一篇NeurIPS 2021的关于VOS (video object segmentation) 的文章,文章的思想很有借鉴价值。
论文链接
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
创新点、主要内容
针对视频实例分割问题,本文提出了一种简单而高效的方法对时空对应性 (space-time correspondence) 进行建模,能够直接得到帧间对应关系而不用对每个目标物体都进行mask features的re-encoding。
本文方法是对STM (space-time memory networks) 的简化,想要得到matching networks的极简形式,提升性能、减少memory usage,更有效的利用memory种的信息。
具体来说:
- 传统的affinities的构建机制都想attention一样是dot products+softmax,这种机制会让高confidence的node一直主导affinities而不考虑query features,一些node可能会被长时间抑制,让很大一部分memory bank的都处在停摆阶段,显然有提高空间
- 本文用negative squared Euclidean distance来代替dot product作为相似度衡量的依据,也将二者进行有效的协同,让性能提升更多。
相关工作
现有方法分为2种:用initial segmentation拟合一个模型,或用temporal propagation,然后spatio-temporal matching
Question 1
space-time和spatio-time二者有什么区别?
- correspondence learning
few-shot learning可以被看作是一个匹配问题,用query和每个support set里的元素做比较,经典的方法就是比较query feature和support feature之间的相似度(cosine similarity、squared Euclidean distance,甚至可以用一个network去学习如何衡量相似性)VOS其实就可以看作是一个few-shot matching problem,memory bank相当于是support set,只不过我们处理的是可能高达百万次的点之间的比较 - video object segmentation
早期的方法是online first-frame finetuning,推理速度缓慢,于是更快的online learning algorithm发展起来(如MRF graph inference、temporal CNN、capsule routing、tracking、 embedding learning 、 space-time matching )
其中embedding learning和space-time learning十分相似,都去尝试学习视频中物体的特征表达。
embedding learning的约束性比较大,采用local search window,很难进行一对一匹配。所以本文聚焦于space-time matching networks (STM) - STM
为视频中的每个object都建立一个memory bank,然后对每个query frame都在memory bank里做匹配,推理得到新的帧被加入memory bank里,算法随着时间进行propagate
