原文标题 :Automated Data Cleaning with Python
使用 Python 进行自动数据清理
如何自动化数据准备并节省下一个数据科学项目的时间

数据科学家普遍认为,数据清理和预处理是数据科学项目的主要部分。而且,您可能会同意我的看法,这不是项目中最令人兴奋的部分。
所以,(让我们问自己):我们可以自动化这个过程吗?
好吧,自动化数据清理说起来容易做起来难,因为所需的步骤高度依赖于数据的形状和特定领域的用例。尽管如此,还是有一些方法可以以标准化的方式将其中至少一部分自动化。
在本文中,我将向您展示如何在 Python 3.8 中构建自己的自动化数据清理管道。
在 Github 上查看 AutoClean 项目。[0]
1 |我们想要自动化什么?
在深入研究这个项目之前,我们应该问自己的第一个也是最重要的问题是:我们可以真正标准化和自动化数据清理过程的哪些步骤?
最有可能自动化或标准化的步骤是在几乎每个数据科学项目的每个清洁过程中一遍又一遍地执行的步骤。而且,由于我们要构建一个“一刀切”的管道,我们要确保我们的处理步骤相当通用,并且可以适应各种类型的数据集。
例如,在大多数项目中反复提出的一些常见问题包括:
- 我的数据采用什么格式? CSV、JSON、文本?还是其他格式?我将如何处理这种格式?
- 我们的数据特征有哪些数据类型?我们的数据集是否包含分类和/或数字数据?我们如何处理每一个?我们想对我们的数据进行一次热编码,和/或执行数据类型转换吗?
- 我们的数据是否包含缺失值?如果是,我们如何处理它们?我们要执行一些插补技术吗?或者我们可以安全地删除缺失值的观察吗?
- 我们的数据是否包含异常值?如果是,我们是应用正则化技术,还是让它们保持原样? ……等等,我们甚至认为什么是“异常值”?
无论我们的项目针对什么用例,这些问题很可能需要解决,因此可以成为自动化的一个很好的主题。
这些问题的答案以及它们的实现将在接下来的几章中讨论和展示。
2 |管道的构建块
首先,让我们从导入我们将使用的库开始。这些将主要是 Python Pandas、Sklearn 和 Numpy 库,因为它们在处理数据时非常有用。
我们将定义我们的脚本将以 Pandas 数据帧作为输入,这意味着我们至少需要将数据转换为 Pandas 数据帧格式,然后才能由我们的管道处理。
现在让我们看看我们管道的构建块。以下章节将经历以下处理步骤:
[Block 1] Missing Values
[Block 2] Outliers
[Block 3] Categorical Encoding
[Block 4] DateTime 特征的提取
[Block 5] Polishing Steps
[ Block 1 ] Missing Values
一个项目以包含缺失值的数据集开始并且有多种处理它们的方法是相当普遍的。我们可以简单地删除包含缺失值的观察,或者我们可以使用插补技术。借助各种回归或分类模型来预测数据中的缺失值也是一种常见的做法。
