2017 年 12 月左右,发表了一篇题为“Attention Is All You Need”的开创性论文。这篇论文彻底改变了 NLP 领域在未来时代的面貌。本文描述了转换器和所谓的序列到序列架构。
序列到序列(或 Seq2Seq)神经网络是一种将一个组件序列转换为另一个序列的神经网络,例如短语中的单词。(考虑到这个名字,这应该不足为奇。)
Seq2Seq 模型 擅长翻译,这涉及将一系列单词从一种语言转换为另一种语言的一系列其他单词。基于长短期记忆 (LSTM) 的神经网络架构被认为最适合序列到序列的需求。LSTM 模型有一个遗忘门的 概念,通过它它也可以忘记不需要记住的信息。
什么是 Seq2Seq 神经网络?
Seq2Seq 模型是以一系列对象 (例如单词、字母或时间序列)开始并生成另一个项目序列作为其输出的模型。当涉及到神经机器翻译时,我们需要提供特定语言的输入句子,而输出应该是另一种语言的翻译文本。
如图2-1所示,基于 Seq2Seq 架构的神经网络以单词learn作为输入,输出单词的法语翻译。
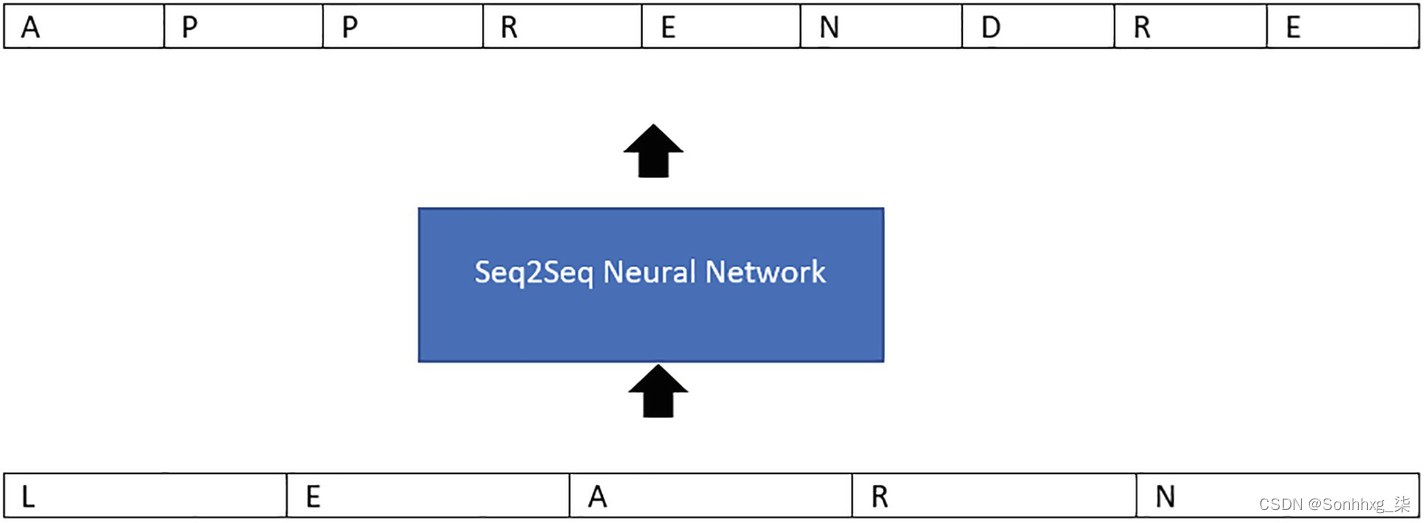
图 2-1 Seq2Seq网络的功能
编码器 和解码器 是构成模型的两个组件,如图2-2所示。输入序列的上下文由编码器以向量的形式保存,然后将其传输给解码器,以便解码器可以根据它包含的信息构造输出序列。
编码器和解码器的架构主要表现为用于序列到序列任务的 RNN、LSTM 或 GRU。
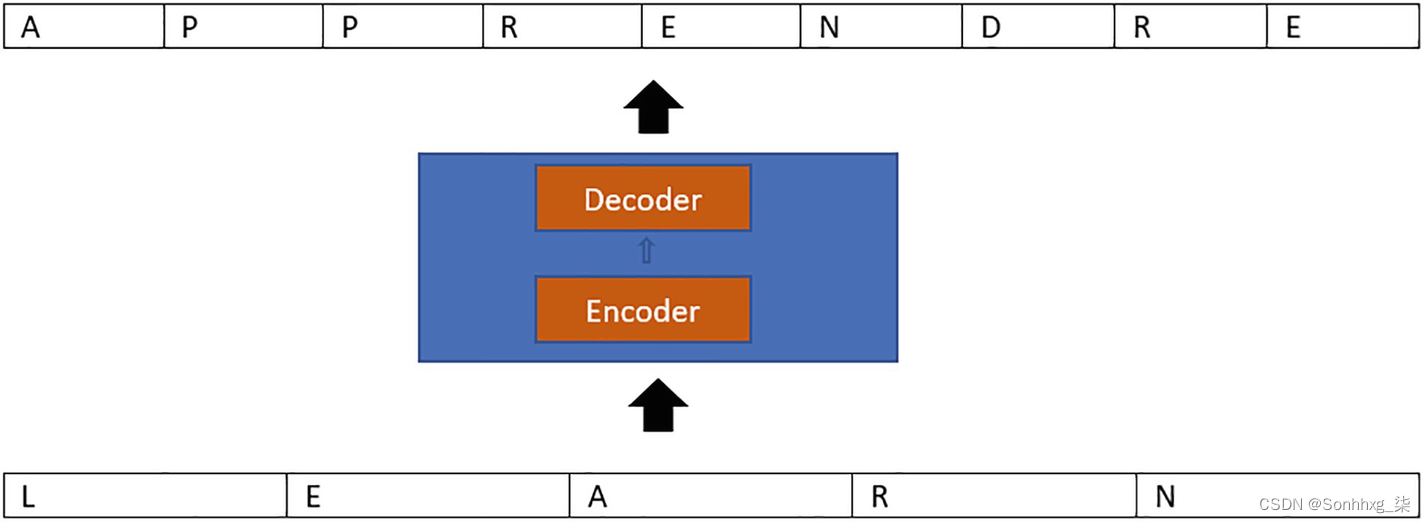
图 2-2 Seq2Seq 网络中编码器-解码器的使用
图2-2解释了编码器和解码器如何适应翻译任务的 Seq2Seq 架构。
我们不会详细介绍 Seq2Seq 架构,因为这本书主要是关于转换器的。但是要理解 Seq2Seq 模型的本质,他们将一个序列作为输入并将其转换为另一个序列。
