
文章目录
- 一、背景
- 二、方法
- 2.1 使用自然语言来监督训练
- 2.2 建立一个超大数据集
- 2.3 选择预训练的方式——对比学习而非预测学习
- 2.4 模型缩放和选择
- 三、效果
- 四、思考
论文:Learning Transferable Visual Models From Natural Language Supervision
代码:https://github.com/OpenAI/CLIP
官网:https://openai.com/research/clip
出处:OpenAI
时间:2021.02
贡献:
- 基于图文匹配,不受限于分类类别,有很强的扩展性!!!这是 CLIP 最炸裂的地方,彻底摆脱了预定义标签列表了
- 不仅仅能识别物体的类别,而且通过引入文本语义和视觉语义进行了联合,所以语义性非常强,迁移效果也很好,因为和语言信息的结合,所以 CLIP 学习到的视觉特征和用语言描述的物体产生了强烈的联系,无论是动漫、素描、真实的香蕉,能在域变化很剧烈的情况下,仍然很好的识别出香蕉
- 提出了一个基于图文匹配的多模态模型, 通过对图像和文本的模型联合训练,最大化两者编码特征的 cosine 相似度,来实现图和文的匹配
- 基于图文匹配的模型比直接学习文本内容的模型效率高很多
效果:
- 超过 30 个数据集上做了测试,最炸裂的就是在 ImageNet 上 zero-shot,就获得了和 R50 一样的效果
简介:
- CLIP 是由 OpenAI 开源的基于对比学习的大规模(4 亿个图文 pairs)图文预训练模型
- 图像和文本的编码器都使用 Transformer,使用余弦相似度来衡量两者编码特征的距离
- 文本描述使用的英文
一、背景
本文的题目叫做:从自然语言监督信号来学习迁移性好的视觉模型
所以本文的重点所在就是要建立一个迁移性好的视觉模型,能够不需要训练就得到很好的效果
之前的计算机视觉任务一般都使用的有限制性的监督信号,比如固定的类别,就有很大的局限性,难以做大做强,所以,如果能够直接从文本描述中来获得监督信号就能大大提高泛化性。
作者证明了使用一个很简单的框架就能实现对图片和文本的匹配,训练的样本是 4亿 图文对儿
预训练完成后,自然语言就可以用来引导模型做图像分类,不局限于已见过的类别,还能扩展到没见过的类别上,而且能很好的迁移到下游任务。
本文作者是如何做的:
- 研究了使用大规模的自然语言处理的数据集来训练图像分类器能达到什么效果
- 即在互联网上搜集了大概 4 亿的 image-text pairs 数据集,然后从头开始训练 ConvVIRT,本文称为 CLIP(Contrastive Language-Image Pre-training),能够高效的从自然语言中获得监督信号
- 作者通过训练 8 个模型来研究 CLIP 的可泛化性,且证明了使用的特征提取模型越大,则泛化性越好
- 作者发现,CLIP 和 GPT 家族很类似,会在 pre-training 阶段学习很多任务,如 OCR、定位、动作识别等
- 作者在 30 多个数据集上进行了 zero-shot 迁移能力的测试,发现其能够达到使用监督学习的效果
二、方法
核心就是利用自然语言的监督信号来指导模型训练
作者强调这种思路并不是一种很新的思路,因为之前就有方法做了相关研究,但描述的很凌乱,同样的思想却被分别称为无监督、自监督、弱监督、有监督的方法,看的很混乱,而且规模也没做大,所以本文就是总结了这些方法且用很多的实验证明了效果
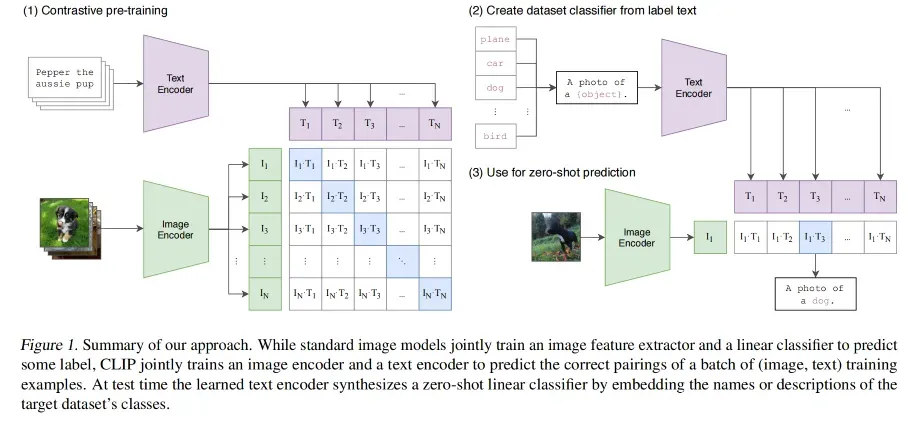
预训练流程:
- 利用自然语言的监督信号来学习迁移到视觉模型
- 对文本使用文本编码器,提取文本特征,对图像使用图像编码器,提取图像特征
- 一个迭代中,假设有 N 个文本特征和对应的 N 个图像特征,CLIP 就是在这些特征上进行对比学习
- 对比学习只需要正样本和负样本的定义
- 这里的正样本就是配对的图文 pairs,也就是图 1(1) 中的对角线位置上的特征对儿,负样本就是其他位置上的特征对儿,这里有 N 个正样本,N^2-N 个负样本
- 这里是无监督的训练方式,所以需要大量的数据,所以使用了 4 亿 图文对儿来预训练
推理:
- 既然 CLIP 是无监督的方式,那么其实是没有分类头的,所以 CLIP 提出了使用 NLP 那边的 prompt template 的方式
- 也就是把 ImageNet 的每个类别名称(如 car)变成一个句子(a photo of car),1000 个类就有 1000 个句子,通过预训练好的文本编码器,就能得到特征
- 为什么要把类别名称变成一个句子呢,因为在预训练的时候模型见到的都是句子,所以使用句子形式的文本就比较好
- 然后把图片特征和文本特征算相似性,和哪个文本最相似,就挑出来这个文本作为类别作为结果
2.1 使用自然语言来监督训练
之前的效果不好的原因其实和 NLP 模型不太好也有很大的关系,NLP 被 transformer 革命后,效果迅速提升了,又简单泛化性又好
那么为什么要使用自然语言的监督信号来训练视觉模型呢,有几个好处:
- 第一:不需要再标注这些数据了,不需要先定好类别、筛选、清洗、标注数据集,现在只需要下载文本-图片的配对,而且模型不受类别的限制,自由度和泛化性就得到了很大的提升
- 第二:图片和文本绑定到一起后,现在学到的特征不单单是视觉的特征,而是多模态的特征,当和语言联系到一起的时候就能很容易的做 zero-shot 迁移
本文方法的一个核心点在于从自然语言的监督信息中学习感知能力
从自然语言中学习的好处:
- 对图像分类来说,和标准的 label 相比,自然语言能够提供更多信息
- 因为不需要将模型构建成一个 1-of-N 的投票选择模式,而是能够从大量互联网文本中包括的更丰富的监督中学习
- 从自然语言中学习不仅仅学习一种特征表示,而是还能将特征表示和语言联合起来,从而实现更灵活的零样本迁移
2.2 建立一个超大数据集
作者构建了一个新的数据集 WIT(WebImageText),其中包括 4 亿对(图像,文本)在互联网上公开可获得的来源。
