1.如何制作自己的图数据
创建一个图,信息如下:
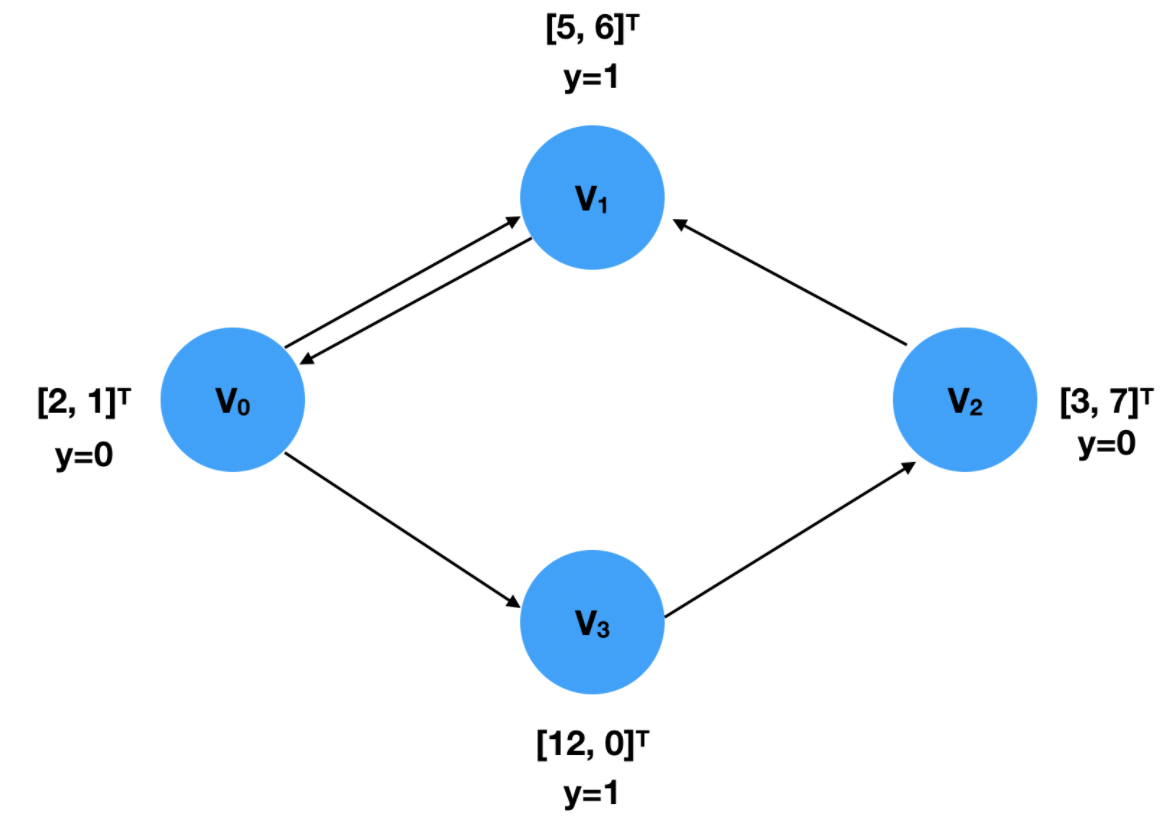
定义数据:x是每个点的输入特征,y是每个点的标签。x的维度为[M,F],M表示结点数,F表示特征个数
x = torch.tensor([[2,1], [5,6], [3,7], [12,0]], dtype=torch.float)
y = torch.tensor([0, 1, 0, 1], dtype=torch.float)
定义邻接矩阵:顺序是无所谓的,上下两种是一样的
edge_index = torch.tensor([[0, 1, 2, 0, 3],#起始点
[1, 0, 1, 3, 2]], dtype=torch.long)#终止点
edge_index = torch.tensor([[0, 2, 1, 0, 3],
[3, 1, 0, 1, 2]], dtype=torch.long)
创建torch_geometric中的图,通过torch_geometric.data
from torch_geometric.data import Data
x = torch.tensor([[2,1], [5,6], [3,7], [12,0]], dtype=torch.float)
y = torch.tensor([0, 1, 0, 1], dtype=torch.float)
edge_index = torch.tensor([[0, 2, 1, 0, 3],
[3, 1, 0, 1, 2]], dtype=torch.long)
data = Data(x=x, y=y, edge_index=edge_index)2.电商购买图数据的构建
用户在逛淘宝的过程中,可能买了一些东西。yoochoose-clicks:表示用户的浏览行为,其中一个session_id就表示一次登录都浏览了哪些东西,item_id就是他所浏览的商品,category表示商品所属的种类。
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv('yoochoose-clicks.dat', header=None)
df.columns=['session_id','timestamp','item_id','category']
buy_df = pd.read_csv('yoochoose-buys.dat', header=None)
buy_df.columns=['session_id','timestamp','item_id','price','quantity']
item_encoder = LabelEncoder()
df['item_id'] = item_encoder.fit_transform(df.item_id)
df.head()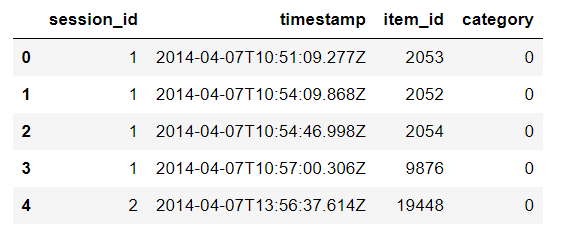
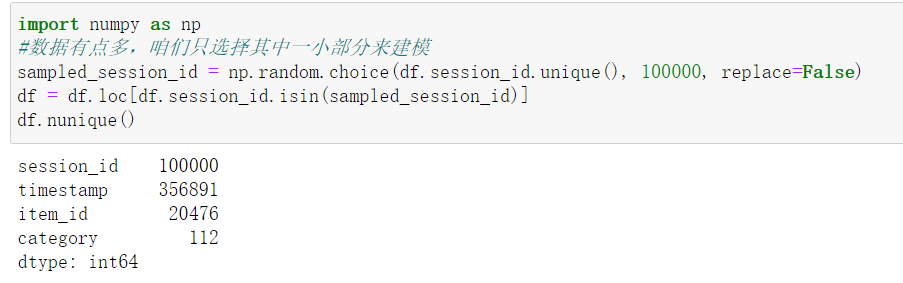
数据有点多,我们只选择其中一小部分来建模
取出标签
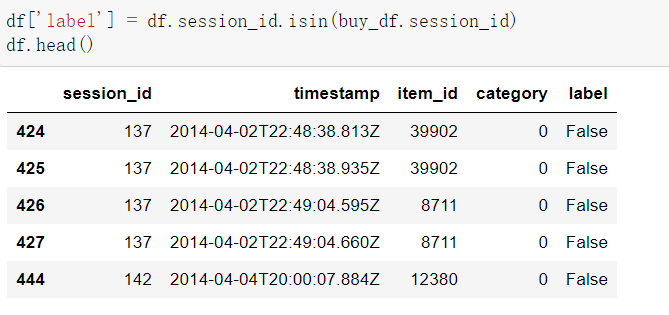
接下来我们制作数据集
- 咱们把每一个session_id都当作一个图,每一个图具有多个点和一个标签
- 其中每个图中的点就是其item_id,特征暂且用其id来表示,之后会做embedding
数据集制作流程
- 1.首先遍历数据中每一组session_id,目的是将其制作成(from torch_geometric.data import Data)格式
- 2.对每一组session_id中的所有item_id进行编码(例如15453,3651,15452)就按照数值大小编码成(2,0,1)
- 3.这样编码的目的是制作edge_index,因为在edge_index中我们需要从0,1,2,3.。。开始