MAST在没有input mask的情况下在RGB图像上用 Siamese networks 建立correspondence
这里有一句话我不太明白:
In this work, we deliberately build such connections and establish that building correspondences between images is a better choice, even when input masks are available, rather than a concession.
我觉得这里进行的比较应该和Siamese network有关,还需要去了解一下。
本文将affinity construction限制在两帧之间,并且考虑修改了相似度衡量的方法。
STCN
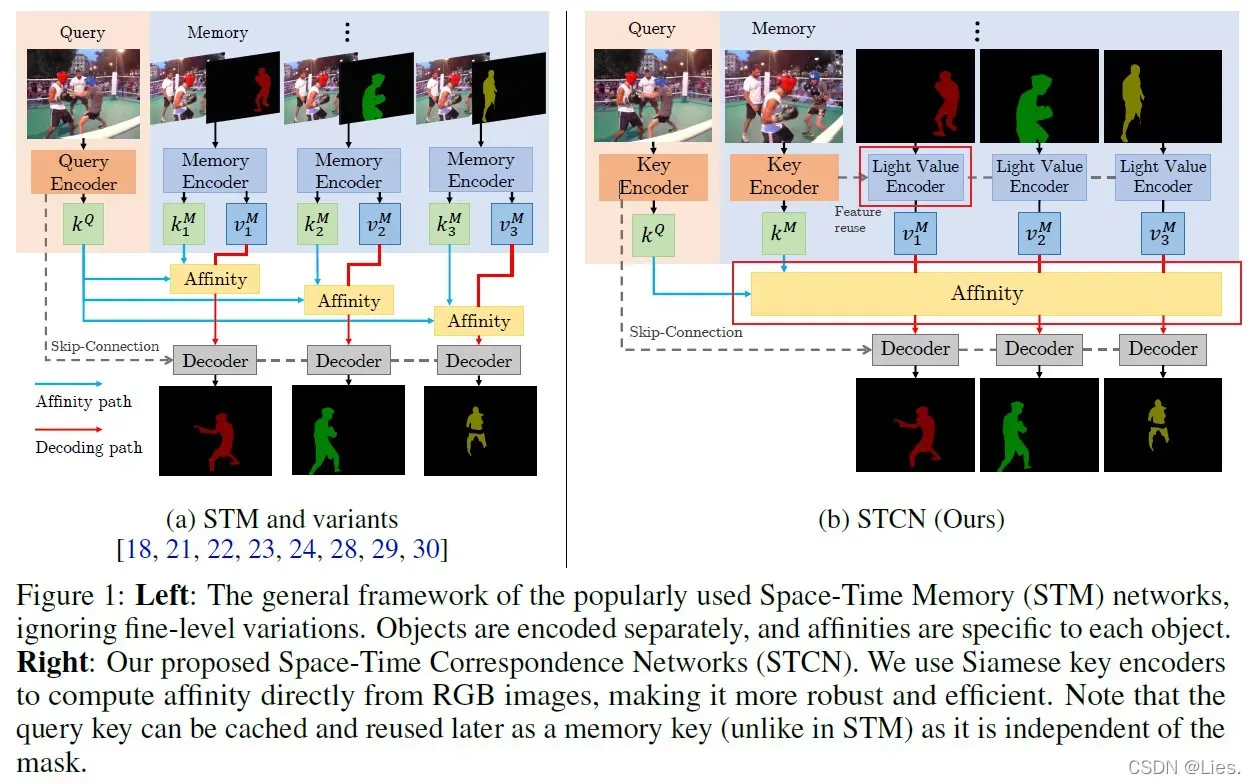
给定一段视频序列和第一帧的annotation,按照帧序处理视频并且维护feature memory bank。
当前帧为query frame,通过key encoder得到其key feature,将它与memory bank中的多个key
进行比较,然后用key affinities从memory中检索回对应的value features
(同样有多个,这里的多个既包含了多个key对应的value也包含一个key对应的多个value)
Feature Extraction
从图里可以看出,STM有两种encoder,分别是query encoder和memory encoder,前者以当前帧的RGB图像作为输入,后者以前一时刻的RGB图像和对应的各个物体的mask作为输入(有几个物体就有几个image-mask pair),所以相当于是对每个物体的mask,RGB图像都会产生不同的key feature,key feature的计算是依赖于mask的,即针对某一帧而言,它在memory bank里的key feature是有多个的,每个都对应一个物体的mask,这一帧里有多少个物体,这一帧就有多少个key feature和value。
而STCN的两种encoder:key encoder和value encoder,前者以当前时刻的RGB图像作为输入(和STM一致),后者在字面上也是以前一时刻的RGB图像和各个物体对应的mask作为输入,但是有很大差别,value encoder所使用的前一时刻的RGB图像的key feature,然后再接收各个物体的mask,产生每个mask对应的value,也就是说每个image对应于其中的任何一个物体mask,它的key feature都是同一个,这一帧里有多少个物体,就会有多少个value,但是只有一个key fature,而且这个key feature是上一时刻里key encoder已经编码得到的,不用再次编码,所以对每个image只用计算一次key feature,key feature的计算并不依赖于mask(这个也是本文把dot product改成L2去计算相似度的根本原因,在后文会提到)。
这里需要搞清图中STCN的memory里feature reuse这条线才能理解上面这段话的第一个黄色部分:
value encoder会先对mask进行特征抽取,然后将key feature和mask feature进行简单的concat,将concat的结果通过两个ResBlock和一个CBAM block,才会产生最终的value feature
