TensorRT
 CUDA和TensorRT都是由NVIDIA开发的用于加速深度学习推理的工具。
CUDA和TensorRT都是由NVIDIA开发的用于加速深度学习推理的工具。
CUDA是NVIDIA提供的一个并行计算平台和编程模型,可以利用GPU的并行计算能力加速各种计算任务,包括深度学习。CUDA提供了一组API和工具,使得开发者可以方便地在GPU上编写高效的并行代码。
TensorRT是NVIDIA开发的一个深度学习推理引擎,可以将训练好的深度学习模型优化并加速,使得在GPU上的推理速度更快。TensorRT使用了一系列的技术,包括网络剪枝、层融合、权重量化和动态张量内存管理等,来减少模型的计算量和内存占用,并利用GPU的硬件特性进行加速。
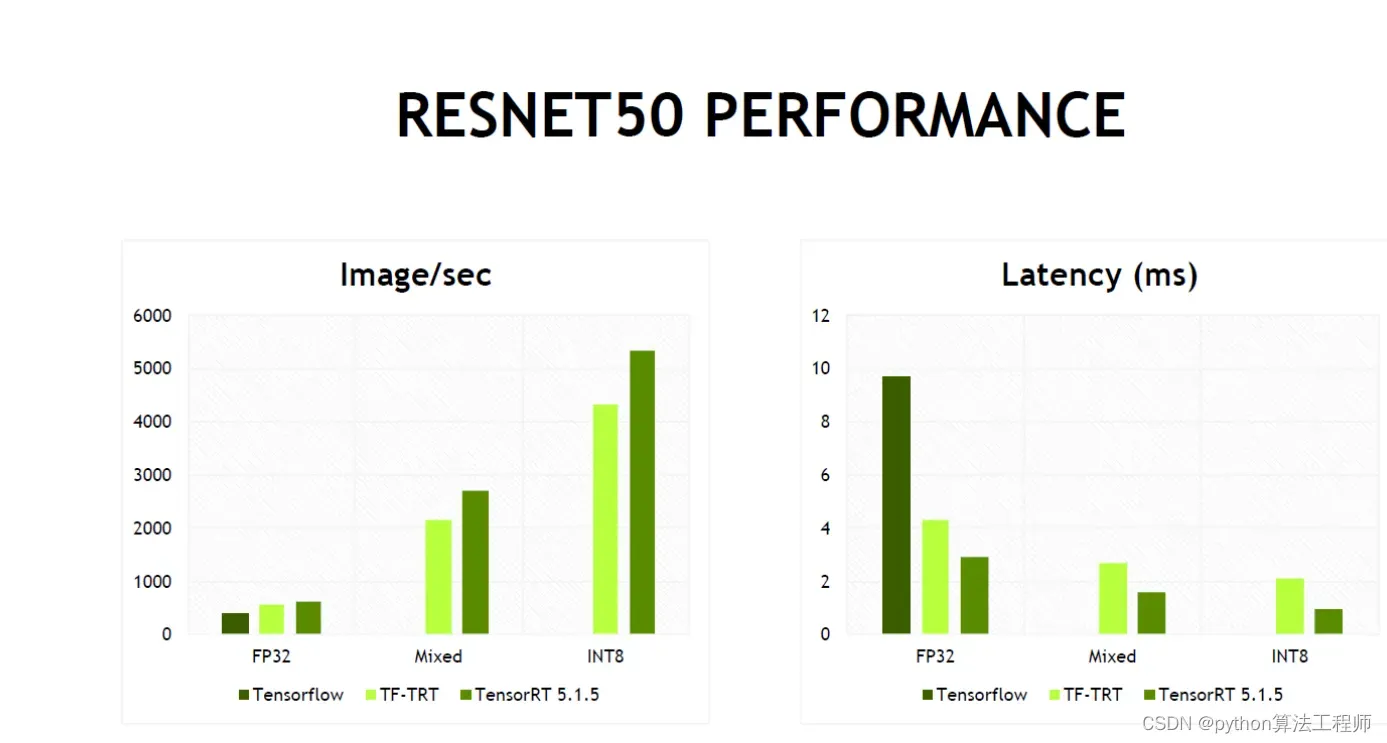
相对于CUDA,TensorRT的加速效果更为明显。TensorRT可以将深度学习模型的推理速度提高数倍,甚至数十倍。这是因为TensorRT使用了更加高效的算法和技术,并且充分利用了GPU的硬件特性,如tensor core和深度学习加速器等。
总之,CUDA是一个通用的并行计算平台,可以用于各种计算任务,包括深度学习。而TensorRT是专门为深度学习推理而设计的引擎,相对于CUDA具有更高的加速效果。
 AI推理的需求主要来自于以下几个方面:
AI推理的需求主要来自于以下几个方面:
-
实时性需求:AI推理应用程序通常需要在实时或几乎实时的情况下进行推理。例如,自动驾驶汽车需要在毫秒级别内做出决策,机器人需要在几毫秒内对环境做出响应。因此,AI推理需要具备高速、低延迟、高并发等特点。
-
精度需求:AI模型的推理结果需要具有高精度,以满足应用程序的需求。例如,医疗诊断需要高精度的疾病检测结果,智能安防需要精准的人脸识别结果。
-
能耗需求:AI推理通常在嵌入式设备、移动设备和云端服务器等不同的平台上运行。在这些平台上,能耗通常是一个重要的考虑因素。因此,AI推理需要具备高效的计算和存储能力,以达到最佳的能耗效率。
-
可扩展性需求:AI推理应用程序通常需要支持大规模的部署和管理。例如,智能城市需要在数百个位置部署数千个传感器,每个传感器都需要进行AI推理。因此,AI推理需要具备可扩展性和易于管理的特点。
综上所述,AI推理的需求包括高速、高精度、高效、可扩展性等方面,这些需求的满足将有助于AI技术在各个领域得到广泛应用。
 TensorRT是NVIDIA提供的一个高效的深度学习推理引擎,其核心知识点包括:
TensorRT是NVIDIA提供的一个高效的深度学习推理引擎,其核心知识点包括:
-
引擎构建:TensorRT引擎的构建是其核心知识点之一。引擎构建包括模型解析、优化和编译等步骤。TensorRT使用网络剪枝、层融合、权重量化等技术来减少模型计算量和内存占用,同时还利用GPU硬件特性进行加速,如tensor core和深度学习加速器等。
-
插件开发:TensorRT支持自定义插件的开发,以支持各种自定义层的推理。插件开发需要了解TensorRT的API和插件开发流程,同时还需要有深度学习和CUDA编程的基础知识。
-
数据类型:TensorRT支持多种数据类型,包括FP32、FP16和INT8等。不同的数据类型对推理速度和精度有不同的影响。例如,INT8可以显著提高推理速度,但可能会牺牲一定的精度。
-
批处理:TensorRT支持批处理,即一次处理多个输入数据。批处理可以显著提高推理效率,特别是在处理大批量数据时。
-
动态形状:TensorRT支持动态形状,即在运行时根据输入数据的形状动态调整网络结构。动态形状可以增加模型的灵活性,同时也需要更多的计算和内存资源。
综上所述,TensorRT的核心知识点包括引擎构建、插件开发、数据类型、批处理和动态形状等方面,这些知识点的掌握可以帮助开发者更好地利用TensorRT来加速深度学习推理。
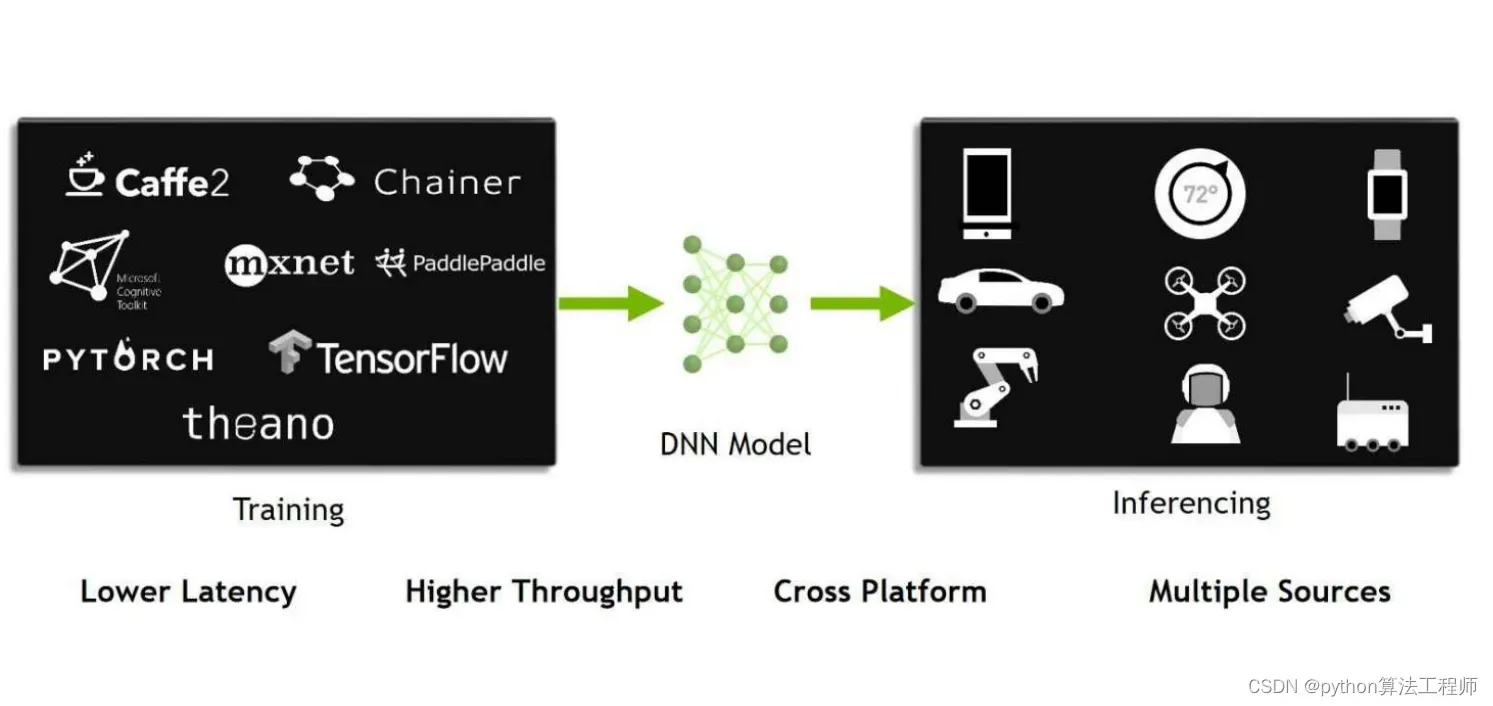
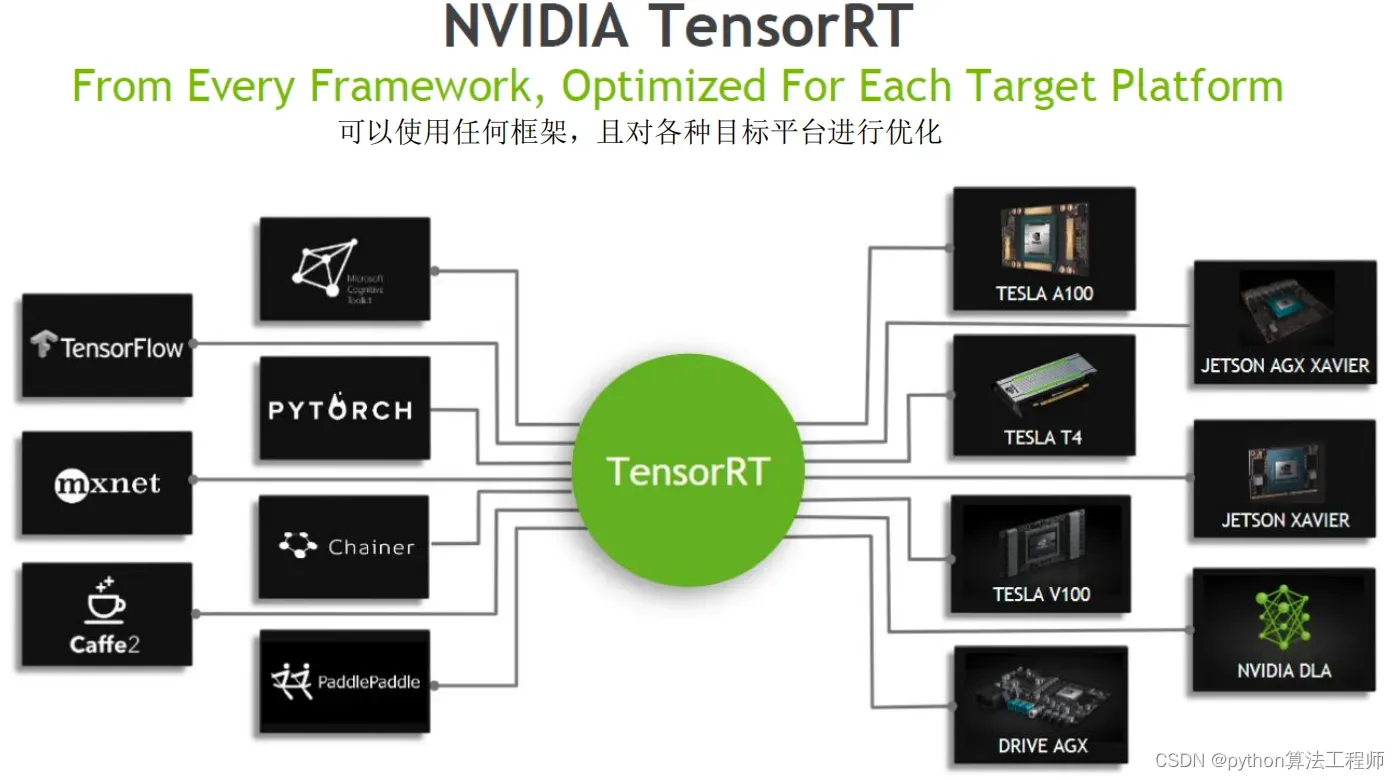
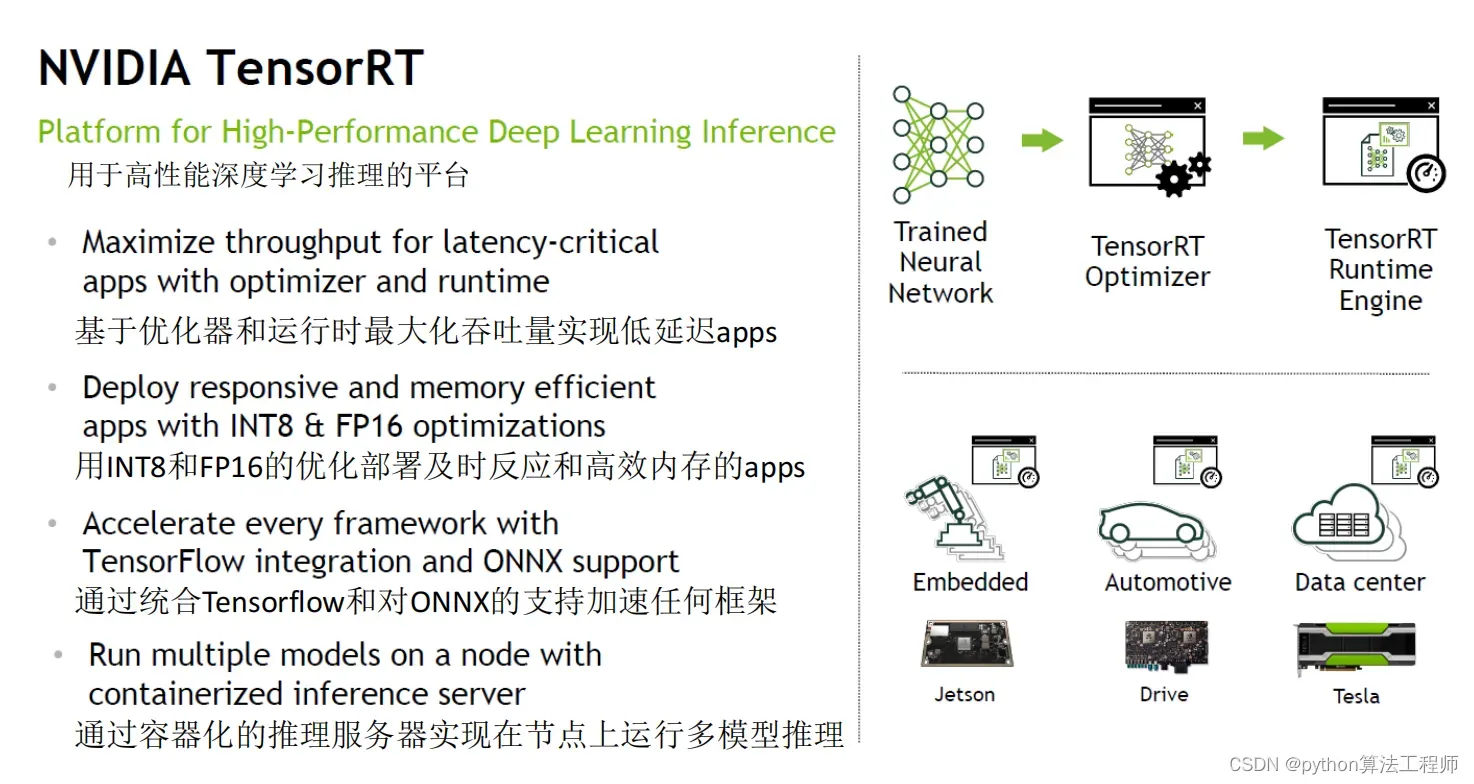
 TensorRT是一个专门用于深度学习推理的优化引擎,可以通过多种优化技术来提高模型推理的速度和效率。TensorRT的优化技术主要包括以下几个方面:
TensorRT是一个专门用于深度学习推理的优化引擎,可以通过多种优化技术来提高模型推理的速度和效率。TensorRT的优化技术主要包括以下几个方面:
-
网络剪枝(Network Pruning):通过减少模型中的冗余权重和神经元来降低计算量和内存占用,从而提高模型的推理速度和效率。
-
