原文标题 :TensorFlow for Computer Vision — How to Implement Convolutions From Scratch in Python
用于计算机视觉的 TensorFlow — 如何在 Python 中从零开始实现卷积
你需要 10 分钟在 Numpy 中使用填充实现卷积

卷积网络很有趣。上周您看到了与普通人工神经网络相比,它们如何提高模型性能。但是卷积实际上对图像做了什么?这就是你今天要学习的内容。[0]
阅读后,您将知道如何使用 Numpy 从头开始编写卷积函数。您将对图像应用模糊、锐化和轮廓等过滤器,您还将了解填充在卷积层中的作用。
这是很多工作,我们从头开始做所有事情。让我们潜入。
不想读书?请观看我的视频:
您可以在 GitHub 上下载源代码。[0]
How Convolutions Work
卷积神经网络是用于图像分类的一种特殊类型的神经网络。任何卷积神经网络的核心都是卷积,这是一种高度专门用于检测图像中的模式的操作。
卷积层要求您指定过滤器(内核)的数量。将这些视为许多模式检测器。早期的卷积层检测基本模式,例如边缘、角落等。根据数据集,在后面的卷积层(例如狗耳朵或猫爪)会检测到专门的模式。
单个过滤器只是一个小矩阵(通常是矩形)。决定行数和列数是您的任务,但 3×3 或 5×5 是很好的起点。过滤器矩阵内的值是随机初始化的。神经网络的任务是在给定特定数据集的情况下学习过滤矩阵的最佳值。
让我们看一下实际的卷积操作。我们有一个 5×5 的图像和一个 3×3 的滤镜。过滤器在图像中每 3×3 组像素上滑动(卷积),并计算元素乘法。然后将乘法结果相加:
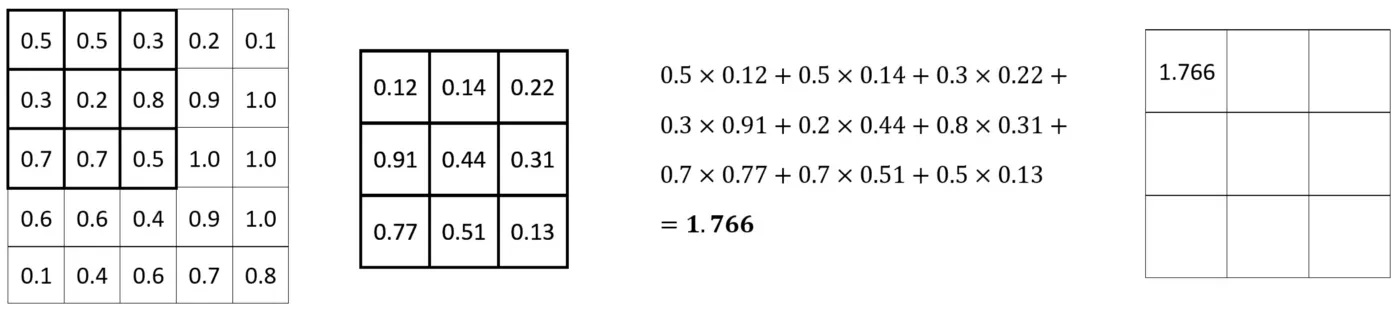
对每组 3×3 像素重复该过程。这是以下集合的计算:

它一直持续下去,直到达到最终的 3×3 像素集:
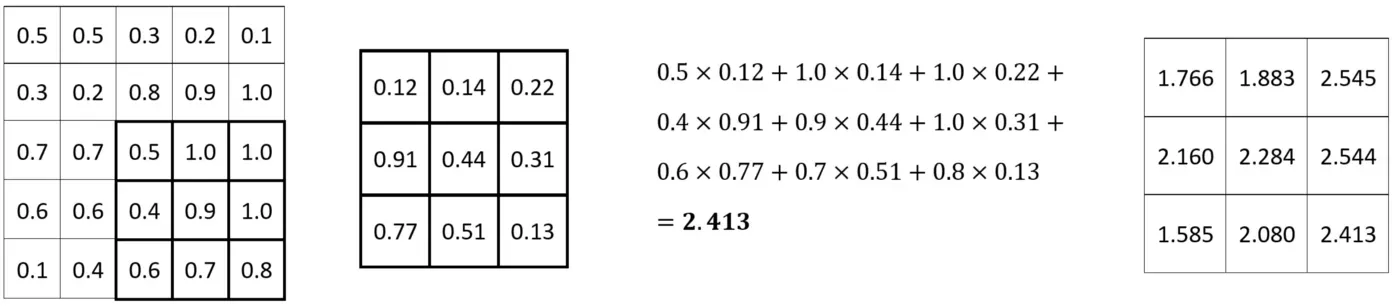