The Transformer
正如本章开头所讨论的,有一篇名为“Attention Is All You Need”的伟大论文,其中提出了一种称为 transformer 的新神经架构。这项工作的主要亮点是一种称为self-attention 的机制。transformer架构 的idea之一是为了摆脱我们一次一个地向网络提供输入的顺序处理。例如,在句子的情况下,RNN 或 LSTM 将从句子中一次输入一个单词。这意味着处理将只是顺序的。Transformers 打算通过一次性将整个序列作为输入提供给网络并允许网络一次学习一个完整的句子来改变这种设计。这将允许进行并行处理,并允许将学习并行地分发到其他内核或 GPU。
Transformer架构 的要点是仅使用自注意力来捕获序列中单词之间的依赖关系,而不依赖于任何基于 RNN 或 LSTM 的方法。
Transformers
变压器的高级架构 如下所示。它由两个主要部分组成:
编码器
解码器
图2-3显示了包含编码器和解码器块的转换器架构。
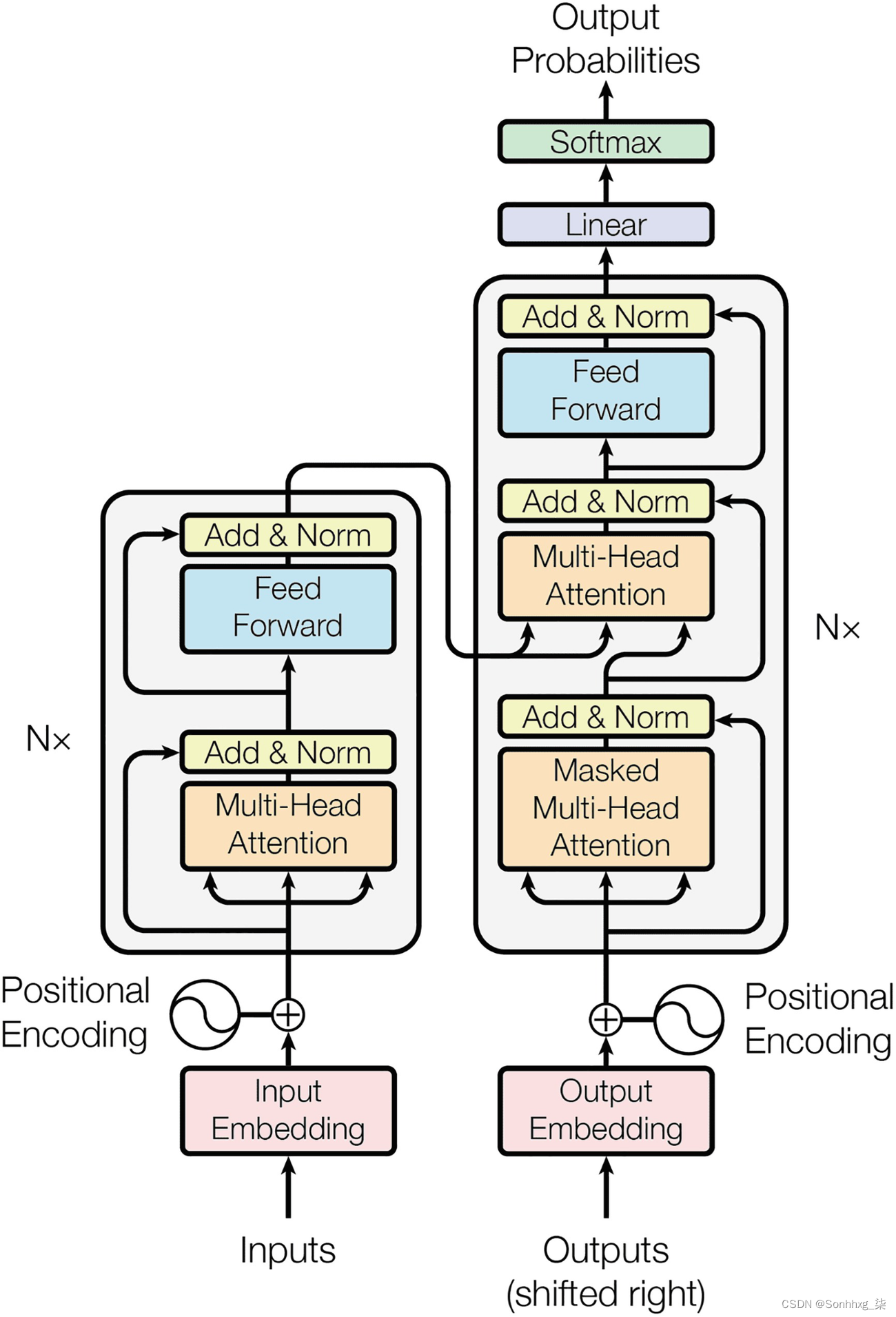
图 2-3 高级 transformer架构 (取自 Vaswani 的“Attention Is All You Need”论文)
编码器
让我们详细看看编码器的各个层。
输入嵌入
必须做 的第一件事是将输入提供给一个进行词嵌入的层。将词嵌入层视为查找表的一种方法,它允许获取每个词的学习向量表示。神经网络中的学习过程基于数字,这意味着每个词都与一个向量相关联,该向量具有表示该词的连续值。
在应用自注意力之前,我们需要将句子中的单词标记为单个标记。
Tokenize
图2-4显示了句子的标记化 过程,其中句子的每个单词都被标记化。

图 2-4 句子中的词标记化
矢量化