层融合(Layer Fusion):将多个层合并为一个更高效的层,从而减少计算和内存占用。
-
权重量化(Weight Quantization):将模型的浮点权重转化为更小的整数权重,从而减少内存占用和计算量。
-
卷积操作优化(Convolution Optimization):通过使用深度学习加速器(DLA)等硬件加速器来优化卷积操作,从而提高模型的推理速度和效率。
-
批处理(Batch Processing):同时处理多个输入数据以提高模型的推理效率。
-
动态形状(Dynamic Shapes):根据输入数据的形状动态调整网络结构,从而提高模型的灵活性和推理效率。
-
混合精度(Mixed Precision):使用低精度浮点数存储权重和激活值,从而减少内存占用和计算量,提高模型的推理速度。
-
异步推理(Asynchronous Inference):将模型的推理任务分配给多个GPU或DLA进行并行计算,从而提高模型的推理速度和效率。
通过以上的优化技术,TensorRT可以提高模型推理的速度和效率,使得深度学习模型能够更加高效地在生产环境中部署和运行。
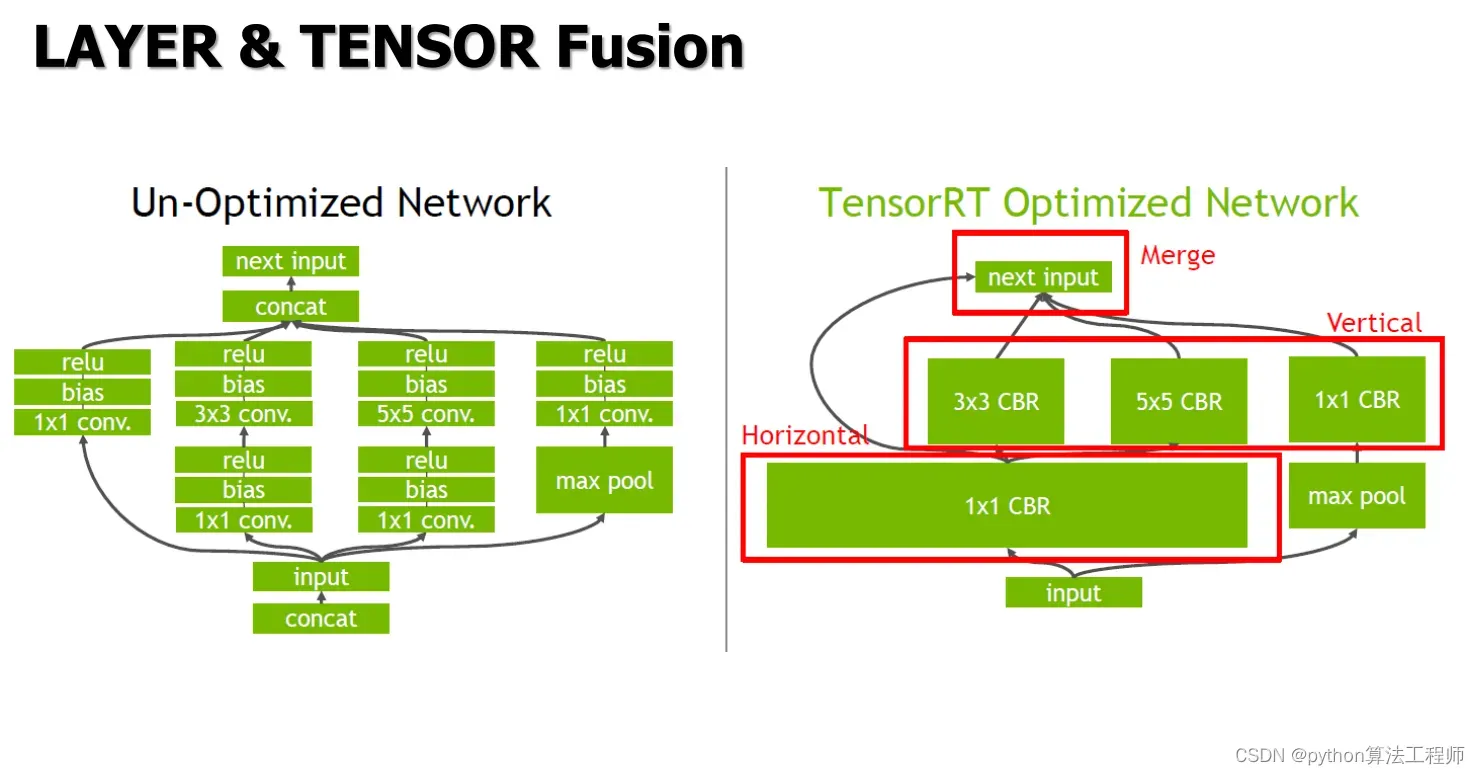 Layer Tensor Fusion是TensorRT中的一种优化技术,用于将多个层合并为一个更高效的层,从而减少计算和内存占用,提高模型推理的速度和效率。
Layer Tensor Fusion是TensorRT中的一种优化技术,用于将多个层合并为一个更高效的层,从而减少计算和内存占用,提高模型推理的速度和效率。
在深度学习模型中,每个层都包含多个操作,例如卷积、激活函数、归一化等。在常规的推理流程中,每个层的输出都要被存储在内存中,然后作为下一层的输入。这种方式会导致大量的数据拷贝和内存访问,从而影响推理的速度和效率。而Layer Tensor Fusion技术可以将多个层的操作合并在一起,从而避免了数据拷贝和内存访问的开销,提高了推理的效率。
具体来说,Layer Tensor Fusion技术可以将多个层的操作合并为一个更高效的操作,例如将卷积层和激活函数层合并为一个卷积操作,或者将卷积层、激活函数层和归一化层合并为一个卷积操作。合并后的操作只需要一次计算和一次内存访问,从而避免了多次数据拷贝和内存访问的开销。此外,合并后的操作还可以使用自定义的CUDA内核进行加速,进一步提高推理的效率。
需要注意的是,Layer Tensor Fusion技术并不适用于所有的深度学习模型和硬件环境。在实际应用中,需要根据具体的模型和硬件环境来选择合适的优化技术,以达到最佳的推理效果。
 Kernel Auto-Tuning是一种优化技术,用于自动搜索最优的卷积核参数,从而提高卷积操作的性能和效率。在深度学习模型中,卷积操作是计算量最大的操作之一,因此优化卷积操作的性能和效率对于提高模型的推理速度和效率非常重要。
Kernel Auto-Tuning是一种优化技术,用于自动搜索最优的卷积核参数,从而提高卷积操作的性能和效率。在深度学习模型中,卷积操作是计算量最大的操作之一,因此优化卷积操作的性能和效率对于提高模型的推理速度和效率非常重要。
Kernel Auto-Tuning技术可以通过自动搜索卷积核的参数,如卷积核大小、步幅、填充等,来找到最佳的卷积核配置,从而提高卷积操作的性能和效率。通常来说,Kernel Auto-Tuning技术需要在多个参数组合上进行测试,然后选择性能最佳的参数组合作为最终的卷积核配置。
在实际应用中,Kernel Auto-Tuning技术通常结合深度学习加速器(DLA)等硬件加速器来使用,以进一步提高卷积操作的性能和效率。同时,Kernel Auto-Tuning技术也需要考虑模型的推理需求和硬件环境等因素,以选择合适的卷积核配置。
需要注意的是,Kernel Auto-Tuning技术会增加模型编译的时间和计算资源消耗,因此在实际应用中需要权衡时间和精度的平衡,选择合适的优化方法来提高模型的推理速度和效率。
 Dynamic Tensor Memory是一种TensorRT中的优化技术,用于根据输入数据的形状动态分配和管理Tensor的内存空间,从而提高模型的灵活性和推理效率。
Dynamic Tensor Memory是一种TensorRT中的优化技术,用于根据输入数据的形状动态分配和管理Tensor的内存空间,从而提高模型的灵活性和推理效率。
在深度学习模型中,Tensor通常具有固定的形状和大小,因此在推理过程中需要为每个Tensor分配固定大小的内存空间。然而,在实际应用中,输入数据的形状和大小通常是不固定的,这就需要动态地分配和管理Tensor的内存空间。而Dynamic Tensor Memory技术可以根据输入数据的形状动态分配和管理Tensor的内存空间,从而提高模型的灵活性和推理效率。
