否标准化
# 执行标准化
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
Train_X = np.asarray(Train_X) # 经过方法np.asarray(x)得到最新的x
Test_X = np.asarray(Test_X)
# 把测试集拿出一半做验证集
Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)二.搭建1DCNN模型
2.1 数据处理
2.2 定义一个保存最佳模型的方法
# 保存最佳模型
class CustomModelCheckpoint(keras.callbacks.Callback):# 使用回调函数来观察训练过程中网络内部的状态和统计信息r然后选取最佳的进行保存
def __init__(self, model, path): # (自定义初始化)
self.model = model
self.path = path
self.best_loss = np.inf # np.inf 表示+∞,是没有确切的数值的,类型为浮点型 自定义最佳损失数值
def on_epoch_end(self, epoch, logs=None): # on_epoch_end(self, epoch, logs=None)在每次迭代训练结束时调用。在不同的方法中这个logs有不同的键值
val_loss = logs['val_loss'] # logs是一个字典对象directory;
if val_loss < self.best_loss:
print("\nValidation loss decreased from {} to {}, saving model".format(self.best_loss, val_loss))
self.model.save_weights(self.path, overwrite=True) # overwrite=True覆盖原有文件 # 此处为保存权重没有保存整个模型
self.best_loss = val_loss2.3 搭建模型
# 搭建模型框架(函数式API方法)
def mymodel():
inputs = keras.Input(shape=(Train_X.shape[1],Train_X.shape[2]))# ([1500, 784, 1])把【784,1】传入输入层,没看数据处理时,还不知道为啥这样传
h1= layers.Conv1D(filters=8,kernel_size=3,strides=1,padding='same',activation='relu')(inputs)
h1 = layers.MaxPool1D(pool_size=2,strides=2,padding='same')(h1)
