1 获取onnx模型
我是使用pytorch训练得到的pth模型,转成onnx模型,这一步之前写过博客,可参考:pytorch分类模型导出onnx模型并验证 [0]
[0]
2 启动docker容器
如果之前在开发机上已经安装过地平线给的docker开发环境,可直接执行指令:
docker start horizon # 启动horizon,horizon是我的容器container 别名
docker attach horizon # 进入horizon
如果你之前没安装过,也没学过docker的相关知识,可参考我的另一篇博客:配置地平线提供的docker开发环境。[0]
3 onnx模型检查
3.1 为什么要检查?
官方回答:验证模型中使用的算子需要符合Horizon平台的算子约束。
翻译回答: onnx模型中,不是所有的函数“我”都支持,你得用“我”支持的。怎么知道“我”是否支持呢?给你个excel表让你查太费事,写个函数让程序查吧,这样快!
3.2 如何操作
把在第一步得到的resnet34.onnx模型,放到开发机的指定位置:
/data/wyx/horizon/horizon_xj3_open_explorer_v1.8.5_20211224/ddk/samples/ai_toolchain/horizon_model_convert_sample/03_classification/05_efficientnet_lite0_onnx/resnet_x3/output/
没有文件夹,新建一个即可,如下图:
为什么要这样说?往下看你就明白了。
然后在resnet_x3文件夹下,新建一个01_check.sh文件,内容如下:
#!/usr/bin/env sh
set -e -v
cd $(dirname $0) || exit
# 模型类型,本文以onnx为例
model_type="onnx"
# 要检查的onnx模型位置
onnx_model="./output/resnet34.onnx"
# 检查输出日志,放到哪里去
# 虽然它还是放到了与01_check.sh同级目录下(感觉像小bug)
output="./model_output/resnet34_checker.log"
# 用的什么架构,不用改
march="bernoulli2"
hb_mapper checker --model-type ${model_type} \
--model ${onnx_model} \
--output ${output} --march ${march}
解释一下:hb_mapper checker就是地平线专属命令了,俗称“工具”。
cd到resnet_x3文件夹下,执行命令:
sh 01_check.sh
输出比较重要的部分如下,第二列是BPU,说明算子运行在BPU上,同理,也可能运行在CPU上。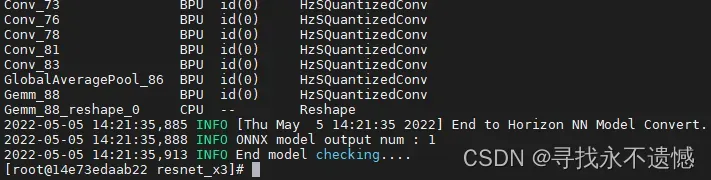
多数算子bpu都支持,包括卷积conv、池化pool、全连接fc等操作。
对于不支持的算子,算了,我们就先让它在CPU上跑。
4 图像数据预处理
本来以为模型检查完,一行命令加载onnx模型,一行命令输出能在地平线开发板上运行的模型。
总的来说,是的,但是,哦,天真。
4.1 一些问题的思考
- 问题1: 模型转换是什么?
回答: 模型转换,是指模型经过量化(例如,网络参数从float32转换成int8)、算子重组、结构优化等一系列操作,得到新的模型,这个新的模型体积更小,推理速度更快。 - 问题2: 为什么要进行模型转换?
答:如果要在各种开发板上运行服务端训练得到的模型,就得适应各个开发板的架构。学习底层太费力了。因此,使用了一套工具链来帮助您快速将服务器端模型转换为在开发板上运行的功能A模型。 - 问题3: 为什么要进行图像数据预处理?
答:Horizon 的量化方案是“数据依赖”的,即在对模型进行量化时,需要有典型的图像输入作为支持。 - 问题4: 什么样的图片能称为典型呢?