💡 插补技术用某些值(如平均值)或与特征空间中的其他样本值相似的值(例如 K-NN)替换缺失数据。
我们如何处理缺失值的选择主要取决于:
- 数据类型(数值或分类)和
- 相对于我们拥有的总样本数量,我们有多少缺失值(从 100k 中删除 1 个观测值与从 100 个中删除 1 个观测值的影响不同)
我们的管道将遵循策略插补>删除,并将支持以下技术:使用线性和逻辑回归进行预测,使用 K-NN、均值、中值和众数进行插补,以及删除。
好的,现在我们可以开始为我们的第一个构建块编写函数了。我们将首先创建一个单独的类来处理缺失值。下面的函数句柄将以不同的方式处理数值和分类缺失值:一些插补技术可能仅适用于数值数据,而有些仅适用于分类数据。让我们看看它处理数字特征的第一部分:
此函数检查为数字和分类特征选择了哪种处理方法。默认设置设置为“自动”,这意味着:
- 数值缺失值将首先通过线性回归的预测进行估算,其余值将通过 K-NN 估算
- 分类缺失值将首先通过 Logistic Regression 的预测进行插补,其余值将通过 K-NN 进行插补
对于分类特征,适用与上述相同的原则,除了我们将仅支持使用 Logistic 回归、K-NN 和模式插补进行插补。使用 K-NN 时,我们将首先将分类特征标记为整数,使用这些标签来预测我们的缺失值,最后将标签映射回其原始值。
根据选择的处理方法,handle 函数从其类中调用所需的函数,然后在各种 Sklearn 包的帮助下处理数据:_impute 函数将负责 K-NN、均值、中值和模式插补, _lin_regression_impute 和 log_regression_impute 将通过预测进行插补,我假设 _delete 的作用是不言自明的。
我们最终的 MissingValues 类结构如下所示:
我不会详细介绍该类其余函数中的代码,但我邀请您查看 AutoClean 存储库中的完整源代码。[0]
在我们完成所有必需的步骤后,我们的函数然后输出处理后的输入数据。
酷,我们通过了管道的第一个区块🎉。现在让我们考虑如何处理数据中的异常值。
[ Block 2 ] Outliers
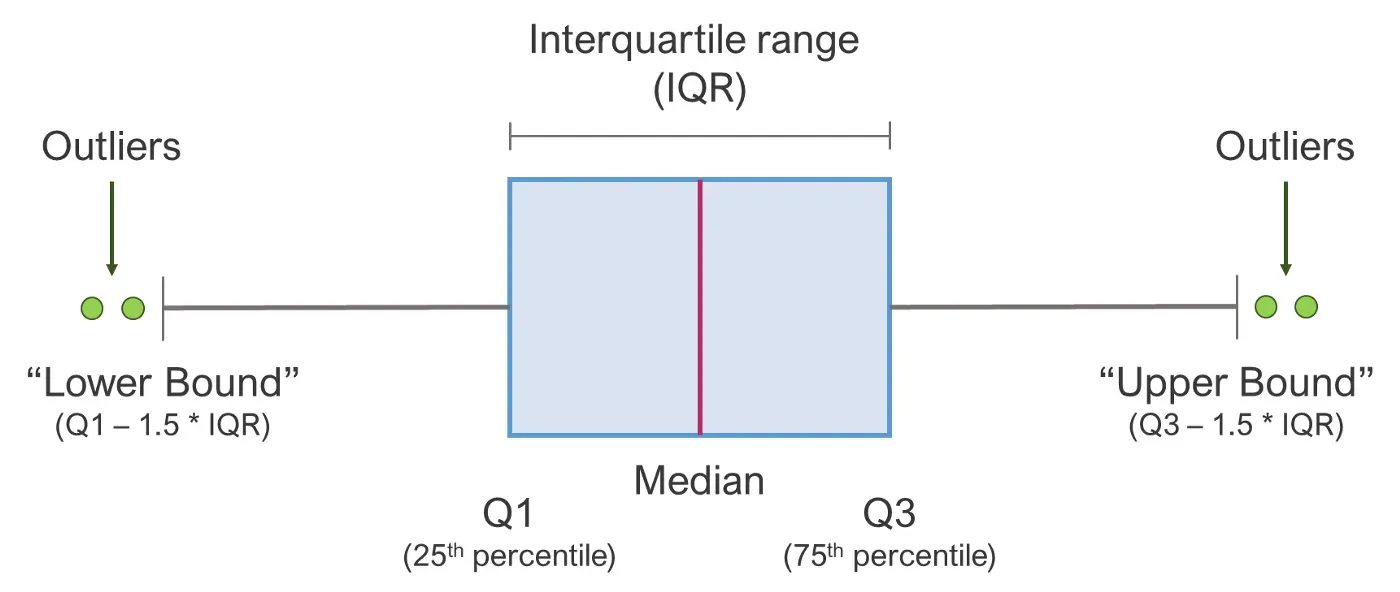
我们的第二个部分将专注于处理数据中的异常值。首先我们需要问自己:我们什么时候认为一个值是异常值?对于我们的管道,我们将使用一个常用的规则,即如果数据点超出以下范围,则可以将其视为异常值:
[Q1 — 1.5 * IQR; Q3 + 1.5 * IQR]
…其中 Q1 和 Q3 是第一个和第三个四分位数,IQR 是四分位数范围。在下面,您可以通过箱线图很好地看到这一点:
既然我们已经定义了异常值是什么,我们现在必须决定如何处理这些异常值。同样有各种策略可以做到这一点,对于我们的用例,我们将关注以下两个:winsorization 和删除。
💡 Winsorization 在统计中用于限制数据中的极值,并通过将异常值替换为数据的特定百分比来减少异常值的影响。