难点在于需要很大很大的数据集,虽然 coco 和 VG 的标注质量很高但数据量很少,但 YFCC100M 数据集有些标注质量很差,配对文本很差,如果使用这些数据训练模型肯定不好。清洗后就缩小了 6 倍(1500w张)太少了
所以 openai 自己收集的数据集有 4 亿图文对儿,和目前视觉最大的数据集 JFT300m 比的话,还多 1亿 ,和 GPT-2 的 WebText 的单词数量差不多接近,所以够大够用,数据集名字是 WIT(WebImageText)
2.3 选择预训练的方式——对比学习而非预测学习
CLIP 为什么使用了对比学习:
- 如果使用输入图像来预测文本的方式,那么可以生成的文本就很多很多了,文本之间的差距是非常大的,模型有太多的可能性了,学习来太慢了
- 如果只需要对图像和文本来配对,那么学习起来就更简单了,如图 2 所示,把预测型的目标函数换成了对比型的目标函数,训练过程一下就提高了 4 倍
现有的很多计算机视觉模型非常耗费计算资源,所以训练的效率很重要,更何况要使用自然语言作为监督信号,这样会比 ImageNet 中使用 1000 个 label 来训练的难度更大。
作者首先尝试了类似于 VirTex 的方法,从头联合训练图像的 CNN 和文本的 transformer 模型,预测每个图像的准确描述。
但如图 2 所示,文本 transformer 模型需要 6300 万参数,是 ResNet-50 这个 image encoder 计算量的 2 倍,学习识别 Imagenet 的类别比其他基于 bag-of-words 的方法低 3 倍。

由于每个图像的描述是不同的,同一个图像的描述也可能是多种多样的,所以要完全按照自然语言作为学习的 label (即学习其描述中的每个单词)的话难度非常大
所以就出现了使用对比学习的方法
现有的很多生成模型也能实现高质量的图像描述,但在相同描述水平的前提下,生成模型比对比模型计算量更高
所以,本文提出的训练系统将 image-to-text 构建成了一个更简单的任务,将自然语言描述的 text 看成一个整体,去学习和哪个 image 来匹配,而非学习 text 中的每个 word。这样的思路将在 Imagenet 上的零样本迁移学习速度提升了 4x
CLIP 的思路:
- 给定一个 batch,包含 N 对儿(image,text)
- CLIP 的训练目标是预测一个 NxN 的可能配对的矩阵
- 所以 CLIP 是要学习多模态的 embedding,同时训练 image encoder 和 text encoder,来最大化一个 batch 内真实的
个(image,text)pairs 的 cosine 相似度,最小化一个 batch 内其他
个非真实匹配的(image,text)pairs 的 cosine 相似度
- 以对称性的 cross entropy loss 来优化这些相似性得分
如图 3 展示了 CLIP 的伪代码:
- 图像 I 经过 image_encoder 得到图像特征
- 文本 T 经过 text_encoder 得到文本特征
- 对两个特征做特征投射和归一化,投射层的意义就从单模态的特征变成多模态空间的特征
- 对两个归一化后的特征求 cos similarity 作为 logits
- 真值的创建使用的是 np.arange(n),也就是 [1,2,3,…,n], 因为正样本全都在对角线上,所以使用对角线式来生成 gt
- 算两个 loss 取平均作为最终的 loss

一些细节:
- 最后使用线性投射层和非线性投射层没有什么大的差别,但图像单模态的模型使用非线性投射层要比线性投射层高 10 个点左右,所以作者认为非线性投射对单模态模型重要,对多模态模型不是很重要
- 由于数据量已经够大了,所以只用了 crop 这一种数据增强
- 由于训练太耗时,所以不太好做调参的实验,所以温度参数倍设置为一个可学习的参数,不需要调了
2.4 模型缩放和选择
在 image encoder 模型的选择上,作者考虑了两个结构:
- ResNet-50
- ViT
text encoder 使用的就是 transformer 结构,base size 是 63M-parameter,12 层,8 个 attention head
之前的 CV 研究中通常使用缩放模型的 width 和 depth 来实现对模型大小的缩放,本文也类似。
对 text encoder,作者只缩放模型的 width
视觉训练了 8 个模型,5 个 ResNet,3 个 Transformer,都训练 32 个 epoch,batch size 是 3 万
- 最大的 Resnet 结构 RN50x64,在 592 个 V100 上训练了 12 天
- ViT-L/14 在 256 个 V100 上训练了 12 天,表现最好,所以使用更大的尺寸 336 又 fine-tuning 了 1 个 epoch,所以叫做 ViT-L/14@336px
- 所以训练 transformer 是要比训练残差网络更高效的
三、效果
作者首先介绍了为什么关注 zero-shot transfer 的原因
- 之前的自监督方法如 MOCO 主要研究的是特征学习的能力,要学习泛化性比较好的特征,但即使学到的好的特征,要用到下游任务的时候还要牵扯到下游数据的标注
- 如何训练一个模型,接下来所有任务就不再微调了呢,这才是 zero-shot 的根本所在
当 CLIP 预训练好就有了图像编码器和文本编码器,推理的时候会将文本输入文本编码器,先把类别名称变成句子,然后得到文本的特征,然后和图像特征计算相似度,哪个相似度最高,就是对应的哪个图片
### Linear-probe evaluation
The example below uses [scikit-learn](https://scikit-learn.org/) to perform logistic regression on image features.
