写在前面:
“Talk is cheap, show me the code.”
本项目为大一学习pytorch的练手之作,代码参考较多,若有错漏请不吝赐教。
内容
1.数据集获取
2.数据集处理
3.卷积神经网络的pytorch实现
4.模型训练
5.模型应用(特定人脸识别)
1.数据集获取
数据集的获取完全参考以下博客中的人脸数据获取方法,使用opencv中的haarcascade_frontalface_alt2.xml 模型进行人脸识别,框出每一张人脸并保存到本地。
利用python、tensorflow、opencv实现人脸识别(包会)!_就是这个七昂的博客-CSDN博客_tensorflow 人脸识别
import cv2
import sys
def CatchPICFromVideo(window_name, camera_idx, catch_pic_num, path_name):
cv2.namedWindow(window_name)
#视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
#告诉OpenCV使用人脸识别分类器
classfier = cv2.CascadeClassifier("D:\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml")
#识别出人脸后要画的边框的颜色,RGB格式
color = (0, 255, 0)
num = 0
while cap.isOpened():
ok, frame = cap.read() #读取一帧数据
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #将当前桢图像转换成灰度图像
#人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0: #大于0则检测到人脸
for faceRect in faceRects: #单独框出每一张人脸
x, y, w, h = faceRect
#将当前帧保存为图片
img_name = '%s/%d.jpg'%(path_name, num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > (catch_pic_num): #如果超过指定最大保存数量退出循环
break
#画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
#显示当前捕捉到了多少人脸图片
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame,'num:%d' % (num),(x + 30, y + 30), font, 1, (255,0,255),4)
#超过指定最大保存数量结束程序
if num > (catch_pic_num): break
#显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id face_num_max path_name\r\n" % (sys.argv[0]))
else:
CatchPICFromVideo("截取人脸", 0, 1000, 'C:\\Users\\73559\\Desktop\\ml\\pic3')捕获结果:
2.数据集处理
(pytorch自带的DataLoader还不太会用,正在学习中,届时将更新本节内容,本节将用传统方法对数据集进行处理)
读取文件夹中图片后,使用opencv对图片进行resize,避免暴力resize使图片像素损失
import os
import numpy as np
import cv2
import random
# from torch.utils.data import DataLoader 学习中...
TRAIN_RATE = 0.8
VALID_RATE = 0.1
SAMPLE_QUANTITY = 2000
IMAGE_SIZE = 64
MYPATH = "C:\\Users\\73559\\Desktop\\ml\\data"
#读取训练数据
images = []
labels = []
def read_path(path_name):
for dir_item in os.listdir(path_name):
#从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item))
if os.path.isdir(full_path): #如果是文件夹,继续递归调用
read_path(full_path)
else: #文件
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = cv2.resize(image, (IMAGE_SIZE, IMAGE_SIZE), interpolation=cv2.INTER_AREA) #修改图片的尺寸为64*64
images.append(image)
