原文标题 :Object Detection Algorithm — YOLO v5 Architecture
目标检测算法——YOLO v5 架构
YOLO v5的历史和架构
基于 CNN 的目标检测器主要适用于推荐系统。 YOLO(You Only Look Once)模型用于高性能的对象检测。 YOLO 将图像划分为一个网格系统,每个网格检测自身内部的物体。它们可用于基于数据流的实时对象检测。它们需要很少的计算资源。
History of YOLO
- Yolov1(2015 年 6 月 8 日):你只看一次:统一的实时对象检测[0]
- Yolov2(2016 年 12 月 25 日):YOLO9000:更好、更快、更强[0]
- Yolov3(2018 年 4 月 8 日):YOLOv3:增量改进[0]
- Yolov4(2020 年 4 月 23 日):YOLOv4:目标检测的最佳速度和准确性[0]
- Yolov5(2020 年 5 月 18 日):Github repo(截至 2021 年 8 月 1 日没有论文)[0]
注意:根据此处的评论,截至 2021 年 8 月 1 日,没有关于 YOLOv5 的论文。因此,这篇文章将详细介绍 YOLOv4,以便于理解 YOLOv5。[0]
要了解 Yolov5 如何提高性能及其架构,让我们看一下以下高级对象检测架构:
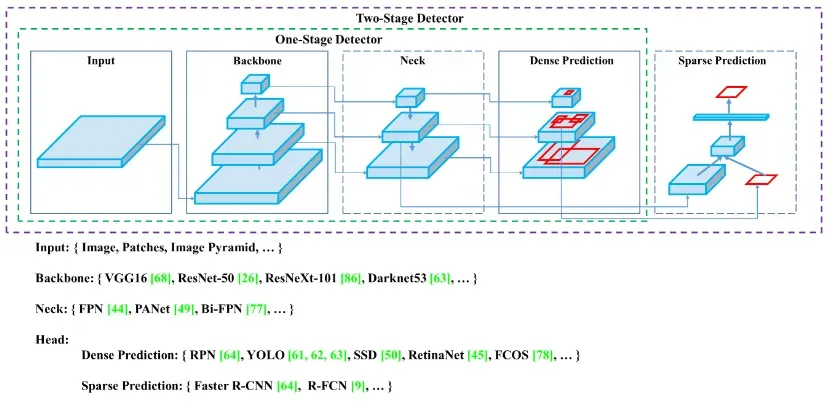
通用对象检测器将有一个用于预训练它的主干和一个用于预测类和边界框的头。 Backbones 可以在 GPU 或 CPU 平台上运行。 Head 可以是用于密集预测的单阶段(例如,YOLO、SSD、RetinaNet)或用于稀疏预测对象检测器的两阶段(例如,Faster R-CNN)。最近的物体检测器有一些层(Neck)来收集特征图,它位于主干和头部之间。