```python
import os
import clip
import torch
import numpy as np
from sklearn.linear_model import LogisticRegression
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR100
from tqdm import tqdm
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Load the dataset
root = os.path.expanduser("~/.cache")
train = CIFAR100(root, download=True, train=True, transform=preprocess)
test = CIFAR100(root, download=True, train=False, transform=preprocess)
def get_features(dataset):
all_features = []
all_labels = []
with torch.no_grad():
for images, labels in tqdm(DataLoader(dataset, batch_size=100)):
features = model.encode_image(images.to(device))
all_features.append(features)
all_labels.append(labels)
return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()
# Calculate the image features
train_features, train_labels = get_features(train)
test_features, test_labels = get_features(test)
# Perform logistic regression
classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1)
classifier.fit(train_features, train_labels)
# Evaluate using the logistic regression classifier
predictions = classifier.predict(test_features)
accuracy = np.mean((test_labels == predictions).astype(float)) * 100.
print(f"Accuracy = {accuracy:.3f}")
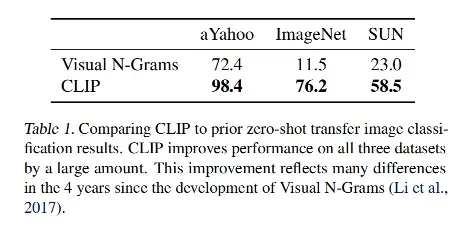
1、零样本迁移的能力:
表 1 对比了 Visual N-Grams 和 CLIP 在 3 个不同数据集上的效果, Visual N-Grams 在 ImageNet 上的效果为 11.5% ,而 CLIP 达到了 76.2%,和经过监督训练的 ResNet50 都差不多了。
CLIP 的 top-5 acc 达到了 95%,和 Inception-v4 差不多,这表明了 CLIP 在分类任务上有很好的零样本迁移能力
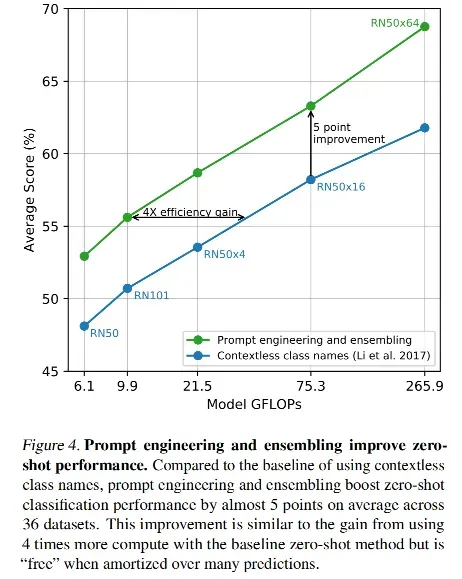
2、prompt engineering and ensembling
- prompt engineering:提示工程,把要检测的类别多给模型一些提示
- prompt ensembling:多用一些提示的模版,多次推理,然后把结果结合起来,一般就会得到更好的效果,CLIP 代码中做了 80 个模板,也就是加很多提示词,尽量描述到图像的上下文环境
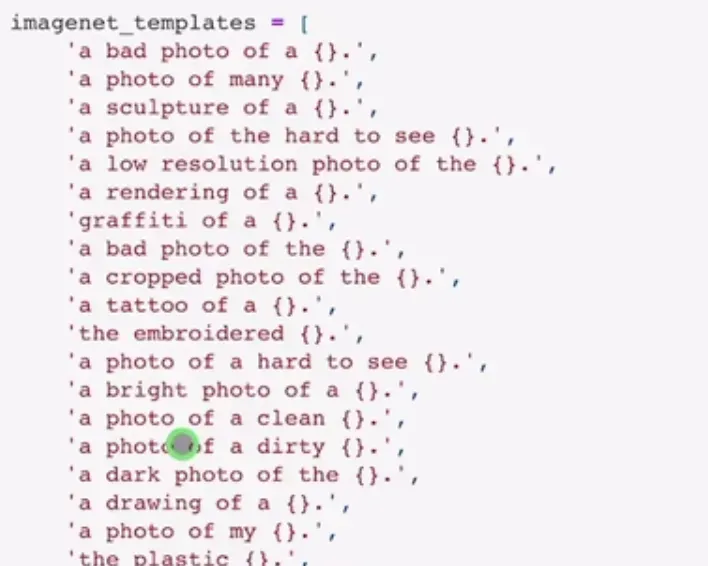
prompt 是在微调和推理的时候用到的,prompt 起到的是提示的作用,也就是文本的作用
为什么要做提示工程,有两个原因:
- 单词有多义性:不同语境下的意义是不同的,可能会误导模型特征的抽取
- 预训练的时候使用的是句子,而不是单词,如果推理的时候使用单词,就会有一定的偏差
- 用上了模版的方式提升了 1.3%