标记化后,我们将之前通过使用 word2vec 或 GloVe 编码获得的标记向量化。现在每个单词都将表示为一个向量,如图2-5所示。
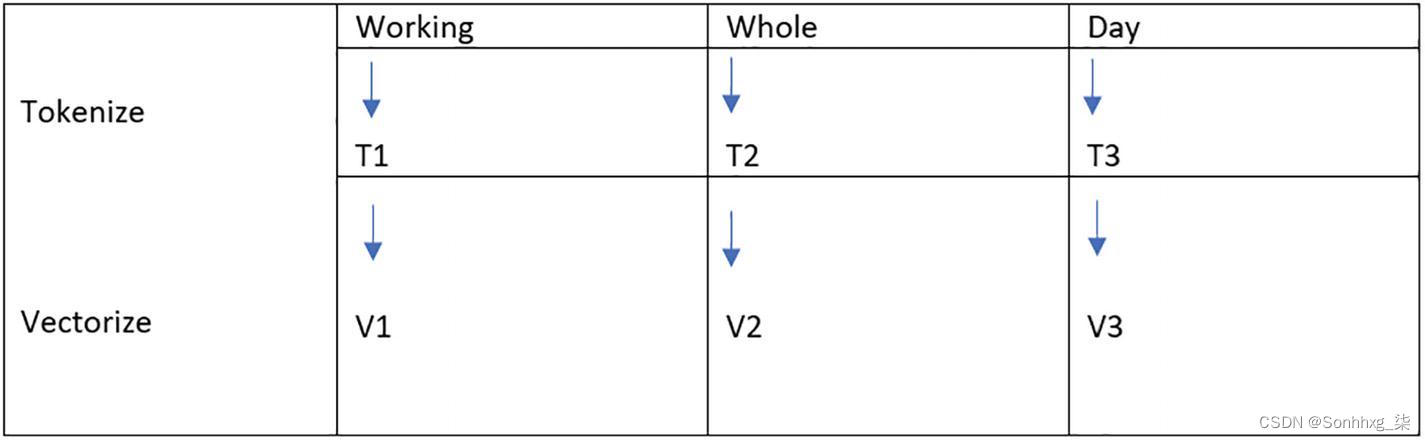
图 2-5 单独矢量化每个标记以创建单词的数学表示
位置编码
它是一种基于特定单词位置的编码,例如,在句子中。
此编码 基于文本在序列中的位置。我们需要提供一些关于输入嵌入位置的信息,因为 transformer 编码器不像递归神经网络那样具有递归性。位置编码就是用来实现这个目标的。作者构思了一种利用正弦和余弦函数的巧妙策略。
位置编码 的数学表示如公式 2-1 所示:
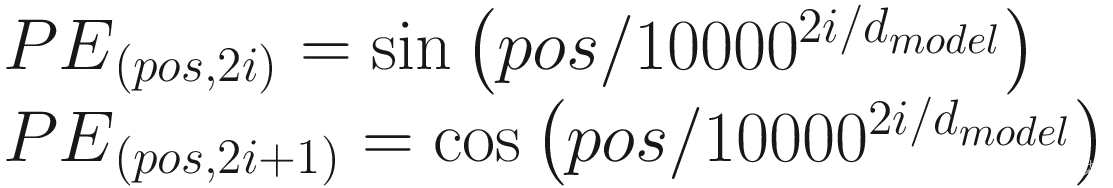
(公式 2-1)
该等式计算每个词的位置嵌入 ,以便每个词在语义成分旁边都有一个位置成分。
位置编码的数学细节不在本讨论范围之内;然而,基本原理如下。
如公式 2-1 所示,我们通过余弦函数在奇数索引处传递单词,在偶数索引处通过正弦函数传递单词。每个单词的输出将是一个向量,表示特定单词的位置编码。我们在下面通过一个例子来解释这一点。
位置编码示例
拿一个序列来说,“Sam loves to walk.”
在这里,首先我们定义一些参数的值:
N:10000。
K:单词在句子中的位置 ,从 0 开始。
D:句子的维度。在我们的例子中是 4。
I:用于映射到列索引。
现在我们计算正弦和余弦分量的值。
Sam
sin(0/10000 (0/4))=0 | cos(0/10000 (0/4))= 1 | sin(0/10000 (2/4))=0 | cos(0/10000 (2/4))= 1 |
Likes
sin(1/10000 (0/4) )=0.8414 | cos(1/10000 (0/4))=0.5403 | sin(1/10000 (2/4) )=0.0099 | cos(1/10000 (2/4) )=0.999 |
