I. 前言
在前面的两篇文章PyTorch搭建LSTM实现时间序列预测(负荷预测)和PyTorch搭建LSTM实现多变量时间序列预测(负荷预测)中,我们利用LSTM分别实现了单变量单步长时间序列预测和多变量单步长时间序列预测。
本篇文章主要考虑用PyTorch搭建LSTM实现多变量多步长时间序列预测。
II. 数据处理
数据集是某地区某一段时间内的电力负荷数据,除了负荷外,还包括温度、湿度等信息。
本文中,我们根据前24个时刻的负荷以及该时刻的环境变量来预测接下来4个时刻的负荷(步长可调)。
def load_data(file_name):
global MAX, MIN
df = pd.read_csv(os.path.dirname(os.getcwd()) + '/data/new_data/' + file_name, encoding='gbk')
columns = df.columns
df.fillna(df.mean(), inplace=True)
MAX = np.max(df[columns[1]])
MIN = np.min(df[columns[1]])
df[columns[1]] = (df[columns[1]] - MIN) / (MAX - MIN)
return df
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, item):
return self.data[item]
def __len__(self):
return len(self.data)
def nn_seq(file_name, B, num):
print('data processing...')
data = load_data(file_name)
load = data[data.columns[1]]
load = load.tolist()
data = data.values.tolist()
seq = []
for i in range(0, len(data) - 24 - num, num):
train_seq = []
train_label = []
for j in range(i, i + 24):
x = [load[j]]
for c in range(2, 8):
x.append(data[j][c])
train_seq.append(x)
for j in range(i + 24, i + 24 + num):
train_label.append(load[j])
train_seq = torch.FloatTensor(train_seq)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
# print(seq[-1])
Dtr = seq[0:int(len(seq) * 0.7)]
Dte = seq[int(len(seq) * 0.7):len(seq)]
train_len = int(len(Dtr) / B) * B
test_len = int(len(Dte) / B) * B
Dtr, Dte = Dtr[:train_len], Dte[:test_len]
train = MyDataset(Dtr)
test = MyDataset(Dte)
Dtr = DataLoader(dataset=train, batch_size=B, shuffle=False, num_workers=0)
Dte = DataLoader(dataset=test, batch_size=B, shuffle=False, num_workers=0)
return Dtr, Dte
其中num表示需要预测的步长,如num=4表示预测接下来4个时刻的负荷。
任意输出数据之一:
(tensor([[0.5830, 1.0000, 0.9091, 0.6957, 0.8333, 0.4884, 0.5122],
[0.6215, 1.0000, 0.9091, 0.7391, 0.8333, 0.4884, 0.5122],
[0.5954, 1.0000, 0.9091, 0.7826, 0.8333, 0.4884, 0.5122],
[0.5391, 1.0000, 0.9091, 0.8261, 0.8333, 0.4884, 0.5122],
[0.5351, 1.0000, 0.9091, 0.8696, 0.8333, 0.4884, 0.5122],
[0.5169, 1.0000, 0.9091, 0.9130, 0.8333, 0.4884, 0.5122],
[0.4694, 1.0000, 0.9091, 0.9565, 0.8333, 0.4884, 0.5122],
[0.4489, 1.0000, 0.9091, 1.0000, 0.8333, 0.4884, 0.5122],
[0.4885, 1.0000, 0.9091, 0.0000, 1.0000, 0.3256, 0.3902],
[0.4612, 1.0000, 0.9091, 0.0435, 1.0000, 0.3256, 0.3902],
[0.4229, 1.0000, 0.9091, 0.0870, 1.0000, 0.3256, 0.3902],
[0.4173, 1.0000, 0.9091, 0.1304, 1.0000, 0.3256, 0.3902],
[0.4503, 1.0000, 0.9091, 0.1739, 1.0000, 0.3256, 0.3902],
[0.4502, 1.0000, 0.9091, 0.2174, 1.0000, 0.3256, 0.3902],
[0.5426, 1.0000, 0.9091, 0.2609, 1.0000, 0.3256, 0.3902],
[0.5579, 1.0000, 0.9091, 0.3043, 1.0000, 0.3256, 0.3902],
[0.6035, 1.0000, 0.9091, 0.3478, 1.0000, 0.3256, 0.3902],
[0.6540, 1.0000, 0.9091, 0.3913, 1.0000, 0.3256, 0.3902],
[0.6181, 1.0000, 0.9091, 0.4348, 1.0000, 0.3256, 0.3902],
[0.6334, 1.0000, 0.9091, 0.4783, 1.0000, 0.3256, 0.3902],
[0.6297, 1.0000, 0.9091, 0.5217, 1.0000, 0.3256, 0.3902],
[0.5610, 1.0000, 0.9091, 0.5652, 1.0000, 0.3256, 0.3902],
[0.5957, 1.0000, 0.9091, 0.6087, 1.0000, 0.3256, 0.3902],
[0.6427, 1.0000, 0.9091, 0.6522, 1.0000, 0.3256, 0.3902]]), tensor([0.6360, 0.6996, 0.6889, 0.6434]))
数据格式为(X, Y)。其中X一共24行,表示前24个时刻的负荷值和该时刻的环境变量。Y一共四个值,表示需要预测的四个负荷值。需要注意的是,此时input_size=7,output_size=4。
III. LSTM模型
这里采用了深入理解PyTorch中LSTM的输入和输出(从input输入到Linear输出)中的模型:
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.output_size = output_size
self.num_directions = 1
self.batch_size = batch_size
self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input_seq):
h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# print(input_seq.size())
seq_len = input_seq.shape[1]
# input(batch_size, seq_len, input_size)
input_seq = input_seq.view(self.batch_size, seq_len, self.input_size)
# output(batch_size, seq_len, num_directions * hidden_size)
output, _ = self.lstm(input_seq, (h_0, c_0))
# print('output.size=', output.size())
# print(self.batch_size * seq_len, self.hidden_size)
output = output.contiguous().view(self.batch_size * seq_len, self.hidden_size) # (5 * 30, 64)
pred = self.linear(output) # pred()
# print('pred=', pred.shape)
pred = pred.view(self.batch_size, seq_len, -1)
pred = pred[:, -1, :]
return pred
IV. 训练和预测
训练和预测代码和前几篇都差不多,只是需要注意input_size和output_size的大小。
训练了100轮,预测接下来四个时刻的负荷值,MAPE为7.53%: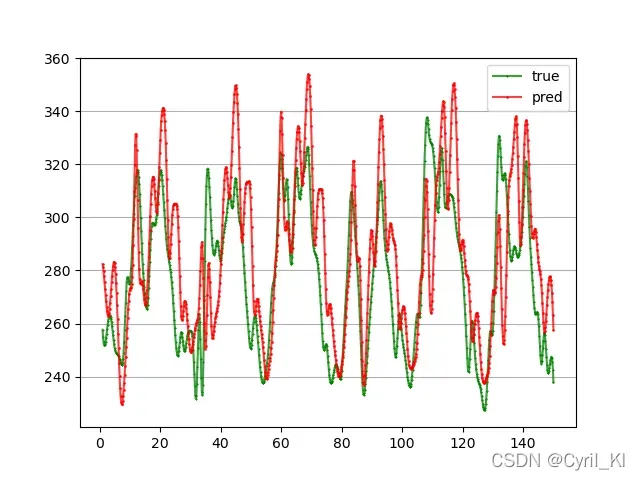
V. 源码及数据
源码及数据我放在了GitHub上,下载时请随手给个follow和star,感谢!
LSTM-Load-Forecasting
文章出处登录后可见!
已经登录?立即刷新