具体来说,Dynamic Tensor Memory技术可以在推理过程中动态地分配和管理Tensor的内存空间,从而避免了固定大小内存的浪费和不足。在TensorRT中,Dynamic Tensor Memory技术可以通过使用CUDA的Unified Memory和Managed Memory等技术来实现。Unified Memory技术可以将主机内存和设备内存统一管理,从而实现动态内存分配和管理;而Managed Memory技术可以将多个设备的内存统一管理,从而实现多设备之间的内存共享和管理。
需要注意的是,Dynamic Tensor Memory技术会增加模型推理的时间和内存消耗,因此需要根据实际应用需求和硬件资源来选择是否使用该技术。同时,Dynamic Tensor Memory技术也需要考虑内存分配和管理的效率和精度等因素,以实现最优的推理效果。
 Precision Calibration是一种优化技术,用于在深度学习模型中减少参数的位数,从而减少模型的存储空间和计算量,提高模型的推理速度和效率。
Precision Calibration是一种优化技术,用于在深度学习模型中减少参数的位数,从而减少模型的存储空间和计算量,提高模型的推理速度和效率。
在深度学习模型中,每个参数通常使用32位浮点数来表示,这会占用大量的存储空间并且需要大量的计算资源来处理。而Precision Calibration技术可以将参数的位数减少到16位、8位甚至更低,从而大大减少模型的存储空间和计算量。
具体来说,Precision Calibration技术可以通过以下几个步骤来实现:
-
数据收集:收集模型的训练数据,并使用该数据来计算每个参数的范围和分布。
-
精度分析:根据参数的范围和分布,分析每个参数的精度需求,并确定合适的位数。
-
参数量化:将每个参数量化为指定位数的整数或浮点数。
-
训练微调:使用量化后的参数来微调模型,并调整模型的权重和偏置,以保持模型的精度。
-
推理加速:在推理过程中,将量化后的参数加载到模型中,并使用低精度的算术运算来加速模型的推理。
需要注意的是,Precision Calibration技术会牺牲模型的精度来换取推理速度和存储空间的优化。因此,在实际应用中,需要根据模型的精度需求和应用场景来选择合适的位数和精度级别,以实现最优的推理效果。

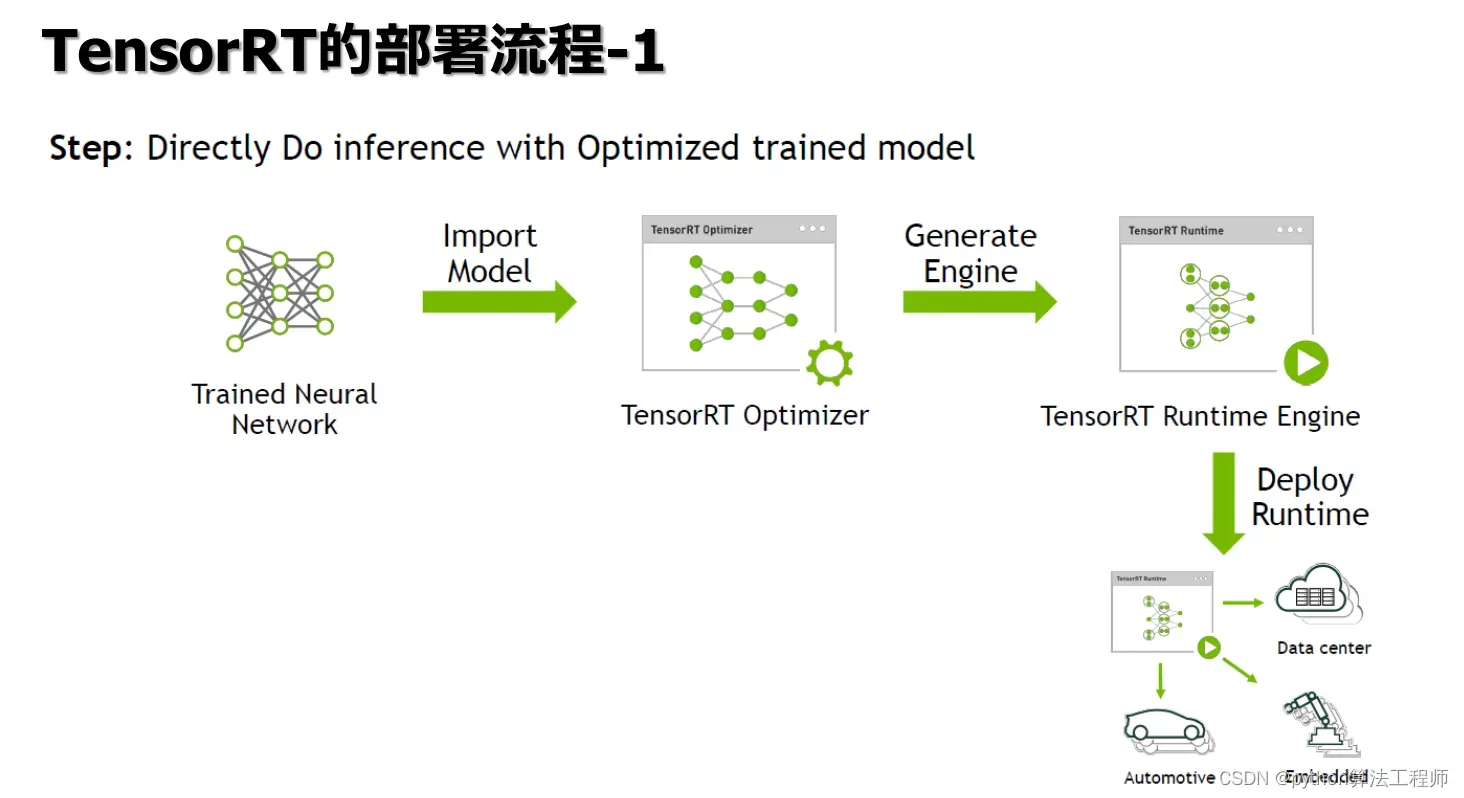
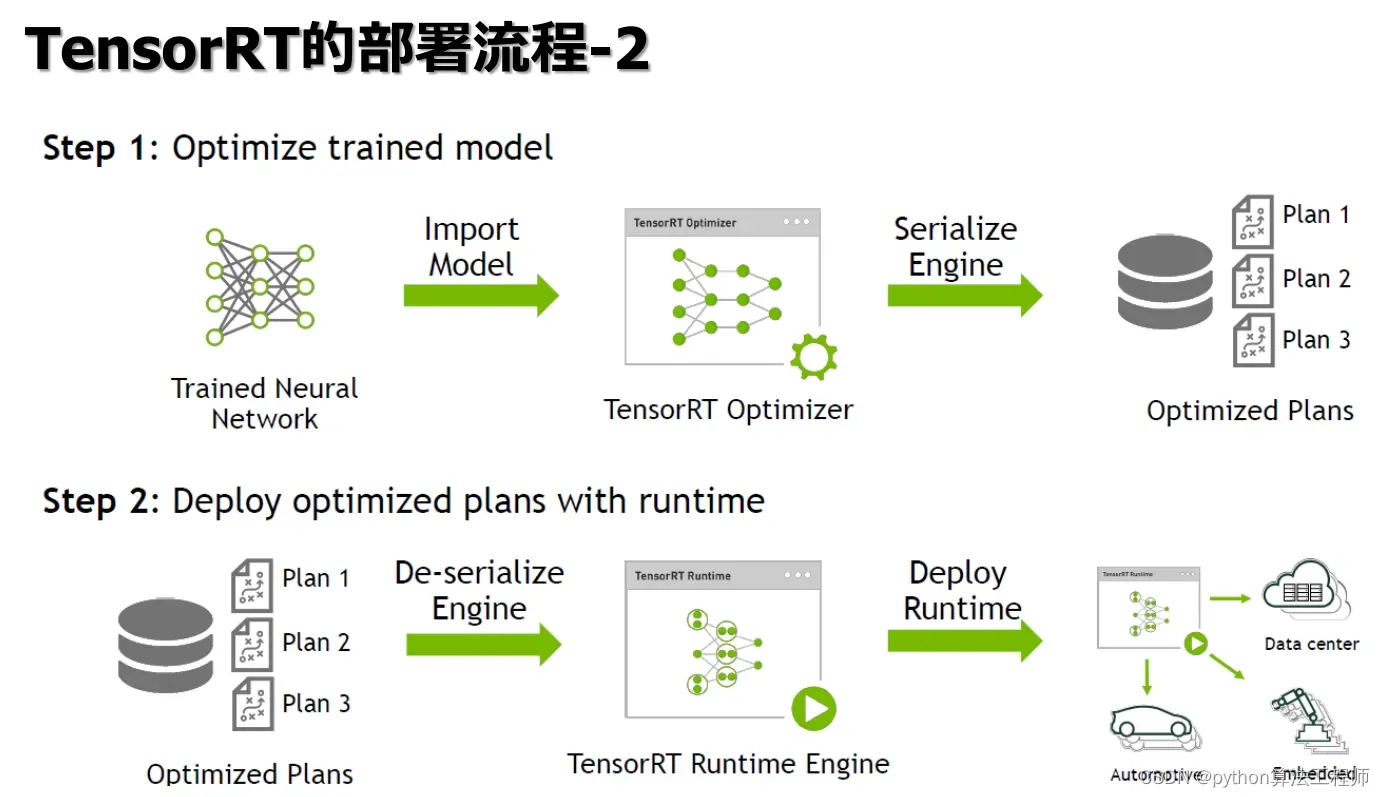
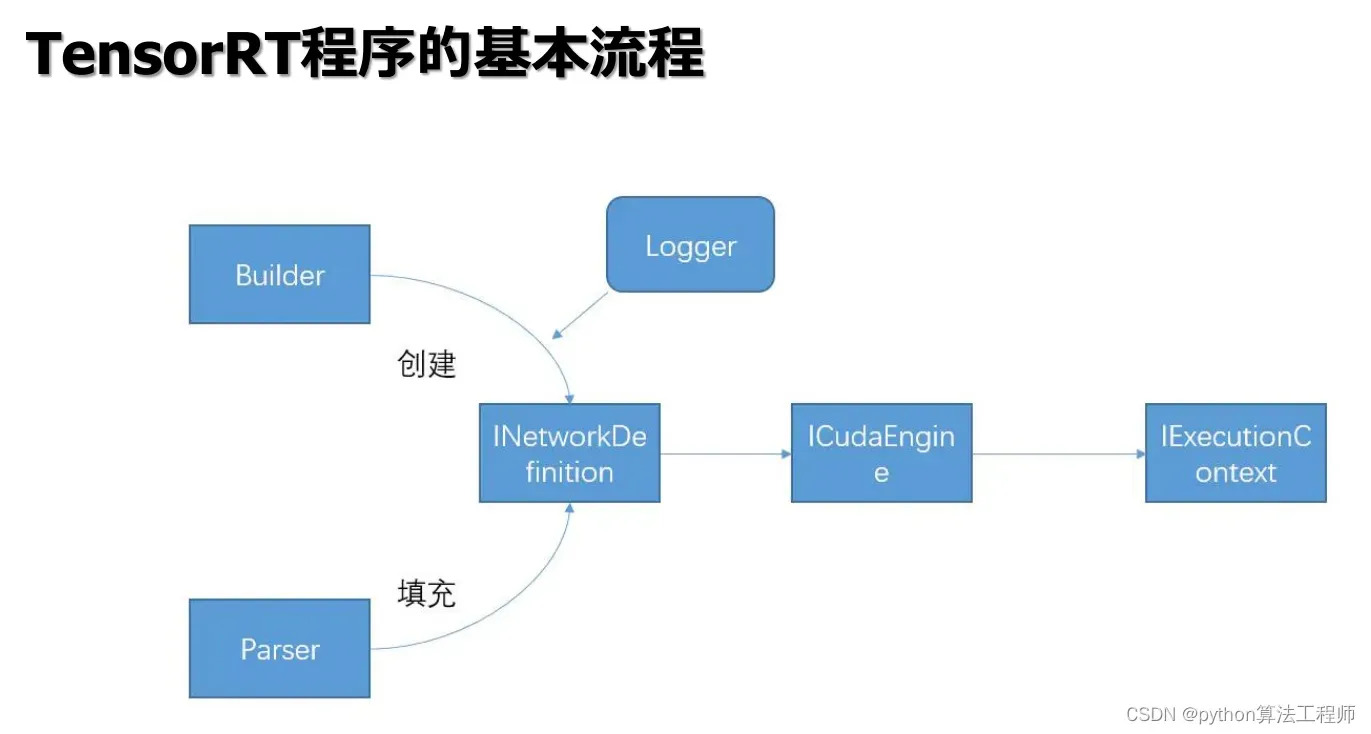

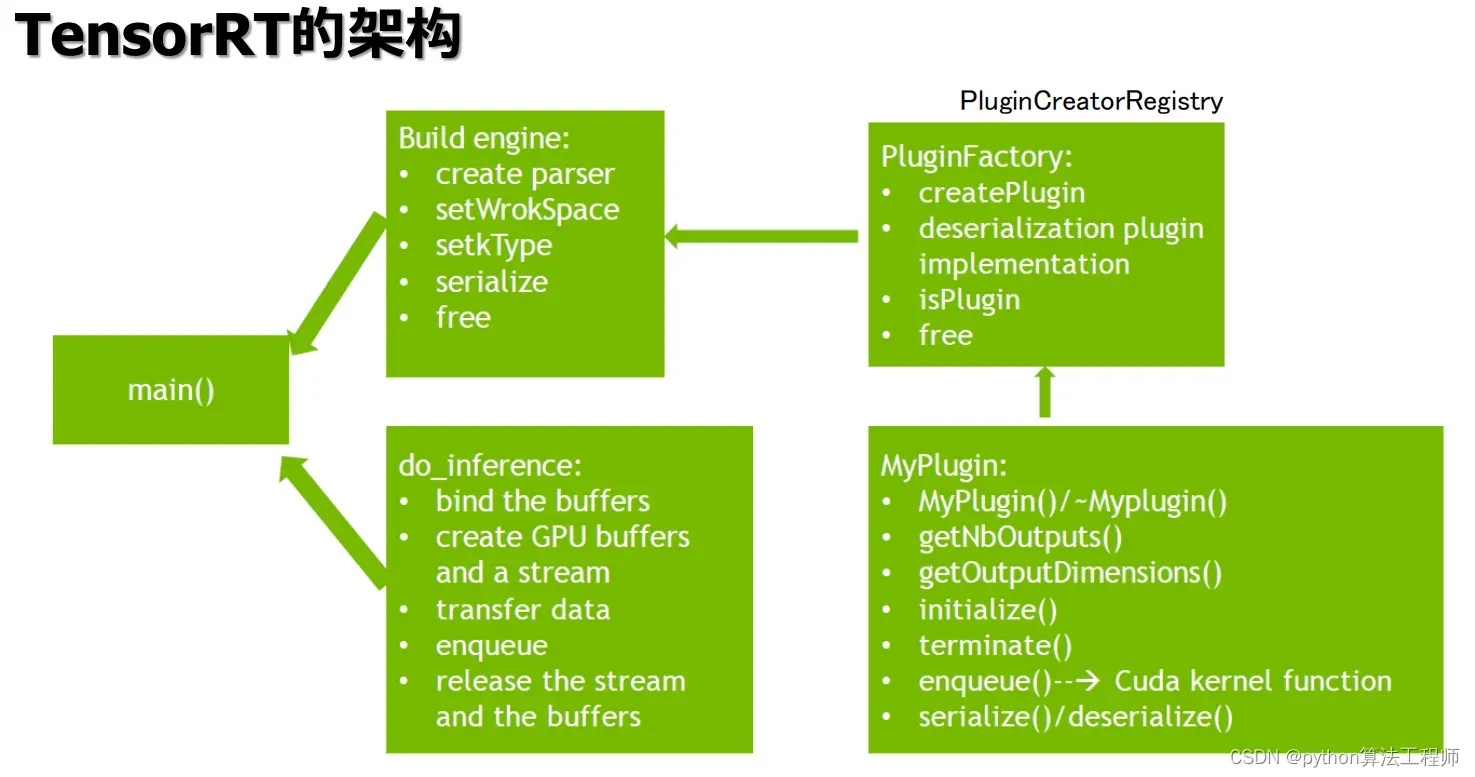


 在TensorRT中,Parse通常指将深度学习模型从常见的深度学习框架(如Caffe、TensorFlow、ONNX等)的格式中解析出来,并将其转换为TensorRT可以处理的格式。这个过程通常包括以下几个步骤:
在TensorRT中,Parse通常指将深度学习模型从常见的深度学习框架(如Caffe、TensorFlow、ONNX等)的格式中解析出来,并将其转换为TensorRT可以处理的格式。这个过程通常包括以下几个步骤:
-
创建解析器:使用TensorRT的API创建相应的解析器对象,例如使用
nvinfer1::createCaffeParser()或nvinfer1::createParser()等函数创建Caffe或ONNX解析器对象。 -
解析模型:使用解析器对象的API将深度学习模型从原始格式中解析出来,并生成对应的TensorRT网络。
-
构建引擎:使用TensorRT的API将TensorRT网络构建为可用于推理的引擎对象,并进行优化和配置等操作。
以下是一个简单的C++代码示例,用于从ONNX模型中解析出TensorRT网络:
#include "NvInfer.h"
#include "NvOnnxParser.h"
using namespace nvinfer1;
using namespace nvonnxparser;
int main(int argc, char** argv) {
// Step 1: 创建解析器
IBuilder* builder = createInferBuilder(gLogger);
INetworkDefinition* network = builder->createNetwork();
IBuilderConfig* config = builder->createBuilderConfig();
