动手教程,3D Python[0]
使用 K-means 和 Python 的 3D 点云聚类教程
用于创建 3D 语义分割数据集的完整 Python 实践指南。了解如何使用 K-Means 聚类通过无监督分割来转换未标记的点云数据。

如果您正在寻求一种用于语义分割的(有监督的)深度学习算法——关键词警报😁——你肯定会发现自己正在寻找一些高质量的标签 + 大量的数据点。
在我们的 3D 数据世界中,3D 点云的未标记性质使得回答这两个标准特别具有挑战性:没有任何好的训练集,很难“训练”任何预测模型。
我们是否应该探索 python 技巧并将它们添加到我们的 quiver 以快速生成出色的 3D 标记点云数据集?
让我们潜入水中! 🤿
无监督工作流聚类前言
为什么无监督分割和聚类是“人工智能的主体”?
通过监督系统进行深度学习 (DL) 非常有用。深度学习架构在过去几年深刻地改变了技术格局。然而,如果我们想创造出色的机器,深度学习需要进行质的更新——拒绝越大越好的观念。今天有几种方法可以实现这一里程碑,最重要的是,无监督或自我监督的方向是游戏规则的改变者。

聚类算法通常用于探索性数据分析。它们还构成了 AI 分类管道中的大部分过程,以无监督/自学习的方式创建标记良好的数据集。
这句话摘自上一篇文章“聚类高维数据的基础”,总结了我们的驱动程序,以快速探索创建半自动标签管道的动手方法。令人兴奋!但是,当然,如果您觉得需要对理论进行一些快速复习,您可以在下面的文章中找到完整的解释。
如何定义聚类?
一句话,聚类意味着将相似的项目或数据点组合在一起。 K-means 是一种计算这种聚类的特定算法。
那么我们可能想要聚类的那些数据点是什么?这些可以是任意点,例如使用 LiDAR 扫描仪记录的 3D 点。

但它们也可以表示数据集中的空间坐标、颜色值(图像、点云等),或其他特征,例如从图像中提取的关键点描述符,以构建单词字典包。



您可以将它们视为空间中的任意向量,每个向量都包含一组属性。然后,我们在定义的“特征空间”中收集许多这些向量,并希望用少量代表来表示它们。但这里最大的问题是,这些代表应该是什么样子?
K-Means 聚类
K-Means 是一种非常简单且流行的算法来计算这种聚类。它通常是一个无监督的过程,因此我们不需要任何标签,例如分类问题。
