调试了很久,终于成功。首先训练自己的数据集环境搭建,深度学习网络搭建anaconda+gpu+pytorch
1.安装anaconda环境
可以见博客,非常小白安装,本人之前安装的显卡驱动貌似不对,会影响gpu训练
1.安装anaconda环境利用Anaconda安装pytorch和paddle深度学习环境+pycharm安装—免额外安装CUDA和cudnn(适合小白的保姆级教学)_炮哥带你学的博客-CSDN博客_anaconda安装cuda
2.准备数据集
这里参考了很多网上的博客,各种说辞,试过不下十个,都会在后续train的过程中踩雷,建议B站搜索炮哥带你学–基于yolov5的目标检测,视频清晰易懂,对于数据集的制作总结,1)专门使用一个数据集文件模板
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 先放所有需要打标签的图片
│├── Annotations 用于存放标注的.xml的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别(这个文件可有可无,但是在我们定义类别比较多的时候,最好有这个创建一个这样的txt文件来存放类别)
2)接下来下载安装图片标签的软件labelimg(网上搜索即可),标记过程也很容易,这里注意打标签的格式为VOC,别问,问就是方便操作且简单易懂,这样标签得到的是.xml文件,但是yolov5训练格式应该是.txt后续转化即可。
目标检测—利用labelimg制作自己的深度学习目标检测数据集_炮哥带你学的博客-CSDN博客
关注博客