h2 = layers.Conv1D(filters=16,kernel_size=3,strides=1,padding='same')(h1)
h2 = layers.MaxPool1D(pool_size=2,strides=2,padding='same')(h2)
h3 = layers.Flatten()(h2) # 扁平层,方便全连接层传入数据
h4 = layers.Dropout(0.6)(h3) # Droupt层舍弃百分之60的神经元
h5 = layers.Dense(32,activation='relu')(h4) # 全连接层,输出为32
outputs = layers.Dense(10,activation='softmax')(h5) # 再来个全连接层,分类结果为10种(9种故障类型,1种正常的)
# 不要出现中文,,,,,,血泪教训,最开始把1DCNN模型,有模型二字,导致编译出错,一顿爆改!
deep_model = keras.Model(inputs,outputs,name = '1DCNN') # 整合每个层,搭建1DCNN模型成功
return deep_model
2.4 编译模型
# 编译模型,(优化器:Adam,损失函数:sparse_categorical_crossentropy)
model.compile(
optimizer=keras.optimizers.Adam(),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])2.5训练模型并保存
history = model.fit(Train_X, Train_Y,
batch_size=256, epochs=50, verbose=1,
validation_data=(Valid_X, Valid_Y),
callbacks=[CustomModelCheckpoint(
model, r'mybestcnn.h5')]) # verbose=1带进度条的输出日志信息 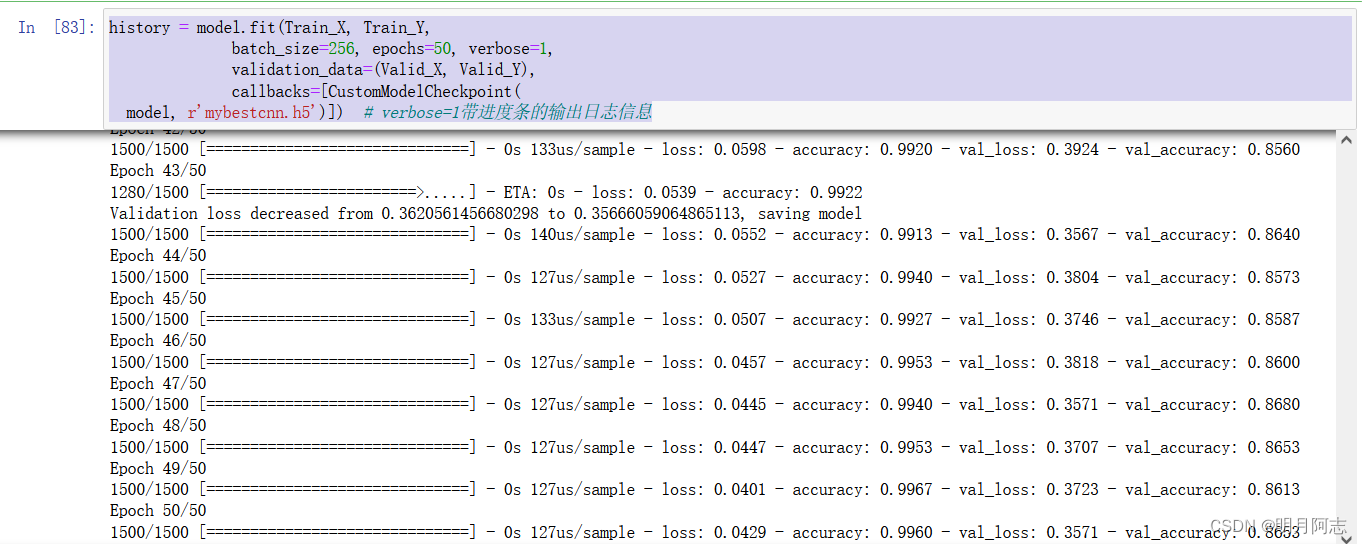
2.6效果展示(损失,精确对比)
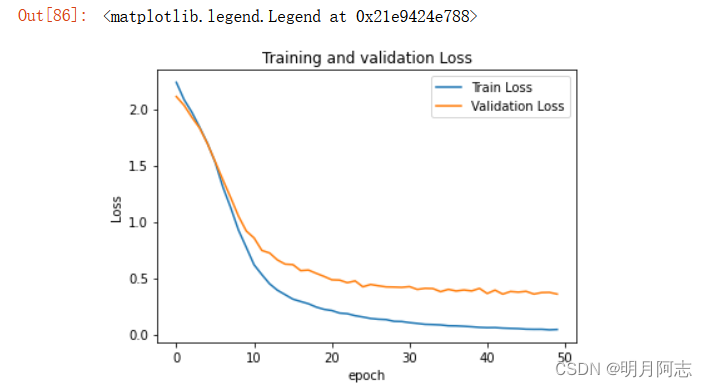
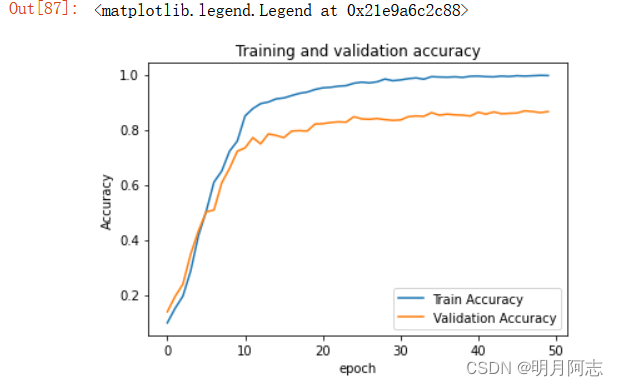
三.评估模型
四.混淆矩阵
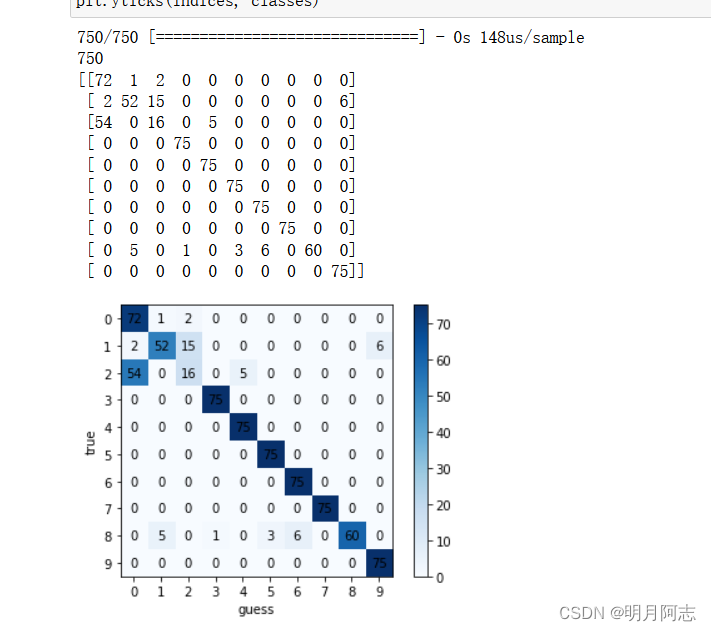
五.总结
第一次完整的看完一篇代码,权当入门起步!,因为版本和环境的问题,把代码从pycharm转到jupyter,着实费了了我好大力,一行一行代码去百度,最后才完成,遇到很多困难,但解决掉BUG的时候真滴酸爽!!!!!!!!
文章出处登录后可见!