INI配置文件及python实现
目录
前言
.ini简介
1.定义
2.结构(格式)
python实现:
1.相对路径和绝对路径
2.python创建ini文件
3.python实现将csv文件写成ini文件
4.python实现将ini文件的值写到csv文件
前言
最近在做一些算法模型,使用INI配置文件主要是用来灵活配置参数,替换一些手动、重复性的工作,本篇对所涉及的INI知识进行总结,包括:ini的相对路径和绝对路径、python创建ini文件、ini文件的读写、python实现将表格(csv文件)转为ini文件、python实现将ini文件的值写到csv文件。
.ini简介
1.定义
*.ini文件是Initialization file的缩写,即为初始化文件。
*.ini配置文件的后缀名也不一定必须是“.ini”,也可以是“.cfg”、“.conf”或者是“.txt”。
参考资料:
[1].https://www.jianshu.com/p/7f60e3ee905b
[2].https://blog.csdn.net/weixin_42040046/article/details/117419624
2.结构(格式)
*.ini文件由节、键、值组成,基本格式如下:
[section]
key1=value1
key2=value2
…
参考资料: https://blog.csdn.net/weixin_42040046/article/details/117419624
python实现
1.相对路径和绝对路径
问题描述:在运行代码时没有添加路径,运行时报错了,后来设置了路径才解决的。
import os
path=os.path.dirname(os.path.realpath(__file__))
参考资料:https://blog.csdn.net/u010263350/article/details/122445234
2.python创建ini文件:
- 导入包
import configparser
- 创建管理对象
conf = configparser.ConfigParser()
- python构建ini文件
conf['PATH']={'dirpath':path}#添加路径:节为PATH,键为dirpath,值为当前路径。
conf['Header']={'Header1':'id','Header2':'domain','Header3':'g_taxid'}#添加内容:节为Header,第一个键Header1,其值为id。...
#把路径和内容写入一个叫做Header_conf.ini的文件里
with open('Header_conf.ini','w') as cfg:
conf.write(cfg)
- 结果:
生成的nin文件: ini文件里的内容:
ini文件里的内容:
(用记事本打开即可)
总代码如下:
import configparser
import os
conf = configparser.ConfigParser(allow_no_value=True)
path=os.path.dirname(os.path.realpath(__file__))
conf['PATH']={'dirpath':path}
conf['Header']={'Header1':'id','Header2':'domain','Header3':'g_taxid'}
with open('Header_conf.ini','w') as cfg:
conf.write(cfg)
3.python实现将csv文件写成ini文件
目的:将ini_test_header.csv文件改写为ini文件。orignin为原始值;retain为从原始值中需要保留下来的值,空格表示不需要保留;rename为从保留下来的值中对某一些值进行重命名,空格表示不需要重命名(还是原来的名字),非空格表示将原来的值改为当前的名字。
具体操作:ini_test_header.csv的表头分别为ini的三个节,其中,随意取与值相同个数的键,然后将值赋给对应的键即可。例如:
【节】:[orignin]
【键=值】:header1=id
-
ini_test_header.csv数据:
-
加载ini_test_header.csv文件
import pandas as pd
#原始数据
input_data=pd.read_csv('ini_test_header.csv')
- 构建键(keys)
我想要将keys命名为header1、header2、header3…
#构建key
str1='header'
str2=0
c=[]
for i in range(input_data.shape[0]):
str2=str1+""+str(i+1)
c.append(str2)
raw = input_data.insert(0, 'Header', value=c)#在原始数据上直接插入这一列keys
- 构建ini文件
#原始值:orignin
conf = configparser.ConfigParser()#创建管理对象
