本节使用的数据为下列链接中的表1、表2(机器学习算法——决策树7(预剪枝处理实例)_Vicky_xiduoduo的博客-CSDN博客)
1. 理论讲解
后剪枝是从训练集生成一棵完整决策树。上节已经分析了,未剪枝之前决策树的验证集精度为42.9%。
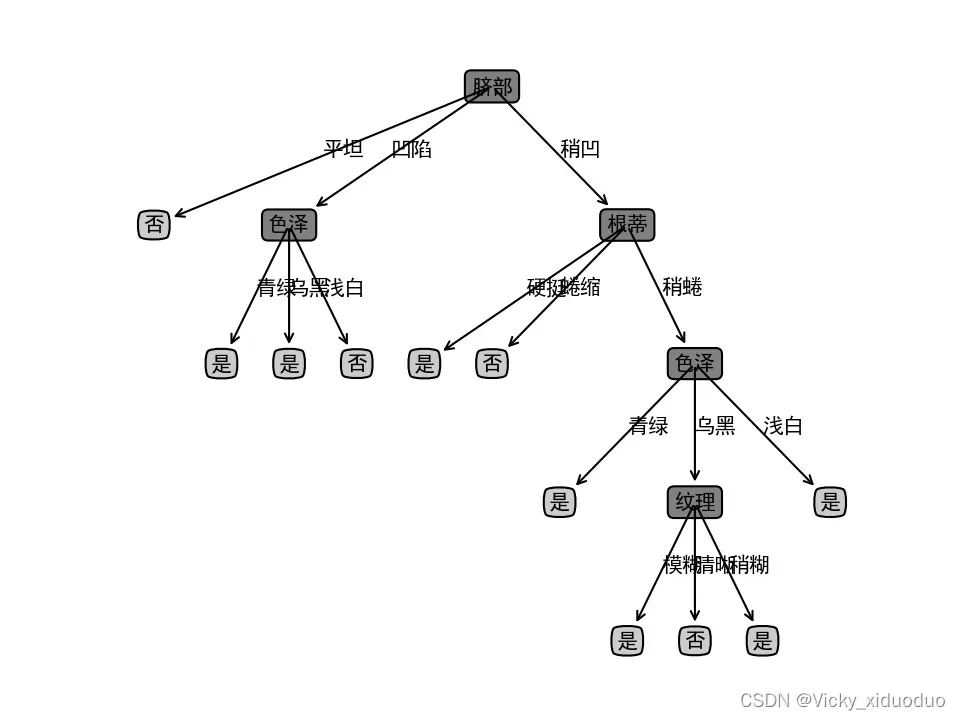
图1 未剪枝前的决策树
基于上图,后剪枝首先考虑纹理,若将其领衔的分支剪除,则相当于把纹理替换成叶节点,替换后的叶节点包含编号{7,15},于是,该叶节点的类别标记为“好瓜”,此时决策树验证集的精确度提升至57.1%。于是后剪枝策略决定剪枝。
然后考虑纹理的父节点“色泽”,若将其领衔的子树替换成叶结点,则替换后的叶结点包含编号{6,7,15},于是,该叶节点的类别标记为“好瓜”,此时决策树验证集的精确度提升至57.1%。所以可以不进行剪枝。
而后脐部的子节点“色泽”,若将其领衔的子树替换成叶结点,则替换后的叶结点包含编号{1,2,3,14},于是,该叶节点的类别标记为“好瓜”,此时决策树验证集的精确度提升至71.4%。于是,后剪枝策略决定剪枝。
对于节点“根蒂”和“脐部”,若将其领衔的子节点替换为子节点,则所得决策树的验证集的精确度分别为“71.4%”和“42.9%”,均未提高,于是它们被保留。
2. 代码实现
后剪枝一般指的是CCP代价复杂度剪枝法(Cost Complexity Pruning)。
即在树构建完成后,对树进行剪枝和简化,以最小化如下损失函数:
:叶节点数
:所有样本的个数
:第 i 个叶子节点上的样本数
:第i个叶子节点的损失函数
α:未定系数,用于惩罚节点数,引导模型使用更少的节点。
损失函数同时考虑了成本和树的复杂度,所以称为成本复杂度剪枝法。本质是在树的复杂性和准确性之间取得平衡。
代码显示如下:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
import graphviz
train_data = pd.read_csv('D:/Machine_Learning/西瓜数据集2.0划分出的训练集.csv', encoding='GBK')
#对象序列化
label = LabelEncoder()
for col in train_data[train_data.columns[:-1]]:
train_data[col] = label.fit_transform(train_data[col])
label_test = LabelEncoder()
for col in test_data[test_data.columns[:-1]]:
test_data[col] = label.fit_transform((test_data[col]))
id3 = DecisionTreeClassifier(criterion='entropy', random_state=0, ccp_alpha=0.2)#调整过的alpha,根据不纯度确定的
id3 = id3.fit(train_data.iloc[:, :-1].values.tolist(), train_data.iloc[:, -1].values)
#计算CCP路径
prunning_path = id3.cost_complexity_pruning_path(train_data.iloc[:, :-1].values.tolist(),
train_data.iloc[:, -1].values
)
print("ccp_alpha:", prunning_path['ccp_alphas'])
print("impurities:", prunning_path['impurities'])
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = export_graphviz(id3,
feature_names=labels,
class_names=['好瓜', '坏瓜'],
filled=True,
rounded=True,
fontname="Microsoft YaHei")
graph = graphviz.Source(dot_data)
graph.render("Post_tree")
打印出来的图片是:
表示,0<α<0.133时,不纯度为0;0.133<α<0.150时,不纯度为0.4等等等
最终的剪枝后决策树如下:
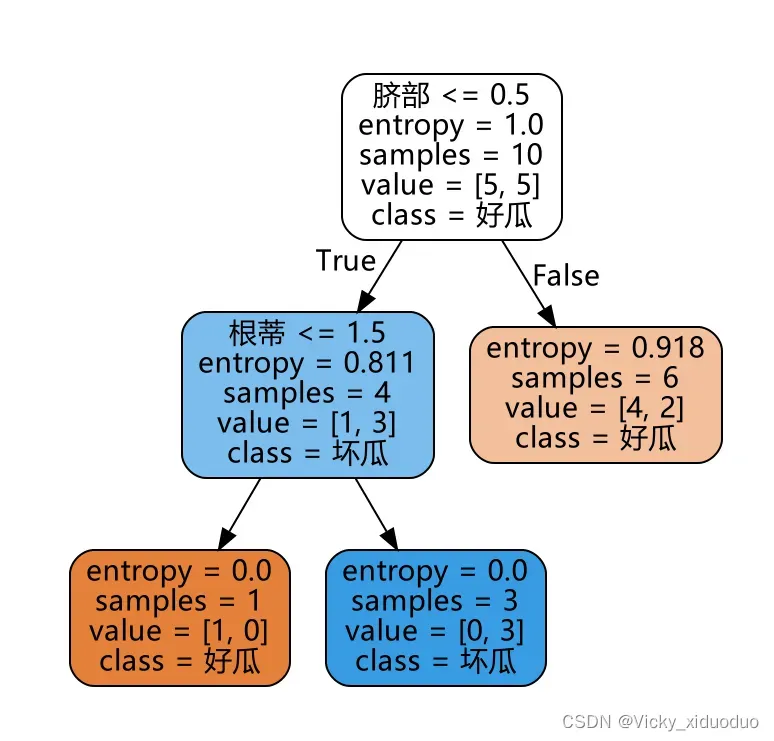
文章出处登录后可见!