3)注意生成的标签与图片是否对应,接下来就是划分数据集,分成train、val。这里涉及到目标分类文件路径,建议在数据集的文件夹命名就统一按照步骤1操作,这样就避免代码运行的错误,真的很容易踩坑。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["hat", "person"] # 按自己的目标分类
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()将上面的数据集分割后,文件夹显示如下
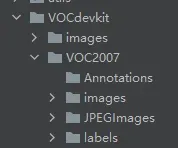
至此,数据集的准备工作就完成了。
3.yolov5模型训练
首先进入GitHub网页下载yolov5源码https://github.com/ultralytics/yolov5/tree/v5.0
网页打开很慢,可能需要一些运气,多尝试
然后code-clone压缩到D盘解压,将步骤2做好的数据集复制到yolov5-5.0的目录下
1)获得预训练权重
预训练权重可以通过这个网址进行下载,本次训练自己的数据集用的预训练权重为yolov5s.pt。
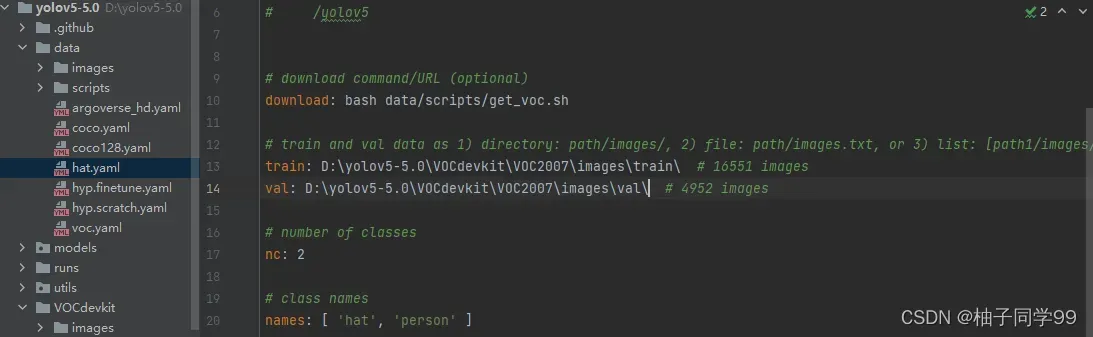
2)修改数据配置文件
修改data目录下的相应的yaml文件。找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,最好和项目相关,这样方便后面操作。我这里修改为hat.yaml。该项目是对安全帽的识别。
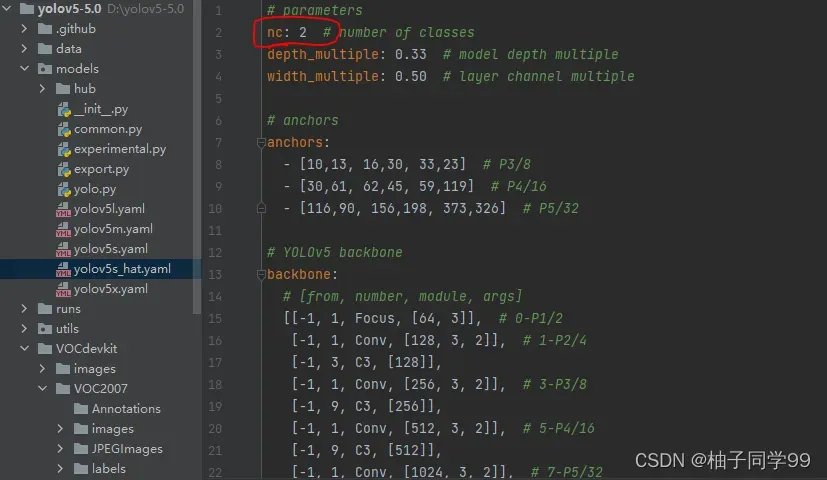
3)修改模型配置文件