我们唯一需要知道的是距离函数。告诉我们两个数据点彼此相距多远的函数。在最简单的形式中,这是欧几里得距离。但根据您的应用,您可能还需要选择不同的距离函数。然后,我们可以确定两个数据点是否彼此相似,从而确定它们是否属于同一个集群。
K-Means 是如何工作的?
它用 K 个代表表示所有数据点,这就是算法的名称。所以K是我们放入系统的用户定义的数字。例如,取所有数据点并用空间中的三个点表示它们。

所以在上面的例子中,蓝点是输入数据点,我们设置 K=3。这意味着我们想用三个不同的代表来表示这些数据点。然后用红色点表示的那些代表将数据点的相应分配定向到“最佳”代表。然后我们得到三个点簇,绿色、紫色和黄色。
K-means 以最小化数据点与其最接近的代表之间的平方距离的方式做到这一点。实现这一点的算法部分通过两个简单的步骤迭代重构:初始化和赋值:
- 我们随机初始化 K 个质心点作为代表,并计算每个数据点与最近质心的数据关联。所以这是我们在这里做的最近邻查询。
- 每个数据点都被分配到其最近的质心,然后我们重新配置空间中每个质心的位置。它是通过从分配给该质心的所有数据点中计算主向量来完成的,这会改变其位置。
所以在算法的下一次迭代中,我们会得到一个新的赋值,然后是一个新的质心位置,我们重复这个过程直到收敛。

💡提示:我们应该注意,K-Means 不是最优算法。这意味着 K-Means 试图最小化距离函数,但我们不能保证找到全局最小值。因此,根据您的起始位置,您可能会得到不同的 K-Means 聚类结果。假设我们想以快速的方式实现 K-Means。在这种情况下,我们通常需要在我们的空间中有一个近似的最近邻函数,因为这是使用该算法完成的最耗时的操作。好消息,我稍后会提示 k-means++ 😉。
因此,K-Means 是一种相对简单的两步迭代方法,用于在高维空间中为潜在的大量数据点寻找代表。现在理论已经结束,让我们通过五个步骤深入了解一个有趣的 Python 代码实现🤲!
1.点云工作流定义
航空激光雷达点云数据集
我们动手教程的第一步是收集一个不错的数据集!这一次,我想分享另一个寻找酷炫 LiDAR 数据集的好地方:法国国家地理研究所的 Geoservices。法国 IGN 的 LiDAR HD 活动开始了 OpenData 收集,您可以在其中获得法国某些地区的清晰 3D 点云!