To
sin(2/10000 (0/4) )=0.909 | cos(2/10000 (0/4) )=-0.416 | sin(2/10000 (2/4) )=0.0199 | cos(2/10000 (2/4) )=0.9998 |
Walk
sin(3/10000 (0/4) )=0.1411 | cos(3/10000 (0/4) )=-0.989 | sin(3/10000 (2/4) )=0.0299 | cos(3/10000 (2/4) )=0.9995 |
我们可以看到句子 “Sam likes to walk”中的每个词是如何得到一个词嵌入向量来表示该词在句子中的位置的。
之后,将这些向量添加到与这些向量 对应的输入嵌入中。将位置嵌入添加到输入嵌入背后的直觉是让每个单词在向量空间中向单词出现的位置发生小的偏移。因此,如果我们多考虑一下,我们可以看到这会导致语义相似的单词发生在附近的位置,在向量空间中被表示为附近。因此,网络提供了有关每个矢量位置的准确信息。由于它们的线性特性以及模型可能很容易学会关注它们,因此同时选择了正弦和余弦函数。
至此,我们已经到达了编码器层,也如图2-6所示。编码器层的目标是将所有输入序列转换为一种表示形式,该表示形式可以捕获 上下文,同时在特定上下文中更加关注对它来说更重要的单词。它从一个多头注意力子模块 开始,然后移动到一个完全连接的网络子模块。最后,这之后是一层规范化。
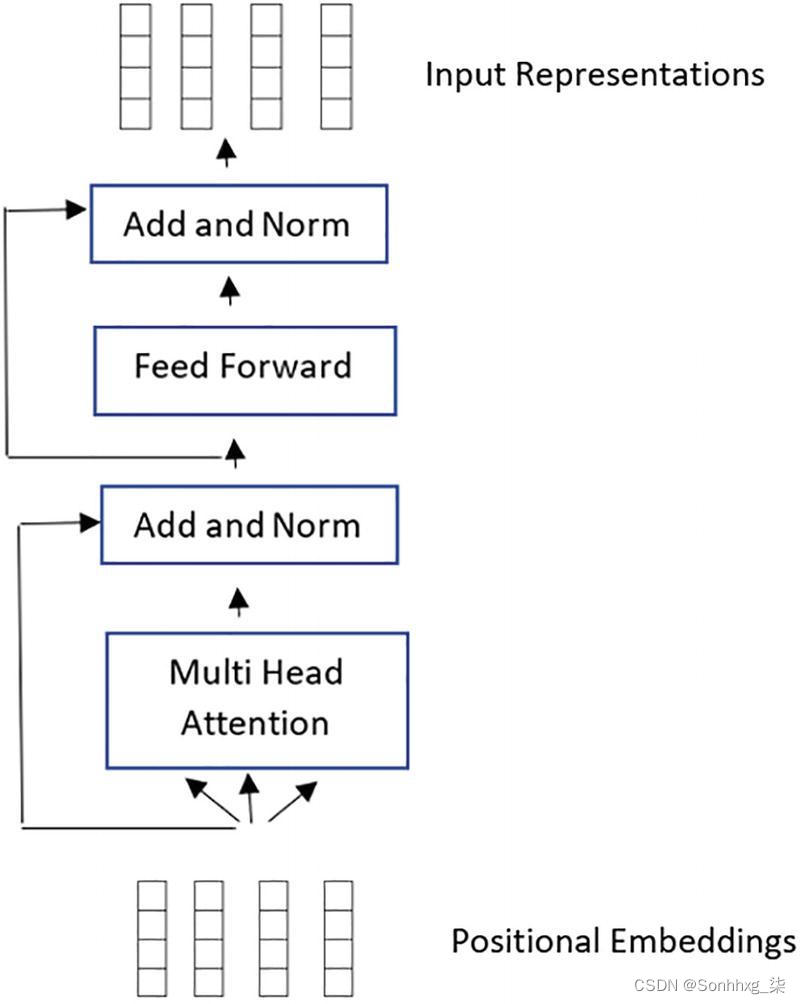
图 2-6 transformer的编码器组件
多头注意
编码器在其多头注意系统 中使用称为自我注意 的特殊注意过程。多头注意力只不过是捕获不同类型注意力的多个自注意力模块。正如本章前面所述,self-attention 允许我们将输入中的每个词与同一个句子中的其他词相关联。
