
背景
我开始关注这个问题,是在使用 PaddleOCR + OpenCV 进行视频文字识别的时候,因为OpenCV 需要循环读取视频的每一帧进行解析,这就导致视频播放特别卡顿。由于视频中相邻帧的内容是一样的,重复识别也没有意义,所以我就在考虑:有没有办法跳帧输出?
咱们能想到的所有问题,都已经被设计师考虑过了,需要用到下面两个函数:
- cv2.VideoCapture.grab()
- cv2.VideoCapture.get()
你可能需要用到的文章:
正文
一、核心方法
1. cv2.VideoCapture.grab() 函数
# 视屏获取,videoPath为视频的路径
cap = cv2.VideoCapture(videoPath)
# 往下读一帧ret,并返回图片信息frame
ret, frame = cap.read()
# 只往下读一帧ret
ret = cap.grad()- read()函数,输出的是两个参数:第一个参数 ret 为 True 或 False,代表有没有读取下一到帧图片;第二个参数 frame,表示读到的一帧图片的信息,OCR就是对 frame 进行识别处理。
- grad()函数,输出的是一个参数:ret 为 True 或 False,代表有没有读取下一到帧图片。
从上面的对比可以看出来,grab() 仅仅是用来指向下一帧,并没有返回多余的图片信息,当不需要解析图片的时候,grab() 函数显然效率更高,更合适。
2. cv2.VideoCapture.get() 函数
cv2.VideoCapture.get(n) ,n 的范围是 0~7,这个方法可以帮助我们获取视频的属性。其中我们用到的就是 get(1) – 获取视频当前帧,可以方便我们做跳帧操作。
总结了一下:
| 方法 | 含义 |
|---|---|
| cv2.VideoCapture.get(0) | 视频文件的当前位置(播放)以毫秒为单位 |
| cv2.VideoCapture.get(1) | 当前帧,基于以0开始的被捕获或解码的帧索引 |
| cv2.VideoCapture.get(2) | 视频文件的相对位置(播放):0 = 电影开始,1 = 影片的结尾。 |
| cv2.VideoCapture.get(3) | 在视频流的帧的宽度 |
| cv2.VideoCapture.get(4) | 在视频流的帧的高度 |
| cv2.VideoCapture.get(5) | 帧率 |
| cv2.VideoCapture.get(6) | 编解码的4字 – 字符代码 |
| cv2.VideoCapture.get(7) | 视频文件中的帧数 |
除此之外,还可以用另外几个方法获取视频属性:
- cv2.VideoCapture.get(cv2.CAP_PROP_FPS):获取帧率;
- cv2.VideoCapture.get(cv2.CAP_PROP_FRAME_COUNT):获取视频时长,单位- 秒。
二、实战练习
1. 代码展示
我这里设置的是每间隔10帧输出一次,大家可以根据自己的需要设置,代码如下:
- get(1) 获取当前帧率跳帧
# _*_coding:utf-8_*_
# 作者: Java Punk
# 时间: 2022-10-09 14:49:45
# 功能: 场景文字识别
import cv2
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
import numpy as np
def ch_match(videoPath):
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
# 视屏获取
cap = cv2.VideoCapture(videoPath)
# 判断是否正常打开
ret = cap.isOpened()
# 循环读取视频帧
while ret:
# 获取当前视频帧位置
now_fps = cap.get(1)
# 设置每 10 帧输出一次
if (now_fps % 10 != 0):
# 跳帧
ret = cap.grab()
continue
print("———————————————————— read fps", now_fps)
# 是否截取到图片;图片信息
ret, frame = cap.read()
# 对返回的图片进行文字识别
result = ocr.ocr(frame, cls=True, rec=True)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
# simsun.ttc 是一款很常见、实用的电脑字体,这里作为识别的模板
im_show = draw_ocr(frame, boxes, txts, scores, font_path='../fonts/SIMSUN.TTC')
im_show = Image.fromarray(im_show)
tp_img = np.asarray(im_show)
cv2.imshow('tp_img', tp_img)
cv2.waitKey(1)
pass
cv2.waitKey(0)
cv2.destroyAllWindows()
pass
if __name__ == '__main__':
print("———————————————————— start ————————————————————\n")
# 图片路径自己设置,下面是我本地的路径,记得替换!!!
ch_match('../img/yz_words/vlog_zxyw_02.mp4')
print("———————————————————— end ————————————————————\n")-
改动一下:记录帧率进行跳帧
实际上每一次视频的 while 循环,都是往下走了一帧,所以我们也可以取巧的利用 i++ 进行跳帧,此时 i = cv2.VideoCapture.get(1)。
...