我进入上面的门户,选择了一个图块,从中提取了一个子图块,删除了地理配准信息,准备了 LiDAR 文件的一些额外属性部分,然后在我的 Open Data Drive 文件夹中提供了它。您感兴趣的数据是 KME_planes.xyz 和 KME_cars.xyz。如果您想在线可视化它们,您可以跳转到 Flyvast WebGL 提取。[0][1]
整体循环策略
我建议遵循一个简单的过程,您可以复制该过程来标记您的点云数据集,如下图所示。
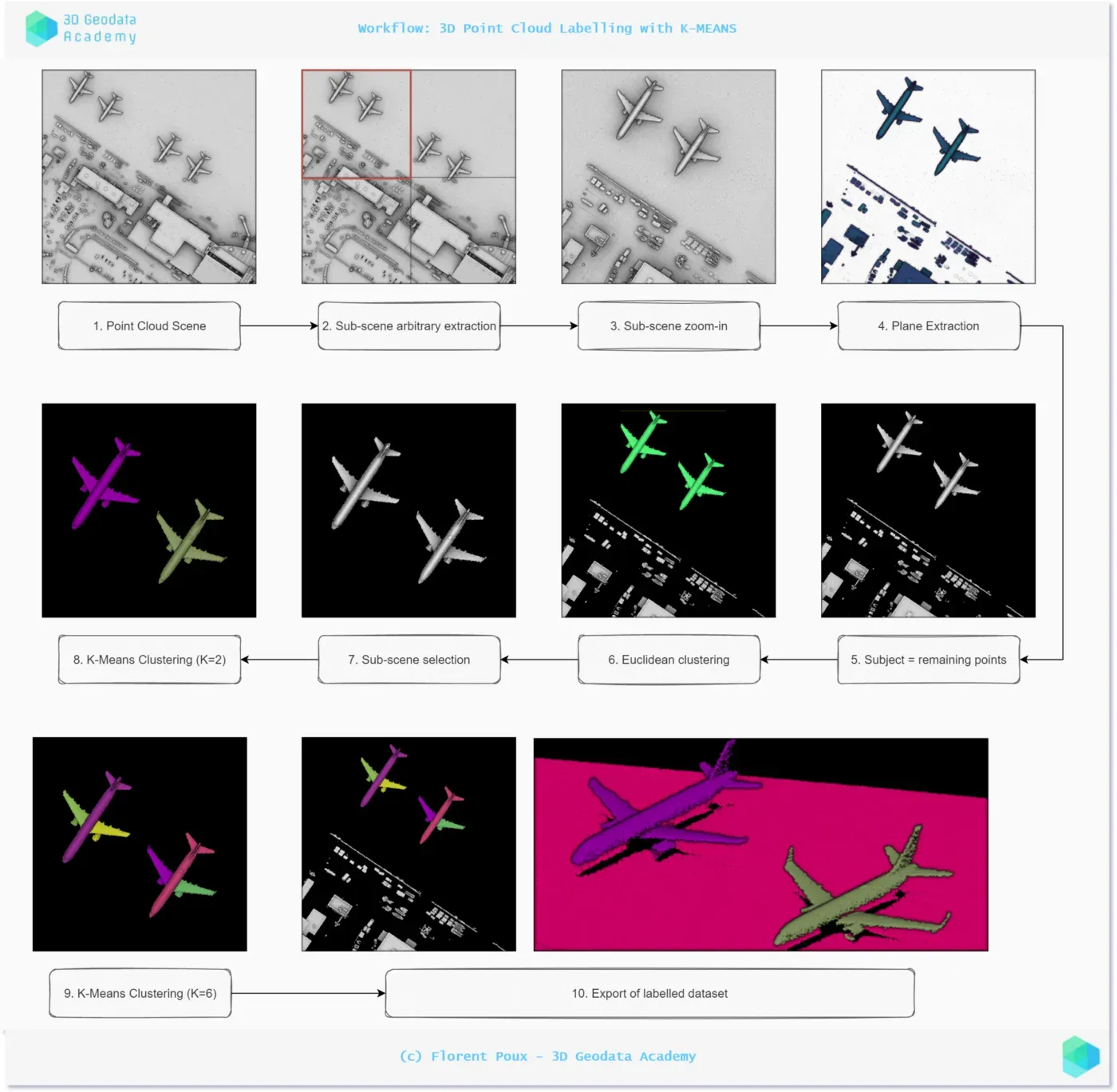
🤓 注意:该策略是从我在 3D Geodata Academy 主持的在线课程中提供的一份文件中摘录的。本教程将涵盖步骤 7 到 10,其他步骤将在课程中深入介绍,或者按照下面的编码指南进行。[0]
2. 设置我们的 3D python 上下文
在这个动手点云教程中,我专注于高效和最少的库使用。我们可以使用 open3d、pptk、pytorch3D 等其他库来完成所有操作……但为了掌握 Python,我们将使用 NumPy、Matplotlib 和 ScikitLearn 来完成所有操作。六行代码来启动你的脚本:
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d
from sklearn.cluster import KMeans
from sklearn.cluster import DBSCAN很好,从那里开始,我建议我们相对表达我们的路径,将包含我们数据集的 data_folder 与数据集名称分开,以便在运行中轻松切换:
data_folder=”../DATA/”
dataset=”KME_planes.xyz”从那里,我想说明一个用 Numpy 加载点云的好技巧。直观的方法是将所有内容加载到 pcd 点云变量中,例如 pcd=np.loadtxt(data_folder+dataset)。但是因为我们将使用这些功能,所以让我们通过动态解压缩变量中的每一列来节省一些时间。 Numpy 有多酷? 😆
x,y,z,illuminance,reflectance,intensity,nb_of_returns = np.loadtxt(data_folder+dataset,skiprows=1, delimiter=’;’, unpack=True)好的!我们现在有一切可以玩!由于 K-Means 的本质,我们必须小心地面元素无所不在,这会提供如下奇怪的东西:
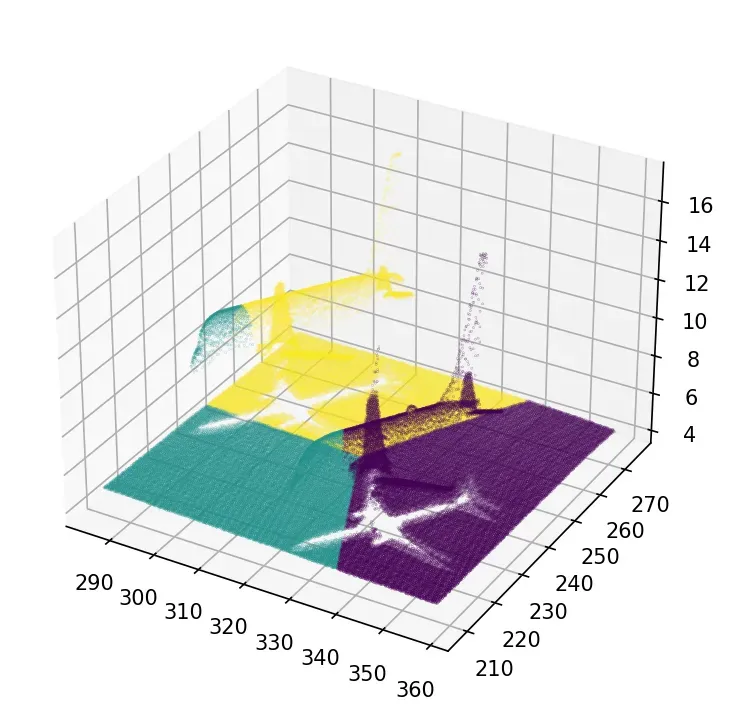
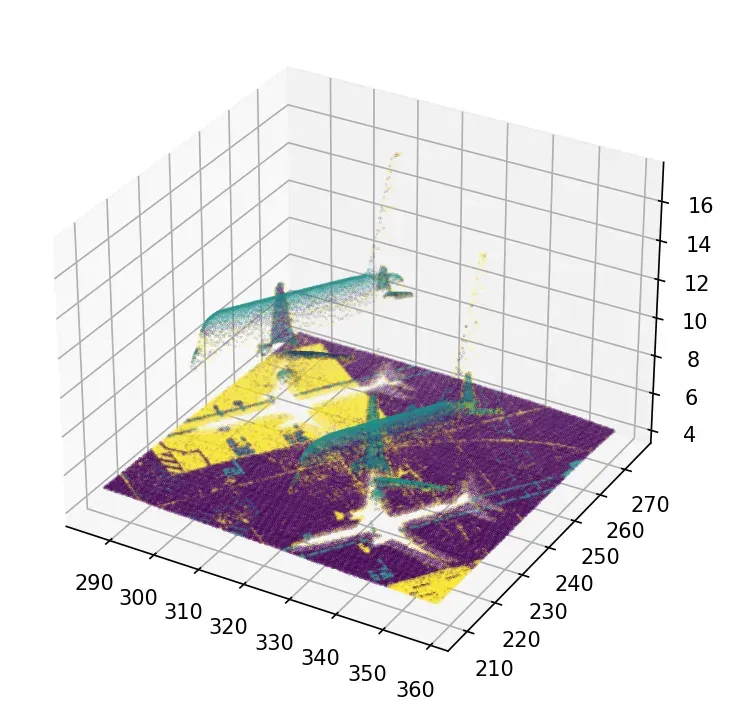
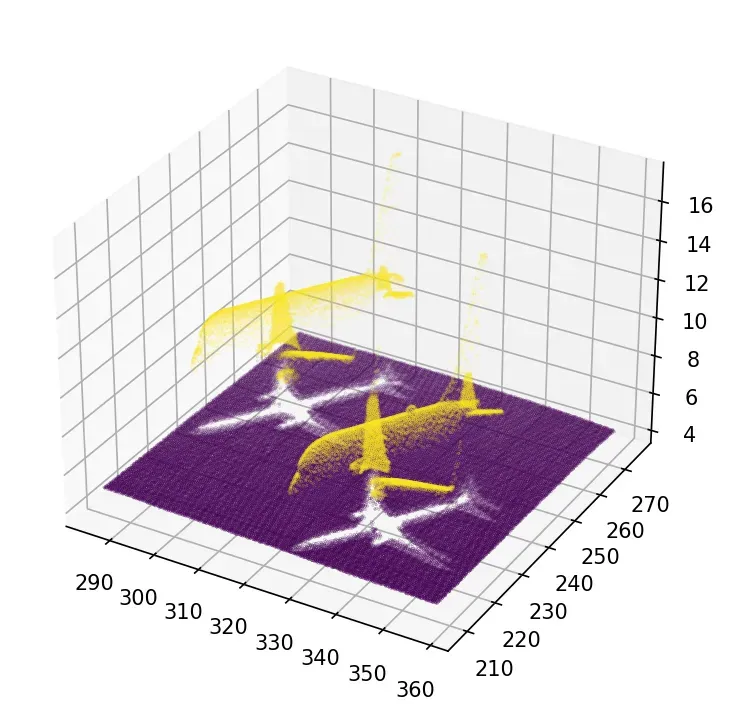
为了避免奇怪的结果,我们应该处理我们认为的异常值,即地面。下面是一个直接的技巧,没有注入太多限制性的知识。
3.点云快速选择
让我通过 Matplotlib 说明如何通过一个微小的监督步骤来处理这个问题。它还允许我为您提供在子图创建和线分层时总是派上用场的代码。我们将检查两个视图的 2D 图,我们的点的平均值落在哪里,看看这是否有助于在后面的步骤中过滤掉地面。
首先,让我们创建一个 subplot 元素,它将在 X、Z 视图上保存我们的点,并绘制浇注空间坐标的平均值:
plt.subplot(1, 2, 1) # row 1, col 2 index 1
plt.scatter(x, z, c=intensity, s=0.05)
plt.axhline(y=np.mean(z), color=’r’, linestyle=’-’)
plt.title(“First view”)
plt.xlabel(‘X-axis ‘)
plt.ylabel(‘Z-axis ‘)💡提示:如果你看线内,我使用强度场作为我们情节的着色元素。我可以这样做,因为它已经以 [0,1] 间隔标准化。 s 代表大小,允许我们给我们的点一个大小。 😉
然后,让我们做同样的技巧,但这次是在 Y、Z 轴上:
plt.subplot(1, 2, 2) # index 2
plt.scatter(y, z, c=intensity, s=0.05)
plt.axhline(y=np.mean(z), color=’r’, linestyle=’-’)
plt.title(“Second view”)
plt.xlabel(‘Y-axis ‘)
plt.ylabel(‘Z-axis ‘)从那里,我们可以使用以下命令绘制绘图:
plt.show()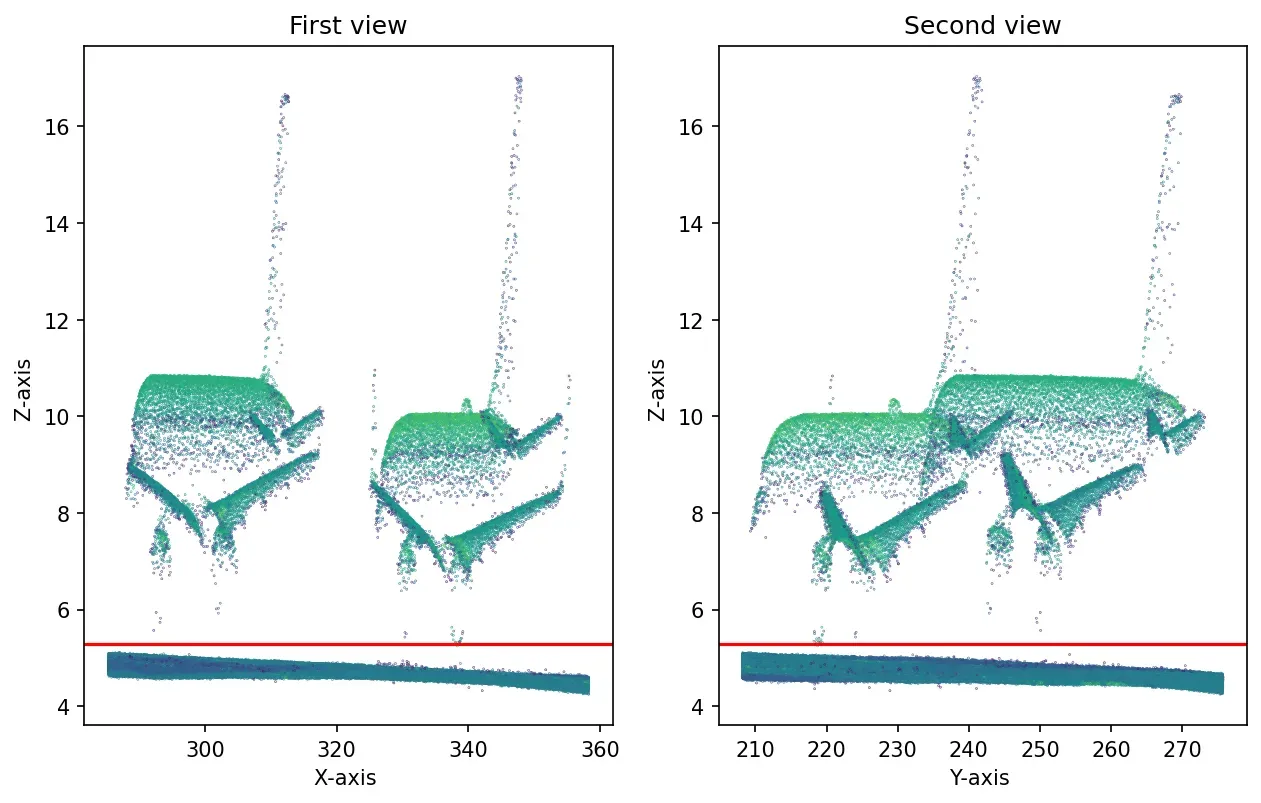
哈哈,好看吗?代表平均值的红线看起来可以让我们很好地过滤掉地面元素!所以,让我们使用它吧!
4.点云过滤