让我们更深入地了解自注意力层。
以这句话为例:
“Sam had been working whole day so he decided to take some rest”
在前面的句子中,作为人类,当他说出这个词时,我们会自动将它与Sam联系起来。这仅仅意味着当我们提到 he 这个词时,我们需要注意Sam这个词。self-attention 机制允许我们在这句话中说出Sam时提供对 Sam 的引用。随着模型的训练,它会查看输入序列中的每个单词,并尝试查看它必须注意的单词,以便为单词提供更好的嵌入。本质上,它通过使用注意力机制更好地捕捉上下文。
在图2-7中可以看到he关注单词Sam。通过使用自注意力 技术 ,可以更好地捕获上下文。

图 2-7 工作中的注意力机制
接下来,我们来看看查询、键和值向量是如何工作的。
查询、键和值向量
自注意力 的概念基于三个向量表示:
Query
Key
Value
Query, key, value概念源自信息检索系统。例如,当我们在谷歌或任何搜索引擎中搜索时,我们会提供一个查询 作为输入。然后,搜索引擎会在其数据库或存储库中找到与查询匹配的特定键,并最终将最佳值作为结果返回给我们。
图2-8显示了Query, key, value机制如何工作以捕获有关单词表示的上下文信息。
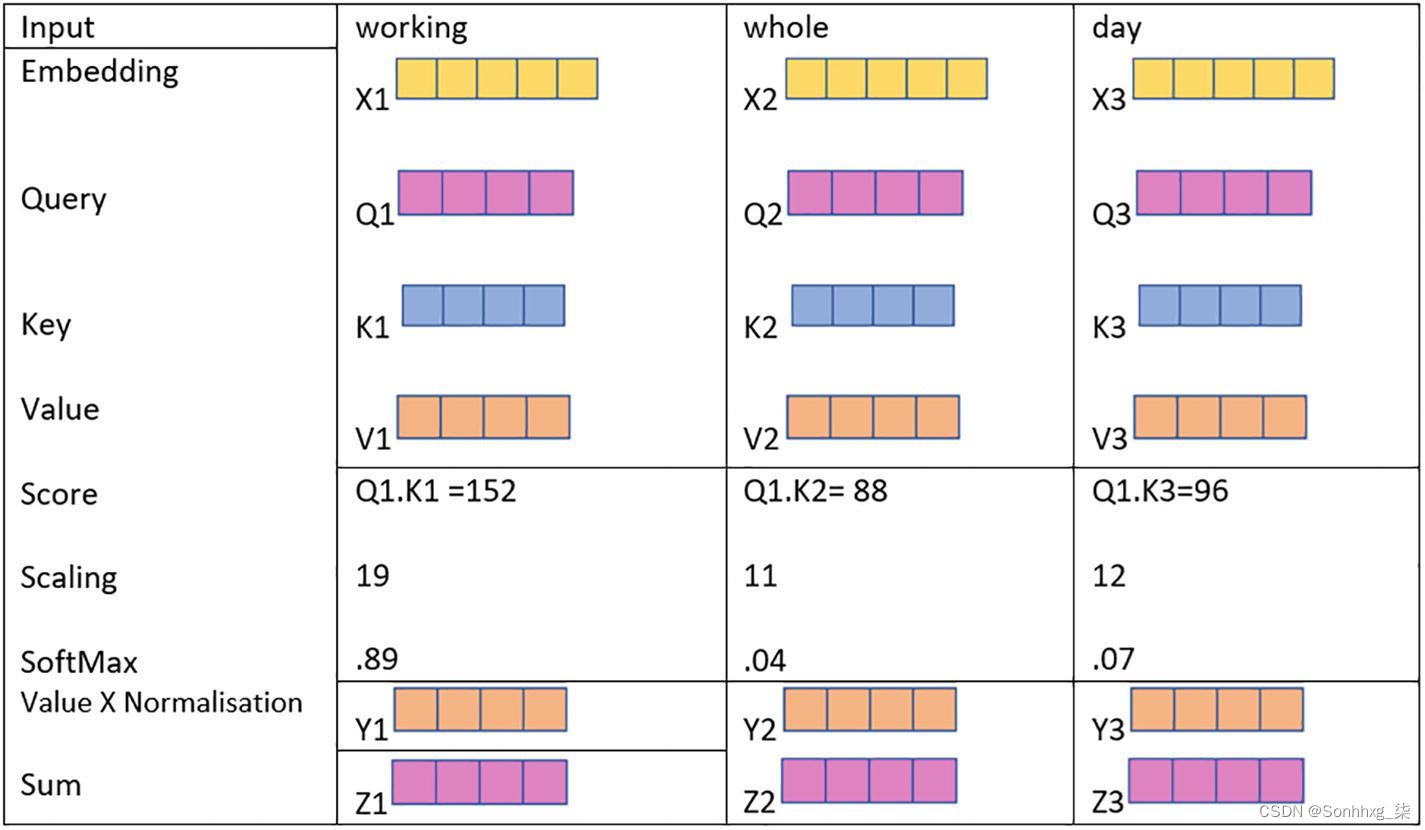
图 2-8 工作中的Query, key, value机制
自注意力
如图2-8中所述,准备好输入向量后,我们将其传递给自注意力 层,该层实际上通过使用注意力机制在其表示中捕获单词的上下文。
图2-9显示了自注意力机制如何创建上下文向量。
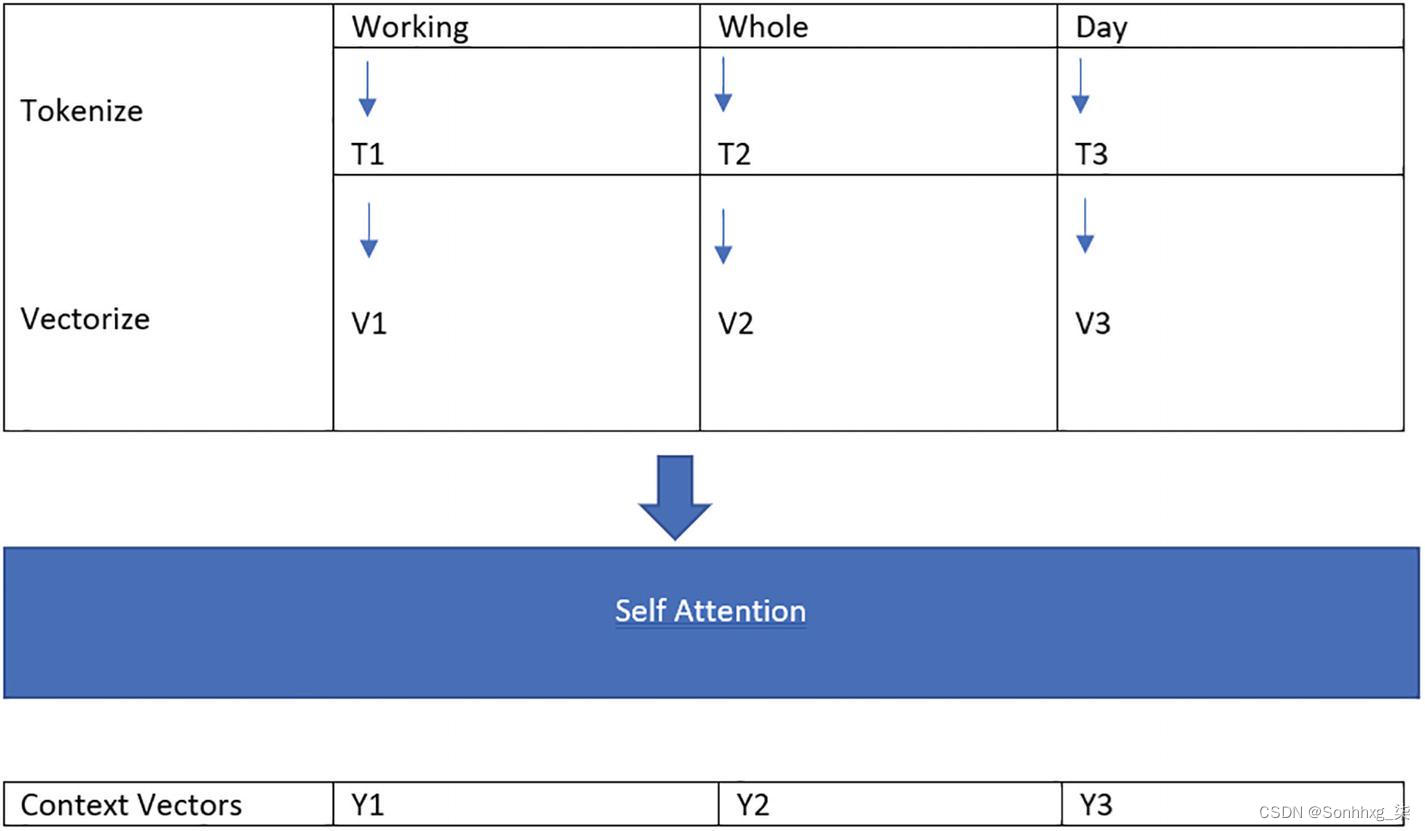
图 2-9 自注意力机制