labels.append(path_name)
return images,labels
#从指定路径读取训练数据
def load_dataset(path_name):
images,labels = read_path(path_name)
#两个人共2000张图片,IMAGE_SIZE为64,故尺寸为2000 * 64 * 64 * 3
#图片为64 * 64像素,一个像素3个通道(RGB)
#标注数据,'pic'文件夹下都是我的脸部图像,全部指定为0,另外一个文件夹下是同学的,全部指定为1
labels = np.array([0 if label.endswith('pic') else 1 for label in labels])
#简单交叉验证
images = list(images)
for i in range(len(images)):
images[i] = [images[i],labels[i]]
random.shuffle(images)
train_data = []
test_data = []
valid_data = []
#训练集
for i in range(int(SAMPLE_QUANTITY * TRAIN_RATE)):
train_data.append(images[i])
#验证集
for i in range(int(SAMPLE_QUANTITY * TRAIN_RATE),int(SAMPLE_QUANTITY * (TRAIN_RATE + VALID_RATE))):
valid_data.append(images[i])
#测试集
for i in range(int(SAMPLE_QUANTITY * (TRAIN_RATE + VALID_RATE)), SAMPLE_QUANTITY):
test_data.append(images[i])
return train_data, test_data , valid_data
# if __name__ == "__main__":
# train_loader = load_dataset(MYPATH)
3.卷积神经网络的pytorch实现
网络结构:
卷积1 -> 卷积2 -> 池化1 -> 卷积3 -> 卷积4 -> 池化2 -> 全连接
import torch
# 定义网络结构
class MYCNN(torch.nn.Module):
def __init__(self):
super(MYCNN,self).__init__()
self.conv1 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=3,
out_channels=32,
kernel_size=3,
padding='same'),
torch.nn.ReLU()
)
self.conv2 = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=32,
out_channels=32,
kernel_size=3),
torch.nn.BatchNorm2d(32),
torch.nn.ReLU()
)
self.maxpool1 = torch.nn.Sequential(
torch.nn.MaxPool2d(2,2),
torch.nn.Dropout(0.1)
)
self.conv3 = torch.nn.Sequential(
torch.nn.Conv2d(32,64,2,padding='same'),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.conv4 = torch.nn.Sequential(
torch.nn.Conv2d(64,64,2,2,0),
torch.nn.BatchNorm2d(64),
torch.nn.ReLU()
)
self.maxpool2 = torch.nn.Sequential(
torch.nn.MaxPool2d(2,2),
torch.nn.Dropout(0.1)
)
self.fc = torch.nn.Sequential(
torch.nn.Linear(1*64*7*7,1024),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(1024, 128),
torch.nn.ReLU(inplace=True),
torch.nn.Linear(128, 2),
torch.nn.Softmax(dim=1) #dim=1是按行softmax——降到(0,1)区间内相当于概率
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.maxpool1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.maxpool2(x)
x = x.contiguous().view(-1,64*7*7) #使用.contiguous()防止用多卡训练的时候tensor不连续,即tensor分布在不同的内存或显存中