简而言之,这就是卷积!卷积层对于找到最佳滤波器矩阵很有用,但卷积本身仅将滤波器应用于图像。对于不同的图像操作,例如模糊和锐化,有大量众所周知的过滤器矩阵。接下来让我们看看如何与他们合作。
数据集和图像加载
在本文的其余部分,我们将使用来自 Kaggle 的 Dogs vs. Cats 数据集。它是根据知识共享许可证获得许可的,这意味着您可以免费使用它。之前的一篇文章描述了如何对其进行预处理,因此如果您想在相同的图像上跟进,请确保复制代码。[0][1]
这不是必需的,因为您可以将卷积应用于任何图像。说真的,从网上下载任何图像,今天它都会为您服务。
让我们把库导入排除在外。你需要 Numpy 来进行数学运算,并需要 PIL 和 Matplotlib 来显示图像:
从这里,我们还要声明两个用于显示图像的函数。第一个绘制单个图像,第二个绘制其中两个并排(1 行,2 列):
您现在可以加载和显示图像。为简单起见,我们将对其进行灰度化并将其调整为 224×224。这些转换都不是强制性的,但它们使我们的工作更容易一些,因为只有一个颜色通道可以应用卷积:

这可以解决无聊的事情。我们将所有卷积过滤器应用到上图。但首先,让我们声明几个过滤器矩阵。
为卷积声明过滤器
神经网络中卷积层的任务是找到 N 个能够最好地从图像中提取特征的过滤器。您知道有用于执行不同图像操作的已知过滤器吗?
嗯,有——比如用于锐化、模糊和勾画的过滤器。我从 setosa.io 网站复制了过滤器矩阵值,我强烈建议您查看它以进行更深入的了解。[0]
无论如何,所有提到的过滤器都不过是 3×3 矩阵。复制以下代码以将它们存储到变量中:
很简单,对吧?这就是单个过滤器的全部内容。接下来让我们从头开始编写卷积并将它们应用于我们的图像。
从头开始实现卷积
对图像应用卷积会使其更小(假设没有填充)。小多少取决于过滤器的尺寸。我们所有的都是 3×3,但你可以做得更大。
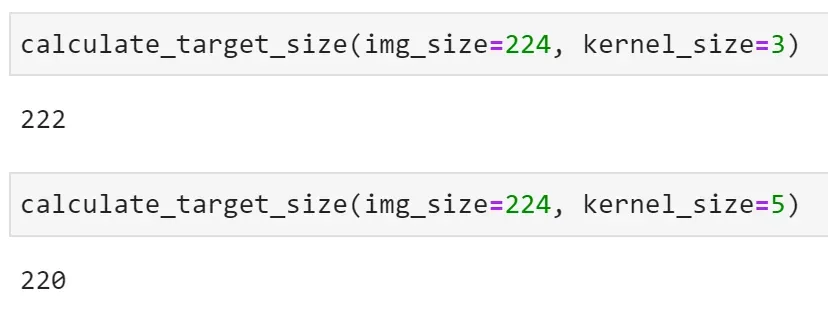