在 YOLOv4 中,CSPDarknet53 作为骨干网和 SPP 块用于增加感受野,将显着特征分离,并没有降低网络运行速度。 PAN 用于来自不同主干级别的参数聚合。 YOLOv3(基于锚的)头用于 YOLOv4。[0][1][2][3]
注意:请通过上述链接了解有关 CSPDarknet53、SPP、PAN 和 YOLOv3 的更多详细信息。
YOLOv4 引入了数据增强马赛克和自我对抗训练(SAT)的新方法。 Mosaic 混合了四个训练图像。自我对抗训练分为前向和后向两个阶段。在第一阶段,网络改变唯一的图像而不是权重。在第二阶段,训练网络以检测修改后图像上的对象。[0][1]


除了上述模块之外,一些现有的方法(空间注意模块[SAM]、PAN、CBN)已经过修改以提高性能。[0][1][2]
Yolov5 与 Yolov4 几乎相似,但有以下一些区别:
- Yolov4 是在 Darknet 框架中发布的,它是用 C 编写的。Yolov5 基于 PyTorch 框架。
- Yolov4 使用 .cfg 进行配置,而 Yolov5 使用 .yaml 文件进行配置。
Netron 中展示的 YOLOv5s 模型[0]

YOLOv5s 模型在 TensorBoard 中展示[0]
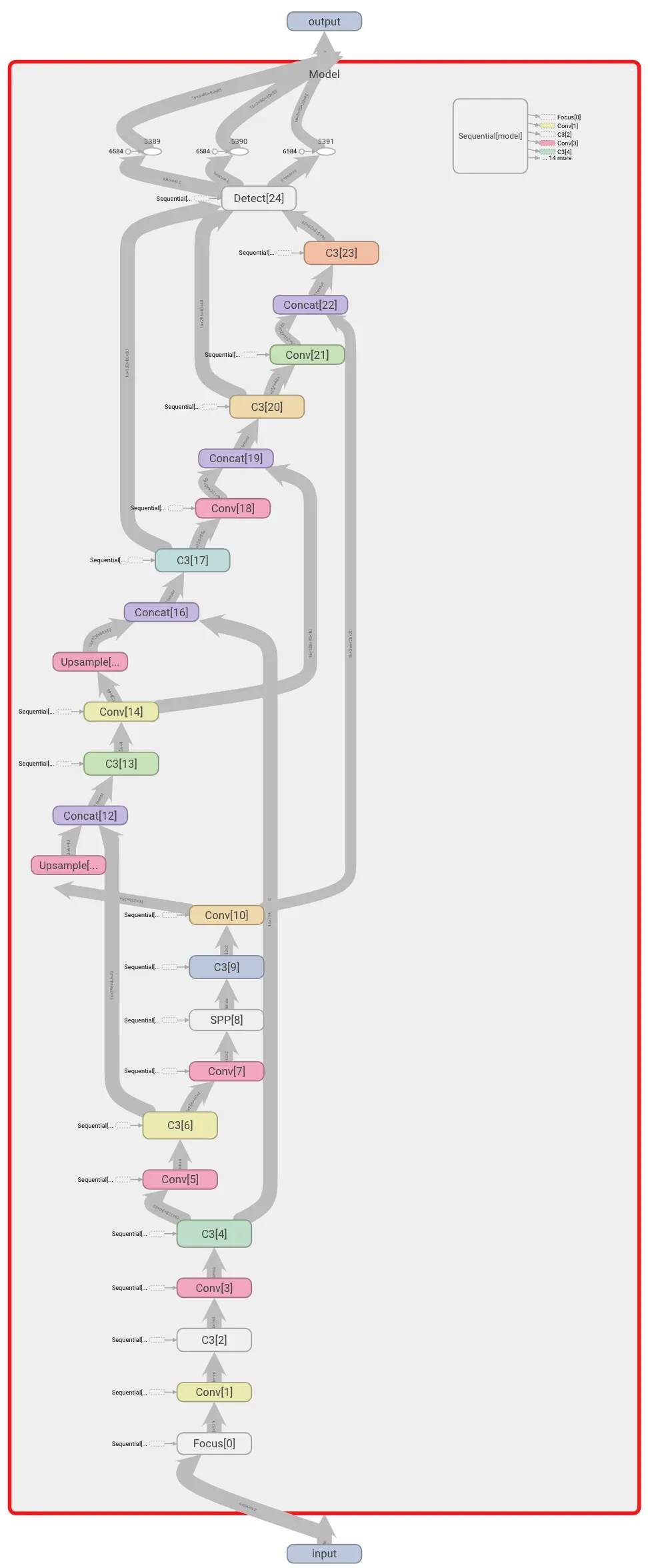
请通过 Yolov5 Github repo 获取更多信息。[0]
感谢您的阅读!如果您喜欢这篇文章,请👏并关注我,因为它鼓励我写更多!
文章出处登录后可见!