回答: 比如分类数据集,每一类都挑到,随机挑就好。一共挑50~100张即可。
4.2 图片挑选与放置
从5个类别中,每个类别随机挑了20张图片,放在resnet_x3/data/image_origin/文件夹下,同时新建一个文件夹image_converted_rgb_f32,用于存放处理后的图像,如图所示:
下面就是对挑选的图片进行处理了。这里我提供两种方法,一种是根据地平线提供的模板进行图像预处理,但它跳来跳去的,而且包括的内容太多,我自己又写了一个flower_data_preprocess.py,实现同样的功能,下面分别介绍。
4.2 使用地平线提供的模板进行图像预处理
如下图所示,在resnet_x3文件夹下需要有这三个文件,下面分别介绍其作用及内容:
- 02_preprocess.sh
内容如下:
#!/usr/bin/env bash
set -e -v
cd $(dirname $0) || exit
python3 ../../../data_preprocess.py \
# 原图片路径
--src_dir ./data/image_origin \
# 处理后图片存哪
--dst_dir ./data/image_converted_rgb_f32 \
# 处理后图片后缀名
--pic_ext .rgb \
# 读取图片的方式,有opencv和skimage两种
--read_mode opencv
很明显告诉我们运行那个文件,往里传哪些参数,至于data_preprocess.py里面的内容就不再介绍了,不然跳来跳去,讲不完了。反正data_preprocess.py是地平线给的,用就完事了。
- preprocess.py
data_preprocess.py中会用到preprocess.py文件中的一个函数,如下图所示。至于里面的内容,就不展开了,不然又得跳了。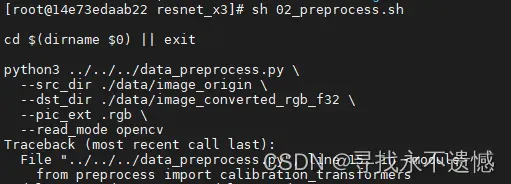
- data文件夹
选中的图片放在里面,处理好的图片也会放在这里。
在resnet_x3文件夹下,执行命令:
sh 02_preprocess.sh
运行界面及结果如下图所示: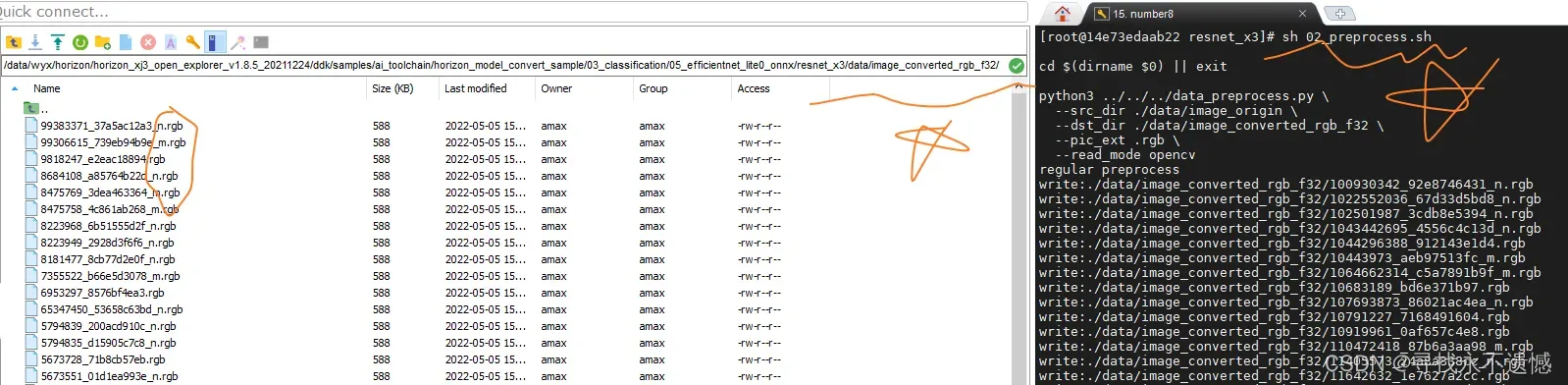
4.3 使用自己写的图像预处理函数
自己写的图像预处理函数放在flower_data_preprocess.py文件中,文件放在resnet_x3文件夹下,实现效果与4.2节一致,其内容如下:
关注的归一化操作,如何处理预训练权重的均值和方差,详见代码注释。
import cv2
import os
import numpy as np
## ------------------------------------------------------------#
# src_dir:从数据集中每个类别各挑选15张图片放到一起
# dst_dir:处理后的图片存放的路径
# pic_ext:处理后的图片后缀名(影响不大,只是为了说明它的通道顺序)
## ------------------------------------------------------------#
src_dir = './data/image_origin'
dst_dir = './data/image_converted_rgb_f32'
pic_ext = '.rgb'
## ---------------------------------------#
# 一次只操作一张图片
## ---------------------------------------#
for src_name in sorted(os.listdir(src_dir)):
## -----------------------------#
# 把图片路径拼出来
## -----------------------------#
src_file = os.path.join(src_dir, src_name)
## -----------------------------#
## opencv实现预处理
## -----------------------------#
img = cv2.imread(src_file)
img = cv2.resize(np.array(img), (224, 224), interpolation=cv2.INTER_CUBIC).astype(np.float32)