为了在高层次上简单地实现注意力,我们采用从前面的步骤中获得的单个词向量 ,并且对于每个词向量
1.我们用自己和其他向量做点积。
2.我们得到一个分数,比如说,S11、S12、S13——在这种情况下,我们在一个句子中有三个词,我们想要捕获 V1 的嵌入。
3.然后将该分数视为权重并乘以 V1、V2 和 V3。
4.标准化分数。
5.完成步骤3中获得的向量的总和。
前面步骤的直觉是捕捉向量空间中单词彼此的接近程度,然后根据这种接近程度分配权重。然后根据它们使用的权重对相邻向量进行加权,并将它们加在一起以给出一个词的表示,其中考虑了其邻域中词的接近程度。
尽管这种机制很简单,但其中并没有学习权重。这就是查询和密钥矩阵机制发挥作用的地方 。这些矩阵中的权重是网络学习到的。每个单独的词向量与查询和键矩阵进行点积以给出查询和键向量。
在对查询、键和值向量执行线性层之后,通过对查询和键执行点积矩阵乘法来完成得分矩阵的生成。
分数矩阵用于计算每个词相对于其他词应具有的相对权重。结果,每个单词都会被分配一个分数,同时保留周围的上下文单词。特定单词的分数越高,它就越受关注。这是用于将查询映射到键的过程。
之后,通过将总分除以包含查询和键的维度的平方根来降低分数。这样做是为了能够构建更稳定的梯度,因为相乘的值会产生爆炸性的效果。
之后,您必须对缩放分数进行 softmax 以获得注意力权重,这将为您提供从 0 到 1 的概率值。当您执行 softmax 时,更好的结果会被放大,而较低的级别 会看到向下调整。因此,该模型能够对他们应该注意的术语更有信心。
将 Softmax 输出与值向量相乘
之后,您可以通过获取注意力权重并将它们乘以您的价值向量来获得输出向量。softmax分数 越高,保留模型学习的单词的值就越重要。得分较低的单词将被得分较高的单词淹没。它的输出在输入后由线性层处理。