好的,我们想找到一个掩码,允许我们摆脱不满足查询的点。我们感兴趣的查询只考虑 Z 值高于平均值的点,z>np.mean(z)。我们将结果存储在变量 spatial_query 中:
pcd=np.column_stack((x,y,z))
mask=z>np.mean(z)
spatial_query=pcd[z>np.mean(z)]💡提示:Numpy 的 column_stack 函数非常方便,但要小心,因为如果应用于太大的向量,它会产生开销。尽管如此,使用一组特征向量非常方便。
然后,您可以通过查看过滤后的点数来快速验证它是否有效:
pcd.shape==spatial_query.shape
[Out] False现在,让我们用以下命令绘制结果,这次是 3D:
#plotting the results 3D
ax = plt.axes(projection=’3d’)
ax.scatter(x[mask], y[mask], z[mask], c = intensity[mask], s=0.1)
plt.show()同样,如果您想要一个与我们的 LiDAR HD 数据完美匹配的顶视图:
#plotting the results 2D
plt.scatter(x[mask], y[mask], c=intensity[mask], s=0.1)
plt.show()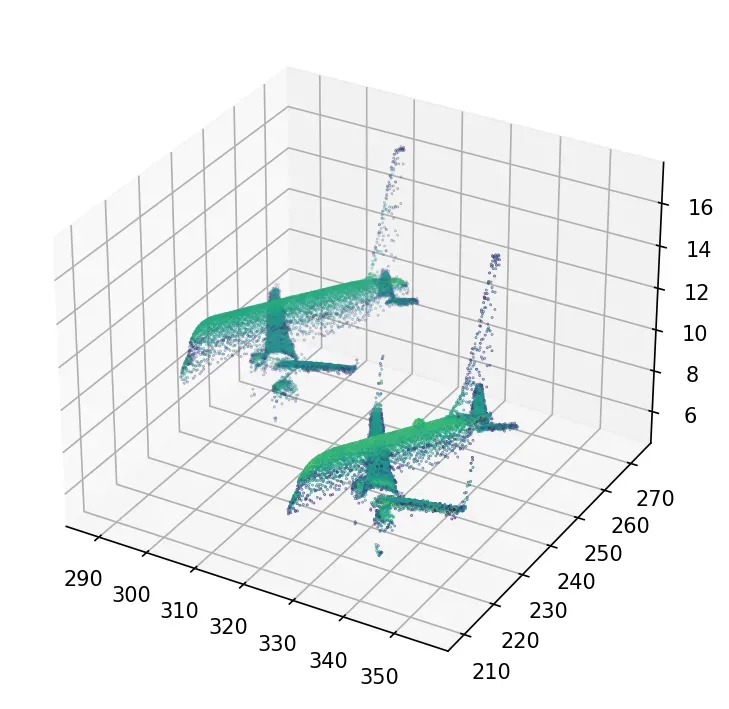
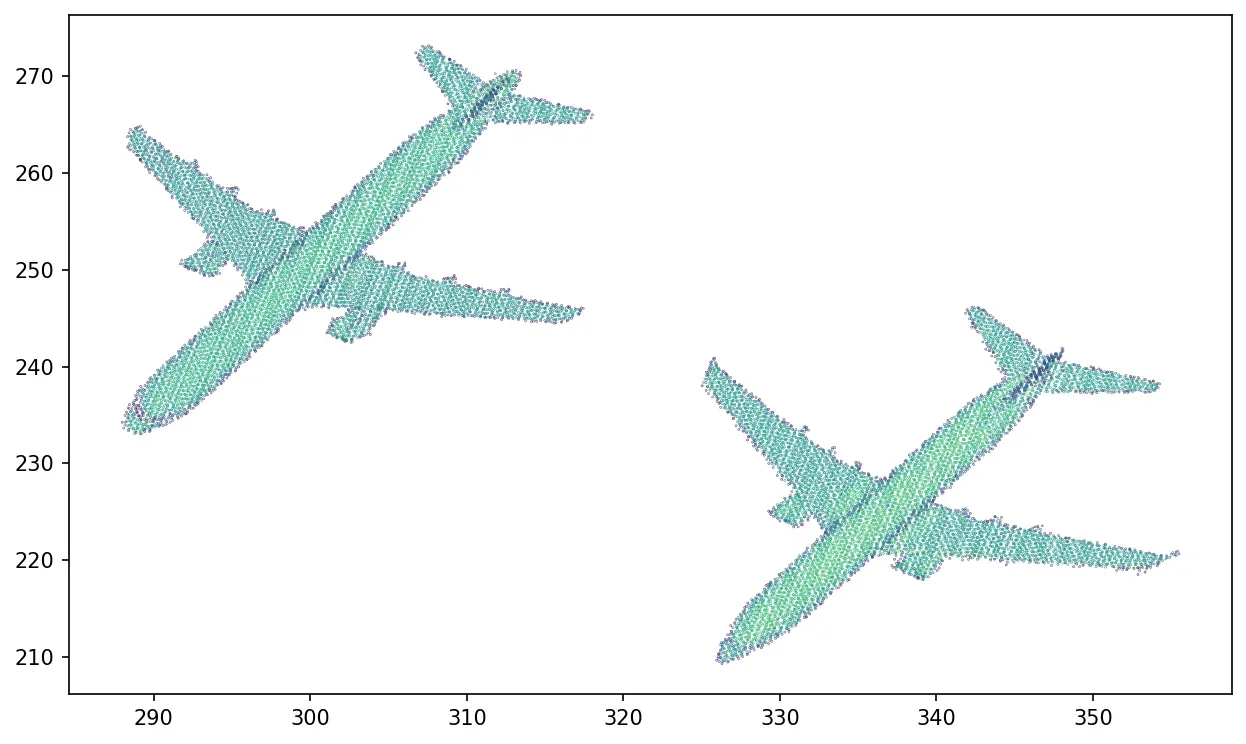
非常好,我们摆脱了烦人的异常点,现在我们可以专注于这两个平面并尝试将语义附加到每个平面上。
5. K-Means 聚类实现
高水平的 Scikit-learn 库的构建会让你开心。只需一行代码,我们就可以拟合聚类 K-Means 机器学习模型。我将强调标准符号,我们的数据集通常表示为 Xto train 或 fit on。在第一种情况下,让我们创建一个仅包含掩码后的 X、Y 特征的特征空间:
X=np.column_stack((x[mask], y[mask]))从那里,我们将运行我们的 k-means 实现,K=2,看看我们是否可以自动检索这两个平面:
kmeans = KMeans(n_clusters=2).fit(X)