在图像上滑动或卷积 3×3 过滤器意味着我们将在所有方面丢失一个像素(总共 2 个)。例如,在 224×224 图像上滑动 3×3 过滤器会产生 222×222 图像。同样,在同一图像上滑动 5×5 过滤器会产生 220×220 图像。
我们将声明一个辅助函数来计算应用卷积后的图像大小。这没什么花哨的,但会让我们的生活更轻松一些。它基本上计算了可以适合图像的过滤器大小的窗口数(假设为方形图像):
这是几个测试的结果:
- 图像尺寸:224,滤镜尺寸:3
- 图像尺寸:224,滤镜尺寸:5
像宣传的那样工作。接下来让我们研究一个卷积函数。以下是 3×3 过滤器对单个 3×3 图像子集的作用:
- 将其提取到单独的矩阵中
- 在图像子集和过滤器之间进行元素乘法
- Sums the results
这是单个 3×3 像素子集的代码实现:

这很容易,但是如何将逻辑应用于整个图像?嗯,很容易。 convolve() 函数计算目标大小并创建具有该形状的零矩阵,迭代图像矩阵的所有行和列,对其进行子集化,并应用卷积。放在一个句子里听起来很多,但代码不应该让你太头疼:
让我们测试一下。以下代码段将锐化滤镜应用于我们的图像:

您可以使用 plot_two_images() 函数在转换前后可视化我们的猫图像:

颜色有点偏,因为右图中的值不在 0 到 255 之间。这不是一个大问题,但您可以通过用零替换所有负值来“修复”它:

右边的图像肯定看起来很锐利,没有争论。让我们看看接下来的模糊处理:

模糊滤镜矩阵没有负值,因此着色是相同的。再一次,没有争论 – 模糊过滤器像宣传的那样工作。
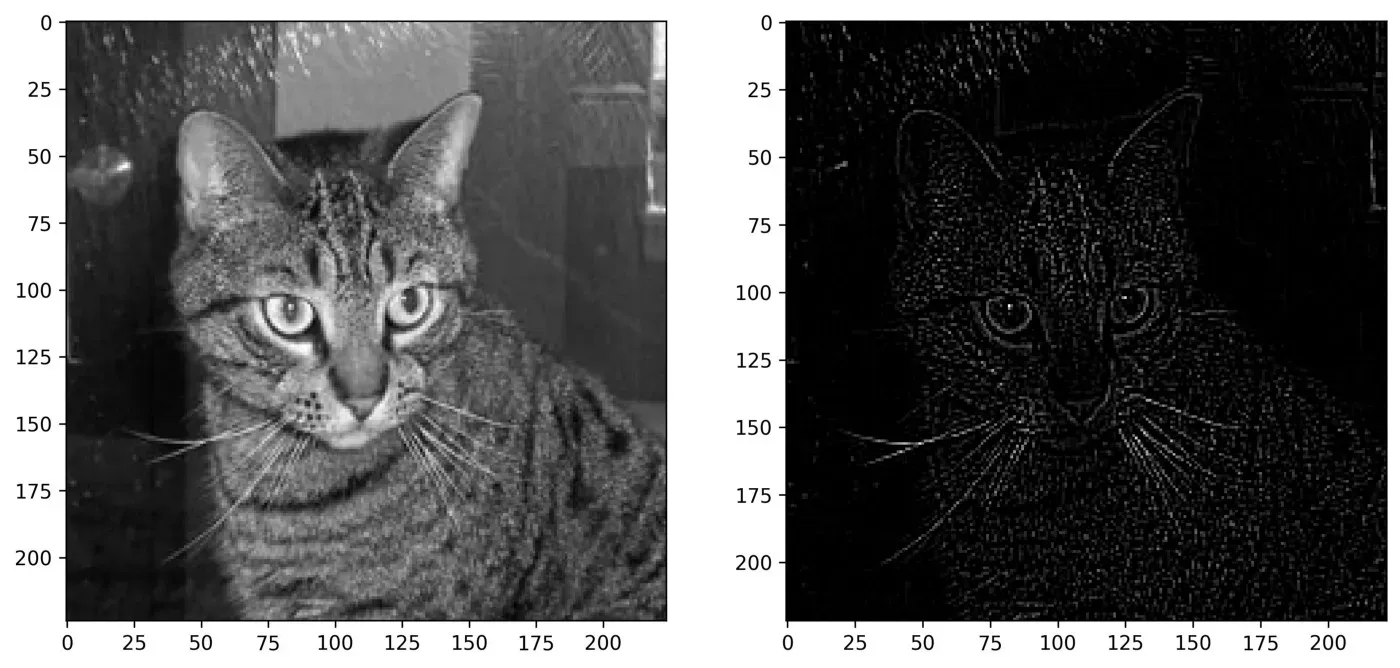
最后,让我们看看轮廓过滤器会对我们的图像做什么:
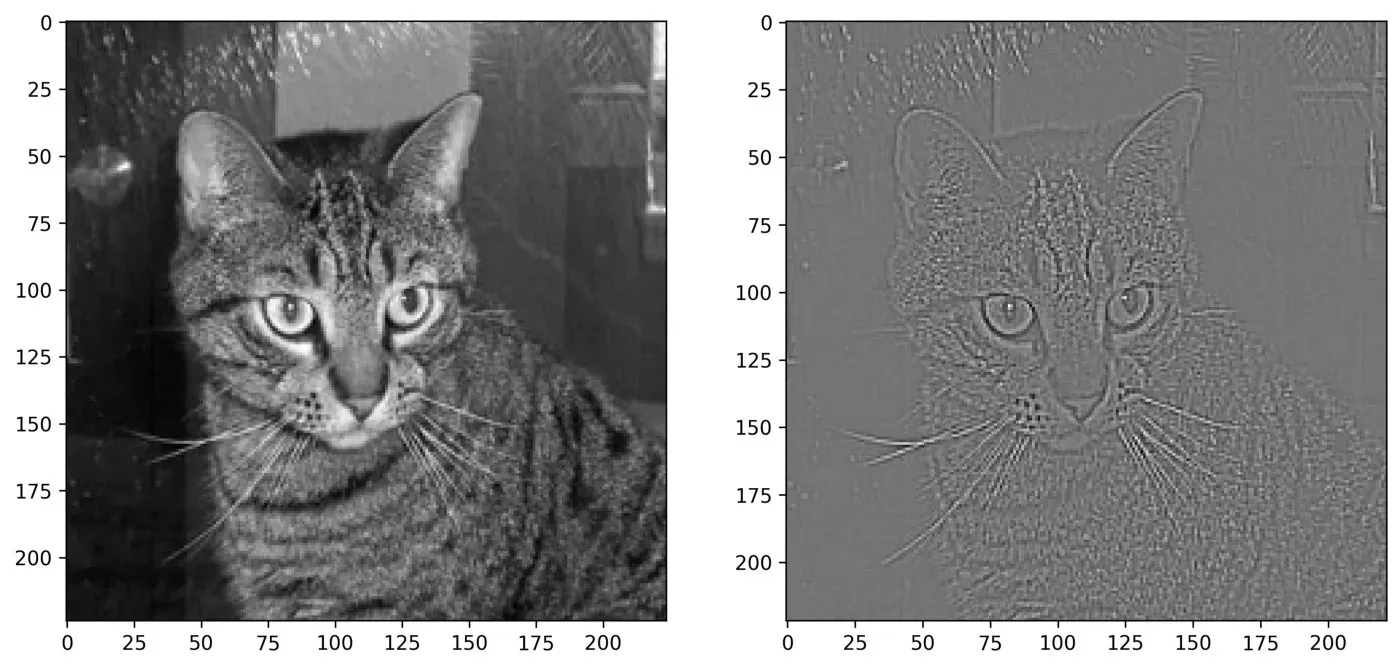
它还存在着色问题,因为矩阵中的值大多为负数。使用negative_to_zero() 来获得更清晰的想法:
plot_two_images(
img1=img,
img2=negative_to_zero(img=img_outlined)