#将原始值写入ini文件
with open('header.ini','w') as cfg:
#原始数据的section:conf.add_section()增加节(section)
conf.add_section(str(input_data.columns[1]))
#原始数据的key、value:conf.set(节,键,值):新增或修改节(section)中键(key)的值(value)
for i in range(input_data.shape[0]):
conf.set(str(input_data.columns[1]),str(input_data.Header[i]),str(input_data.orignin[i]))
conf.write(cfg)
conf.read('heaner.ini')
#保留值:retain
retain=input_data#不想更改原始数据,便将原始数据赋给了retain
retain_null=retain[retain.retain.notnull()]#只要去掉空格,剩下就是需要保留的值
retain_null=retain_null.drop(['index'],axis=1)
#将保留值写入ini文件
with open('header.ini','w') as cfg:
#构建section
#保留数据的section
conf.add_section(str(retain.columns[2]))
#保留数据的key、value
for i in range(retain_null.shape[0]):
conf.set(str(retain_null.columns[2]),str(retain_null.Header[i]),str(retain_null.retain[i]))
conf.write(cfg)
conf.read('heaner.ini')#写入同一个ini文件
#重命名值:rename
data=retain_null
data=retain_null.fillna(0)
data['rename']=np.where(data['rename']==0,data['retain'],data['rename'])#当值为空时,名字为retain的名字
data['rename']=np.where(data['retain']==data['rename'],data['retain'],data['rename'])#当两者不同时,名字为rename的名字
rename=data
rename=rename.drop(['orignin','retain'],axis=1)
rename=pd.DataFrame(rename)
#将重命名值写入ini文件
with open('header.ini','w') as cfg:
#构建section
#保留数据的section
conf.add_section(str(rename.columns[1]))
#保留数据的key、value
for i in range(rename.shape[0]):
conf.set(str(rename.columns[1]),str(rename.Header[i]),str(rename['rename'][i]))
conf.write(cfg)
conf.read('heaner.ini')#同一个ini文件
总代码:
#导入包
import numpy as np
import pandas as pd
import configparser
'''这个程序是,构建一个包含原始特征、保留特征和重命名特征的ini配置文件'''
#原始数据
input_data=pd.read_csv('ini_test_header.csv')
#构建key
str1='header'
str2=0
c=[]
for i in range(input_data.shape[0]):
str2=str1+""+str(i+1)
c.append(str2)
raw = input_data.insert(0, 'Header', value=c)
#创建管理对象
conf = configparser.ConfigParser()
#将原始值orignin改写为ini文件
with open('header.ini','w') as cfg:
#原始数据的section
conf.add_section(str(input_data.columns[1]))
#原始数据的key、value
for i in range(input_data.shape[0]):
conf.set(str(input_data.columns[1]),str(input_data.Header[i]),str(input_data.orignin[i]))
conf.write(cfg)
conf.read('heaner.ini')
print(input_data.columns[1])