plt.scatter(x[mask], y[mask], c=kmeans.labels_, s=0.1)
plt.show()💡提示:我们通过调用 sklearn.cluster._kmeans.KMeans kmeans 对象上的 .labels_ 方法从 k-means 实现中检索标签的有序列表。这意味着我们可以直接将列表传递给散点图的颜色参数。
如下所示,我们在两个集群中正确检索了两个平面!增加集群的数量 (K) 将提供不同的结果,您可以对其进行试验。
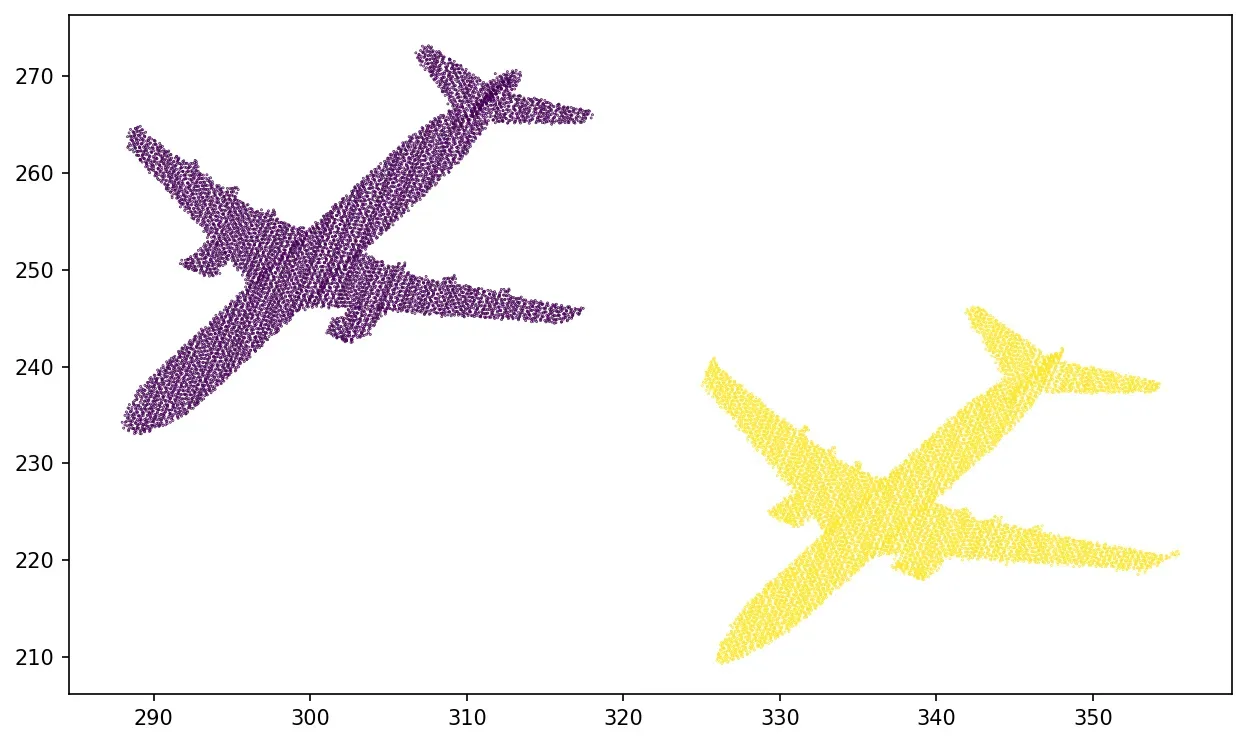
选择正确数量的聚类一开始可能并不那么明显。如果我们想要一些启发式方法来帮助以无监督的方式决定这个过程,我们可以使用 Elbow 方法。我们正在使用 Elbow 方法中的参数 K,即我们想要提取的簇数。
为了实现该方法,我们将循环 K,例如,在 [1:20] 的范围内,使用 K 参数执行我们的 K-Means 聚类,并计算我们将存储的 WCSS(聚类内平方和)值在一个列表中。
💡提示:init 参数是初始化质心的方法,这里我们将其设置为 k-means++ 进行聚类,重点是加快收敛速度。然后,通过 kmeans.inertia_ 的 wcss 值表示每个点与簇中质心之间的距离平方和。
X=np.column_stack((x[mask], y[mask], z[mask]))
wcss = []
for i in range(1, 20):
kmeans = KMeans(n_clusters = i, init = ‘k-means++’, random_state = 42)
kmeans.fit(X)
wcss.append(kmeans.inertia_)🦩趣闻:如果你注意k-means线的细节,你可能想知道为什么是42?好吧,没有聪明的理由😆。 42这个数字在科学界一直是个笑话,它源自传奇的《银河系漫游指南》,其中一台名为 Deep Thought 的巨大超级计算机计算出“生命终极问题的答案……”。[0]
然后,一旦我们的 wcss 列表完成,我们可以根据 K 值绘制 wcss 图形,哪种看起来像 Elbow(可能这与方法的名称有关?🤪)。
plt.plot(range(1, 20), wcss)
plt.xlabel(‘Number of clusters’)
plt.ylabel(‘WCSS’)