auto parser = createParser(*network, gLogger);
// Step 2: 解析模型
const std::string onnxModelFile = "model.onnx";
parser->parseFromFile(onnxModelFile.c_str(), -1);
// Step 3: 构建引擎
builder->setMaxBatchSize(1);
builder->setMaxWorkspaceSize(1 << 30);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
engine->destroy();
network->destroy();
builder->destroy();
parser->destroy();
return 0;
}
需要注意的是,在实际应用中,还需要根据具体的模型和应用场景进行优化和配置,以实现最优的推理效果。


以下是使用C++开发TensorRT项目的基本流程:
-
准备模型数据:将模型转换为TensorRT可以处理的格式,如ONNX、Caffe、Tensorflow等格式,并将模型参数序列化为二进制文件。
-
创建推理引擎:使用TensorRT的API创建推理引擎对象,其中包括构建网络结构、设置推理参数、优化模型等步骤。
-
分配内存空间:使用CUDA的API分配设备内存来存储输入和输出Tensor的数据,并将数据从主机内存复制到设备内存。
-
执行推理:使用TensorRT的API执行推理操作,将输入数据传递到推理引擎中,并获得推理结果,然后将结果从设备内存复制到主机内存。
-
释放资源:释放设备内存和TensorRT对象的资源,以避免内存泄漏和资源占用。
以下是一个简单的C++代码示例,用于执行基于TensorRT的推理操作:
#include <iostream>
#include <fstream>
#include <sstream>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "NvInferRuntimeCommon.h"
using namespace std;
using namespace nvinfer1;
using namespace nvonnxparser;
int main(int argc, char** argv) {
// Step 1: 准备模型数据
const string onnxFile = "model.onnx";
const string engineFile = "model.engine";
IBuilder* builder = createInferBuilder(gLogger);
INetworkDefinition* network = builder->createNetwork();
IBuilderConfig* config = builder->createBuilderConfig();
auto parser = createParser(*network, gLogger);
parser->parseFromFile(onnxFile.c_str(), 0);
builder->setMaxBatchSize(1);
builder->setMaxWorkspaceSize(1 << 30);
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// Step 2: 创建推理引擎
ofstream engineStream(engineFile, ios::binary);
IHostMemory* serializedEngine = engine->serialize();
engineStream.write((char*)serializedEngine->data(), serializedEngine->size());
serializedEngine->destroy();
engine->destroy();
network->destroy();
builder->destroy();
// Step 3: 分配内存空间
void* inputTensorData = malloc(inputTensorSize * sizeof(float));
void* outputTensorData = malloc(outputTensorSize * sizeof(float));
cudaMalloc(&deviceInputTensor, inputTensorSize * sizeof(float));