从上面这个过程也可以很明显的看出来key feature的计算不依赖于mask
作者也阐述了这样设计的原因:correspondence应该是直接在帧与帧之间产生的,而不应该引入mask作为干扰。从另一个角度来说,这样的设计其实是使用了Siamese structure,而这个被广泛用于在few-shot learning中计算key feature。
本文还提到了网络层数上的差距,STM用了两个ResNet50,而STCN用了一个ResNet50和一个ResNet18,因为value encoder实际是接收了mask作为输入(image的key feature是由key encoder产生的),而key feature实际接收的是RGB image作为输入,去提取image的特征肯定要比提取mask的特征困难,所以key encoder的层数更深。
除此以外,前一时刻的image对应的key feature是否放进memory bank里取决于propagate的过程。
Memory Reading and Encoding
对于给定的帧memory frame和当前帧query frame,在上一阶段(feature extraction)会生成如下内容:
、
分别是key encoder和value encoder编码后的feature dimension
,memory key,维度为
,memory value,维度为
,query key,维度为
在本阶段能够求得以下内容:(是任意求相似度的方法,
是第
个位置的feature vector)
, pairwise affinity matrix
,softmax-normalized affinity matrix
,aggregated readout feature for the query frame
这里会在后面Computing Affinity中具体来说,要花点时间搞明白这些东西的维度都是多少,不然很容易糊涂(当然也可以直接看代码)
这里可以看出,当前帧的value feature是memory中的value feature进行加权求和得到的,而权重的计算仅依靠key feature,也就是只和image有关,和object无关,所以对不同物体对应的value feature,这个权重值是可以共享的。
但是在STM中,对每个object,权重值都要重新计算。
本阶段得到了当前帧的对应于每个object的value feature,就能够通过decoder来产生当前帧对应object的mask了,在本文中decoder的设计和STM差距不大(原文如下),更细节的内容还需要去看STM的论文。
Features are processed and upsampled at a scale of two gradually with higher-resolution features from the key encoder incorporated usingskip-connections. The final layer of the decoder produces a stride 4 mask which is bilinearly upsampled to the original resolution. In the case of multiple objects,soft aggregationof the output masks is used.