prompt 还有提示的功能,在做 zero-shot 的时候就能给模型更多的信息,把解的空间缩小,更容易得到好的效果,比如使用 a photo of a {label}, a type of pet,就能提示模型找的是动物
还有就是在 OCR 数据集上,如果给 prompt 的词语打上双引号,那么模型就明白就是想找双引号中的内容
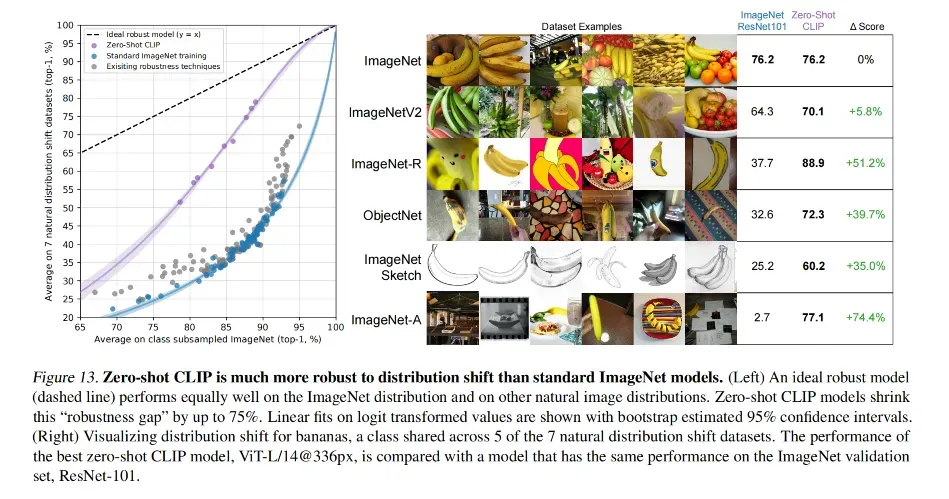
下图是官网上展示的在 ImageNet 数据集上使用 ResNet101 和 CLIP ViT-L 的对比效果:
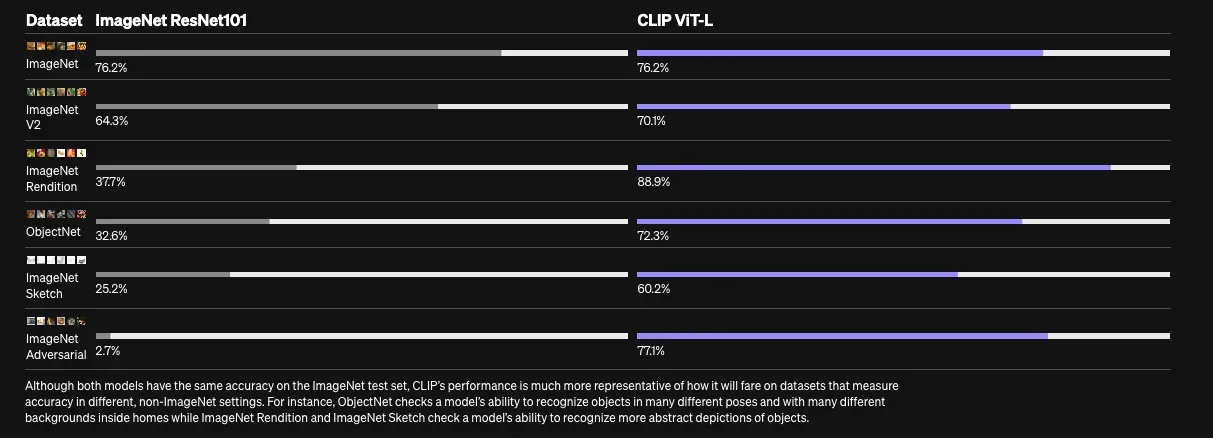
CLIP 在一些数据集上的效果:
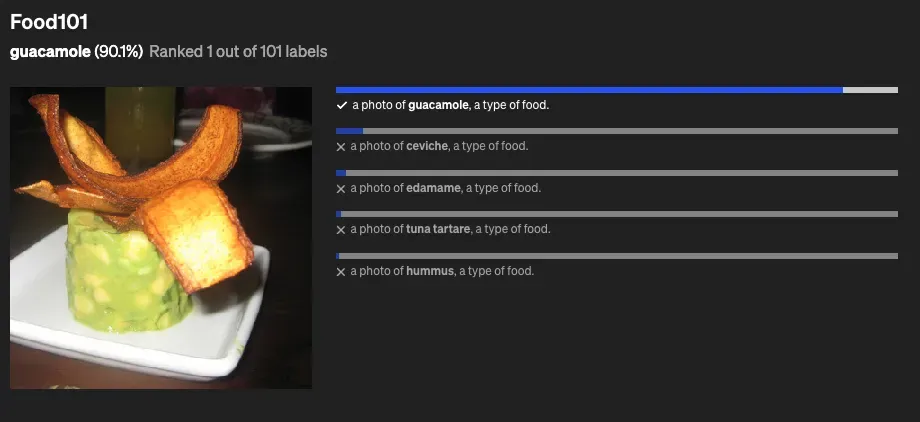




3、大秀结果
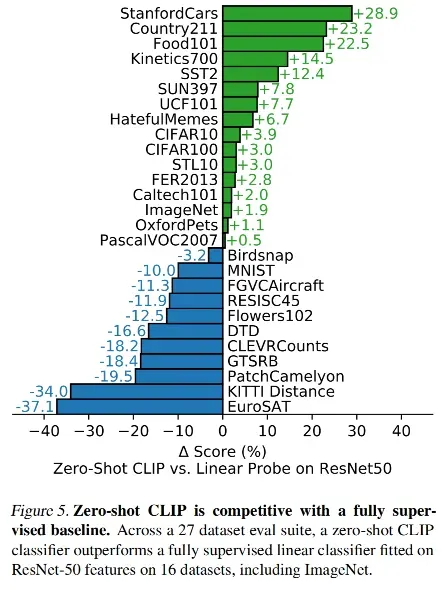
zero-shot 的效果
Zero-shot CLIP 和 ResNet + linear prop 的对比,ResNet + linear prop 作为一个基线,如果 CLIP 表现好就用绿色展示,反之则用蓝色展示
- 在 16 个数据集上,Zero-shot CLIP 都超越了有监督训练的 ResNet50,证明了 zero-shot 迁移到下游任务上的有效性
- CLIP 表现好的任务:对于给物体分类的数据集,CLIP 一般都表现的比较好,车、食物、动物等,也就是图像中有容易描述的物体,则更好匹配
- CLIP 表现不好的任务:对纹理分类、对图像中物体计数的问题等对 CLIP 来说比较难
- 作者认为,这种特别难的任务,只做 zero-shot 的迁移可能不是很好,如果做 few-shot 的迁移可能会更合理一些,比如需要特定领域知识的任务,需要一些先验知识会更好
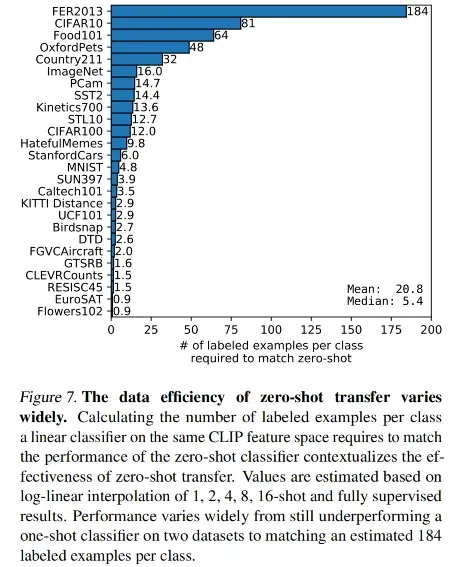
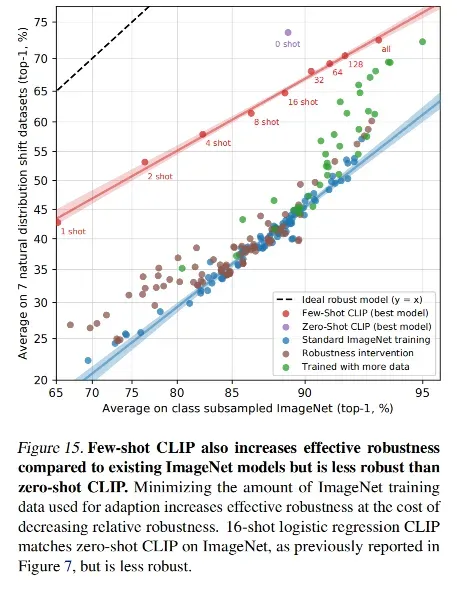
few-shot 的效果
所以,作者也做了一些 few-shot 的任务:蓝色、橘色、绿色的线的方法都没有使用自然语言数据