cudaMalloc(&deviceOutputTensor, outputTensorSize * sizeof(float));
// Step 4: 执行推理
ICudaEngine* engine = loadCudaEngine(engineFile);
IExecutionContext* context = engine->createExecutionContext();
cudaMemcpy(deviceInputTensor, inputTensorData, inputTensorSize * sizeof(float), cudaMemcpyHostToDevice);
context->execute(1, &deviceInputTensor, &deviceOutputTensor);
cudaMemcpy(outputTensorData, deviceOutputTensor, outputTensorSize * sizeof(float), cudaMemcpyDeviceToHost);
// Step 5: 释放资源
cudaFree(deviceInputTensor);
cudaFree(deviceOutputTensor);
context->destroy();
engine->destroy();
return 0;
}
需要注意的是,在实际应用中,还需要考虑模型的精度、内存管理、并行计算等因素,以实现最优的推理效果。

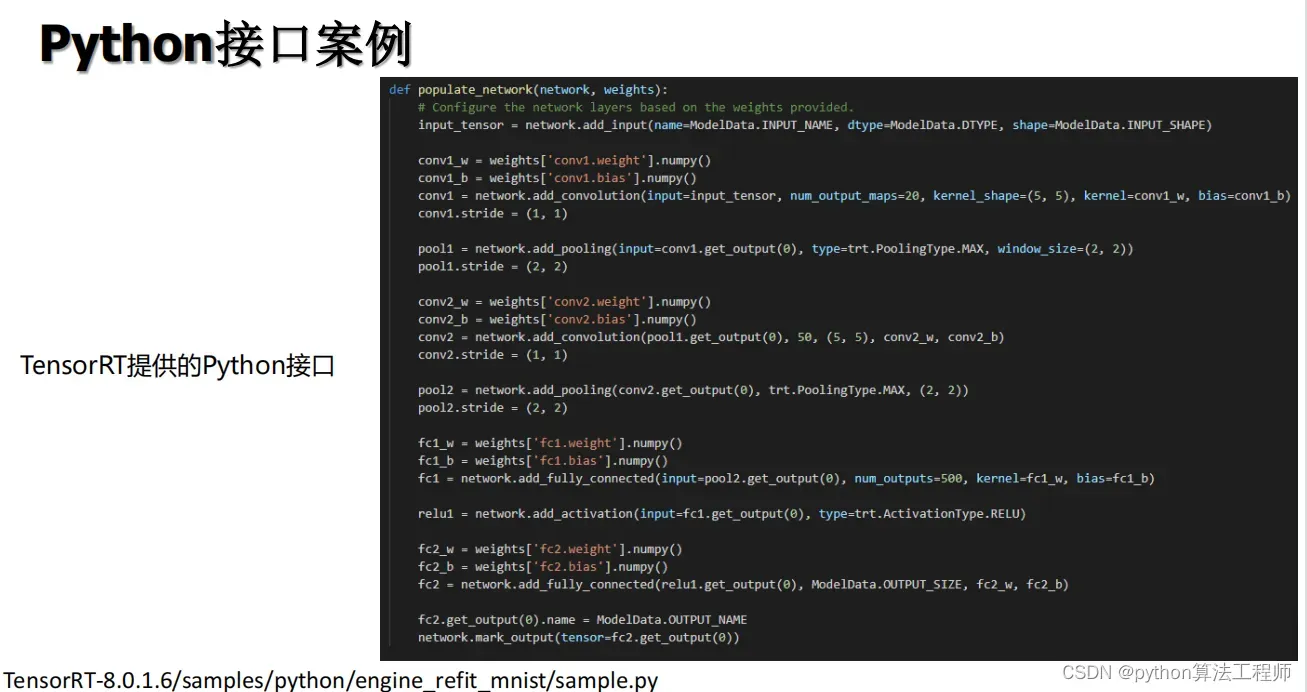




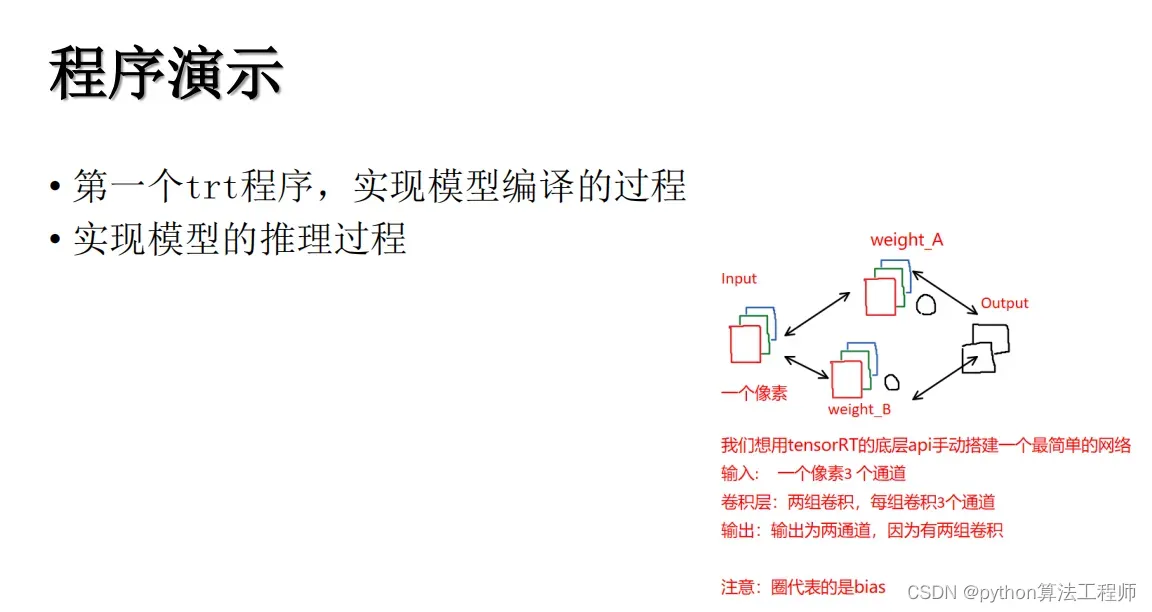





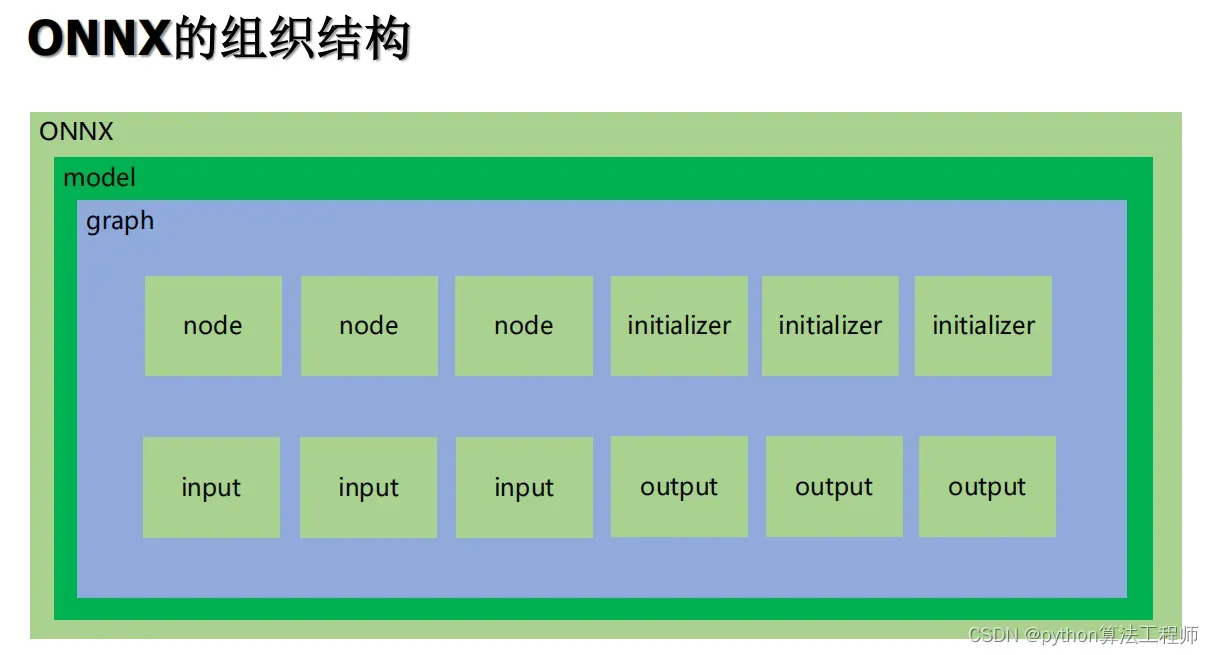


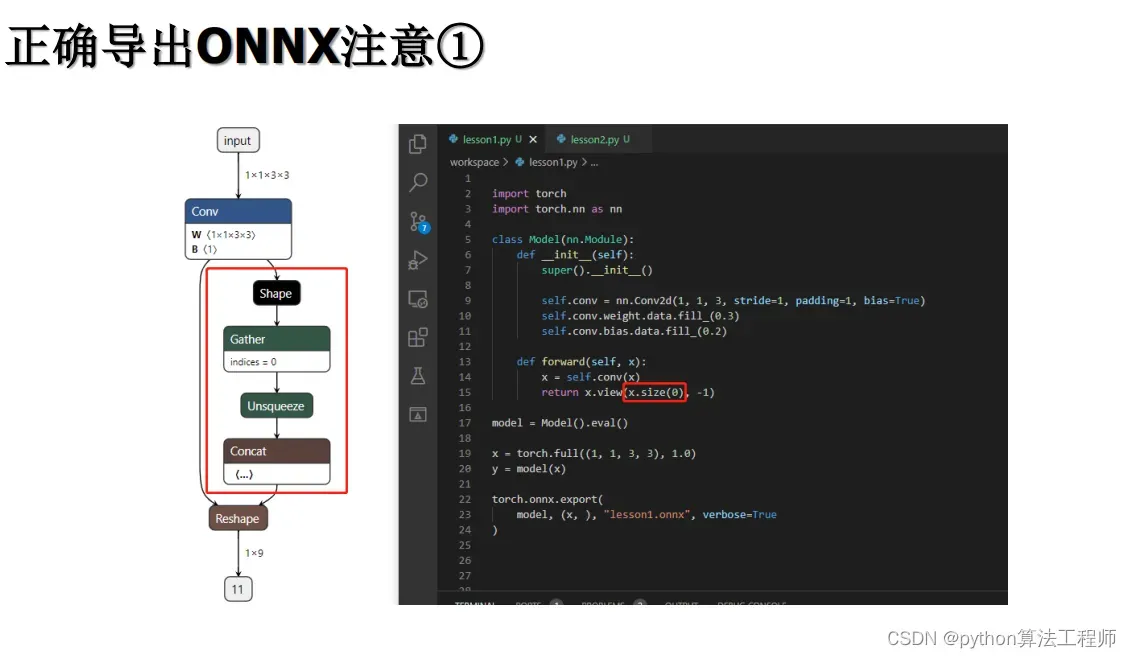
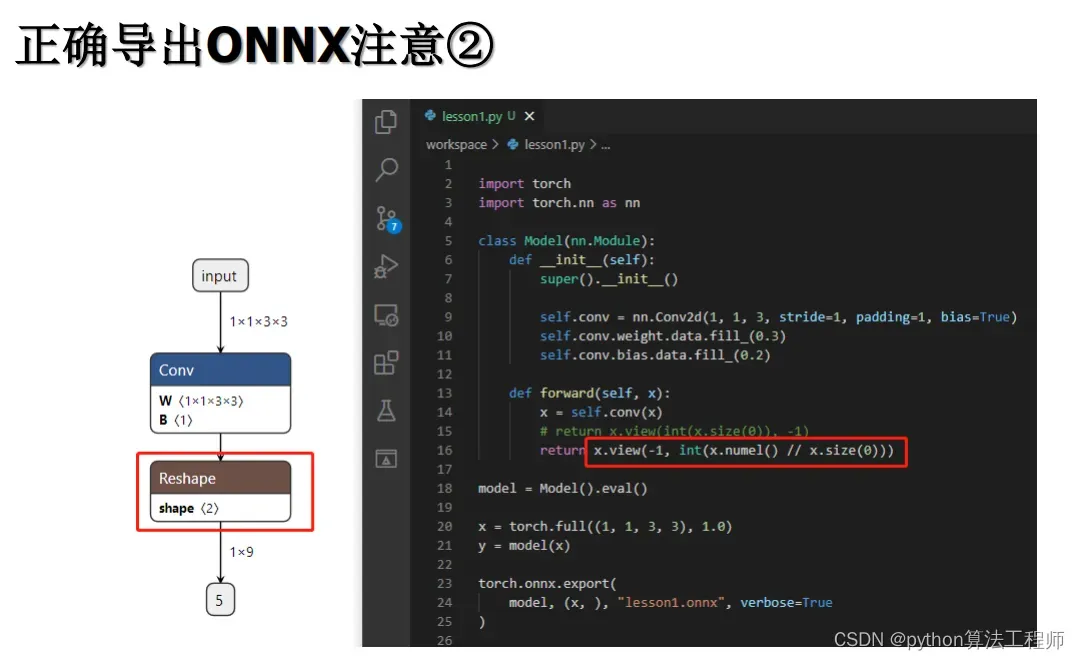

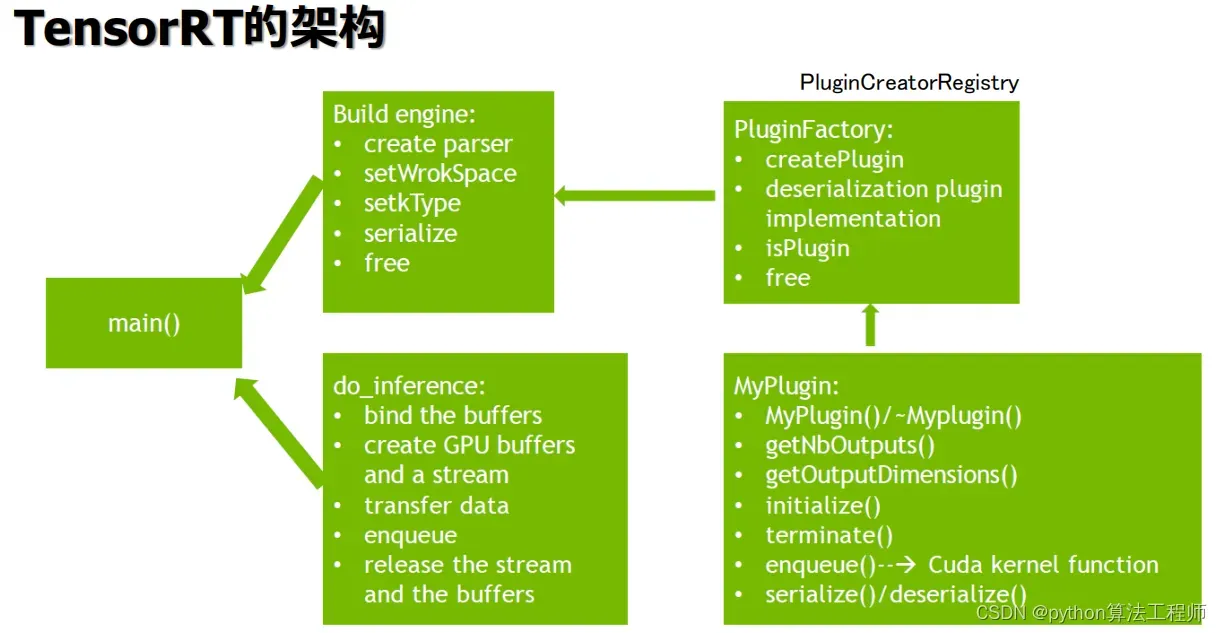
在TensorRT中,Plugin是一种扩展模块,用于实现自定义操作或层,以满足特定的应用需求。Plugin可以使用C++编写,并通过TensorRT的API进行加载和注册,成为TensorRT中的一部分。
Plugin通常用于以下几种情况:
-
实现自定义操作:当需要使用TensorRT不支持的操作时,可以通过编写Plugin来实现自定义操作,例如YOLOv3中的Region层和Darknet中的Route层等。
-
提高性能:当需要使用高效的算法或硬件特性时,可以通过编写Plugin来利用GPU的并行计算能力和专用硬件的优势,例如使用cuDNN库中的算法或使用NVIDIA Tensor Cores进行混合精度计算等。
-
应用优化:当需要使用特定的应用逻辑或数据结构时,可以通过编写Plugin来实现应用优化,例如使用稀疏矩阵或低秩矩阵进行压缩和加速等。
以下是一个简单的C++代码示例,用于编写并注册一个简单的Plugin:
#include "NvInferPlugin.h"
using namespace nvinfer1;
using namespace plugin;
class MyPlugin : public IPluginV2Ext {
public:
MyPlugin(/* parameters */) { /* constructor */ }
MyPlugin(const void* data, size_t length) { /* deserialize */ }
int getNbOutputs() const override { return 1; }
Dims getOutputDimensions(int index, const Dims* inputs, int nbInputDims) override { /* compute output dimensions */ }
bool supportsFormat(DataType type, PluginFormat format) const override { /* check supported formats */ }
void configureWithFormat(const Dims* inputDims, int nbInputs, const Dims* outputDims, int nbOutputs, DataType type, PluginFormat format, int maxBatchSize) override { /* configure plugin */ }