## -----------------------------------------------------#
# PC端网络训练时,数据需要归一化,为何在这儿不做?
# 答:模型转换时,需要的图像输入分为是0~255,故不要归一化。
## -----------------------------------------------------#
# img /= 255.0
# ---------------------------------------#
# 常规操作是:先转成RGB,再减均值,除方差
# ---------------------------------------#
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
## -----------------------------------------------------------------------------------------#
# 问题1:PC端网络训练时,数据需要减均值,除方差,为何在这儿不做?
# 答:为了和yaml中data_mean_and_scale下的mean_value与scale_value参数配合
# 在yaml文件中设置即可
# 问题2:是否在这儿减均值,除方差,在yaml中data_mean_and_scale参数设置为no_preprocess即可?
# 答:按道理是的,但要注意,下方的减去均值,除以方差,是针对ImageNet归一化后的数据,
# 那没有归一化的数据,其均值方差和下面的数据大小又有着怎么的关系呢?欢迎查看下一小节
## -----------------------------------------------------------------------------------------#
# img -= [0.485, 0.456, 0.406]
# img /= [0.229, 0.224, 0.225]
## -----------------------------------------------------------------------------------------#
# 从HWC,变为CHW。用的是Pytorch框架,其输入是NCHW,故需要这一步。
# 对于更多NCHW还是NHWC问题,可参考https://blog.csdn.net/weixin_45377629/article/details/124040681
## -----------------------------------------------------------------------------------------#
img = img.transpose(2, 0, 1)
# ---------------------------------------#
# 添加batch维度
# 至此,图像预处理完毕
# ---------------------------------------#
img = np.expand_dims(img, 0)
# -----------------------------------------------------#
# os.path.basename:返回最后的 文件名,也就是src_image
# 例如:os.path.basename("./src/1.jpg"),返回:1.jpg
# -----------------------------------------------------#
filename = os.path.basename(src_file)
# print(src_file)
# -----------------------------------------------------#
# os.path.splitext: 把图片名和图片扩展名分开,
# 例如:1.jpg,short_name=1, ext=.jpg
# -----------------------------------------------------#
short_name, ext = os.path.splitext(filename)
# ---------------------------------------#
# 新的图片名
# ---------------------------------------#
pic_name = os.path.join(dst_dir, short_name + pic_ext)
dtype = np.float32
img.astype(dtype).tofile(pic_name)
print("write:%s" % pic_name)
运行效果如下图所示: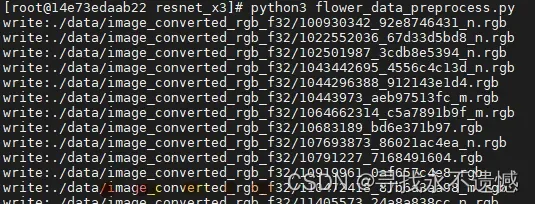
4.4 归一化前后 图像数据 均值与方差怎么变 ?