# 视频帧计数
timeC = 0
# 循环读取视频帧
while ret:
timeC = timeC + 1
# 每隔 10 帧进行操作
if (timeC % 10 != 0):
ret = cap.grab()
continue
...2. 效果展示
感兴趣的小伙伴可以把跳帧部分的代码去掉看看效果,对比一下,说下我用公司电脑测试的结果:
- 执行跳帧前:原视频时长7s,最后 cv2.imshow() 时长 2min;
- 执行跳帧后:原视频时长7s,最后 cv2.imshow() 时长 20s;
下面是“执行跳帧后”的效果(由于上传大小限制,无奈只能降低画质):
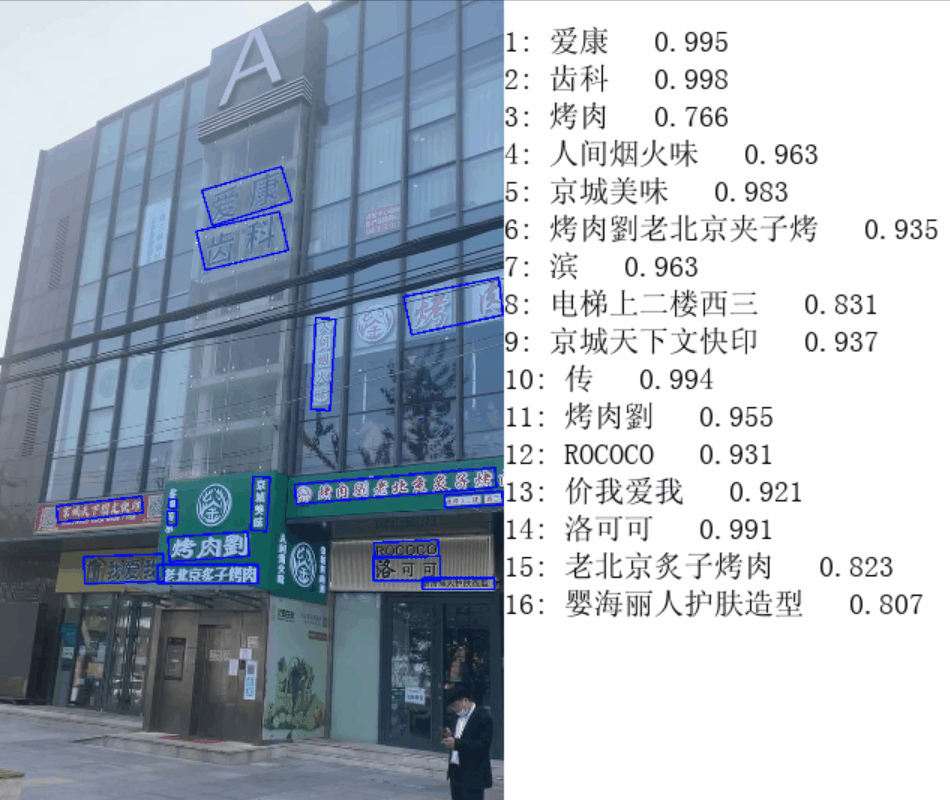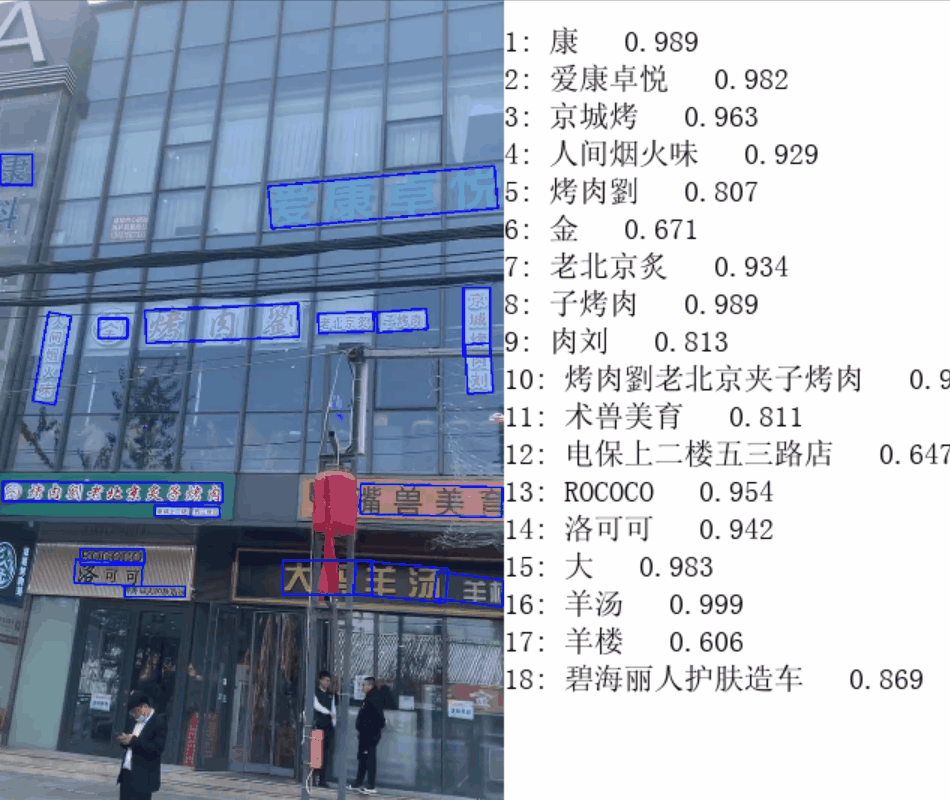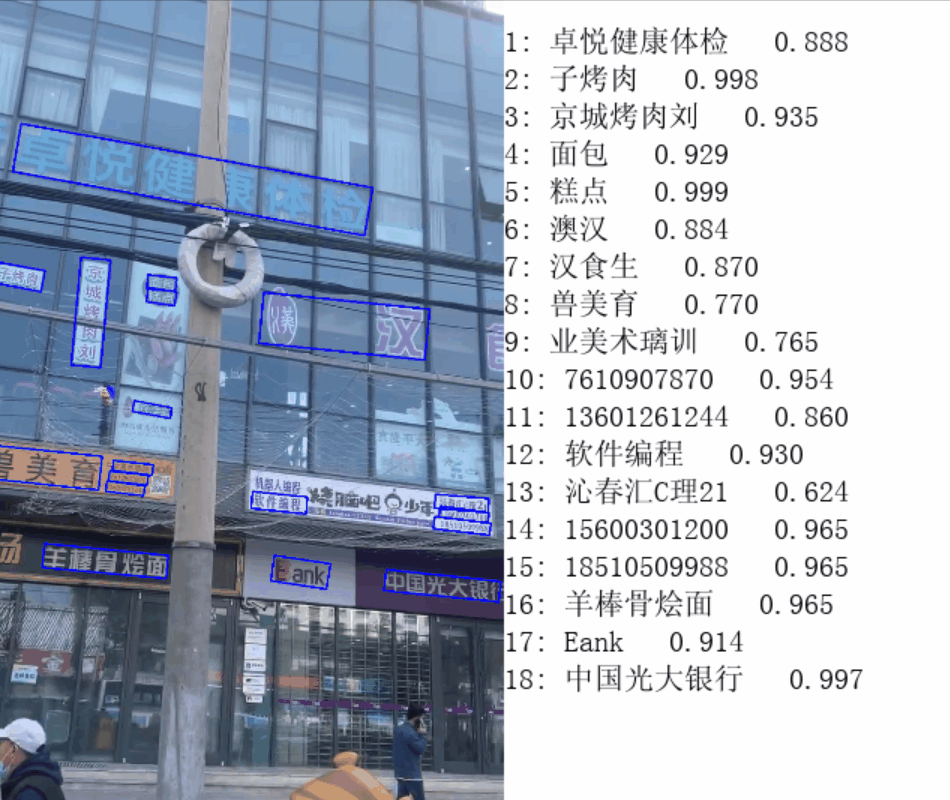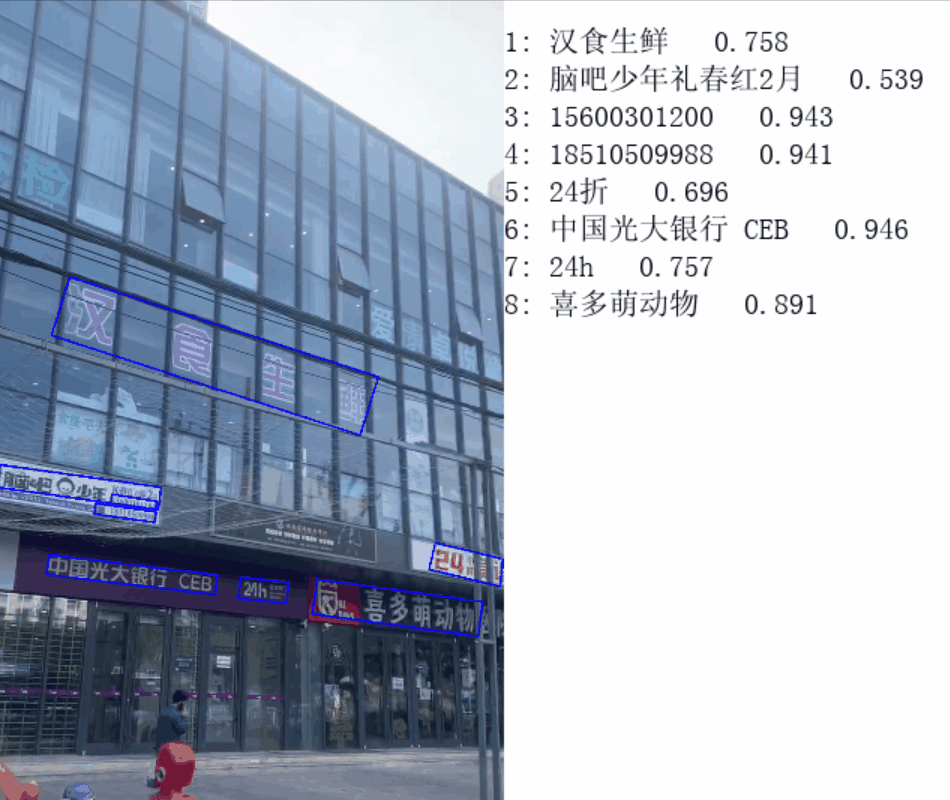
文章出处登录后可见!
已经登录?立即刷新