print(conf.items('orignin'))#读取到一个section中的所有数据,返回一个列表
#保留值:retain
retain=input_data
retain_null=retain[retain.retain.notnull()]
retain_null=retain_null.drop(['index'],axis=1)
#将保留着改写为ini文件
with open('header.ini','w') as cfg:
#构建section
#保留数据的section
conf.add_section(str(retain.columns[2]))
#保留数据的key、value
for i in range(retain_null.shape[0]):
conf.set(str(retain_null.columns[2]),str(retain_null.Header[i]),str(retain_null.retain[i]))
conf.write(cfg)
conf.read('heaner.ini')
print(conf.items('retain'))
#重命名:rename
data=retain_null
data=retain_null.fillna(0)
data['rename']=np.where(data['rename']==0,data['retain'],data['rename'])
data['rename']=np.where(data['retain']==data['rename'],data['retain'],data['rename'])
#data.to_csv('rename.csv',index=False)
rename=data
rename=rename.drop(['orignin','retain'],axis=1)
rename=pd.DataFrame(rename)
#将重命名改写为ini文件
with open('header.ini','w') as cfg:
#构建section
#保留数据的section
conf.add_section(str(rename.columns[1]))
#保留数据的key、value
for i in range(rename.shape[0]):
conf.set(str(rename.columns[1]),str(rename.Header[i]),str(rename['rename'][i]))
conf.write(cfg)
conf.read('heaner.ini')
print(conf.items('rename'))
header.ini结果如下:
[orignin]
header1 = id
header2 = domain
header3 = g_taxid
header4 = g_sciname
header5 = s_taxid
header6 = s_sciname
header7 = s1_taxid
header8 = s1_sciname
header9 = index
header10 = s_reads
header11 = g_reads
header12 = cov_len
header13 = s_ueffi
header14 = g_ueffi
header15 = reads_index
header16 = rffi
header17 = cover_perc
header18 = bg
header19 = m2
[retain]
header1 = id
header2 = domain
header3 = g_taxid
header4 = g_sciname
header5 = s_taxid
header6 = s_sciname
header7 = s1_taxid
header8 = s1_sciname
header10 = s_reads
header11 = g_reads
header12 = cov_len
header13 = s_ueffi
header14 = g_ueffi
header15 = reads_index
header16 = rffi
header17 = cover_perc
header19 = m2
[rename]
header1 = id
header2 = domain
header3 = g_taxid
header4 = g_sciname
header5 = s_taxid
header6 = s_sciname
header7 = s1_taxid
header8 = s1_sciname
header10 = s_specific_value
header11 = g_specific_reads
header12 = coverage_length
header13 = s_value
header14 = g_value
header15 = discrete_index
header16 = rffi
header17 = coverage_pct
header19 = 2R