图2-10显示了将注意力权重与值向量相乘以获得输出的机制。

图 2-10 将注意力权重乘以值向量
计算多头注意力
在应用self-attention 之前,您必须首先将查询、键和值分成 N 个向量,以便您可以使用这些数据进行多头注意力计算。之后,每个分裂向量都会经历自己特定的自注意力过程。术语“head”指的是每个单独的自我关注过程。在通过最后一个线性层之前,每个头生成的输出向量通过连接的方式组合成一个向量。原则上,每个头都会学到一些独特的东西,这将导致编码器模型具有更大的表示能力。
多头注意力 只是以不同方式多次应用的自我注意力。目标是通过这些不同的头部捕捉不同的上下文表示。通过使用 multi-headed attention,我们得到的特定单词的表征非常丰富。
残差连接、层归一化和前馈网络
然后将原始位置输入嵌入 作为附加组件提供多头注意输出向量。这种类型的连接称为剩余连接。您可以将此步骤视为将输入(在本例中为位置编码)添加到输出(在本例中为多头注意力输出)。在此之后,对残差连接的输出执行称为层归一化的操作。层归一化的目标是提高训练性能。
归一化后,输出通过一个前馈网络传递,然后这个前馈网络的结果被归一化为输入作为馈送到前馈网络的数据。
因为它们使梯度能够直接在网络中移动,所以残差连接有利于网络的训练过程。层归一化负责稳定网络,最终导致所需训练时间的显着减少。
这或多或少是编码器工作方式的高层次。接下来,我们简要讨论变压器的解码器组件。
解码器
解码器负责生成文本序列。解码器与编码器类似,具有如下层
多头注意力层
添加和规范层
前馈层
此外,它还有一个带有 softmax 分类器的线性层,用于发出输出的概率。这就是生成部分发挥作用的地方。
解码器的工作方式是采用起始标记化词,然后是先前的输出(如果有)并将其与编码器的输出相结合。
下面解释解码过程中涉及的不同方面。
输入嵌入和位置编码