- 对模型进行预训练,训练好后把模型参数冻住,然后使用下游带标签的数据训练分类头,也就是 linear probe 任务,linear prob 需要训练分类头,则需要带标签数据,那就算是 few-shot 了
- linear probe CLIP 就是把训练好的图片编码器冻住,做 linear prob
- 横坐标表示每个类别训练了几个样本,纵坐标是平均分类准确度,也就是上面那 27 个数据集中的 20 个数据集,剔除了 7 个样本不足 16 的数据集
- 蓝色的曲线是 BIT(big transfer),主要是为迁移学习量身定做的,是使用 ImageNet-21k 做预训练的,数据集比较大,蓝色的曲线是很强的 baseline
- zero-shot CLIP 在不使用任何下游数据 few-shot 训练的情况下,就已经和 BiT-M 使用 16-shot 个数据训练的结果打了平手
- 紫色的曲线是对 CLIP 的图片编码器 few-shot 迁移学习的效果,在样本只有 1/2/4 的情况下,还不如直接做 zero-shot 的效果,最后就是随着训练样本的增多,超越了 zero-shot 的效果
- 所以对难的任务,有一些训练样本来进行 few-shot 对模型效果的提升是非常有必要的

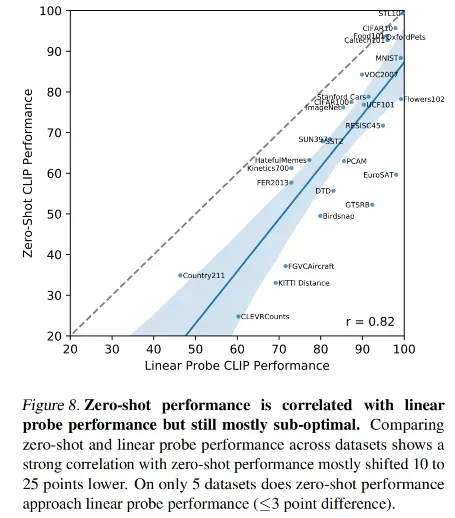
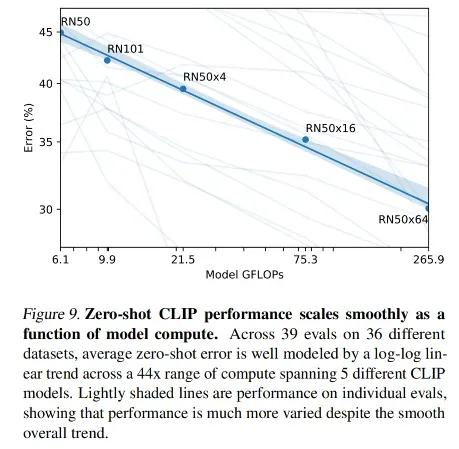
使用全部样本做 linear prob
作者在 3.2 节 (Representation learning )中呈现了使用全部数据来做 linear probe 的效果,之所以本节叫特征学习因为无监督或自监督的方法,都是先预训练一个模型,然后在下游任务进行微调
下游任务用全部数据,就可以用两种方式来衡量预训练模型的效果:
- linear prob:冻住训练好的模型,只训练分类头
- finetune:模型参数全部放开,参与训练,更灵活,且效果一般更好
但是作者这里说,只使用 linear prob 的方法,因为 CLIP 这个工作就是为了研究和数据集无关的泛化性高的训练方式,如果使用 fine-tuning,可能本来预训练的模型并不好,而是经过微调才表现的好了,所以并不能说明你的预训练模型的效果
linear prob 不灵活,只有最后一层 fc 是可学习的,学习性很小,更能准确的反映出预训练模型的好坏