当使用winsorization时,我们将再次使用我们上面定义的范围来替换异常值:
- values > upper bound 将替换为上限值和
- 值 < 下限将被下限值替换。
Outliers 类的最终结构如下所示:
我们到了第二个块的末尾——现在让我们看看如何编码分类数据。
[ Block 3 ] Categorical Encoding
为了能够使用分类数据执行计算,在大多数情况下,我们需要我们的数据是数字类型 i。 e.数字或整数。因此,常见的技术包括 one-hot 编码数据或标签编码数据。
💡 数据的 One-hot 编码将特征的每个唯一值表示为二进制向量,而标签编码为每个值分配一个唯一整数。
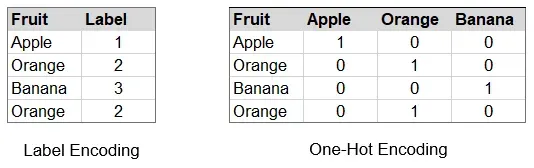
每种方法都有各种优缺点,例如 f. e. one-hot 编码产生了许多附加功能的事实。此外,如果我们标记编码,某些算法可能会将标签解释为数学相关:1 个苹果 + 1 个橙子 = 1 个香蕉,这显然是对此类分类数据的错误解释。
对于我们的管道,我们将设置默认策略“auto”以根据以下规则执行编码:
- 如果特征包含 < 10 个唯一值,它将是 one-hot-encoded
- 如果特征包含 < 20 个唯一值,它将被标签编码
- 如果特征包含 > 20 个唯一值,则不会对其进行编码
这是处理编码过程的一种非常原始且快速的方法,可能会派上用场,但也可能导致编码不完全适合我们的数据。即使自动化很棒,我们仍然希望确保我们也可以手动定义哪些特征应该被编码,以及如何编码。这是在 EncodeCateg 类的句柄函数中实现的:
handle 函数将列表作为输入,而我们想要手动编码的特征可以通过列名或索引来定义,如下所示:
encode_categ = [‘onehot’, [‘column_name’, 2]]现在我们已经定义了如何处理异常值,我们可以继续我们的第四块,它将涵盖日期时间特征的提取。
[ Block 4 ] DateTime 特征的提取
如果我们的数据集包含具有日期时间值的特征,例如时间戳或日期,我们很可能希望提取这些特征,以便在以后处理或可视化时更容易处理。
我们也可以以自动方式执行此操作:我们将让我们的管道搜索功能并检查其中一个是否可以转换为日期时间类型。如果是,那么我们可以放心地假设此功能包含日期时间值。
我们可以定义提取日期时间特征的粒度,而默认设置为“s”表示秒。提取后,该函数会检查日期和时间的条目是否具有有效含义:如果提取的“日”、“月”和“年”列均包含 0,则将全部删除三列。 “小时”、“分钟”和“秒”也是如此。
现在我们已经完成了日期时间提取,我们可以继续进行管道的最后一个构建块,这将包括一些最终调整以完善我们的输出数据帧。
[ Block 5 ] Dataframe Polishing
现在我们已经处理了我们的数据集,我们仍然需要做一些调整以使我们的数据框“看起来不错”。我的意思是什么?