x = self.fc(x)
return x网络结构参考:
PyTorch基础入门六:PyTorch搭建卷积神经网络实现MNIST手写数字识别_Liamcoder的博客-CSDN博客_pytorch搭建卷积神经网络
防范措施:
pytorch的卷积层参数所需 [输入通道,输出通道,卷积核大小,步长,补丁数]

其中 padding 支持 “same” 和 “valid”。”same”情况下不能自行设定除1以外的步长,可通过所给公式解一元方程求得padding。
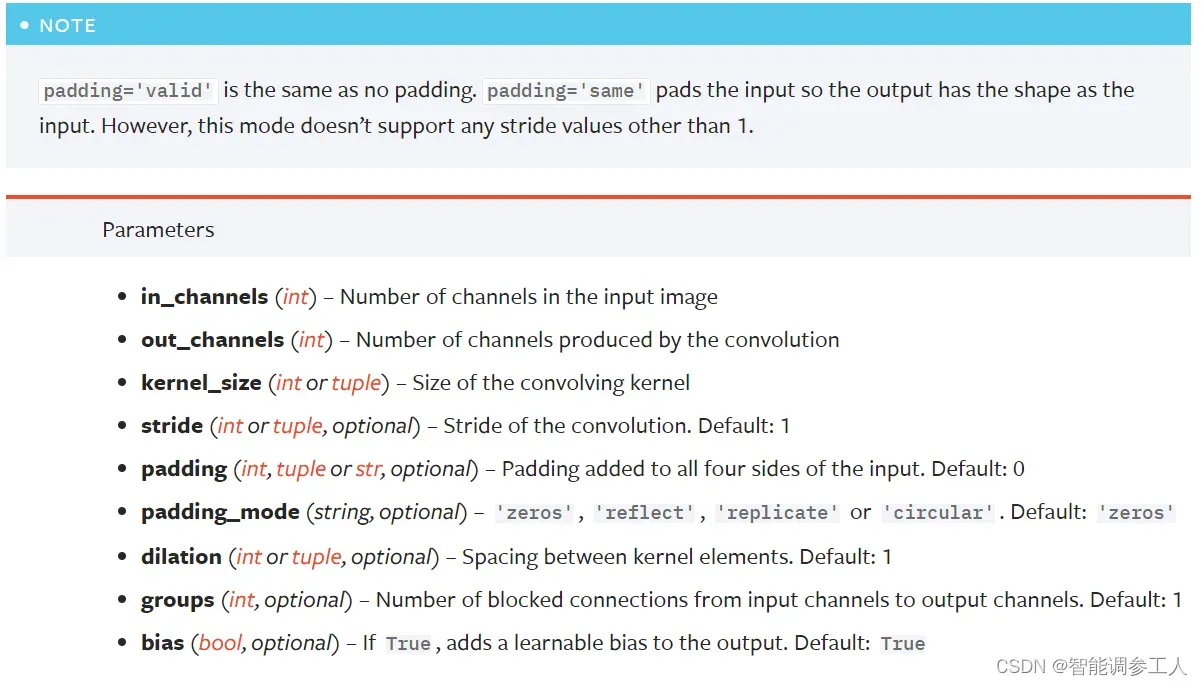

卷积层功能的详细信息,请参见官方文档:
Conv2d — PyTorch 1.11.0 documentation
相关信息:
在线卷积池计算器:
在线卷积池公式计算器
BatchNorm2d原理:
BatchNorm2d原理、作用及其pytorch中BatchNorm2d函数的参数讲解_LS_learner的博客-CSDN博客_batchnorm2d
快速理解CNN原理(可视化):
CNN Explainer
SoftMax:
torch.nn.functional中softmax的作用及其参数说明 – 慢行厚积 – 博客园
4.模型训练
注释应该很详细。)
test data没有用到,可根据实际情况调用。
import torch
import numpy as np
from torch.autograd import Variable
from prepare import load_dataset, MYPATH
from cnn import MYCNN
from torch import nn, optim
#定义学习率
learning_rate = 0.02
#是否使用GPU训练
device = torch.device("cuda" if torch.cuda.is_available() else"cpu")
model = MYCNN().to(device)
#定义交叉熵损失函数与SGD随机梯度下降
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
#数据载入
train_data, test_data , valid_data = load_dataset(MYPATH)
epoch = 0
for data in train_data:
img, label = data
img = torch.LongTensor(img)
#升维,因为pytorch规定输入卷积层的张量至少为4纬,故在此加一个batch的维度
img = Variable(torch.unsqueeze(img, dim=0).float(), requires_grad=False)
#改变张量维度的顺序,pytorch规定卷积层的张量为[batch_size,channel,image_height,image_width],即此处要求2000*3*64*64,而我们原来为2000*64*64*3。
img= np.transpose(img, (0,3,1,2))
#label不能直接转换为LongTensor否则会报错,原因未知-_-
label = torch.tensor(label)
label = label.long()
#转换为向量,否则无法进行判断
label = torch.flatten(label)
label = Variable(label)
img = img.to(device)
label = label.to(device)
out = model(img)
loss = criterion(out, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch+=1
if epoch%50 == 0:
print('epoch: {}, loss: {:.4}'.format(epoch, loss.data.item()))
model.eval()
eval_loss = 0
eval_acc = 0
for data in valid_data:
img, label = data
img = torch.LongTensor(img)
img = Variable(torch.unsqueeze(img, dim=0).float(), requires_grad=False)
img= np.transpose(img, (0,3,1,2))
label = torch.tensor(label)
label = label.long()
label = torch.flatten(label)
label = Variable(label)
img = img.to(device)
label = label.to(device)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item()*label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(