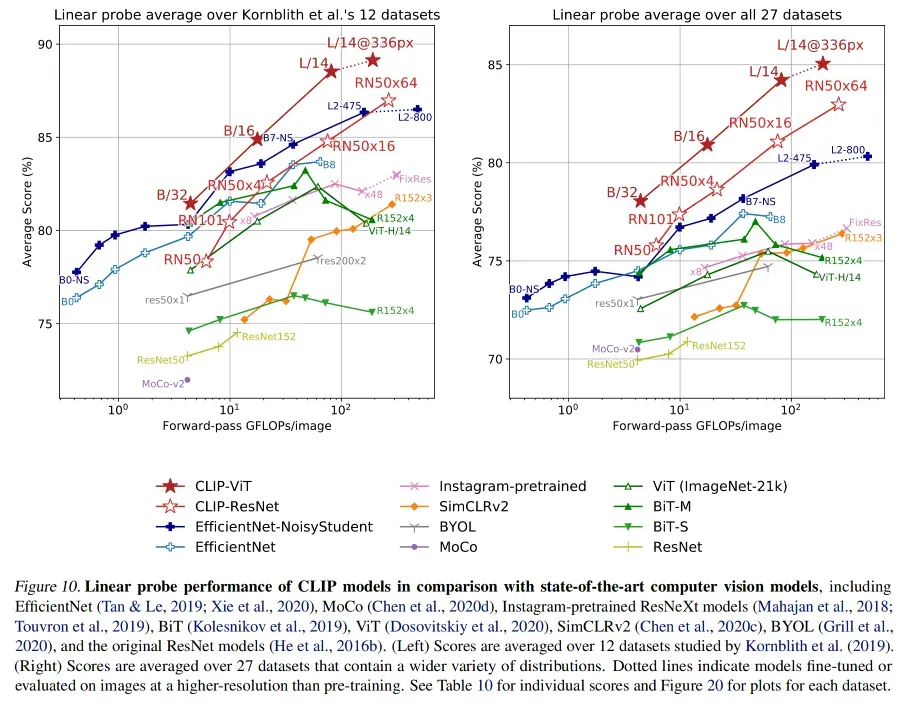
图 10 对比了很多方法,横坐标是前向传播的计算量,纵坐标是平均准确率,所以越靠近左上角的位置,模型的 trade-off 更好
这里 CLIP 效果是最好的,说明了在 zero-shot、few-shot、all-shot 上的 linear prob 训练后的效果都是最好的
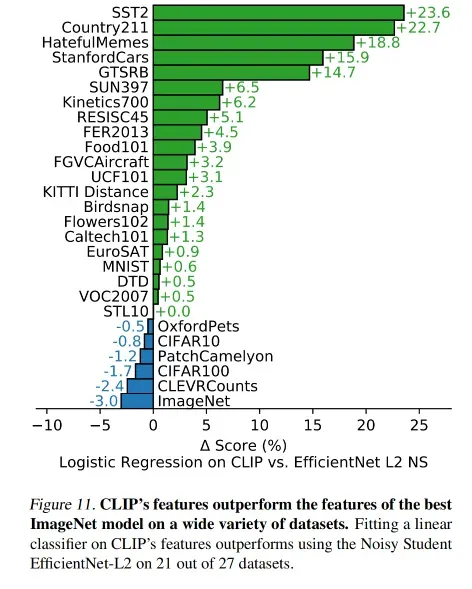
最后使用了当前在 ImageNet 上表现最好的模型,把这个模型和 CLIP 模型参数全部冻住,然后抽特征做 logistic regression
作者发现在 27 个数据集里,CLIP 在 21 个数据集上都超过了 EfficientNet,且好几个都超的很大,就算 CLIP 效果差的也只是差了一点。
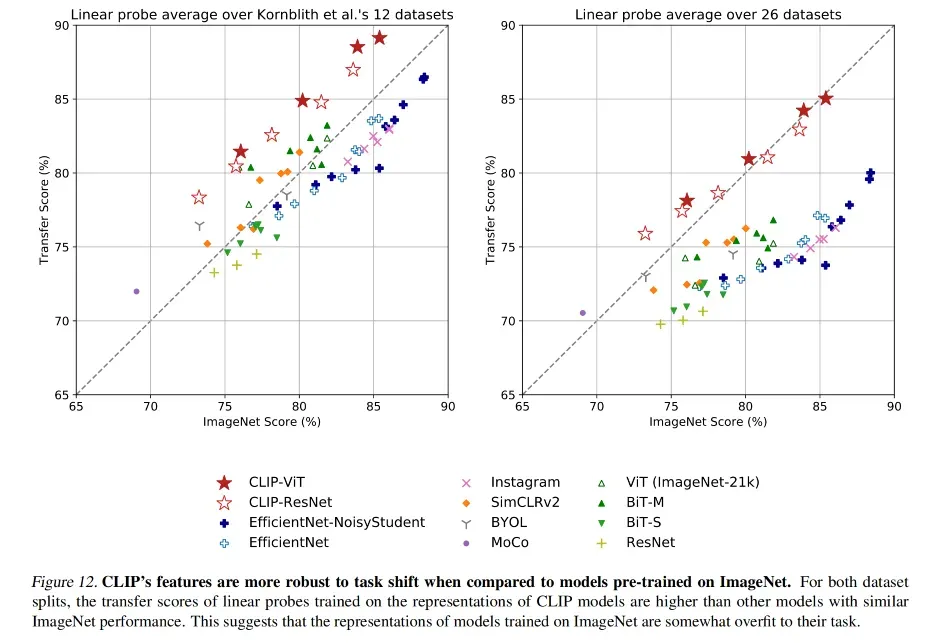
在 zero-shot、few-shot、all 数据集衡量完效果后,作者还衡量了其他的特性
首先是模型的泛化性(稳健性),当数据分布差距非常大的时候,普通模型掉点非常大, CLIP 就非常稳健
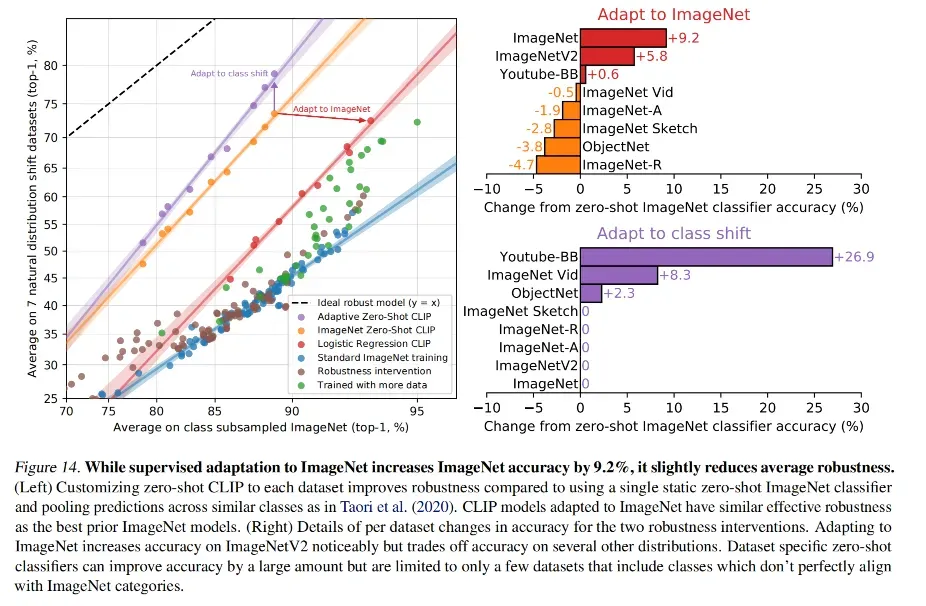
既然在这么多任务上 CLIP 都取得了很好的效果,那么和人比,看看有什么相似和区别,还能怎么提升 CLIP 的效果
作者找了 5 个人,看 Oxford IIT 数据集中的 3669 张测试图片,这里都是一些宠物,一共是 37 类,参加实验的人不能上网搜索,one-shot 就给参赛者每个种类看一张,two-shot 就是看两张。
- zero-shot CLIP 要比 zero-shot human 表现好的多,93.5 vs. 53.7
- 给人 one-shot 后,直接提升了 20 多个点的效果,提升非常多,作者认为是人可以把之前的常识和图片拿到一起去做这种判断
- 给人 two-shot 后的效果并没有增加,说明在先验知识没有增加的情况下(没有系统的学习过这些知识),再多看一两个图片也于事无补
