原文标题 :Techniques for handling underfitting and overfitting in Machine Learning
机器学习中处理欠拟合和过拟合的技术

在本文中,我将讨论可用于处理过拟合和欠拟合的各种技术。我将简要讨论欠拟合和过拟合,然后讨论处理它们的技术。
Introduction
在我之前的一篇文章中,我谈到了偏差-方差权衡。我们讨论了与模型复杂度的偏差-方差关系以及欠拟合和过拟合的样子。如果您不理解这些术语,我鼓励您阅读这篇文章:
为了快速回顾一下,让我们看一下下图。
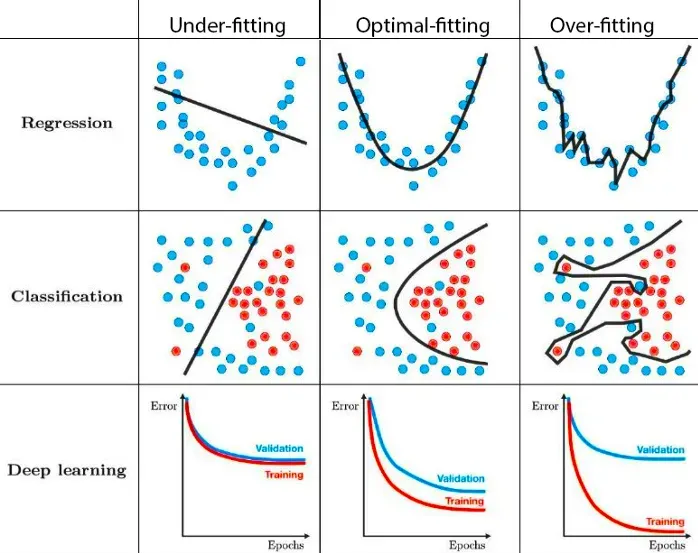
当模型具有非常高的偏差并且无法捕获数据中的复杂模式时,就会发生欠拟合。这会导致更高的训练和验证错误,因为模型不够复杂,无法对基础数据进行分类。在上面的示例中,我们看到数据具有二阶关系,但模型是线性模型,因此无法
过度拟合是相反的,因为模型太复杂(或更高的模型),甚至捕获数据中的噪声。因此,在这种情况下,人们会观察到一个非常低的测试误差值。但是,当它无法泛化到验证集和测试集时。
我们希望找到模型在训练和验证误差值之间的差距较小的最佳拟合情况。它应该比其他两种情况更好地概括。
如何处理欠拟合
- 在这种情况下,最好的策略是通过增加深度学习模型的参数数量或模型的顺序来增加模型的复杂性。欠拟合是由于模型比需要的简单。它无法捕获数据中的模式。增加模型的复杂性将导致训练性能的提高。如果我们使用足够大的模型,它甚至可以实现零训练误差,即模型将记住数据并遭受过拟合。目标是达到最佳甜蜜点。
- 尝试对模型进行更多时期的训练。确保损失在训练过程中逐渐减少。否则,训练代码/逻辑本身很可能存在某种错误或问题。
- 如果您没有在每个 epoch 之后对数据进行洗牌,则可能会损害模型性能。确保您正在改组数据是此时执行的一项很好的检查。
如何处理过拟合
与欠拟合相比,有几种技术可用于处理可以尝试使用的过拟合。让我们一一看看。
1. 获得更多的训练数据:虽然获得更多的数据可能并不总是可行的,但获得更具代表性的数据是非常有帮助的。拥有更大的多样化数据集通常有助于模型性能。您可以获得更好的模型,可以更好地概括。这意味着模型在看不见的数据(真实测试集)上的表现会更好。
2. 增强:如果您无法获得更多数据,您可以尝试增强以在数据中添加变化。增强意味着通过类似于您在真实数据中可能期望的变化的转换来人为地修改现有数据。对于图像数据,https://imgaug.readthedocs.io/en/latest/ 是一个非常全面的库,它为您提供了大量的增强方法。它允许您快速有效地组成强大的增强序列。我会推荐以下两篇文章以供进一步阅读。 Olga Chernytska 有一篇关于图像增强的详细文章,您应该考虑阅读。 Valentina Alto 在本文中很好地解释了如何在 Keras 中完成图像增强。[0][1][2][3][4]
3. 早停[2,3]:早停是一种正则化形式,用于在使用迭代方法(例如梯度下降[2])训练学习器时避免过度拟合。在训练神经网络时,我们迭代地使用训练数据中的梯度,并尝试使模型更好地拟合底层的真实世界函数。从某种意义上说,这种方法可以让你在最佳拟合点处或附近停下来。从而防止过度拟合训练集并减少泛化错误。为了决定何时停止,我们可以监控某些指标,例如损失、test_accuracy、val_accuracy,并根据满足的某些条件停止训练。
4.正则化L1,L2:正则化是附加在损失函数中的一项,用于对大的网络参数权重施加惩罚,以减少过拟合。 L1 和 L2 正则化是两种广泛使用的技术。尽管它们惩罚大权重,但它们都以不同的方式实现正则化。
L1 正则化:L1 正则化将权重参数的 L1 范数的缩放版本添加到损失函数中。 L1 正则化的方程是:
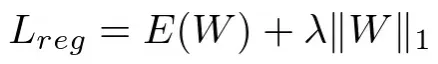
其中 Lreg = 正则化损失,E(W) = 误差项,λ 是超参数,||W||₁ 是权重的 L1 范数
现在,即使误差项为零,只要权重不为零,我们仍然会有 +ve 高的 Lreg 值。并且由于优化问题的目标是最小化 Lreg,将权重设置为零将导致更低的损失。权重中的更多零意味着更多的稀疏性。有可用的几何解释表明稀疏解决方案更多。您可以观看/阅读以下视频/文章:
- https://www.youtube.com/watch?v=76B5cMEZA4Y[0]