对于在服务器端使用Pytorch训练网络是,通常会归一化图像数据,然后减去均值,除以方差,再传入网络。
在训练网络模型时,我们大多会使用Imagenet数据集或者COCO数据集的预训练权重,用它们的均值和方差,例如:
if 'coco' in args.dataset:
mean_vals = [0.471, 0.448, 0.408]
std_vals = [0.234, 0.239, 0.242]
elif 'imagenet' in args.dataset:
mean_vals = [0.485, 0.456, 0.406]
std_vals = [0.229, 0.224, 0.225]
这些是归一化的均值和方差。归一化前后数据的均值和方差有什么关系?用一个例子来说明:
import numpy as np
a = np.array([4,8,12,16])
b = a / 255.0
mean_a = np.mean(a)
mean_b = np.mean(b)
std_a = np.std(a)
std_b = np.std(b)
print("mean_a", mean_a)
print("mean_b", mean_b)
print("std_a", std_a)
print("std_b", std_b)
运行输出:
PS D:\DeepLearning\classification> python .\1.py
mean_a 10.0
mean_b 0.0392156862745098
std_a 4.47213595499958
std_b 0.01753778805882188
可以发现mean_b = mean_a / 255,std_b = std_a / 255,也就是说对于归一化后的数据其均值与方差均是归一化前的数据的。
5 获取.bin模型
准备好处理后的图像数据,下面就是获取能够在开发板上运行的模型了,地平线在开发板上运行的模型后缀为.bin,故在此称为.bin模型。
这一步需要准备两个文件,一个是03_build.sh,一个是resnet34_config.yaml,两个文件均放于resnet_x3文件夹下。下面分别介绍这两个文件里的内容:
5.1 03_build.sh
加载resnet34_config.yaml文件,使用hb_mapper中的makertbin工具去操作即可。
#!/bin/bash
set -e -v
cd $(dirname $0)
config_file="./resnet34_config.yaml"
model_type="onnx"
# build model
hb_mapper makertbin --config ${config_file} \
--model-type ${model_type}
5.2 resnet34_config.yaml
重点关注网络输入的预处理方法:norm_type: ‘data_mean_and_scale’,需要了解的内容已在注释中给出。
# 模型转化相关的参数
model_parameters:
# ONNX浮点网络数据模型文件
onnx_model: './output/resnet34.onnx'
# 适用BPU架构
march: "bernoulli2"
# 指定模型转换过程中是否输出各层的中间结果,如果为True,则输出所有层的中间输出结果,
layer_out_dump: False
# 日志文件的输出控制参数,
# debug输出模型转换的详细信息
# info只输出关键信息
# warn输出警告和错误级别以上的信息
log_level: 'debug'
# 模型转换输出的结果的存放目录
working_dir: 'model_output'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'resnet34_224x224_rgb'
# 模型输入相关参数, 若输入多个节点, 则应使用';'进行分隔, 使用默认缺省设置则写None
input_parameters:
# (选填) 模型输入的节点名称, 此名称应与模型文件中的名称一致, 否则会报错, 不填则会使用模型文件中的节点名称
input_name: ""
# 网络实际执行时,输入给网络的数据格式,包括 nv12/rgb/bgr/yuv444/gray/featuremap,
# pytorch模型一般是rgb
input_type_rt: 'rgb'
# 网络实际执行时输入的数据排布, 可选值为 NHWC/NCHW
# 若input_type_rt配置为nv12,则此处参数不需要配置
# pytorch模型一般是NCHW
input_layout_rt: 'NCHW'
# 网络训练时输入的数据格式,可选的值为rgb/bgr/gray/featuremap/yuv444
# pytorch模型一般是rgb
input_type_train: 'rgb'
# 网络训练时输入的数据排布, 可选值为 NHWC/NCHW
# pytorch模型一般是rgb
input_layout_train: 'NCHW'
# (选填) 模型网络的输入大小, 以'x'分隔, 不填则会使用模型文件中的网络输入大小,否则会覆盖模型文件中输入大小
input_shape: ''