plt.show()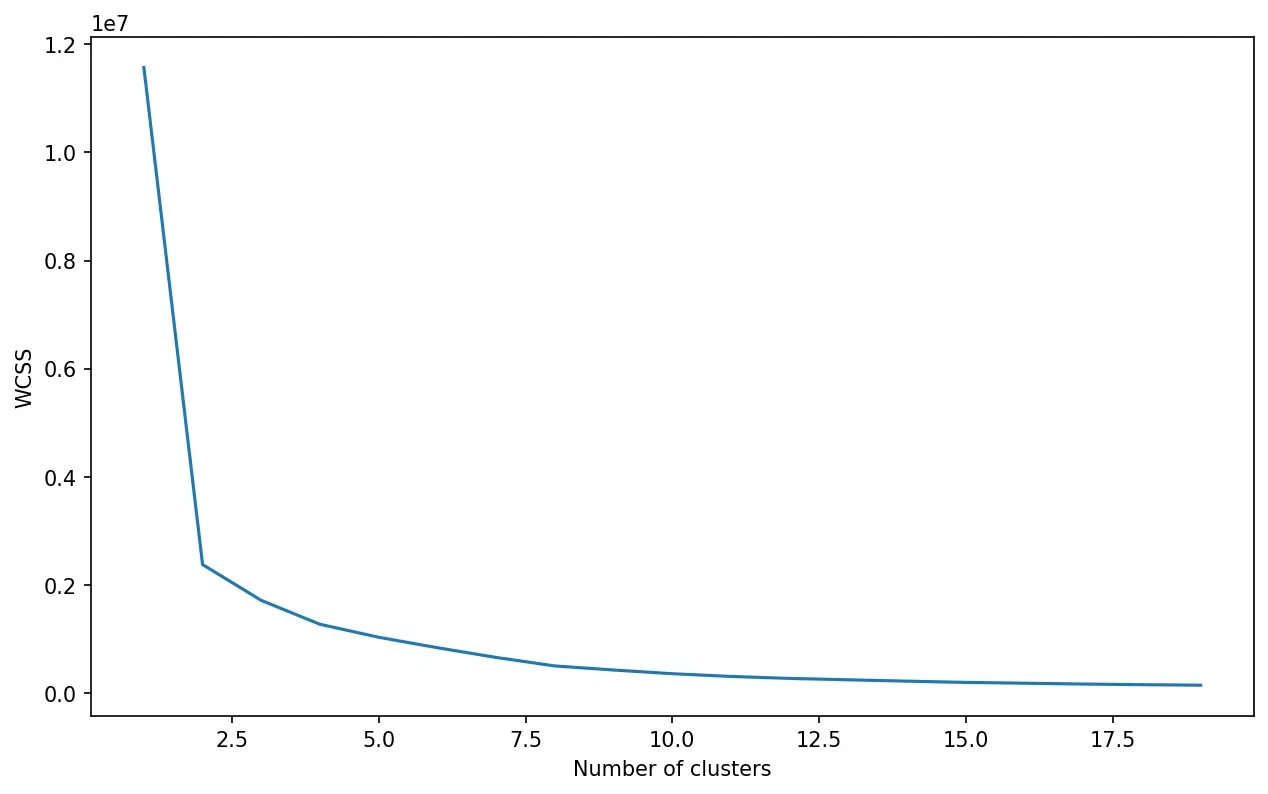
这看起来很神奇,因为我们看到创建肘部形状的值位于许多 2 的集群中,这非常有意义 😁。
与 DBSCAN 的聚类比较
在之前的文章中,我们深入研究了使用 DBSCAN 进行聚类。
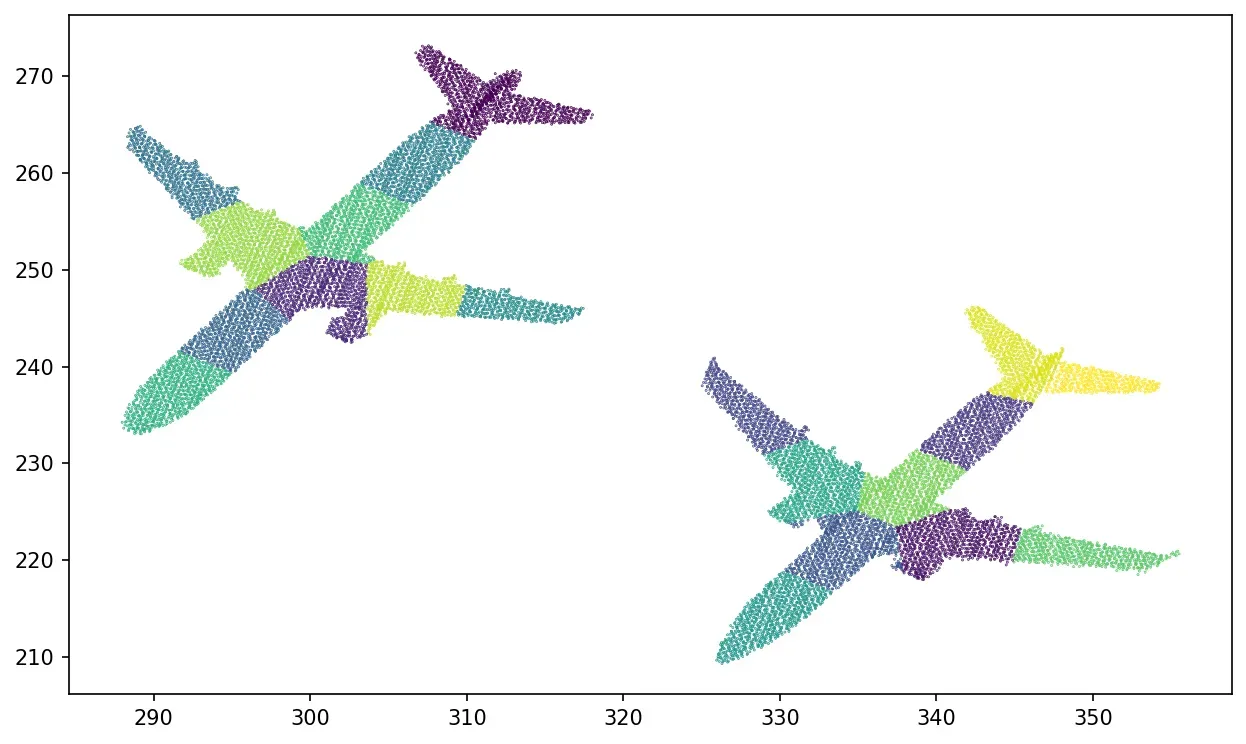
如果您遵循它,您可能想知道在 3D 点云的情况下,K-Means 相对于 DBSCAN 的真正优势是什么?好吧,让我来说明您可能想要切换的情况。我提供了空中 LiDAR 数据集的另一部分,其中包含三辆彼此靠近的汽车。如果我们在 K=3 的情况下运行 K-Means,我们会得到:
data_folder="../DATA/"
dataset="KME_cars.xyz"
x,y,z,r,g,b = np.loadtxt(data_folder+dataset,skiprows=1, delimiter=';', unpack=True)
X=np.column_stack((x,y,z))
kmeans = KMeans(n_clusters=3).fit(X)
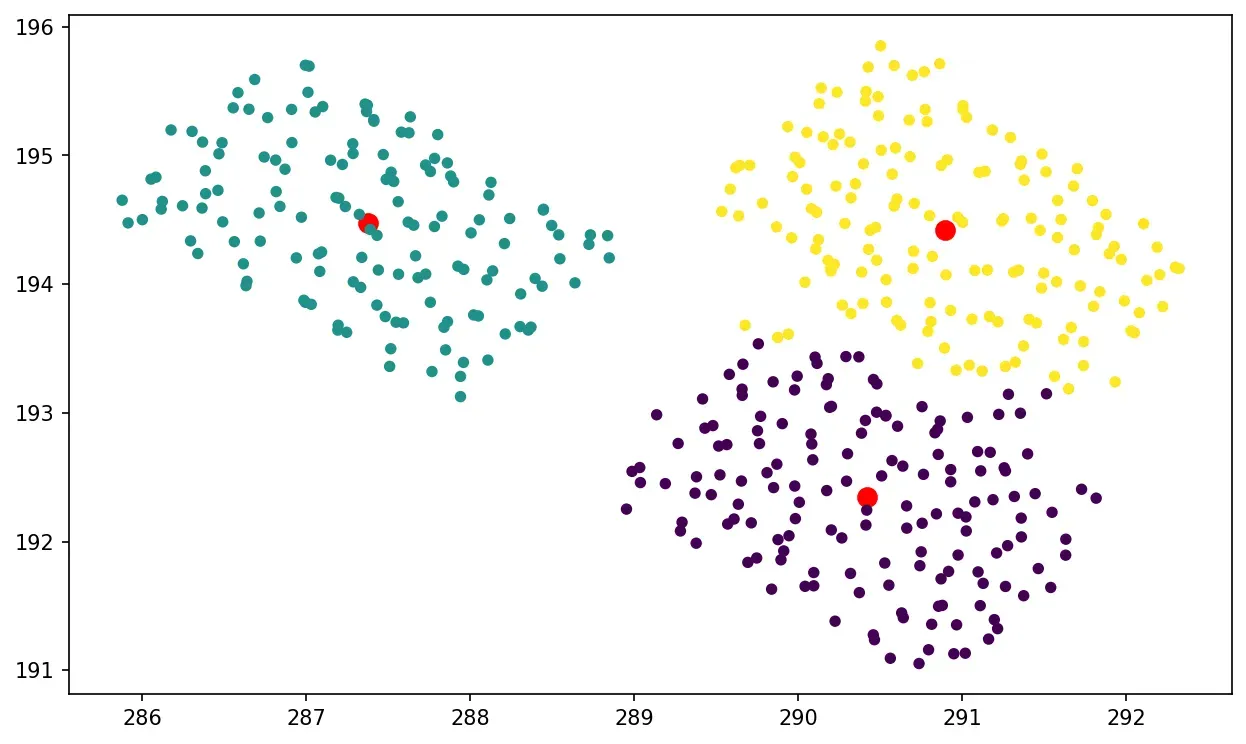
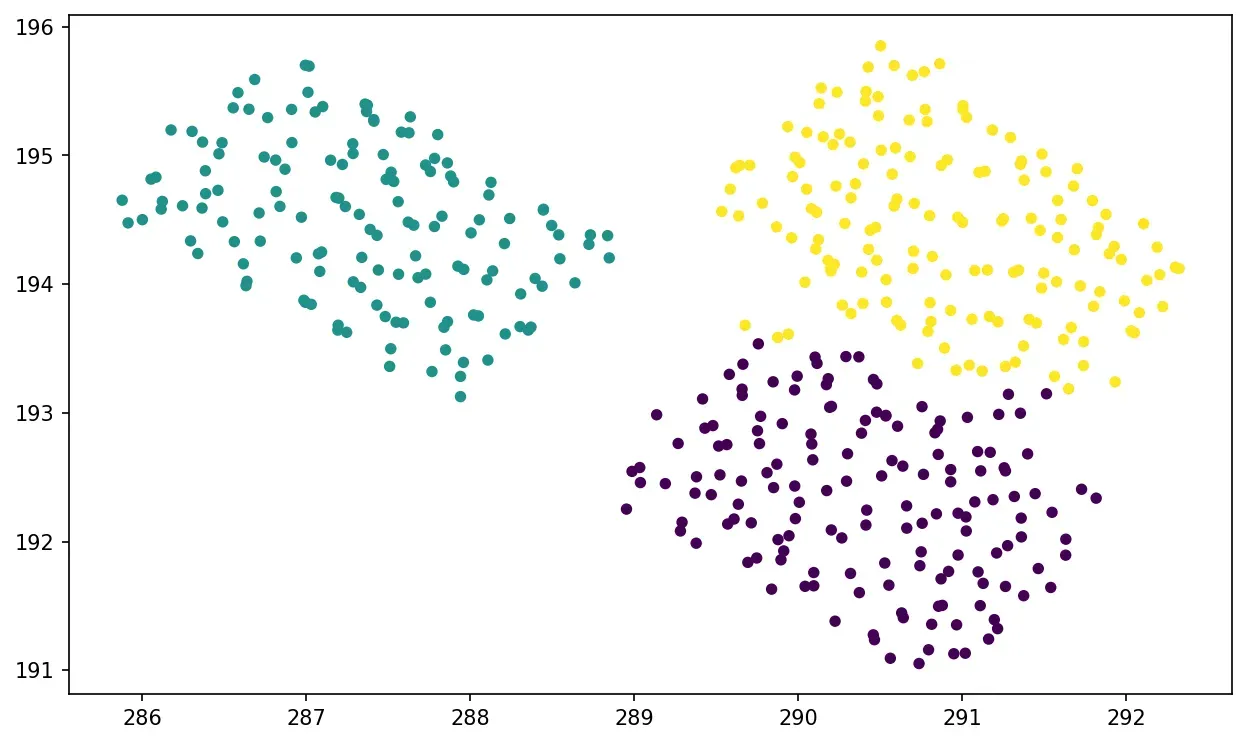
如您所见,即使我们无法在空间上描绘对象,我们也可以获得出色的聚类。 DBSCAN 是什么样的?好吧,让我们检查下面的代码行:
#analysis on dbscan
clustering = DBSCAN(eps=0.5, min_samples=2).fit(X)
plt.scatter(x, y, c=clustering.labels_, s=20)
plt.show()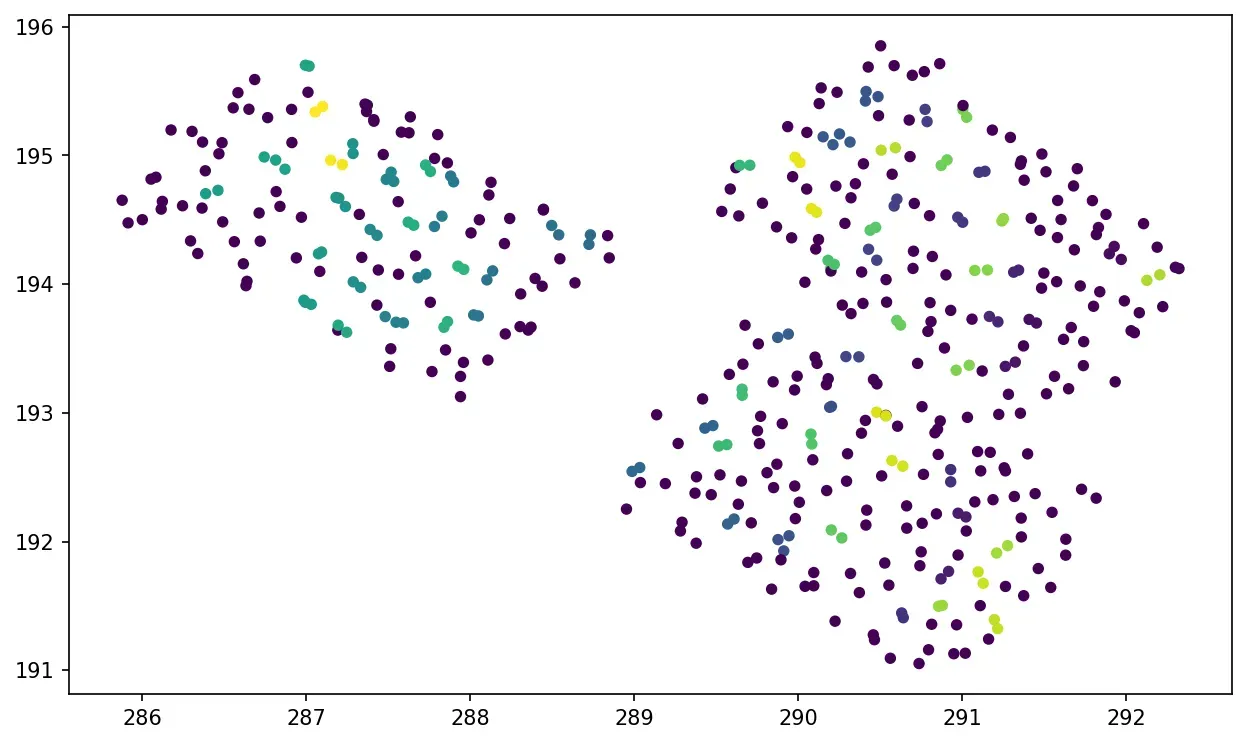
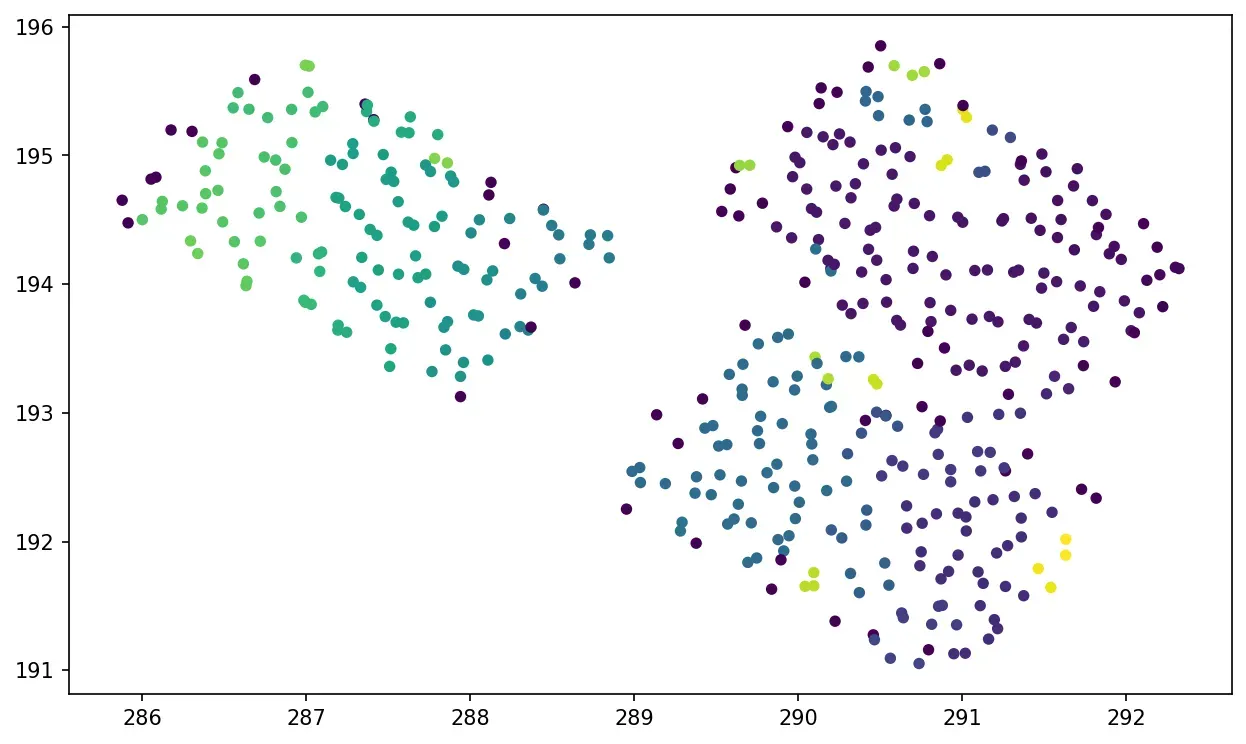
正如你所看到的,除了难以设置 epsilon 参数之外,我们无法描绘出右边的两辆车,至少通过这些特征。在这种情况下,K-Means 为 1–0 🙂。
玩转特征空间。
目前,我们仅使用空间特征来说明 K-Means。但是我们可以使用任何功能组合,这使得在不同的应用程序上使用起来超级灵活!