- 4.点的特征就由其ID组成,edge_index是这样,因为咱们浏览的过程中是有顺序的比如(0,0,2,1)
- 5.所以边就是0->0,0->2,2->1这样的,对应的索引就为target_nodes: [0 2 1],source_nodes: [0 0 2]
- 6.最后转换格式data = Data(x=x, edge_index=edge_index, y=y)
- 7.最后将数据集保存下来
from torch_geometric.data import InMemoryDataset
from tqdm import tqdm
df_test = df[:100]
grouped = df_test.groupby('session_id')
for session_id, group in tqdm(grouped):
print('session_id:',session_id)
sess_item_id = LabelEncoder().fit_transform(group.item_id) # 对离散数据进行排序,返回0,1,2,3
print('sess_item_id:',sess_item_id)
group = group.reset_index(drop=True)
group['sess_item_id'] = sess_item_id
print('group:',group)
node_features = group.loc[group.session_id==session_id,['sess_item_id','item_id']].sort_values('sess_item_id').item_id.drop_duplicates().values
node_features = torch.LongTensor(node_features).unsqueeze(1) # 用sess_item_id表示node features
print('node_features:',node_features)
target_nodes = group.sess_item_id.values[1:] # 顺序任务,构建邻接矩阵,source-->target
source_nodes = group.sess_item_id.values[:-1]
print('target_nodes:',target_nodes)
print('source_nodes:',source_nodes)
edge_index = torch.tensor([source_nodes, target_nodes], dtype=torch.long)
x = node_features
y = torch.FloatTensor([group.label.values[0]])
data = Data(x=x, edge_index=edge_index, y=y)
print('data:',data)3.网络结构定义模块
API文档解释如下:
SAGEConv:

TopKPooling流程
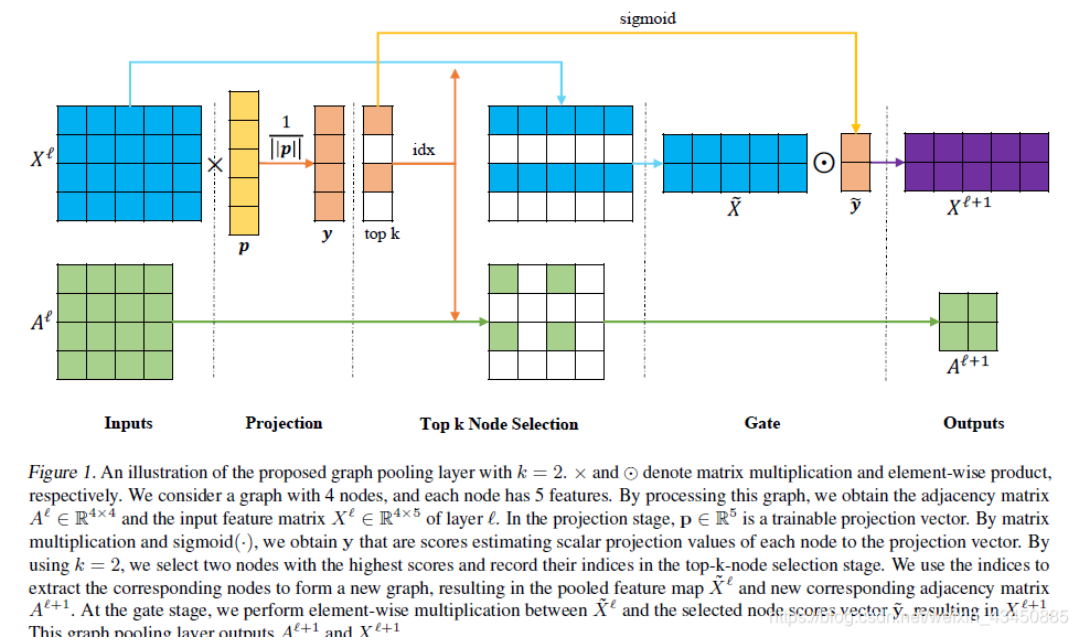
- 其实就是对图进行剪枝操作,选择分低的节点剔除掉,然后再重新组合成一个新的图,邻接矩阵也紧跟着变化
具体做法是,首先对于输入x,假设维度为4*5,乘以一个可训练的权重参数(5*1),得分值取topk,在取出对应的未经过变换的着,乘以权重(sigmoid归一化的得分值),得到最终结果。相当于就是,假设top1为99,top2为0.1,我们想让得分高的占更大的权重。同时,邻接矩阵也需要跟着变动。

embed_dim = 128
from torch_geometric.nn import TopKPooling,SAGEConv
from torch_geometric.nn import global_mean_pool as gap, global_max_pool as gmp