- 稀疏性和 L1 规范 https://towardsdatascience.com/regularization-in-machine-learning-connecting-the-dots-c6e030bfaddd[0][1]
- https://developers.google.com/machine-learning/crash-course/regularization-for-sparsity/l1-regularization[0]
- 稀疏正则化:L₁ 正则化 https://www.inf.ed.ac.uk/teaching/courses/mlpr/2016/notes/w10a_sparsity_and_L1.pdf[0][1]
L2 正则化:我们将权重的平方 L2 范数添加到成本/损失/目标函数中。 L2正则化方程如下:
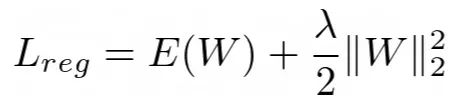
其中 Lreg = 正则化损失,E(W) = 误差项,λ 是称为正则化率的超参数,||W||₂ 是权重的 L2 范数
该方程的导数导致优化期间权重更新方程中的以下项:
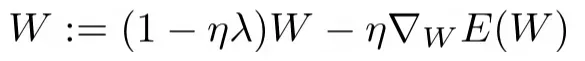
其中 η 是学习率
我们看到旧的权重按 (1-ηλ) 缩放或随着每次梯度更新而衰减。因此,L2 正则化会导致更小的权重。因此,它有时也被称为重量衰减。有关详细说明,我强烈建议您阅读 google 机器学习速成课程中的这篇文章:Regularization for Simplicity: L₂ Regularization[0]
Dropout [4]:该技术的主要思想是在训练期间从神经网络中随机丢弃单元。它在以下论文中进行了介绍:Srivastava 等人的 Dropout: A Simple Way to prevent Neural Networks from Overfitting (2014)。在训练过程中,随机 dropout 样本形成了大量不同的“细化”网络。辍学是通过从概率为 p 的伯努利分布中绘制的矩阵来实现的(为了得到 1)[即dropout 概率为 1-p],然后与隐藏层的输出进行元素乘法。下图显示了训练阶段的 dropout。[0]
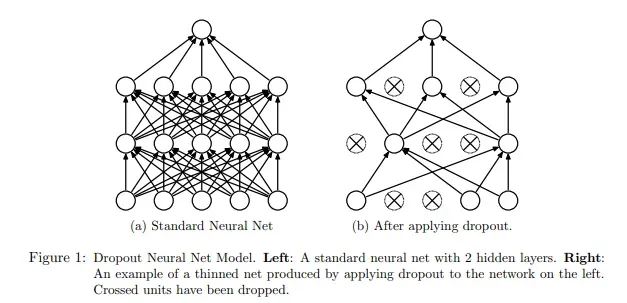
Dropout 确保没有神经元最终过度依赖其他神经元,而是学习一些有意义的东西。可以在卷积、池化或全连接层之后应用 Dropout。
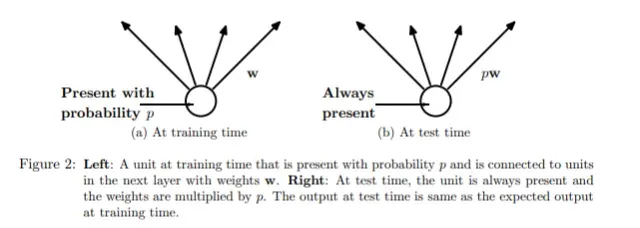
要记住的另一件事是,由于在训练期间并非所有神经元都一直处于活动状态,但概率为 p,因此在推理期间需要使用该值缩放权重。您可以在论文中或从这篇文章中阅读有关缩放要求的更多信息:CS231n Convolutional Neural Networks for Visual Recognition[0]
DropConnect:这种技术就像将 dropout 提升到一个新的水平。我们不是随机丢弃节点,而是随机丢弃权重。因此,我们不是关闭节点的所有连接,而是切断某些随机连接。这意味着具有 DropConnect 的全连接层变成了稀疏连接层,其中在训练阶段随机选择连接 [5]。对于 DropConnect 层,输出如下:
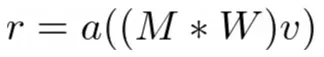
其中 r 是层的输出,v 是层的输入,W 是权重参数,M 是用于截断从概率为 p 的伯努利分布中抽取的随机连接的掩码矩阵。在训练期间为每个示例独立绘制掩码 M 的每个元素。由于这些随机连接下降,我们的网络权重得到动态稀疏性,从而导致过度拟合的减少。
References
[1] Pinterest Image[0]
[2] Early stopping[0]
[3] https://machinelearningmastery.com/early-stopping-to-avoid-overtraining-neural-network-models/[0]
[4] Nitish Srivastava、Geoffrey Hinton、Alex Krizhevsky、Ilya Sutskever 和 Ruslan Salakhutdinov。 2014. Dropout:一种防止神经网络过度拟合的简单方法。 J.马赫。学习。水库。 15, 1(2014 年 1 月),1929–1958。
[5] 带代码的论文——DropConnect 解释[0]
文章出处登录后可见!