)
你知道唯一的问题是什么吗?卷积图像的形状为 222×222 像素。如果要保持原始大小为 224×224 像素怎么办?这就是填充发挥作用的地方。
从头开始使用填充实现卷积
TensorFlow 的 Conv2D 层允许您为填充参数指定有效或相同。第一个(默认)在应用卷积操作之前不添加填充。这基本上就是我们在上一节中介绍的内容。
第二个根据过滤器大小添加填充,因此源图像和卷积图像具有相同的形状。
填充本质上是图像周围的“黑色”边框。它是黑色的,因为值为零,而零代表黑色。黑色边框对计算没有任何副作用,因为它只是与零的乘法。
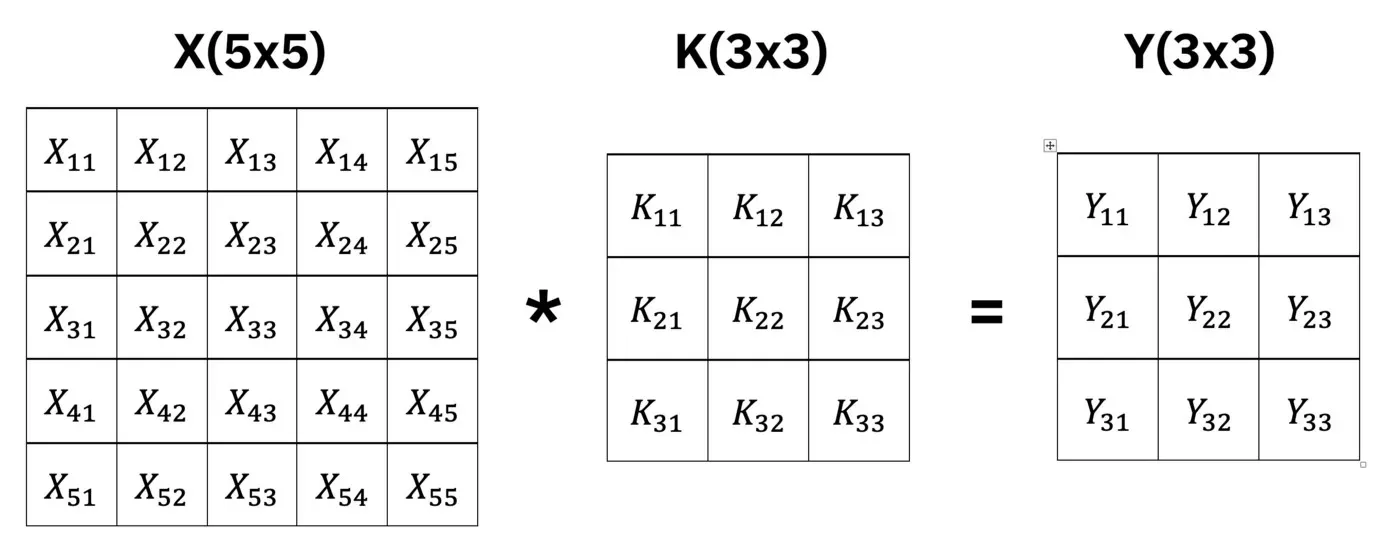
在编写任何代码之前,让我们对这个概念有一个直观的理解。下图向您展示了图像 X 在应用过滤器 K 时发生的情况。基本上,它从 5×5 变为 3×3 (Y):
添加像素宽度的填充会产生 7×7 像素的输入图像 (X) 和 5×5 像素的结果图像 (Y):
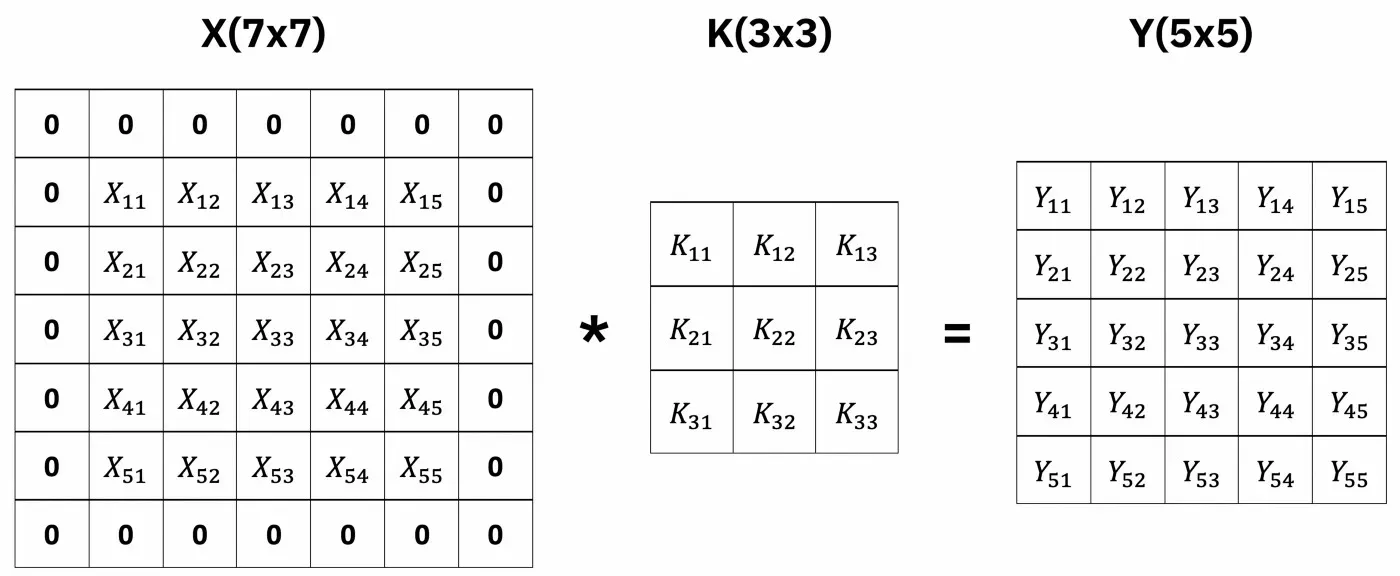
第二幅图像中的 Y 与第一幅图像中的 X 具有相同数量的像素,这正是我们想要的。卷积操作必须从图像中获取一些像素,最好将这些像素设为零。
在现实世界中,边缘上的像素通常不包含重要的图案,因此丢失它们并不是世界上最糟糕的事情。
现在进入代码。首先,让我们声明一个函数,该函数返回我们需要在单边填充图像的像素数,具体取决于内核大小。这只是一个与 2 的整数除法:
def get_padding_width_per_side(kernel_size: int) -> int:
# Simple integer division
return kernel_size // 2以下是内核大小 3 和 5 的几个示例:

没什么。我们现在将编写一个向图像添加填充的函数。首先,该函数声明了一个形状为 image.shape + padding * 2 的零矩阵。我们将 padding 乘以 2,因为我们在所有方面都需要它。然后该函数索引矩阵,以便忽略填充并使用实际图像值更改零:
def add_padding_to_image(img: np.array, padding_width: int) -> np.array:
# Array of zeros of shape (img + padding_width)
img_with_padding = np.zeros(shape=(
img.shape[0] + padding_width * 2, # Multiply with two because we need padding on all sides
img.shape[1] + padding_width * 2
))
# Change the inner elements
# For example, if img.shape = (224, 224), and img_with_padding.shape = (226, 226)
# keep the pixel wide padding on all sides, but change the other values to be the same as img
img_with_padding[padding_width:-padding_width, padding_width:-padding_width] = img
return img_with_padding让我们通过为图像添加 3×3 过滤器的填充来测试它:
img_with_padding_3x3 = add_padding_to_image(
img=np.array(img),
padding_width=pad_3x3
)
print(img_with_padding_3x3.shape)
plot_image(img_with_padding_3x3)
如果放大得足够近,您可以看到黑色边框。如果您想知道,此图像的形状为 226×226 像素。以下是显示为矩阵时的样子:
img_with_padding_3x3
您可以看到被零包围的原始图像,这正是我们想要的。让我们看看是否同样适用于 5×5 内核:
img_with_padding_5x5 = add_padding_to_image(
img=np.array(img),
padding_width=pad_5x5
)
print(img_with_padding_5x5.shape)
plot_image(img_with_padding_5x5)
现在您肯定可以看到这张 228×228 图像上的黑色边框。让我们看看它打印为矩阵时的样子:
img_with_padding_5x5
它看起来应该是这样的——所有边都有两个像素填充。让我们对我们的单像素填充图像应用锐化滤镜,看看是否有任何问题:
img_padded_3x3_sharpened = convolve(img=img_with_padding_3x3, kernel=sharpen)
print(img_padded_3x3_sharpened.shape)
plot_two_images(
img1=img,
img2=img_padded_3x3_sharpened
)
工作没有任何问题。卷积后的图像具有 224×224 像素的形状,这正是我们想要的。
简而言之,这就是卷积和填充。今天我们介绍了很多,所以接下来让我们做一个简短的回顾。
Conclusion
卷积比听起来容易。整个事情归结为在整个图像上滑动过滤器。如果你放弃所有的矩阵术语,它会简化为小学数学——乘法和加法。没有什么特别的事情发生。
我们可以通过引入跨步使事情进一步复杂化——但这些对卷积和池化都是通用的。我将把它们留到下一篇文章中,其中涉及池化——一种通常遵循卷积层的缩小操作。
请继续关注那个。我将在下周的前半部分发布它。
喜欢这篇文章吗?成为 Medium 会员,继续无限制地学习。如果您使用以下链接,我将收到您的一部分会员费,您无需支付额外费用。[0]
Stay connected
文章出处登录后可见!