出于本教程的目的,您还可以使用照度、强度、返回次数和反射率进行实验。

以下是使用这些功能的两个示例:
X=np.column_stack((x[mask], y[mask], z[mask], illuminance[mask], nb_of_returns[mask], intensity[mask]))
kmeans = KMeans(n_clusters=3, random_state=0).fit(X)
plt.scatter(x[mask], y[mask], c=kmeans.labels_, s=0.1)
plt.show()或再次
X=np.column_stack((z[mask] ,z[mask], intensity[mask]))
kmeans = KMeans(n_clusters=4, random_state=0).fit(X)
plt.scatter(x[mask], y[mask], c=kmeans.labels_, s=0.1)
plt.show()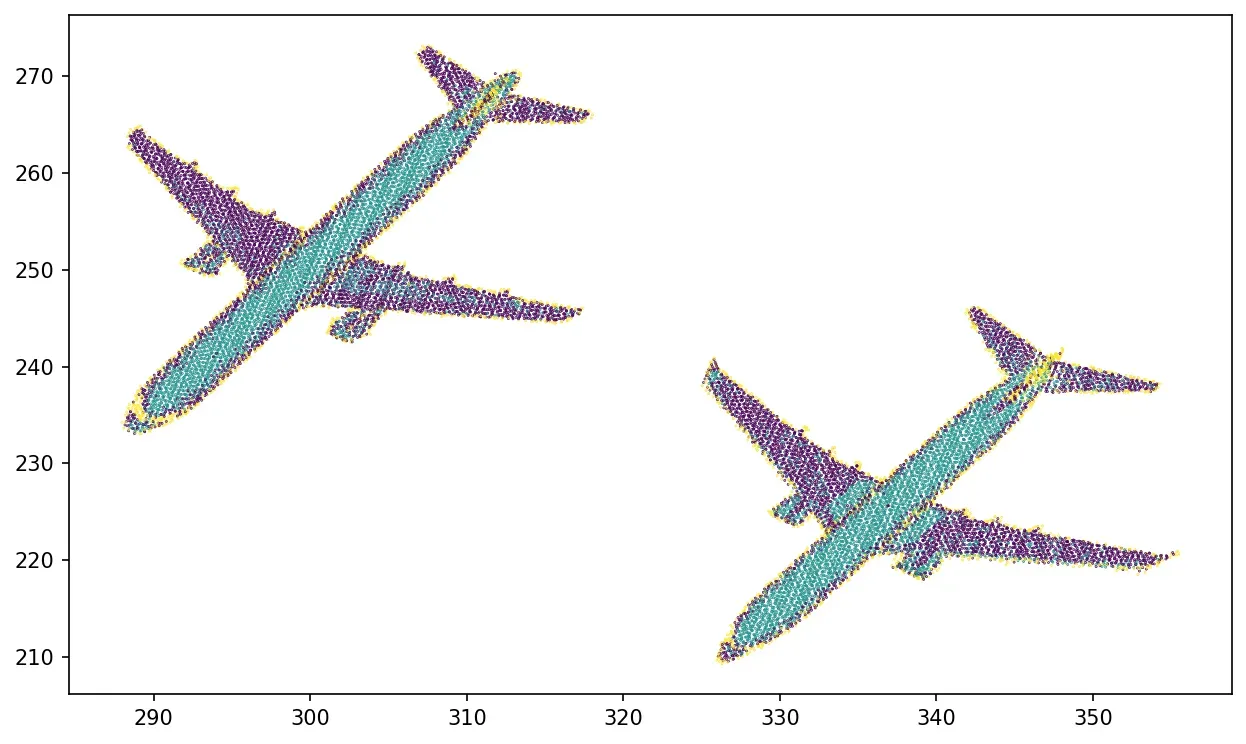
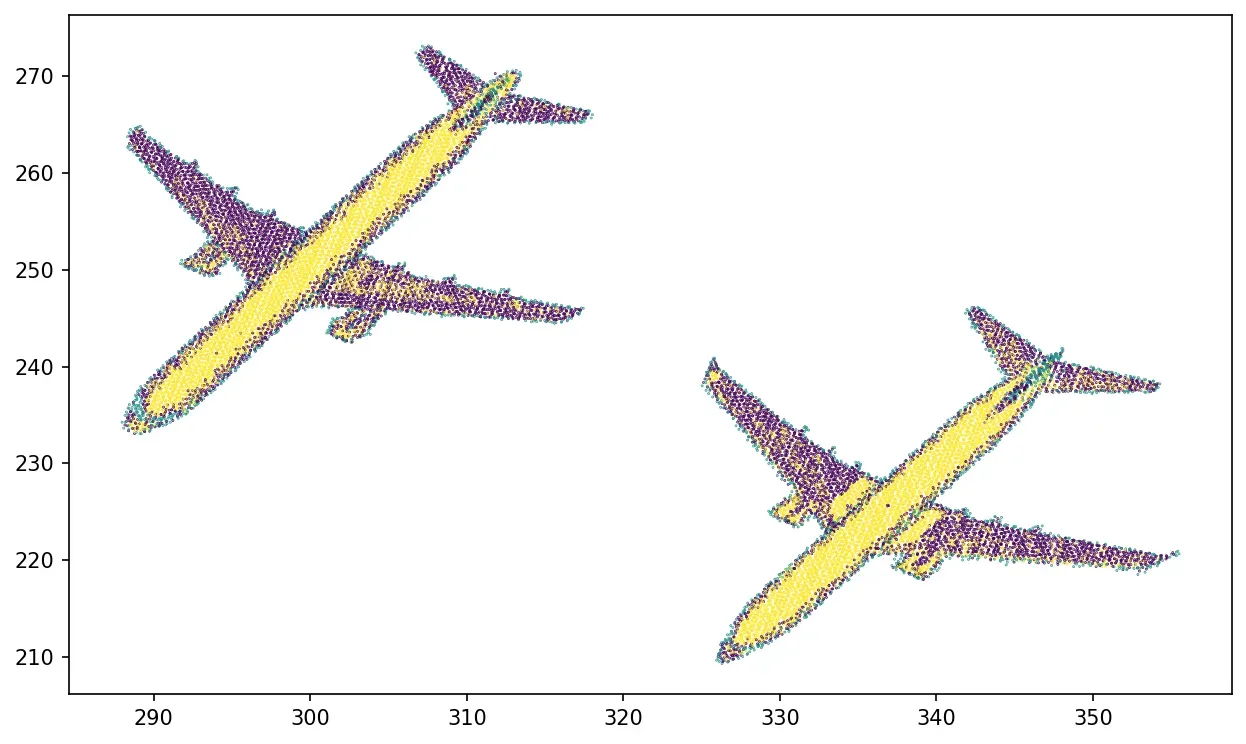
更深入地讲,我们可以更好地描述每个点周围的局部邻域,例如,通过主成分分析。实际上,这可以允许提取大量或多或少相关的几何特征。它将超出当前文章的范围,但您可以确定我稍后会针对特定问题深入探讨它。您还可以通过点云处理器在线课程直接深入了解 PCA 专业知识。[0]
最后,我们只需将数据导出到一个连贯的结构,例如,一个 .xyz ASCII 文件,只包含可以在外部软件中读取的带有标签信息的空间坐标:
result_folder=”../DATA/RESULTS/”
np.savetxt(result_folder+dataset.split(“.”)[0]+”_result.xyz”, np.column_stack((x[mask], y[mask], z[mask],kmeans.labels_)), fmt=’%1.4f’, delimiter=’;’)如果您想让它直接工作,我还创建了一个 Google Colab 脚本,您可以在此处访问:To the Python Google Colab script。[0]
Conclusion
热烈祝贺🎉!您刚刚学习了如何通过 K-Means 聚类开发自动半监督分割,当语义标签与 3D 数据不可用时,它非常方便。我们了解到,我们仍然可以通过调查数据中固有的几何模式来推断语义信息。
真诚的,干得好!但这条路肯定不会到此结束,因为您刚刚释放了智能流程的巨大潜力,可以在细分级别进行推理!
未来的文章将深入探讨点云空间分析、文件格式、数据结构、对象检测、分割、分类、可视化、动画和网格划分。
走得更远
存在其他用于点云的高级分割方法。这是我深入参与的一个研究领域,您已经可以在文章 [1-6] 中找到一些精心设计的方法。一些全面的教程即将推出,用于更高级的 3D 深度学习架构!
- Poux, F. 和 Billen, R. (2019)。基于体素的 3D 点云语义分割:无监督几何和关系特征与深度学习方法。 ISPRS 国际地理信息杂志。 8(5),213; https://doi.org/10.3390/ijgi8050213 — Jack Dangermond 奖(链接到新闻报道)[0][1]
- Poux, F.、Neuville, R.、Nys, G.-A. 和 Billen, R. (2018)。 3D 点云语义建模:室内空间和家具的集成框架。遥感, 10(9), 1412. https://doi.org/10.3390/rs10091412[0]
- Poux, F.、Neuville, R.、Van Wersch, L.、Nys, G.-A. 和 Billen, R. (2017)。考古学中的 3D 点云:应用于准平面物体的采集、处理和知识集成的进展。地球科学, 7(4), 96. https://doi.org/10.3390/GEOSCIENCES7040096[0]
- Poux, F., Mattes, C., Kobbelt, L., 2020。室内 3D 点云的无监督分割:应用于基于对象的分类,ISPRS — 国际摄影测量、遥感和空间信息科学档案。第 111-118 页。 https://doi:10.5194/isprs-archives-XLIV-4-W1-2020-111-2020[0]
- Poux, F., Ponciano, J.J., 2020。用于 3d 室内点云实例分割的自学习本体,ISPRS — 国际摄影测量、遥感和空间信息科学档案。第 309-316 页。 https://doi:10.5194/isprs-archives-XLIII-B2-2020-309-2020[0]
- Bassier, M., Vergauwen, M., Poux, F., (2020)。用于建筑内部分类的点云与网格特征。遥感。 12, 2224. https://doi:10.3390/rs12142224[0]
文章出处登录后可见!