在实际水质预测数据处理的工程中,往往遇到高波动的数据,而这些数据对于往后预测并没有什么用。比如说,上游河道因为有污水处理厂周期性排放污水,导致某种因子周期升高,但到了下游,河水充分混合,水质变得相对平滑。
示例如下:
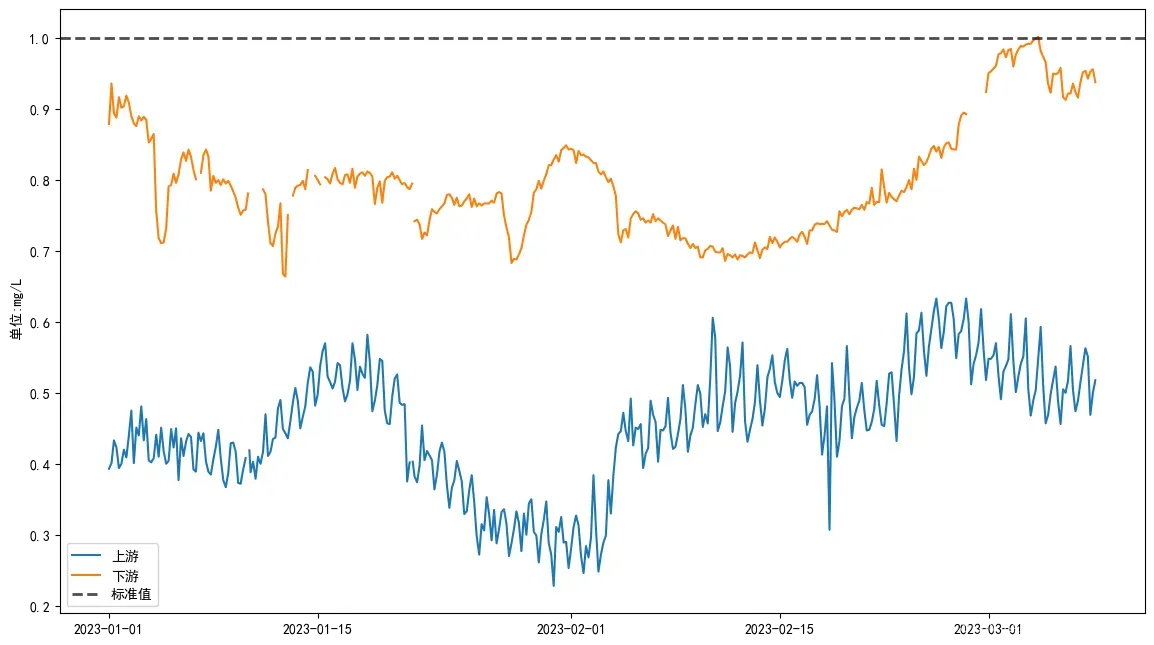
如果直接用上游波动数据预测的话,那么预测就会出现很多不必要的波动,导致预测结果不理想,如图:
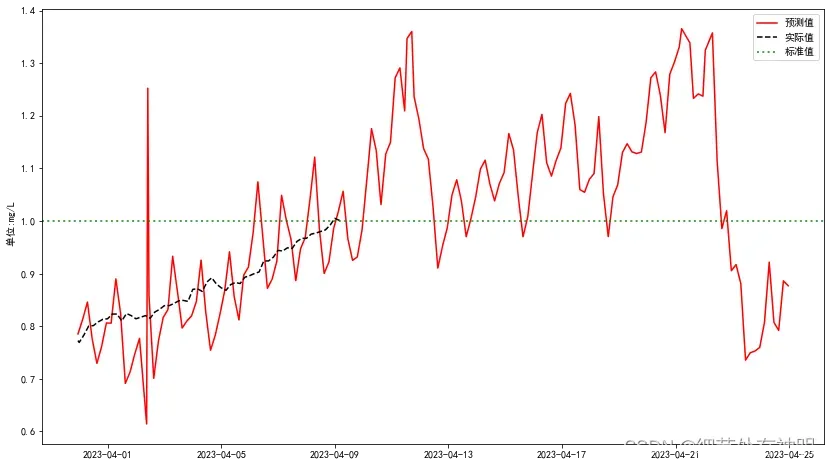
那么我们可以通过滤波的方式将不必要的波动去掉,并保留数据趋势。代码如下:
import pandas as pd
from scipy.signal import savgol_filter
# 指定滤波器窗口大小
window_size = 21
# 应用移动平均滤波器
smoothed = preb_cb.rolling(window=window_size).mean()该方法时通过移动平均滤波器实现的。经过滤波后结果如下:
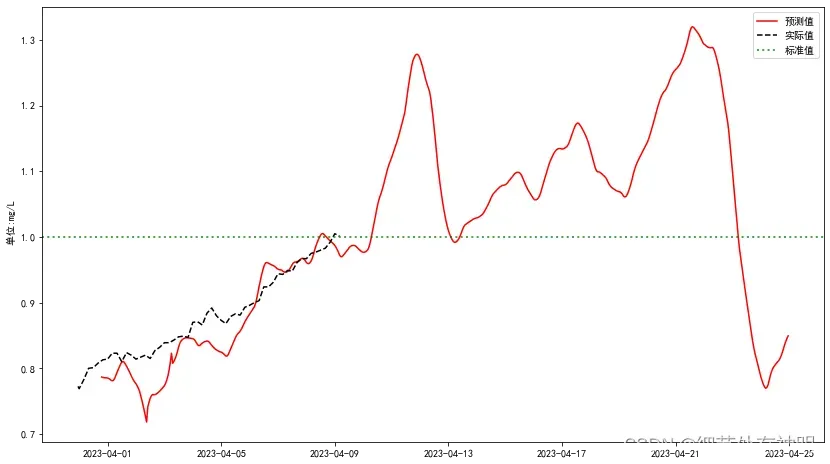
使用移动平均滤波应注意窗口的选择,可以通过循环选优,选择残差最小的窗口大小代码如下:
def seek_windows(df):
"""
df: DataFrame时间序列数据,共两列,第一列为直接预测后形成的波动数据,第二列为真实数据;
查找最佳的平移窗口;
"""
df_empty = pd.DataFrame(columns=["mean", "window"])
df0 = df.iloc[:, 0]
df1 = df.iloc[:, 1]
for window in range(1, 24, 1):
df2 = df0.rolling(window=window).mean()
df0_shifted = df2.shift(-window)
df0_shifted = df0_shifted.dropna()
df1_trimmed = df1[:-window]
mean_error = mean_absolute_error(df0_shifted, df1_trimmed)
df_empty2 = pd.DataFrame({"window": [window], "mean": [mean_error]})
df_empty = pd.concat([df_empty, df_empty2], axis=0)
df_sorted = df_empty.sort_values(by=["mean"])
best_window =df_sorted["window"][0:1][0]
return best_window
滤波的方法有很多,常用的滤波器包括移动平均滤波器、指数平滑滤波器、巴特沃斯滤波器、Butterworth滤波器等。移动平均滤波器和指数平滑滤波器适用于平稳或趋势型信号,而巴特沃斯和Butterworth滤波器则更适合于非线性或周期性信号。
我们选择适合自己数据的就行了。
—-
希望对你有帮助。
文章出处登录后可见!
已经登录?立即刷新