本文基于斯坦福cs231n课程,更多详细笔记[0]
图像分类遇到的问题
- semantic gap 语义鸿沟,人看到的是一张图片,但是计算机看到的是数字矩阵
- viewpoint variation 视角不同,看到的内容不同
- Illumination 照明问题
- Deformation 变形问题
- Occlusion 遮挡问题
- Background Clutter 比如猫身上的条纹和背景很像
- Intraclass variation 类内差异问题,猫有不同的大小颜色等
很难直接写代码来判断是什么对象

数据驱动的方法
- 图像数据集的集合
- 使用机器学习方法训练分类器
- 在新图像上评估此分类器
K-最近邻算法分类
通过比较图像之间的差异进行分类,并通过像素比较差异。
首先,通过训练函数简单地记住所有的训练数据。每次输入一张图片进行预测,都会遍历记忆的训练数据,找到最接近的图片,根据最接近的图片的类别对输入的图片进行预测。类别。
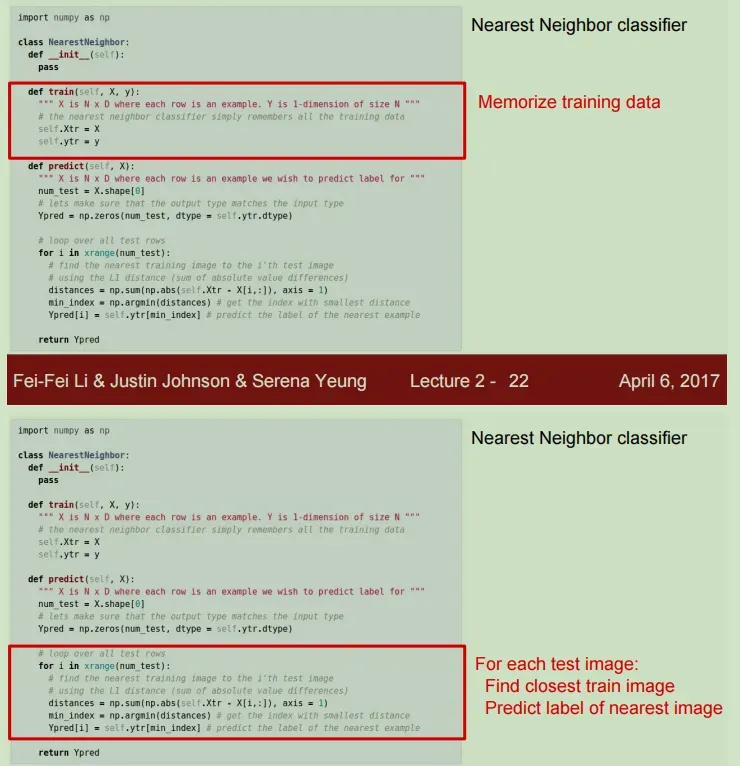
训练的复杂度:O(1)
预测的复杂度:O(N)
这是一个糟糕的结果,因为该算法在训练时很快,但在实际进行预测时却很慢,这与我们最初的意图完全相反。
K最邻近
如果只计算最近的图像,就会有缺点。例如,在下图中,绿色分区中有一个黄色点。因为只计算最近的点,所以将为该区域选择黄色点。
所以K最邻近算法是找到最近的K的点,然后在这些邻近点中进行投票,然后这些票数多的临近点预测出结果,实现这个算法的方式有很多,比如将距离进行加权,但是最简单的还是进行多数投票,临近点中哪个类别最多就确定为哪个类别。
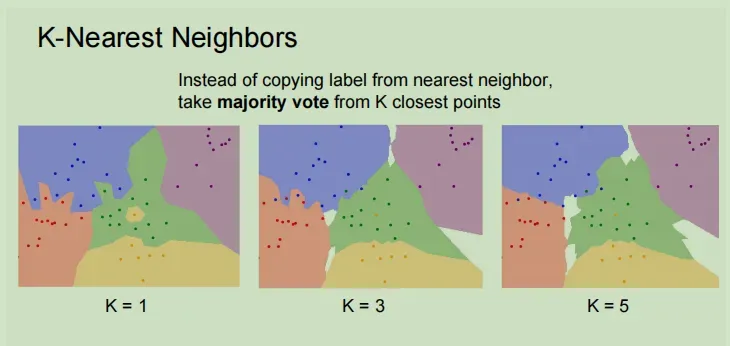
当k=3时,图中的黄色噪点不会导致周围的区域划分为黄色了,决策边界也将随着K的增加而被平滑掉。图中的白色区域代表在这个区域中没有临近点,即没有进行分类。
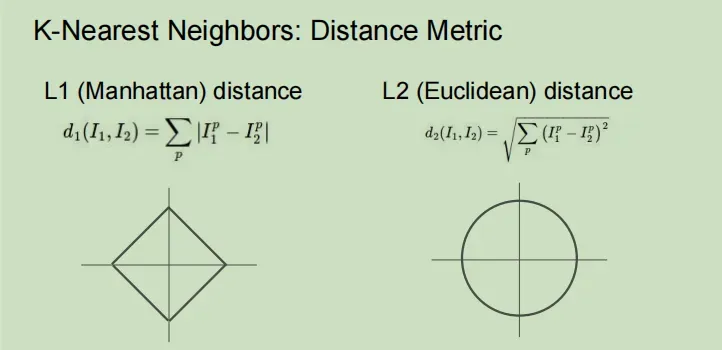
衡量距离的两种函数
曼哈顿距离(L1)和欧氏距离(L2)
L1距离取决于选取的坐标轴,如果你旋转坐标轴,那么L1距离可能改变,但是L2距离不会改变。所以,如果你输入的向量值有一部分有一些重要的意义,那么L1可能更合适,如果只是空间中的通用向量,没有什么意义,那么L2可能更自然一些。
超参数的确定
超参数:K和距离测量方式
q:什么时候L1比L2好?
a:需要根据实际问题来看,最佳的方法时两种都尝试一下
错误的判断方法:
- 不区分测试集和训练集,选择表现最好的超参数进行整体训练
- 训练后,在测试集上使用,调整参数,选择在测试集上表现最好的超参数。缺点:遇到一组新数据时可能会失效
正确方法:
它分为三个部分,训练、验证和测试。在验证数据集上选择合适的超参数,最后可以使用测试数据集