int initialize() override { /* initialize plugin */ }
void terminate() override { /* terminate plugin */ }
size_t getWorkspaceSize(int maxBatchSize) const override { /* compute required workspace size */ }
int enqueue(int batchSize, const void* const* inputs, void** outputs, void* workspace, cudaStream_t stream) override { /* execute plugin */ }
size_t getSerializationSize() const override { /* compute serialized size */ }
void serialize(void* buffer) const override { /* serialize plugin */ }
void destroy() override { delete this; }
};
class MyPluginCreator : public IPluginCreator {
public:
MyPluginCreator() {}
~MyPluginCreator() {}
const char* getPluginName() const override { return "MyPlugin"; }
const char* getPluginVersion() const override { return "1.0"; }
const PluginFieldCollection* getFieldNames() override { return nullptr; }
IPluginV2Ext* createPlugin(const char* name, const PluginFieldCollection* fc) override { return new MyPlugin(/* parameters */); }
IPluginV2Ext* deserializePlugin(const char* name, const void* serialData, size_t serialLength) override { return new MyPlugin(serialData, serialLength); }
void setPluginNamespace(const char* libNamespace) override { mNamespace = libNamespace; }
const char* getPluginNamespace() const override { return mNamespace.c_str(); }
private:
std::string mNamespace;
};
REGISTER_TENSORRT_PLUGIN(MyPluginCreator);
以上代码中,MyPlugin类实现了IPluginV2Ext接口,包括Plugin的各种方法,例如getNbOutputs()、getOutputDimensions()、enqueue()等。MyPluginCreator类实现了IPluginCreator接口,用于创建和序列化Plugin对象。最后,通过REGISTER_TENSORRT_PLUGIN宏将MyPluginCreator注册为一个可用的Plugin。
需要注意的是,在实际应用中,还需要根据具体的需求编写和配置Plugin,以实现最优的性能和效果。



提高性能方式
- 算子融合(层与张量融合):简单来说就是通过融合一些计算op或者去掉一些多余op来减少数据流通次数以及显存的频繁使用来提速
- 量化:量化即IN8量化或者FP16以及TF32等不同于常规FP32精度的使用,这些精度可以显著提升模型执行速度并且不会保持原先模型的精度
- 内核自动调整:根据不同的显卡构架、SM数量、内核频率等(例如1080TI和2080TI),选择不同的优化策略以及计算方式,寻找最合适当前构架的计算方式
- 动态张量显存:我们都知道,显存的开辟和释放是比较耗时的,通过调整一些策略可以减少模型中这些操作的次数,从而可以减少模型运行的时间
- 多流执行:使用CUDA中的stream技术,最大化实现并行操作
高性能
定义:时间/空间复杂度更低,即算法复杂度低,保证计算的同时内存消耗低,耗时短.