Memory Management
这个部分主要是讲如何去构建一个memory bank
- 对每个memory frame,存储它的两个信息: memory key 和 memory value
- all memory frames (except the first one) are once query frames,我理解的这个once query frames是“曾经的query frame“,就是不同对这个frame进行二次encode
- memory key就是上一时刻用key encoder编码得到的key feature(reuse那条线)
- memory value是上一时刻帧对应的各个object的mask经过value encoder后编码得到的value feature
STM把每5个query frame作为一个memory frame,把前一时刻的frame作为temporary memory frame来保证精确匹配(注意这个是temporary不是temporal啊,我第一遍就看错了),但是实际上这个所谓的temporary frame(即前一帧)的存在是没有必要的,甚至是有害的
- key feature就已经足够保证匹配的robust了,没必要再加上close-range (temporal) propagation,不懂这里为什么又变成temporal了,奇怪
- temporary memory key可能和query过于相似了,因为连续帧直接的差距通常特别小,这样很容易导致drifting(作者解释说这是由于L2 similarity导致的)
删掉temporary memory这个模块减少了value encoder的调用次数,能够提升速度,同时作者提到,虽然在后续实验中验证了这个模块是没有用的,但是为了保持一致性,还是将它保留了下来。
Computing Affinity
这部分主要探讨相似度计算的方法,要求
必须足够快、最高效率利用memory,因为对于一帧image和mask产生的feature来说,有
个pairwise relation需要计算,实际可以达到50 million也就是五千万对关系。
这里的重点是维度的计算:
memory bank中有个memory key,其中的一个memory key为
,当前帧的query key为
,那么它们的形状大概就是这样:
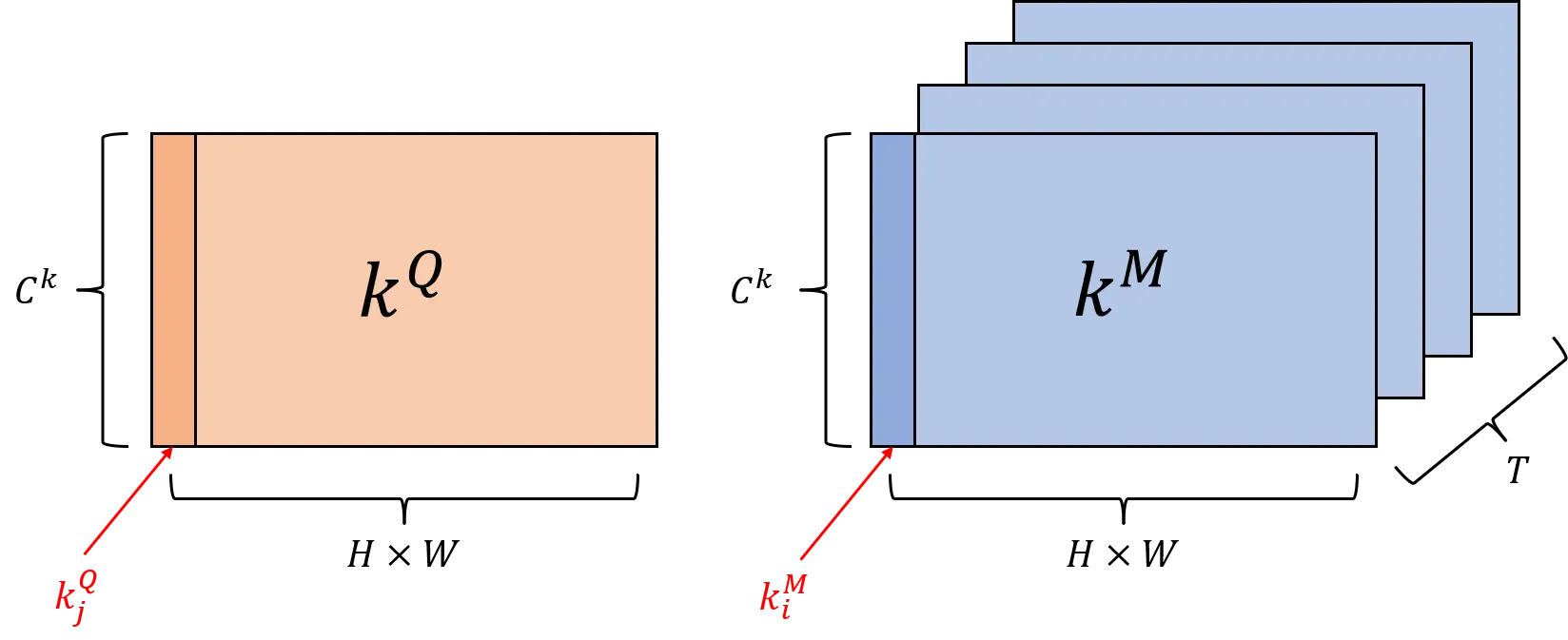
考虑三种计算相似度的方法,三种方法计算出来的形状都是一样的,即:
- dot product,
,其中
,算出的相似度范围为

- cosine similarity的计算过程和上面一样,在矩阵相乘的过程中左边的一行和右边的一列乘完后要除以行的模长和列的模长,进行标准化,即
,算出的相似度范围为
,所以也称它为标准化后的dot product注意到,如果使用cosine similarity,那么通过反向传播会让不相关的点拥有接近于0的S值,所以在memory reading阶段算出的权重也就为0,相当于这个点不存在(没有被propagate)
- negative squared Euclidean distance,就是计算L2距离的平方然后加个负号,即
,算出的相似度范围为
关键问题:为什么认为dot product在这个任务中不好?