在很大程度上,解码器 的开头与编码器的开头相同。为了获得位置嵌入,输入首先通过嵌入层放置,然后通过位置编码层放置。然后将位置嵌入发送到第一个多头注意层。
第一层多头注意力
该层虽然在名称上与我们在编码器中使用的类似,但在功能 上略有不同。原因是解码器只能访问句子中当前单词之前的单词。它不应该看到序列中的下一个单词。
我们需要有一种方法来避免在未来计算术语的注意力分数。所讨论的技术称为掩蔽 。通过使用先行掩码,您可以限制解码器查看尚未到来的标记。mask 包含在 softmax 计算之前和之后,softmax 计算发生在分数缩放之后。我们不会在本书中讨论先行掩码的数学细节。Mask 的基本思想是只根据前面的词计算当前词的注意力分数,而不计算句子中未来词的注意力分数。
第二层多头注意力
该层从解码器 的第一个多头注意层 获取输出,并将其与编码器的输出相结合。这将使解码器能够更好地理解要关注编码器 输出的哪些组件。这个多头注意力层的输出通过前馈网络传递。
输出概率的线性分类器和最终 Softmax
前面的多头注意力层和前馈网络的输出再次被归一化,并传递到一个带有 softmax 组件的线性层以发出概率 ——例如,特定序列中下一个单词的概率的话。这就是架构的生成方面大放异彩的地方。
概括
本章解释了转换器的工作原理。它还详细说明了 Transformer 所利用的注意力机制的力量,以便它们可以做出更准确的预测。循环神经网络可以追求类似的目标,但它们有限的短期记忆使得实现这些目标变得困难。如果您希望编码一个长序列或生成一个长序列,transformers 可能是您更好的选择。自然语言处理部门能够取得前所未有的结果,这是变压器设计的直接结果。
在下一章中,我们将从代码的角度更详细地研究转换器的工作原理。我们介绍了 huggingface 生态系统,它是 transformer 模型的主要开源存储库之一。
文章出处登录后可见!