TensorRT密集型操作更友好,使用TensorRT实现高性能深度学习推理
要点:
- 尽量使得GPU高密集度运行,避免出现CPU、GPU相互交换运行(非常耗时)
- 尽可能使tensorRT运行多个batch 数据。采用多线程。
- 预处理尽量cuda化,例如图像需要做normalize、reisze、warpaffine、bgr2rgb等,在这里,采用cuda核实现warpaffine+normalize等操作,集中在一起性能好
- 后处理尽量cuda化,例如decode、nms等。在这里用cuda核实现了decode和nms
- 善于使用cudaStream,将操作加入流中,采用异步操作避免等待
- 内存复用
硬件编解码
imread
- NvJPEG硬件解码图像
- NVDEC硬件解码视频
建立模型流程model_build
-
继承自
nvinfer1::ILogger定义logger类 -
实例化logger,作为全局日志打印的东西
-
构建模型编译器
-
创建网络 创建编译配置
auto builder = nvinfer1::createInferBuilder(logger); auto network = builder->createNetworkV2(1);//其中1表示显示批处理 auto config = builder->createBuilderConfig(); -
配置网络参数, 配置最大的batchsize,意味着推理所指定的batch参数不能超过这个
builder->setMaxBatchSize(1); -
配置工作空间的大小, 每个节点不用自己管理内存空间,不用自己去cudaMalloc内存, 使得所有节点均把workspace当做内存池,重复使用,使得内存
config->setMaxWorkspaceSize(1 << 30); -
默认情况下,使用的是FP32推理,如果希望使用FP16,可以设置这个flags
builder->platformHasFastFp16(); //这个函数告诉你,当前显卡是否具有fp16加速的能力 builder->platformHasFastInt8(); //这个函数告诉你,当前显卡是否具有int8的加速能力 -
如果要使用int8,则需要做精度标定,模型量化内容,把你的权重变为int8格式,计算乘法。减少浮点数乘法操作,用整数(int8)来替代
-
构建网络结构;
-
自定义网络结构,并赋值权重
-
采用nvidia提供的nvonnxparser
-
自行编译nvonnxparser
-
-
使用构建好的网络,编译引擎
auto engine = builder->buildEngineWithConfig(*network, *config) -
序列化模型为数据,并储存为文件
auto host_memory = engine->serialize(); save_to_file("04.cnn.trtmodel", host_memory->data(), host_memory->size()); -
回收内存
trtexec
可实现转engine模型
cd /TensorRT-7.2.3.4/bin
模型推理流程inferrence
例:04.tensorRT.cnn.cpp
- 设置推理用的设备,创建流
cudaSetDevice(0);
cudaStreamCreate(&stream);
- 加载模型数据
auto model_data = load_from_file("04.cnn.trtmodel");
- 创建运行时实例对象,并反序列化模型, 通过引擎,创建执行上下文
auto runtime = nvinfer1::createInferRuntime(logger);
auto engine = runtime->deserializeCudaEngine(model_data.data(), model_data.size());
auto context = engine->createExecutionContext();
- 获取绑定的tensor信息,并打印出来,所谓绑定的tensor,就是指输入和输出节点
int nbindings = engine->getNbBindings();
- 分配输入数据和输出内存空间
// 分配输入的设备空间
float* input_device_image = nullptr;
size_t input_device_image_bytes = sizeof(float) * input_host_image.size();
cudaMalloc(&input_device_image, input_device_image_bytes);
// 创建流,并异步的方式复制输入数据到设备
cudaStream_t stream = nullptr;
cudaStreamCreate(&stream);
cudaMemcpyAsync(input_device_image, input_host_image.data(), input_device_image_bytes, cudaMemcpyHostToDevice, stream);
// 分配输出的设备空间
float* output_device = nullptr;
size_t output_device_bytes = 1000 * sizeof(float);
cudaMalloc(&output_device, output_device_bytes);
- 入队并进行异步推理
void* bindings[] = {input_device_image, output_device};
context->enqueueV2(1, bindings, stream, nullptr);
- 异步复制结果
vector<float> output_predict(1000);
cudaMemcpyAsync(output_predict.data(), output_device, output_device_bytes, cudaMemcpyDeviceToHost, stream);
enqueue的第四个参数inputConsumed,是通知input_device可以被修改的事件指针
如果在这里cudaEventSynchronize(inputConsumed);,在这句同步以后,input_device就可以被修改干别的事情
- 同步流,确保结果执行完成
cudaStreamSynchronize(stream);
- 打印最后的结果
- 释放内存
细节
- 注意推理时的预处理,指定了rgb与bgr对调
- 如果需要多个图像推理,需要:
- 在编译时,指定maxbatchsize为多个图
- 在推理时,指定输入的bindings shape的batch维度为使用的图像数,要求小于等于maxbatchsize
- 在收取结果的时候,tensor的shape是input指定的batch大小,按照batch处理即可
ONNX
-
onnx框架,依赖自protobuf做序列化解析文件, nvonnxparser解析器,libnvonnxparser.so。
-
如果解析器与pytorch的onnx版本不匹配时就会导致莫名的错误、 如果解析器与pytorch的protobuf版本不匹配,也会导致错误,无法加载nvonnxparser解析器,
-
nvidia开源,所以可以直接拿来编译使用。 https://github.com/onnx/onnx-tensorrt
-
但是nvonnxparser解析器,自身也有版本问题,他的版本需要配合tensorRT版本一起使用
-
nvonnxparser这个解析器,不同版本有不同的坑,这个与动态batchsize有关。 比较好的搭配,是https://github.com/onnx/onnx-tensorrt/tree/6.0 版本
ONNX与Protobuf
-
onnx框架,依赖自protobuf做序列化解析文件。
-
Protobuf通过onnx-ml.proto编译得到onnx-ml.pb.h和onnx-ml.pb.cc或onnx_ml_pb2.py
-
onnx-ml.pb.cc的代码操作onnx模型文件,实现增删改
-
onnx-ml.proto描述onnx文件如何组成,结构
推理发生错误解决方案:
-
下载特定的protobuf,这里我用的是3.11.4
-
下载onnx,保留其proto协议文件,生成pb.h、pb.cpp,只使用这几个即可,不需要onnx全部,Protocol Buffers,为了解决任何语言之间的数据序列化反序列化工作
- 通过proto协议文件,定义数据的结构
- 通过protoc程序,对xx.proto进行编译,编译为指定语言的输出,输出结果是代码
以c++为例,输出是xx.pb.cpp和xx.pb.h
以python为例,输出是xx_pb2.py - 使用生成的代码,对数据进行编码或者解析
- protocal buffers有两个储存格式,一种是文字形式,一种是二进制形式
-
下载onnx-tensorrt,配合onnx、protobuf等一起加入到项目进行编译,此时nvonnxparser可以替换为
项目内的源代码,那么任何错误都可以在源代码中进行调试
ONNX文件操作
查看节点:model.graph.node
删除节点:model.graph.node.remove(item)先修改输入输出
添加节点:onnx.helper.make_node(name, op_type, inputs, outputs, axes)
onnx拼接:
- 先把pre_onnx的所有节点和输入输出加上前缀
n.name = f'pre/{n.name}' - 把yolov5s的image的输入节点修改为pre_onnx的输出节点
- 把pre_onnx的node全部放到yolov5s的node中
- 把pre_onnx的输入名称作为yolov5s的input名称
正确导出ONNX
-
对于任何用到shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,tensor.view(int(tensor.size(0)), -1),断开跟踪
-
对于nn.Upsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小
-
对于reshape、view操作时,-1的指定请放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1的明确数字
-
torch.onnx.export指定dynamic_axes参数,并且只指定batch维度,禁止其他动态
-
使用opset_version=11,不要低于11
-
避免使用inplace操作,例如y[…, 0:2] = y[…, 0:2] * 2 – 0.5
-
尽量少的出现5个维度,例如ShuffleNet Module,可以考虑合并wh避免出现5维
-
尽量把让后处理部分在onnx模型中实现,降低后处理复杂度
简化过程的复杂度,去掉gather、shape类的节点,很多时候,部分不这么改看似也是可以但是需求复杂后,依旧存在各类问题。按照说的这么修改,基本总能成。做了这些,就不需要使用onnx-simplifer了
Int8量化
利用int8乘法替换float32乘法实现性能加速, 对计算过程提高4倍加速
**量化模式:**1.PTQ训练后量化;2.QAT量化感知训练:TensorRT8.0后版本提供,一般在训练框架中进行
int8标定:
**目的:**使确定编码所用参数是否合适
采用KL散度衡量两个分布之间的差异。
细节:
- 标定预处理必须与推理过程预处理一致
- getBatchSize,标定的batch是多少
- getBatch,标定的输入数据是什么,把指针赋值给bindings即可,返回false表示没有数据了
- readCalibrationCache,若从缓存文件加载标定信息,则可避免读取文件和预处理,若该函数返回空指针则表示没有缓存,程序会重新通过getBatch重新计算
- writeCalibrationCache,当标定结束后,会调用该函数,我们可以储存标定后的缓存结果,多次标定可以使用该缓存实现加速
int8不会大幅降低精度原因
- 将低精度计算造成的损失理解为一种噪声;
- weight大部分服从正态分布,值域小且对称
量化算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y6dpur23-1680900703022)(TensorRT.assets/image-20221116145759444-16685818867501.png)]
左边非对称量化,右边对称量化
-
动态对称量化:onnx
-
动态非对称量化算法
能够更好的捕捉到权重分布,不友好,用的不多
-
静态对称量化算法:TensorRT
量化模式
PTQ训练后量化
Int8量化步骤:
-
配置setFlag nvinfer1::BuilderFlag::kINT8
-
实现Int8EntropyCalibrator类并继承自IInt8EntropyCalibrator2
-
实例化Int8EntropyCalibrator并且设置到config.setInt8Calibrator
-
Int8EntropyCalibrator的作用,是读取并预处理图像数据作为输入
QAT感知量化训练:
量化感知训练钱需要将BN层融合到conv层中
一般都是在训练框架中去做,比如Pytorch
- 在训练的前向和后向传递期间,所有权重和激活都被“假量化”
浮点值四舍五入以模仿 int8 值,但所有计算仍然使用浮点数完成。 - 训练期间的所有权重调整都是在“意识到”模型最终会被量化的情况下进行的;
在量化之后,这种方法通常会产生比动态量化或训练后静态量化更高的准确度
量化的优点
- 加快推理速度,访问一次32位浮点型可以访问4次int8整型,整型运算比浮点型运算更快;
- 减少存储空间,在边缘侧存储空间不足时更具有意义;
- 减少设备功耗,内存耗用少了推理速度快了自然减少了设备功耗;
- 易于在线升级,模型更小意味着更加容易传输;
- 减少内存占用,更小的模型大小意味着不再需要更多的内存;
量化的缺点
- 模型量化增加了操作复杂度,在量化时需要做一些特殊的处理,否则精度损失更严重;
- 模型量化会损失一定的精度,虽然在微调后可以减少精度损失,但推理精度确实下降.