- 但只有 5 个人参赛,说服力也不是很高,而且网络数据本来猫猫狗狗的数据就很多,CLIP 的预训练数据集可能已经包含了非常多的样本,所以就很好判断,很好匹配
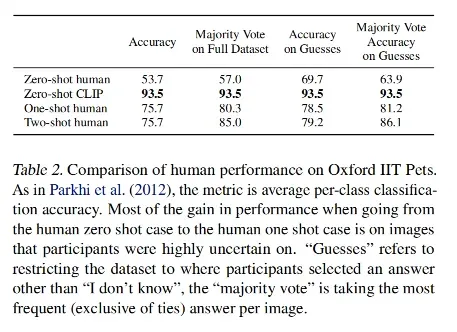
对人来说难的样本对 CLIP 来说也难,对人简单的样本对 CLIP 来说也简单,这应该也和尝试有关,和现实世界的分布有关
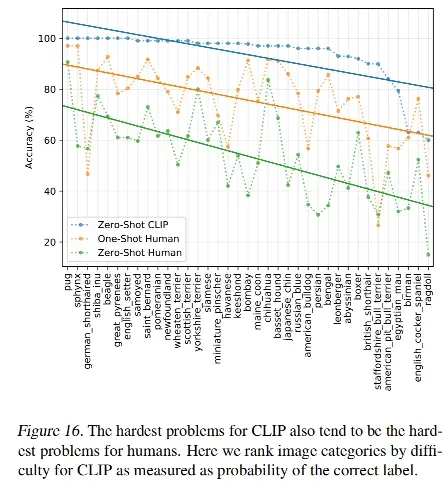
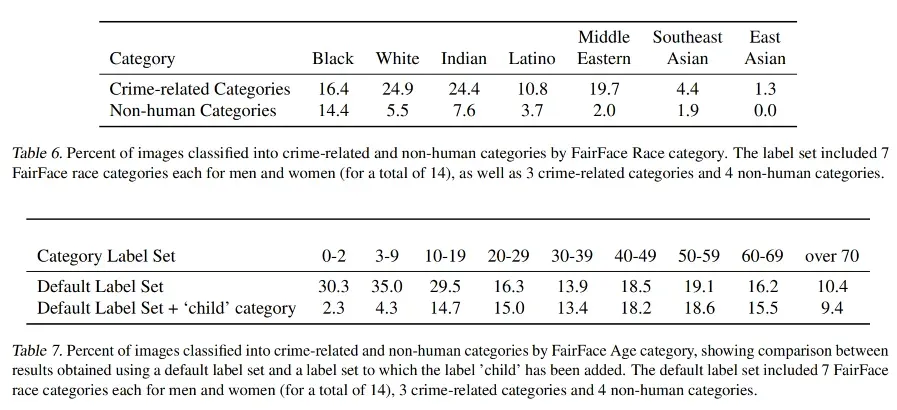
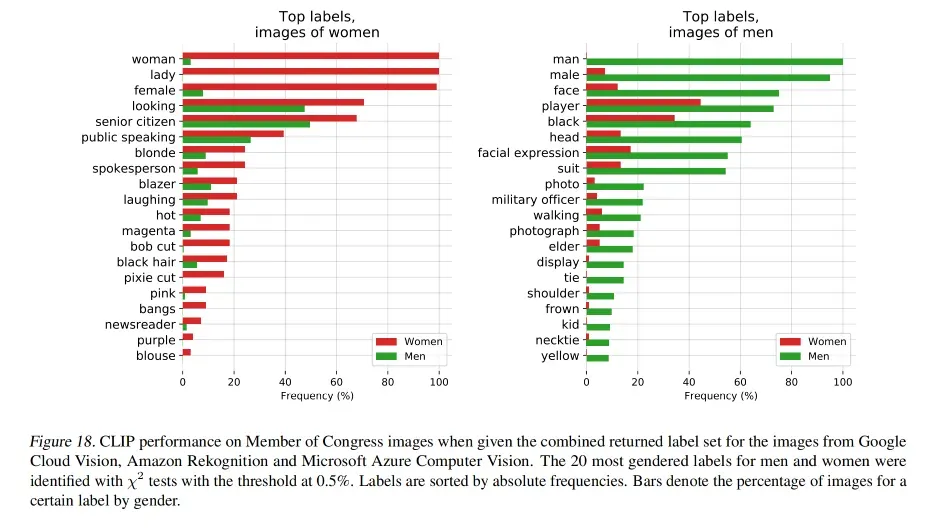
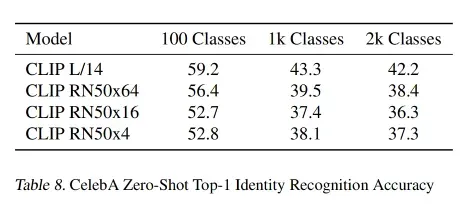
四、思考
局限性
-
CLIP 在很多数据集上平均来看是可以和基线模型达成平手的,但并不是 sota 的效果,CLIP 的性能强,但也不是强到了不行的程度,但如果想要弥补十几个点的差距,还需要 1000 倍的花费来实现,但这很难实现
-
CLIP 在一些细分类、抽象概念、专项领域的表现都不好
-
CLIP 对域的分布和训练数据差的非常大的时候,效果很差,如 MNIST 只有 88% 的效果,作者去看有没有和 MNIST 数据长得像的样本,但发现 4 亿数据中并没有这种数据,说明 CLIP 模型也是依据训练数据中学到的知识的,并不是说可以随意泛化到任何想要的数据上去
-
虽然 CLIP 可以做 zero-shot 的分类,但还是从给定的类别中去选择接近的类别的,相比而言,更灵活的方式是生成图像的标题,所以不够灵活,以后可能会把对比学习和生成学习结合起来训练
-
CLIP 对数据的利用并不是很高效,还是需要大量大量的数据来投喂,训练 32 个 epch,相当于跑了 12.8 billion 的图片,如果 dataloder 1s 看一张图,那么需要 405 年的时间,所以作者觉得用的数据太多了,如果能减少数据用量就更好了
-
可以用数据增强,还有自监督或伪标签的方式,都能有更好的数据利用效果
-
测试数据集也有局限性
-
爬取的文本数据会带有社会偏见
-
不提供训练样本时效果反而好,zero-shot 的效果超越了 one-shot、few-shot 等的效果,这个还有待研究
文章出处登录后可见!