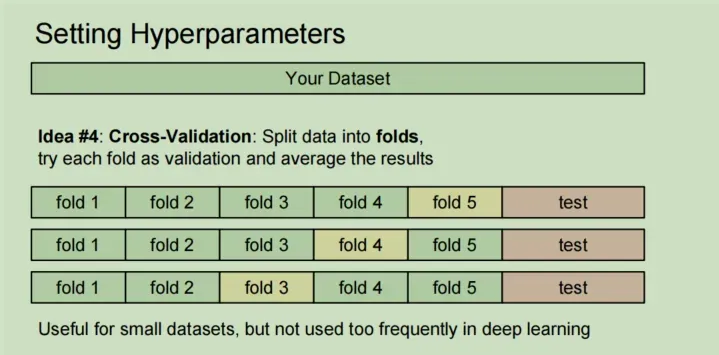
或者使用交叉验证,但是这种方法在深度学习中不是很常见,因为训练数据本身非常耗费资源,而交叉验证需要额外训练几次,非常耗费资源
交叉验证的思想是将测试数据集平均分成若干份后的数据,每次选取其中一份作为验证数据集,其余作为训练数据集。这样,多次训练得到最优参数。
测试集是否能很好地代表真实世界的数据?将收集到的数据随机分为训练集和测试集。
knn不会被使用,它的测试时间很长,使用L1或L2这种向量化的距离衡量方式不适合表示图像之间的视觉相似度,例子:
维度灾难,所需样本数量呈指数增长
总结:
- 在图像分类中,我们使用训练数据集,包括图像和标签,我们需要在测试数据集上预测图像的标签
- KNN分类器预测标签基于最近的训练样例
- 超参数是,距离的衡量方式和K
- 使用验证数据集选择超参数,最后只用测试数据集测试模型
线性分类
linear classification
神经网络的模块化
将神经网络想象成乐高积木。您可以将不同的神经网络模块拼接成一个大型卷积网络。线性分类器是深度学习应用中最基本的构建块之一。
再例如,该系统输入一幅图像输出对于该图像的描述性句子,工作原理就是使用CNN关注图像处理图像,使用RNN关注语义处理语言,将这两个网络放在一起就可以组成一个很好的处理系统。