TensorRT插件
**作用:**实现tensorrt不支持的算子。例如HWish
通过官方插件:
编译官方plugin库,将生成的libnvinfer_plugin.so.7替换成原本的.so文件。
编写流程
-
python实现导出onnx
- 对插件的layer,写类A, 继承自torch.autograd.Funtion
- 类A中增加@staticmethod的一个静态方法,
- g.op导出的插件名称就叫“Plugin”:g.op(“Plugin”,x,p)
- name_s = “模型名称”
- info_s = json.dumps(XXX) 会通过json解析,反序列化
-
继承自TRTPlugin
- new_config用于返回自定义config类并进行配置
- getOutputDimensions返回layer处理后的tensor大小
- enqueue实现具体推理工作
-
SetupPlugin()
-
主要实现enqueue
-
RegisterPlugin(): onnxplugin.hpp中,
知识点
- 对插件进行了封装,使得用起来更简单
- 在onnx-tensorrt中添加了onnxplugin.cpp,实现对IPluginV2DynamicExt的封装
- 在onnx-tensorrt/builtin_op_importers.cpp:5095行,添加了Plugin的解析支持
- DEFINE_BUILTIN_OP_IMPORTER(Plugin)
- 使得只要名字是Plugin的节点,都可以解释到该函数上
- 在代码中,为通用插件提供了支持,使得使用者只需要继承简单的插件接口即可完成需求
- 在gen-onnx.py导出时,symbolic函数返回时,g.op返回的永远都是Plugin这个名字,然后name_s指定为自己注册的插件名称,info_s则传递为json字符串,那么复合属性就可以轻易得到支持
封装后的插件实现
- 导出onnx时,按照gen-onnx.py,在symbolic函数返回时,指定g.op的name为Plugin
- 指定g.op中name_s属性为注册的插件名称,对应后续插件类的类名
- 指定g.op中info_属性为需要读取的复合属性,字符串。通常可以传递json,使得属性再复杂都可以,避免使用官方的方式
- 创建easy-plugin.cu文件,定义自己的类并继承自ONNXPlugin::TRTPlugin
- 实现需要的函数
- config_finish[非必要]:配置完成函数
- 当插件配置完毕时调用,可以在其中拿到各种属性,例如info、weights等
- new_config[非必要]:实例化一个配置对象
- 可以自定义LayerConfig类并返回,也可以直接使用LayerConfig类
- 这个函数最大的作用,是配置本插件支持的数据格式和类型。比如fp32和fp16的支持等
- getOutputDimensions[非必要],获取该插件输出的shape大小,默认取第一个输入的大小
- 对应于原始插件的getOutputDimensions函数
- enqueue[必要],插件推理过程
- 插件的实际推理过程,该函数可能在编译和推理阶段数次调用
- config_finish[非必要]:配置完成函数
- 注册插件,使用RegisterPlugin宏
- RegisterPlugin(MYSELU);
- 格式是RegisterPlugin(类名);
- end
封装
目的:降低tensorrt使用门槛和集成难度,避免重复代码,关注业务逻辑,而非复杂细节。
RAII:
资源获取即初始化
目的:创建资源时初始化,哪里分配哪里释放,再配合接口模式
原则:
- 头文件尽量只包含需要的部分
- hpp中不写using namespace
Tensor类封装:
**目的:**实现内存管理,维度管理,偏移量计算,索引计算,CPU/GPU互相自动拷贝。
内存拷贝:
- 定义内存状态,表示当前最新的内存所在位置(GPU,CPU,Init)
- 懒分配原则,需要时才分配
- 获取内存地址:tensor.cpu表示拿到最新数据放到cpu
Builder封装
目的:实现onnx到engine的转换封装,int8封装,
- 模型编译接口
- Int8 标定数据处理
- 插件处理,自定义插件支持
- 特殊处理,reshape钩子hook??
- 定制onnx的输入节点shape
infer封装:
目的:实现tensorRT引擎的推理管理,自动关联引擎的输入和输出,管理上下文,插件
RAII+接口模式的封装
onnxPlugin封装:
目的:封装插件的细节,序列化,反序列化,creator,tensor,weight.
简单的plugin
onnx封装:(官方)
-
protocol通过onnx-ml.proto编译得到onnx-ml.pb.h和onnx-ml.pb.cc
-
onnx-ml.pb.cc的代码操作onnx模型文件,实现增删改
-
onnx-ml.proto描述onnx文件如何组成,结构
推理发生错误解决方案:
onnx_parser:(官方)
其中builtin_op_importers.cpp对应onnx的插件
等价与tensorRT8x
封装后的代码
common
Onnxruntime
python:
session = onnxruntime.InferenceSession("workspace/yolov5s.onnx", providers=["CPUExecutionProvider"])
pred = session.run(["output"], {"images": image_input})[0]
c++:
openvino
intel在cpu上推理加速引擎
线程池
promise:
future:
condition_variable:
性能测量
时间:
#include <chrono>
auto startTime = std::chrono::high_resolution_clock::now();
context->enqueueV2(&buffers[0], stream, nullptr);
cudaStreamSynchronize(stream);
auto endTime = std::chrono::high_resolution_clock::now();
float totalTime = std::chrono::duration<float, std::milli>(endTime - startTime).count();
CUDA耗时:
计算CUDA事件之间的耗时
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
cudaEventRecord(start, stream); // 开始
context->enqueueV2(&buffers[0], stream, nullptr); // cuda事件
cudaEventRecord(end, stream); // 结束
cudaEventSynchronize(end); // 异步
float totalTime;
cudaEventElapsedTime(&totalTime, start, end); // 总耗时
遇见的问题
-
Slice节点,提示slice is out of input range
原因:Slice节点,是由yolo中Focus层导出所生成,生成时,其ends值【通常是-1】给定为极大的整数值,导致两者不兼容
解决方案:- 修改pytorch的导出代码,让这个ends值是tensorRT合理的。修改的方式,是opset_version中找到对应的节点修改他
修改/root/anaconda3/lib/python3.8/site-packages/torch/onnx/symbolic_opset11.py文件中slice函数 - 干掉Focus层,使用cuda核去实现。把Focus层认为是预处理,与BGR->RGB转换、normalize进行合并为一个操作
- 修改pytorch的导出代码,让这个ends值是tensorRT合理的。修改的方式,是opset_version中找到对应的节点修改他
-
model.model[-1].export = True,指定为导出模式
- model.model是所有layer的Sequential结构,model.model[-1]指最后一层,即Detect
- model.model[-1].export = True,会使得Detect在forward时,返回原始数据,而不进行sigmoid等复原操作
因为复原操作需要我们自己定义在cuda核中作为后处理实现 - 后处理干的事情就是把网络输出结果回复成图像大小的框
- 整个推理,就是 预处理(RGBBGR/FOCUS/Normalize) -> CNN(TensorRT) -> 后处理(Decode成框)
-
Gather的错误,While parsing node number 97 [Gather]:
原因:依旧是PyTorch和TensorRT和Onnx之间没有统一的原因。要么他修改了新版本,要么你修改了新版本,反正就不一起改
解决方案:- 干掉Gather,分析原因:
-
出现的第一个场景是:Resize节点
- 修改def symbolic_fn(g, input, output_size, *args):的返回值为
channel, height, width
scales = [1, 2, 2]
return g.op(“Upsample”, input, scales_f=scales)
这里的scales指Upsample的缩放倍数
Gather是由symbolic_fn内的调用造成
经过这个操作后,Reisze以及各种Gather操作合并为一个Upsample,去掉Gather
- 修改def symbolic_fn(g, input, output_size, *args):的返回值为
-
出现的第二个场景是:Reshape和Transpose节点
- 出现在网络的输出节点上,Detect模块上
- 由于Detect的forward中,使用view函数,输入的参数是来自x[i].shape。shape会在导出onnx时进行跟踪并生成节点
因此产生了Gather、shape、concat、constant等一系列多余节点
将x[i].shape返回值,强制转换为int(python类型)时,可以避免节点跟踪和生成多余节点
-
- 干掉Gather,分析原因:
-
维度问题,onnx中和pytorch导出可以是5个维度,但是tensorRT显示是4个维度
- 原因:目前的框架内使用的是tensorRT3个维度版本(CHW),N是由用户推理指定(MaxBatchSize,也是enqueue对应的Batch参数);目前没有考虑5个维度情况,因此需要去掉5个维度的问题。如果使用多维度(5个维度),灵活度上去,复杂度会异常高
- 解决方案:去掉5个维度的影响,这通常都是可以去掉的,在yolov5中,去掉reshape和transpose(也就是view和permute)
-
推理过程中反序列化报错
Serialization (Serialization assertion creator failed.Cannot deserialize plugin since corresponding IPluginCreator not found in Plugin Registry)
-
原因:为了使用TensorRT的插件,libnvinfer_plugin.so库必须被加载,所有插件必须通过调用initLibNvinferPlugins注册.
-
解决:初始化并登记所有TensorRT的plugins到Plugin Registry.添加
initLibNvinferPlugin()
- 推理耗时计算
#include <chorno>
auto startTime = std::chorno::high_resolution_clock::now();
auto endTime = std::chorno::high_resolution_clock::now();
float totalTime= std::chorno::duration<float, std::milli>(endTime - startTime).count();
- best.onnx含有nms,输出为[concatoutput_dim, 7],其中onnx转tensorrt文件后,输出维度为[100, 7],即每次推理会输出100X7个框。如何改成输出[框的个数,7],即输出维度第一维也为动态。
- 解决:1.在导出ONNX模型时去掉后处理,尽量不引入自定义OP,然后导出ONNX模型, 之后再通过CUDA编程实现NMS计算。
- tensorrt的精度FP32,(Quadro P4000不支持FP16), 推理时间均为60ms左右,而采用onnx文件在python进行推理一张图片1.7ms左右. 采用tensorrt加速反而推理速度变慢了?
time.time()计时单位为秒
-
预处理未进行cuda加速。
-
采用不带nms的onnx转FP32精度的TensorRT的engine模型推理一张图片需要2ms左右,采用CUDA后处理部分需要35ms左右,如何对nms进行提速?
- 解决:可尝试将nms融入onnx,采用训练后INT8量化,降低模型精度;或者基于TensorRT 8.0之后版本,在训练过程中进行量化
11.tensorrt推理后:采用size_t类型输入到模型中,float类型输出,当将gpu推理的结果复制到cpu上时耗时4000ms。
解决办法:
nms,输出为[concatoutput_dim, 7],其中onnx转tensorrt文件后,输出维度为[100, 7],即每次推理会输出100X7个框。如何改成输出[框的个数,7],即输出维度第一维也为动态。
- 解决:1.在导出ONNX模型时去掉后处理,尽量不引入自定义OP,然后导出ONNX模型, 之后再通过CUDA编程实现NMS计算。
- tensorrt的精度FP32,(Quadro P4000不支持FP16), 推理时间均为60ms左右,而采用onnx文件在python进行推理一张图片1.7ms左右. 采用tensorrt加速反而推理速度变慢了?
time.time()计时单位为秒
-
预处理未进行cuda加速。
-
采用不带nms的onnx转FP32精度的TensorRT的engine模型推理一张图片需要2ms左右,采用CUDA后处理部分需要35ms左右,如何对nms进行提速?
- 解决:可尝试将nms融入onnx,采用训练后INT8量化,降低模型精度;或者基于TensorRT 8.0之后版本,在训练过程中进行量化
11.tensorrt推理后:采用size_t类型输入到模型中,float类型输出,当将gpu推理的结果复制到cpu上时耗时4000ms。
解决办法:
使用更快的数据传输方式:可以尝试使用更快的数据传输方式,如CUDA的异步内存拷贝,或者使用更快的设备之间的数据传输方式,如PCIe Gen3 x16或NVLink等。
减小数据传输量:可以尝试减小数据传输量,如使用更小的数据类型(如半精度浮点数或整数量化)或仅传输需要的数据(如仅传输置信度最高的检测框)。
对推理过程进行优化:可以尝试优化推理过程中的计算流程,如使用TensorRT的优化算法、减少计算图中的计算节点数量等,以减少GPU计算时间。
使用更快的CPU:可以尝试使用更快的CPU,以加快将数据从GPU传输到CPU的速度。
减少CPU处理时间:可以尝试减少CPU处理时间,如使用多线程或异步方式处理数据,以减少CPU处理数据的时间。
文章出处登录后可见!