上面提的三种相似度计算的方式,可以很明显的发现dot product其实就是放缩版的cosine similarity,用cosine similarity乘以两向量的模长就是dot product的值,也是说对于dot product而言,向量模长越大,求出来的值就越大,这会使一些模长较大(模大的向量是显著特征,更加重要)的memory key占据主导权,导致另一些memory key没有起到作用。
self-attention为什么要用dot product呢?
可以理解为一个模数很大的向量是一个显着特征,我想用一个类似于max pooling(大值:重要信息)的思路来处理。
cosine忽略了向量大小,当然这个也是有依据的:模长是内部(矢量内部)结构,矢量之间的角度是外部(矢量之间)结构,它们是不同的东西需要分开分析。
在NLP任务或者视频分类任务中,dot product很有效,是因为更重要的特征往往需要更大的注意力,比如london比the更有用,前景的人像素比背景的天空像素更重要。
但是在STCN中并不能这样考虑,因为我们一开始考虑的初衷就是correspondence应该是直接在帧与帧之间产生的,而不应该引入mask作为干扰,所以在这种情况下像素之间应该是近乎对等的关系,更有利于对query frame的每个像素(包括背景)都进行精确的匹配。
背景像素也是携带信息的,如果我们能知道它是背景像素,那么它一定不是前景(有点像废话),即使没有精确的训练,STCN在追踪背景(比如背景的河流、湖等)的表现上也十分的好。
“相对重要”的概念并不普遍适用于本文的任务。
我个人的理解,泛化性的根本就是无论是什么,都能够区分,那么图片里的像素就不会有哪个重要哪个不重要的概念
本文所做的一些实验也证明L2相比于dot product,能让更多的memory node参与到投票当中,同时也能在相同的情况下提升性能。
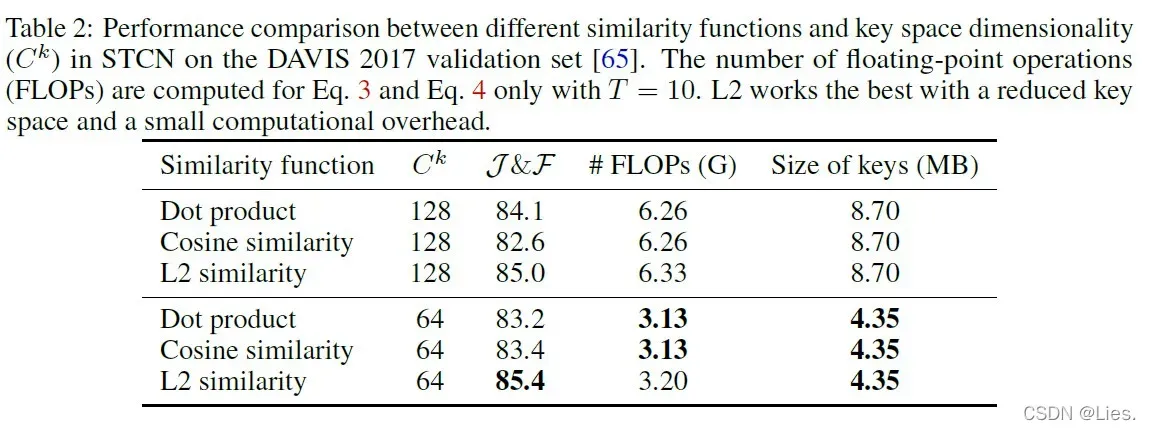
从table2里注意到降低也就是key feature的dimension对cosine和L2都有积极作用,但是对dot product有消极作用,因为更高的维度能把key feature扩散在向量空间中,防止在低维下一些key feature过于相似,对其他key feature产生抑制效果(理由同前面dot product为什么在本人无中表现不好)。
论文主体内容到这就结束了,实验部分去看看原文结果即可,这篇论文最主要的是要去知道为什么不适用dot product而使用L2,也许有更好的衡量相似度的方式可以提出来而不是用最基本的三种去换。
文章出处登录后可见!