# 网络实际执行时,输入给网络的batch_size, 默认值为1
#input_batch: 1
# 网络输入的预处理方法,主要有以下几种:
# no_preprocess 不做任何操作
# data_mean 减去通道均值mean_value
# data_scale 对图像像素乘以data_scale系数
# data_mean_and_scale 减去通道均值后再乘以scale系数
# 注意:此处不是减去均值,除以方差!
norm_type: 'data_mean_and_scale'
# 图像减去的均值, 如果是通道均值,value之间必须用空格分隔
# 注意:此处的均值是没有归一化的均值,例如ImageNet的R通道,应该是: 124.16 = 0.485x255
mean_value: 124.16 116.28 103.53
# 图像预处理缩放比例,如果是通道缩放比例,value之间必须用空格分隔
# 注意:此处的scale是乘以,以前的方差是除以。且是没有归一化数据
# 例如ImageNet的R通道,应该是: 0.0171248 = 1 / (0.229x255)
scale_value: 0.0171248 0.0175070 0.0174292
# 模型量化相关参数
calibration_parameters:
# 模型量化的参考图像的存放目录,图片格式支持Jpeg、Bmp等格式,输入的图片
# 应该是使用的典型场景,一般是从测试集中选择20~100张图片,另外输入
# 的图片要覆盖典型场景,不要是偏僻场景,如过曝光、饱和、模糊、纯黑、纯白等图片
# 若有多个输入节点, 则应使用';'进行分隔
# 预处理后的图片所在路径
cal_data_dir: './data/image_converted_rgb_f32'
# 如果输入的图片文件尺寸和模型训练的尺寸不一致时,并且preprocess_on为true,
# 则将采用默认预处理方法(skimage resize),
# 将输入图片缩放或者裁减到指定尺寸,否则,需要用户提前把图片处理为训练时的尺寸
# preprocess_on: False
# 模型量化的算法类型,支持kl、max、default、load,通常采用default即可满足要求, 若为QAT导出的模型, 则应选择load
calibration_type: 'default'
# 编译器相关参数
compiler_parameters:
# 编译策略,支持bandwidth和latency两种优化模式;
# bandwidth以优化ddr的访问带宽为目标;
# latency以优化推理时间为目标
compile_mode: 'latency'
# 设置debug为True将打开编译器的debug模式,能够输出性能仿真的相关信息,如帧率、DDR带宽占用等
debug: False
# 编译模型指定核数,不指定默认编译单核模型, 若编译双核模型,将下边注释打开即可
# core_num: 2
# 优化等级可选范围为O0~O3
# O0不做任何优化, 编译速度最快,优化程度最低,
# O1-O3随着优化等级提高,预期编译后的模型的执行速度会更快,但是所需编译时间也会变长。
# 推荐用O2做最快验证
optimize_level: 'O3'
运行以下命令:
sh 03_build.sh
重点关注第5列的预先相似度Cosine Similarity,都在0.9以上,说明转换的还不错。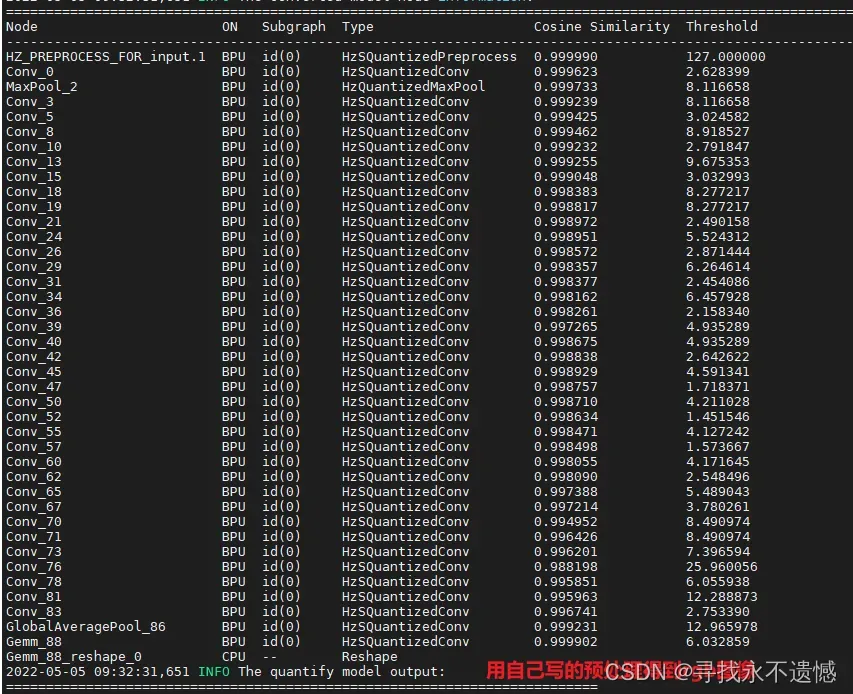
- 日志文件-hb_mapper_makertbin.log
- 量化前原始onnx模型-resnet34_224x224_rgb_original_float_model.onnx
- 量化中间产物:resnet34_224x224_rgb_optimized_float_model.onnx
- 量化后onnx模型-resnet34_224x224_rgb_quantized_model.onnx
- 板端模型-resnet34_224x224_rgb.bin。
6 在开发机上验证转换过程中生成的两个onnx模型
predict_docker_x3_onnx.py用在03_build.sh构建得到.bin模型之后,用于验证过程产物——两个onnx模型,存放在resnet_34/文件夹下。
处理思路很简单:数据预处理——加载模型——模型推理——模型输出后处理,内容如下:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
import json
import cv2