import torch.nn.functional as F
class Net(torch.nn.Module): #针对图进行分类任务
def __init__(self):
super(Net, self).__init__()
self.conv1 = SAGEConv(embed_dim, 128)
self.pool1 = TopKPooling(128, ratio=0.8)
self.conv2 = SAGEConv(128, 128)
self.pool2 = TopKPooling(128, ratio=0.8)
self.conv3 = SAGEConv(128, 128)
self.pool3 = TopKPooling(128, ratio=0.8)
self.item_embedding = torch.nn.Embedding(num_embeddings=df.item_id.max() +10, embedding_dim=embed_dim)
self.lin1 = torch.nn.Linear(128, 128)
self.lin2 = torch.nn.Linear(128, 64)
self.lin3 = torch.nn.Linear(64, 1)
self.bn1 = torch.nn.BatchNorm1d(128)
self.bn2 = torch.nn.BatchNorm1d(64)
self.act1 = torch.nn.ReLU()
self.act2 = torch.nn.ReLU()
def forward(self, data):
x, edge_index, batch = data.x, data.edge_index, data.batch # x:n*1,其中每个图里点的个数是不同的
#print(x)
x = self.item_embedding(x)# n*1*128 每个节点原来用item_id来表示,现在转换为128维的向量表示
#print('item_embedding',x.shape)
x = x.squeeze(1) # n*128
#print('squeeze',x.shape)
x = F.relu(self.conv1(x, edge_index))# n*128
#print('conv1',x.shape)
x, edge_index, _, batch, _, _ = self.pool1(x, edge_index, None, batch)# pool之后得到 n*0.8个点
#print('self.pool1',x.shape)
#print('self.pool1',edge_index)
#print('self.pool1',batch)
#x1 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x1 = gap(x, batch) # 构建图的全局特征,每个点特征取平均
#print('gmp',gmp(x, batch).shape) # batch*128
#print('cat',x1.shape) # batch*256
x = F.relu(self.conv2(x, edge_index))
#print('conv2',x.shape)
x, edge_index, _, batch, _, _ = self.pool2(x, edge_index, None, batch)
#print('pool2',x.shape)
#print('pool2',edge_index)
#print('pool2',batch)
#x2 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x2 = gap(x, batch)
#print('x2',x2.shape)