由于该项目使用的是yolov5s.pt这个预训练权重,所以要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错)。同上修改data目录下的yaml文件一样,我们最好将yolov5s.yaml文件复制一份,然后将其重命名,我将其重命名为yolov5_hat.yaml。
4)训练自己的模型 调整train.py
运行train.py之气,一定要安装好环境配置
pip install -r requirements.txt此过程,我没有装上pycocotools,在终端环境以及conda环境下都没有安装成功,以为就要滑铁卢了,然后找了安装方法,从百度云下载链接:https://pan.baidu.com/s/1obsY0MerqNd24zwcYURYtA
提取码:xo9j

之后安装解压文件复制粘贴在conda/evns/lid/sit-package即可
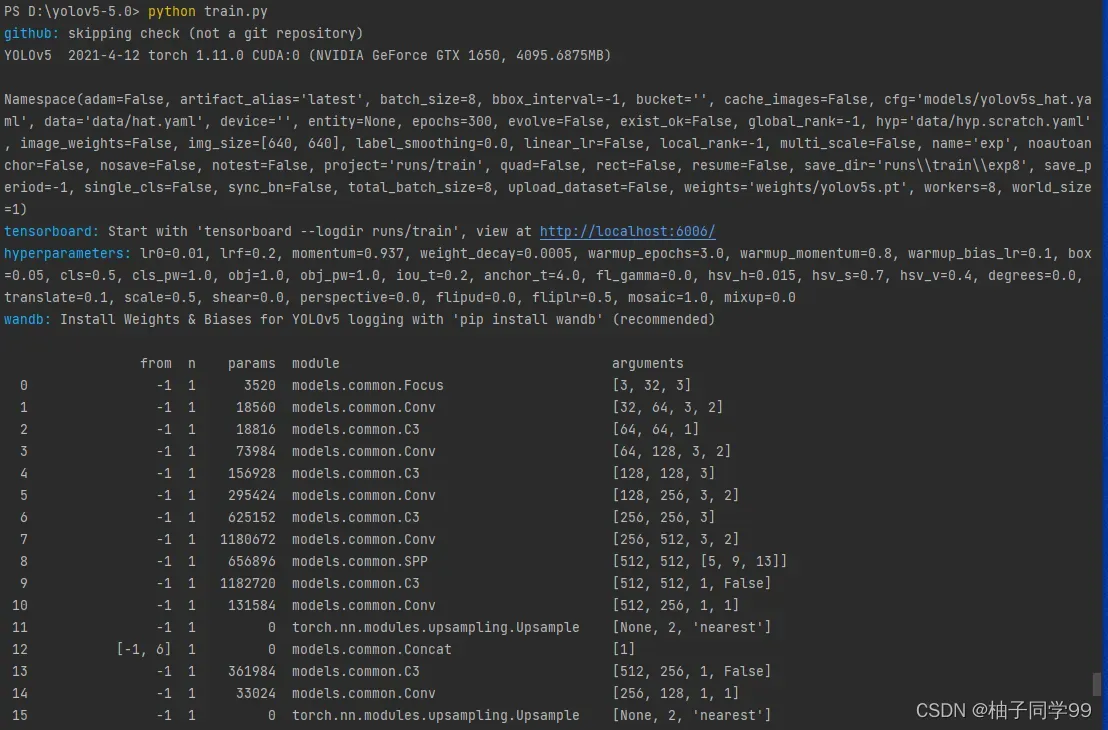
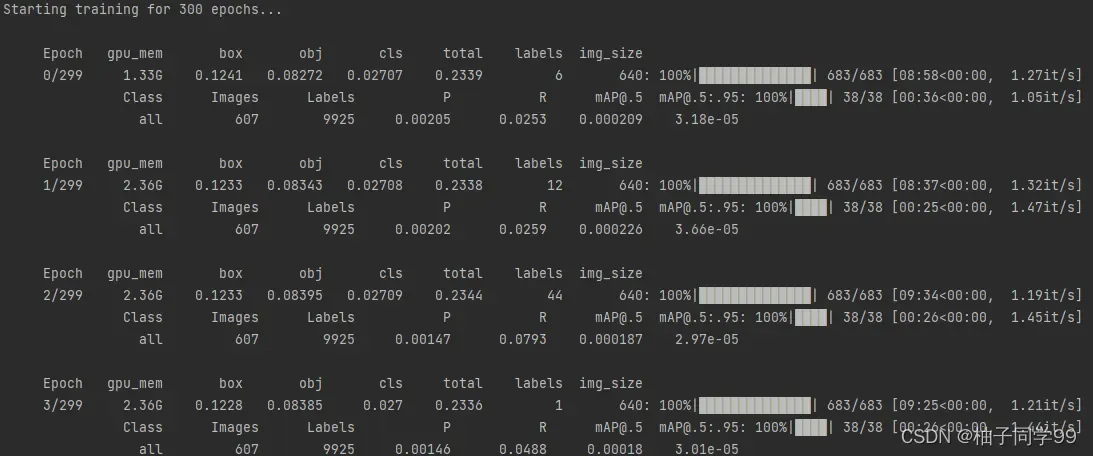
然后python train.py开始训练,训练过程也出现报错
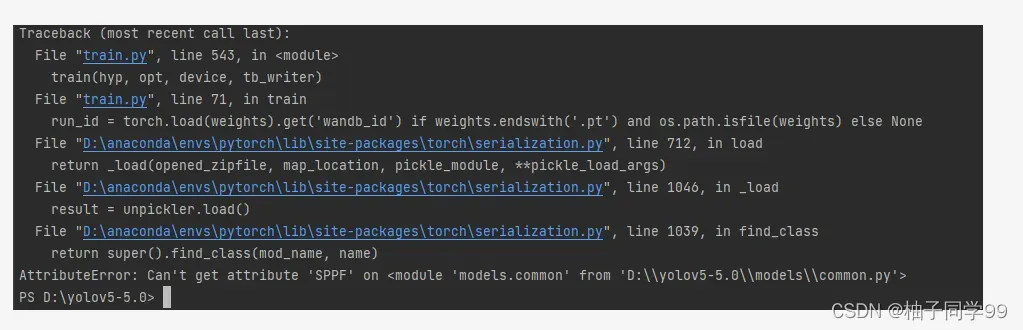
之后查询SPPF,解决方法:打开models-common.py文件,插入以下代码
import warnings
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)解决了,继续运行,遇到错误警告
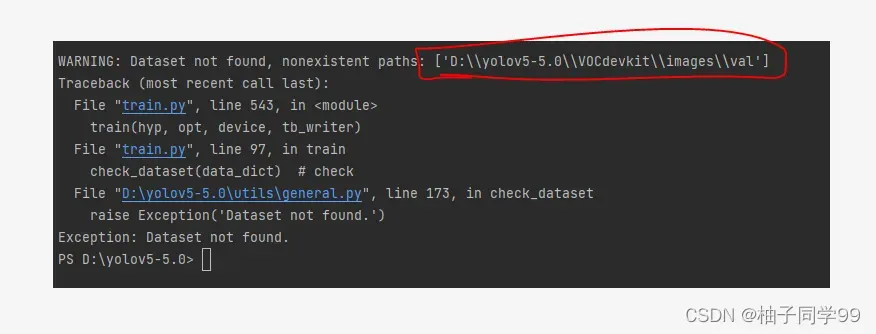
这里不知道数据集路径为什么不显示VOCdevkit\VOC2007\images
于是我按提示路径将images文件复制到VOCdevkit文件下,至此解决完所有问题,运行代码
感激。
文章出处登录后可见!