from horizon_tc_ui import HB_ONNXRuntime
def softmax_2D(X):
"""
针对二维numpy矩阵每一行进行softmax操作
X: np.array. Probably should be floats.
return: 二维矩阵
"""
# looping through rows of X
# 循环遍历X的行
ps = np.empty(X.shape)
for i in range(X.shape[0]):
ps[i,:] = np.exp(X[i,:])
ps[i,:] /= np.sum(ps[i,:])
return ps
def check_onnx(onnx_model, img, json_path, input_shape):
## --------------------------------------------#
## opencv实现预处理方式
## --------------------------------------------#
img = cv2.resize(np.array(img), input_shape, interpolation=cv2.INTER_CUBIC).astype(np.float32)
## --------------------------------------------#
# 使用编译过程中生成的onnx模型是不需要归一化的
# 模型需要的数值范围0~255,ncv读取的刚好是0~255
## --------------------------------------------#
# img /= 255.0
## --------------------------------------------#
# 网络训练输入一般是RGB的图片,故在此也转一下
# 为了省时间,似乎这儿可以和yaml中参数配合,去掉这一步
## --------------------------------------------#
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
## ------------------------------------------------------------------#
# 常规操作是:减去均值,除以方差
# 为了和yaml中data_mean_and_scale下的mean_value与scale_value参数配合
# 注意:此处是针对0~255的通道顺序RGB的图像进行减去均值,乘以方差倒数
## ------------------------------------------------------------------#
img -= [124.16, 116.28, 103.53]
img *= [0.0171248, 0.0175070, 0.0174292]
## --------------------------------------------#
# opencv读取的img是HWC格式
# quantized_onnx_model输入格式NHWC
# optimized_float_onnx_model输入格式NCHW
## --------------------------------------------#
if "optimized" in onnx_model:
img = img.transpose(2, 0, 1) # 从HWC,变为CHW
## -------------------------------#
## 添加batch维度
## -------------------------------#
img = np.expand_dims(img, 0)
# --------------------------------#
# class_indict用于可视化类别
# --------------------------------#
with open(json_path, "r") as f:
class_indict = json.load(f)
## -------------------------------#
## 加载onnx模型
## -------------------------------#
ort_session = HB_ONNXRuntime(model_file=onnx_model)
## 下面这两行有啥用?我注释掉也没什么影响
#ort_session_2.set_dim_param(0, 0, '?')