x = F.relu(self.conv3(x, edge_index))
#print('conv3',x.shape)
x, edge_index, _, batch, _, _ = self.pool3(x, edge_index, None, batch)
#print('pool3',x.shape)
#x3 = torch.cat([gmp(x, batch), gap(x, batch)], dim=1)
x3 = gap(x, batch)
#print('x3',x3.shape)# batch * 256
x = x1 + x2 + x3 # 获取不同尺度的全局特征
x = self.lin1(x)
#print('lin1',x.shape)
x = self.act1(x)
x = self.lin2(x)
#print('lin2',x.shape)
x = self.act2(x)
x = F.dropout(x, p=0.5, training=self.training)
x = torch.sigmoid(self.lin3(x)).squeeze(1)#batch个结果
#print('sigmoid',x.shape)
return x训练模型
from torch_geometric.loader import DataLoader
def train():
model.train()
loss_all = 0
for data in train_loader:
data = data
#print('data',data)
optimizer.zero_grad()
output = model(data)
label = data.y
loss = crit(output, label)
loss.backward()
loss_all += data.num_graphs * loss.item()
optimizer.step()
return loss_all / len(dataset)
model = Net()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
crit = torch.nn.BCELoss()
train_loader = DataLoader(dataset, batch_size=64)
for epoch in range(10):
print('epoch:',epoch)
loss = train()
print(loss)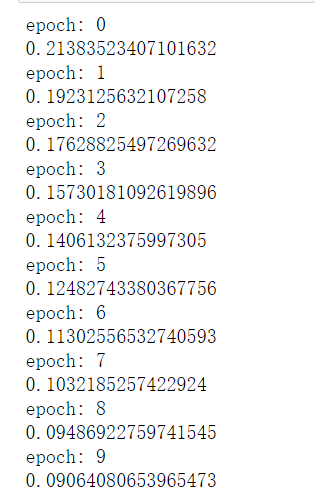
评估
from sklearn.metrics import roc_auc_score
def evalute(loader,model):
model.eval()
prediction = []
labels = []
with torch.no_grad():
for data in loader:
data = data#.to(device)
pred = model(data)#.detach().cpu().numpy()
label = data.y#.detach().cpu().numpy()
prediction.append(pred)
labels.append(label)
prediction = np.hstack(prediction)
labels = np.hstack(labels)
return roc_auc_score(labels,prediction) for epoch in range(1):
roc_auc_score = evalute(dataset,model)
print('roc_auc_score',roc_auc_score)roc_auc_score 0.9325659815540558
文章出处登录后可见!