首先,由于插补技术或应用的其他处理步骤,一些最初为整数类型的特征可能已转换为浮点数。在输出我们的最终数据帧之前,我们会将这些值转换回整数。
其次,我们希望将数据集中的所有浮点特征四舍五入到与原始输入数据集中相同的小数位数。一方面这是为了避免浮点小数中不必要的尾随 0,另一方面确保不要将我们的值四舍五入超过我们的原始值。
同样,我不会更详细地介绍这些想法背后的代码,但我邀请您查看 AutoClean 存储库中的完整源代码。[0]
3 |把它们放在一起
首先,恭喜你坚持到现在! 🎉
我们现在已经到了想要将所有构建块放在一起的部分,这样我们就可以真正开始使用我们的管道了。您可以在我的 GitHub 存储库中找到完整的 AutoClean 代码,而不是在这里发布完整代码:
让我们看一个 AutoClean 如何处理下面的示例数据集的可视化示例:
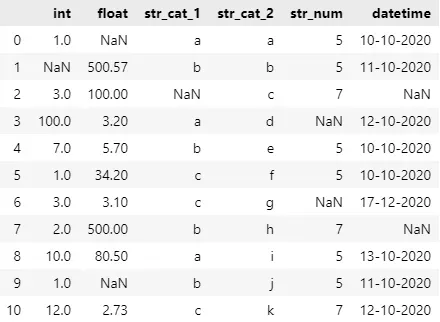
我生成了一个随机数据集,如您所见,当涉及到不同的数据类型时,我让它变得相当不同,并且我在数据集中添加了一些随机的 NaN 值。
现在我们可以运行 AutoClean 脚本,如下所示:
生成的已清理输出数据帧如下所示:
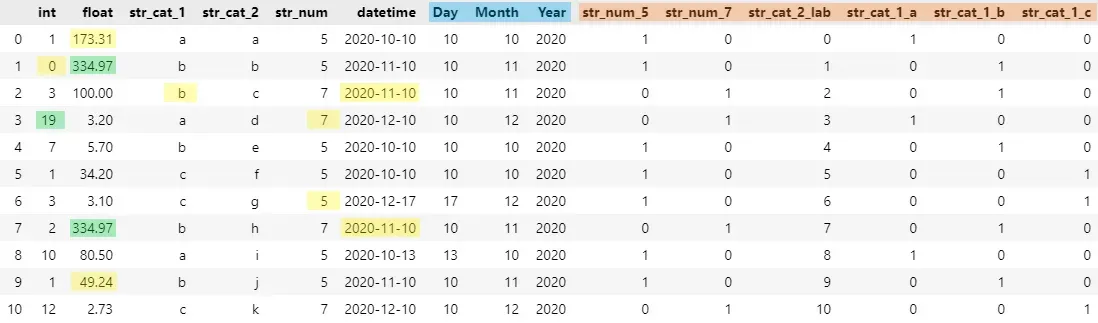
在上图中,您将直观地看到 AutoClean 对我们的数据所做的更改。估算的缺失值用黄色标记,异常值用绿色标记,提取的日期时间值用蓝色标记,分类编码用橙色标记。
我希望这篇文章对您有所帮助,并且 AutoClean 将帮助您节省一些宝贵的时间。 🚀
如果您有任何问题或反馈,请随时发表评论。也欢迎在 GitHub 上投稿![0]
References:
[1] N. Tamboli,所有你需要知道的关于不同类型的缺失数据值以及如何处理它 (2021)[0]
[2] C. Tylor,什么是四分位距规则? (2018)[0]
[3] J. Brownlee,分类数据的序数和单热编码 (2020)[0]
文章出处登录后可见!