线性分类器
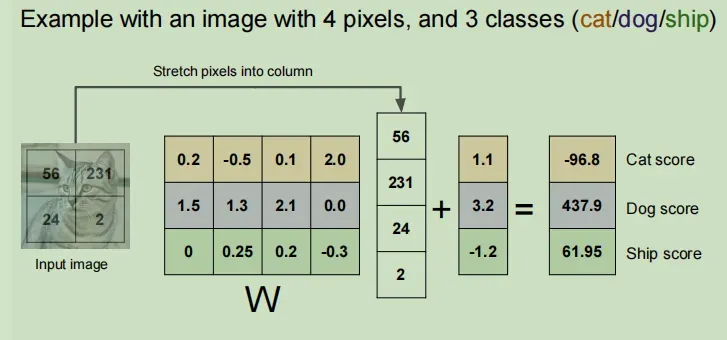
思想就是将图片参数输入,与权重W相乘,可以再加上一个偏差量b(偏差给了数据独立的缩放比例以及每个类别的偏移量),得到一个列向量,每个元素都代表一个类别的得分,该图像所属类别为得分高的那个。原理如下如所示:

将一个32 * 32像素三通道的图片看成一个3072的列向量,由于类别一共有10类,那么权重W就可以设置为10 * 3072的矩阵,那么结果就是一个长度为10的列向量。
具体来看下面这个例子,假设一张像素为4的图片,类别有三类,整个流程如下:
问题来了,那个这个训练好的权重矩阵W到底和输入的图像有什么关系呢?其实可以把权重矩阵的每一行看成一个模板,我们把矩阵中每一行单独拿出来做成一个图像,在CIFAR-10中,训练好的权重矩阵W的每一行对应的图像如下图:

另一种解释:
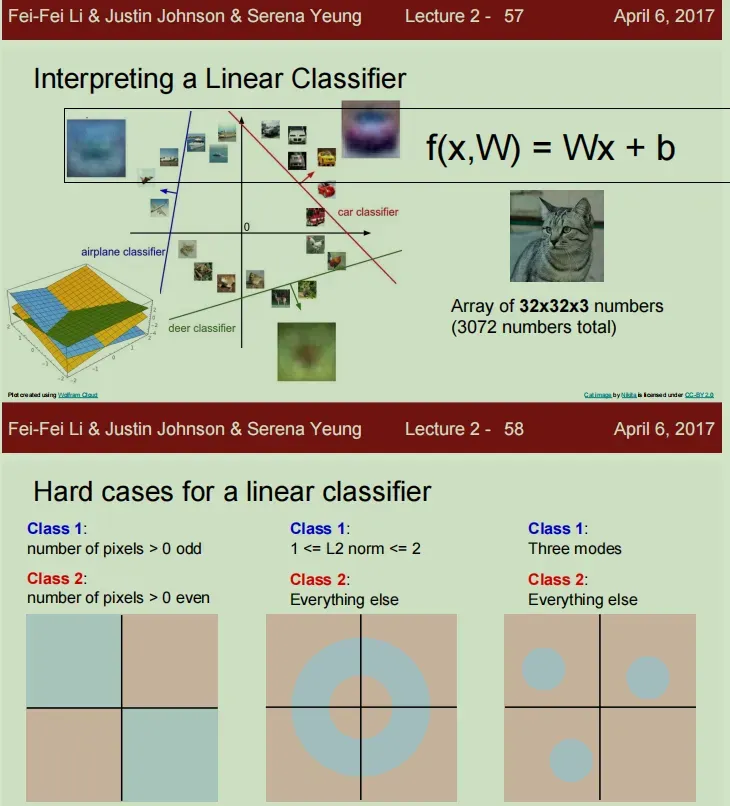
你也可以把每张图像想象成高维空间中的一个点,我们尝试用一条线对每个点进行分类。但这也带来了线性分类器的困境,当多模态数据出现在不同的域空间时(例如,一个类别出现在不同的域空间中)
更多内容可以访问我的个人博客[0]
文章出处登录后可见!