eval_loss / (len(test_data)),
eval_acc / (len(test_data))
))
#保存训练好的模型
torch.save(model, 'net.pkl')5.模型应用(特定人脸识别)
同样参考此博客,修改了调用模型以及img的处理。其他不再赘述。利用python、tensorflow、opencv实现人脸识别(包会)!_就是这个七昂的博客-CSDN博客_tensorflow 人脸识别j
import numpy as np
import cv2
import sys
import torch
from torch.autograd import Variable
if __name__ == '__main__':
if len(sys.argv) != 1:
print("Usage:%s camera_id\r\n" % (sys.argv[0]))
sys.exit(0)
#加载模型
device = torch.device("cuda" if torch.cuda.is_available() else"cpu")
model = torch.load('net.pkl').to(device)
#框住人脸的矩形边框颜色
color = (0, 255, 0)
#捕获指定摄像头的实时视频流
cap = cv2.VideoCapture(0)
#人脸识别分类器本地存储路径
cascade_path = "D:\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt2.xml"
#循环检测识别人脸
while True:
ret, frame = cap.read() #读取一帧视频
if ret is True:
#图像灰化,降低计算复杂度
frame_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
else:
continue
#使用人脸识别分类器,读入分类器
cascade = cv2.CascadeClassifier(cascade_path)
#利用分类器识别出哪个区域为人脸
faceRects = cascade.detectMultiScale(frame_gray, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32))
if len(faceRects) > 0:
for faceRect in faceRects:
x, y, w, h = faceRect
#截取脸部图像提交给模型识别这是谁
img = frame[y - 10: y + h + 10, x - 10: x + w + 10]
img = cv2.resize(img, (64, 64), interpolation=cv2.INTER_AREA)
img = torch.from_numpy(img)
img = Variable(torch.unsqueeze(img, dim=0).float(), requires_grad=False)
img = np.transpose(img, (0,3,1,2))
img = img.to(device)
faceID = model(img)
ACC = str(faceID[0][0].item())
cv2.putText(frame,"ACC:" + ACC[:6],
(x - 40, y - 40), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
1, #字号
(255,0,255), #颜色
2) #字的线宽
#如果是“我”
if faceID[0][0] > faceID[0][1] and faceID[0][0] > 0.9:
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, thickness = 2)
#文字提示是谁
cv2.putText(frame,'It\'s me!',
(x + 30, y + 30), #坐标
cv2.FONT_HERSHEY_SIMPLEX, #字体
1, #字号
(255,0,255), #颜色
2) #字的线宽
else:
pass
cv2.imshow("me", frame)
#等待10毫秒看是否有按键输入
k = cv2.waitKey(10)
#如果输入q则退出循环
if k & 0xFF == ord('q'):
break
#释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()结果示意图:
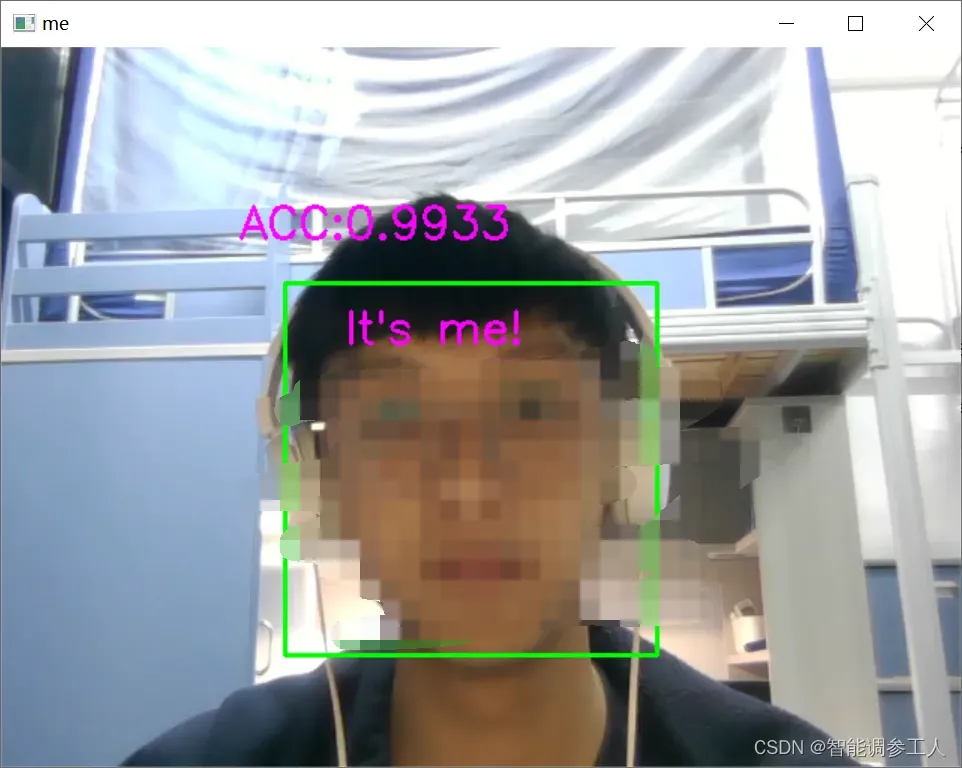
注:若有多块GPU则cuda要改成cuda:0(代表第一张GPU)
缺点总结:batchsize没有改动依旧是图片原有数量2000,若使用dataloader可大大减少处理部分代码。冗余处理较多,代码不美观,有修改意见请dd不吝赐教!!
文章出处登录后可见!