对比orignin和retain,可以发现,在retain中header9和header18不存在。因此,当你想要保留哪些值、不保留哪些值时,只需要在csv文件的retain列把它剔除,运行脚本之后就是想要的保留的值。
对于重命名列,当你想要对某些值进行重命名时,只需要在rename列写上它的新名字,运行脚本之后就能够得到重命名值。
- https://www.cnblogs.com/XhyTechnologyShare/p/11935553.html
- https://blog.csdn.net/zishendianxia/article/details/121373331
4.python实现将ini文件的值写到csv文件
目的:将构建好的ini文件中的值作为csv文件的表头,配置到csv文件上。要求:orignin为原始数据表头;从原始数据(data.csv)中选出表头为retain的数据;从选出的数据retain数据中对某些表头重命名。
- 数据-data.csv
- 关键代码
#加载ini文件路径及其文件
path = os.path.dirname(os.path.realpath(__file__))
filepath = os.path.join(path, "header.ini")
#创建管理对象
conf = configparser.ConfigParser()
conf.read(filepath)
#获取items:【(‘option’,‘value’),...】
y=conf.items('orignin')
#定义一个空列表c用来拼items里的值
c = []
#获取items,返回列表里的值,得到的是str
for yy in y:
#获取第偶个值(偶【1::2】,奇【::2】),即仅使用值
for yyy in yy[1::2]:
print(yyy)
c.append(yyy)
retain=conf.items('retain')
re=[]
for xx in retain:
for xxx in xx[1::2]:
re.append(xxx)
rename=conf.items('rename')
name=[]
for zz in rename:
for zzz in zz[1::2]:
name.append(zzz)
#将c赋给数据列表的列名
data.columns=c
print(data)
- 总代码
import configparser
import pandas as pd
import os
#加载csv数据
data=pd.read_csv('data.csv',header=None,encoding='utf-8')
#加载ini文件路径及其文件
path = os.path.dirname(os.path.realpath(__file__))
filepath = os.path.join(path, "header.ini")
#创建管理对象
conf = configparser.ConfigParser()
conf.read(filepath)
#获取items:【(‘option’,‘value’),...】
y=conf.items('orignin')#原始值
#定义一个空列表c用来拼items里的值
c = []
#获取items,返回列表里的值,得到的是str
for yy in y:
#获取第偶个值(偶【1::2】,奇【::2】),即仅使用值
for yyy in yy[1::2]:
c.append(yyy)
retain=conf.items('retain')#保留值:retain
r=[]
for xx in retain:
for xxx in xx[1::2]:
r.append(xxx)
rename=conf.items('rename')#重命名值:rename
name=[]
for zz in rename:
for zzz in zz[1::2]:
name.append(zzz)
#将c赋给数据列表的列名
data.columns=c
data.to_csv('raw_data_header.csv',index=False)#得到带有表头的原始数据
retain_data=data[r]
retain_data.to_csv('retain_data.csv',index=False)#得到筛选出的数据
retain_data.columns=name
rename_data=retain_data
rename_data.to_csv('rename_data.csv',index=False)#得到重命名数据
- 结果
带有表头的原始数据: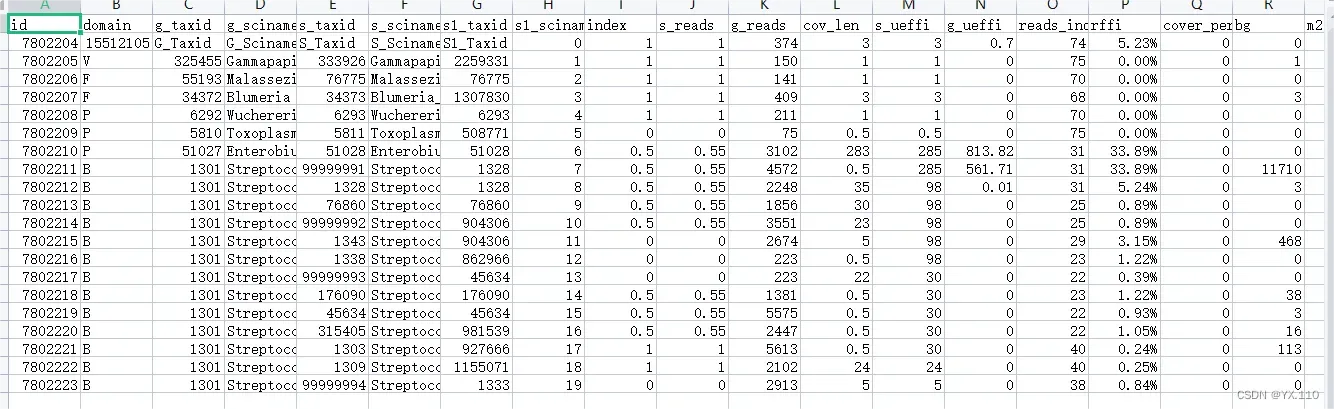
需要保留的列: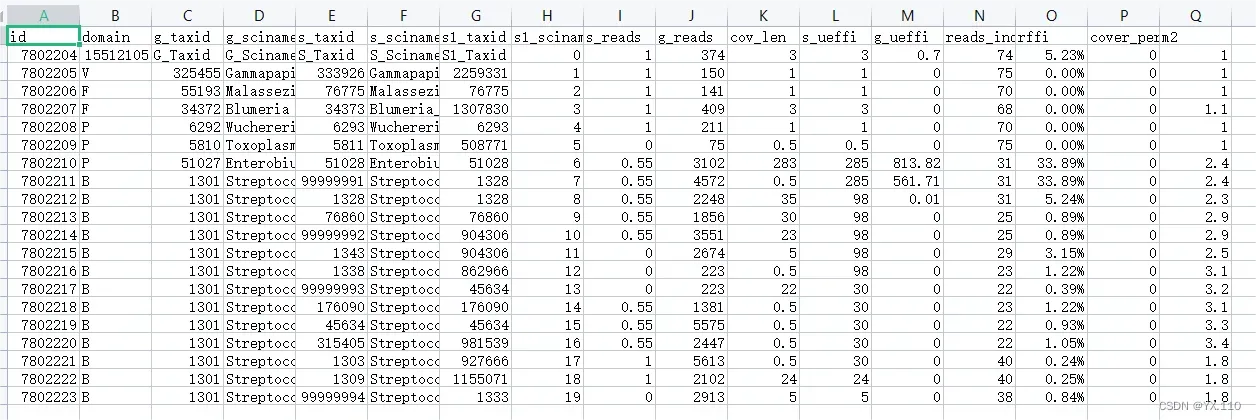
重命名数据:
写在最后:
以上功能使用excel表格能够完成,但是当数据量大(几十万行)且需要反复、手动处理这项任务时,我想,写个程序似乎更容易来处理这些数据。
共勉。
文章出处登录后可见!