#ort_session_2.set_providers(['CPUExecutionProvider'])
# -----------------------------------#
# onnx模型推理
# 初始化数据,注意此时 img 是numpy格式
# -----------------------------------#
input_name = ort_session.input_names[0]
ort_outs = ort_session.run(None, {input_name: img}) # 推理得到输出
# print(ort_outs) # [array([[-4.290639 , -2.267056 , 7.666328 , -1.4162455 , 0.57391334]], dtype=float32)]
# -----------------------------------#
# 经过softmax转化为概率
# softmax_2D按行转化,一行一个样本
# 测试时,softmax可不要!
# -----------------------------------#
predict_probability = softmax_2D(ort_outs[0])
# print(predict_probability) # array([[0.1],[0.2],[0.3],[0.3],[0.1]])
# ----------------------------------------#
# argmax得到最大概率索引,也就是类别对应索引
# ----------------------------------------#
predict_cla = np.argmax(predict_probability, axis=-1)
# print(predict_cla) # array([2])
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla[0])],
predict_probability[0][predict_cla[0]])
print(print_res)
plt.title(print_res)
for i in range(len(predict_probability[0])):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
predict_probability[0][i]))
plt.savefig("./result.jpg")
plt.show()
if __name__ == '__main__':
## ----------------------------------------------------------------#
# 注意,quantized_onnx_model的输入格式为:NHWC
# optimized_float_onnx_model的输入格式为:NCHW
# 这儿的命名一定要以quantized和optimized进行区分,后面的代码中有用到
## ----------------------------------------------------------------#
quantized_onnx_model = './model_output/resnet34_224x224_rgb_quantized_model.onnx'
optimized_float_onnx_model = './model_output/resnet34_224x224_rgb_optimized_float_model.onnx'
# ----------------------------------------#
# 输入图像被resize到什么尺寸
# 分类网络输入尺寸
# ----------------------------------------#
input_shape = (224, 224)
img_path = "./data/tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
# 下面两行,用它显示图片而已
img = Image.open(img_path)
plt.imshow(img)
img = cv2.imread(img_path)
# read class_indict
json_path = './class_indices.json'
# -----------------------------------------------------------------------#
# 关键部分
# 第一个参数用于切换:quantized_onnx_model 或 optimized_float_onnx_model
# -----------------------------------------------------------------------#
check_onnx(quantized_onnx_model, img, json_path, input_shape)
print("onnx model check finsh.")
运行结果:
- 对于rose.jpg的分类预测结果。
使用optimized_float_onnx_model模型推理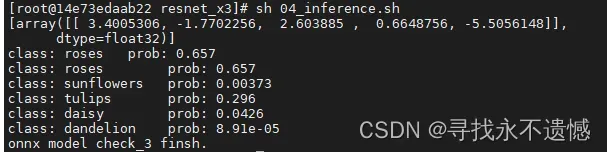
- 对于tulip.jpg的分类预测结果
使用optimized_float_onnx_model模型推理: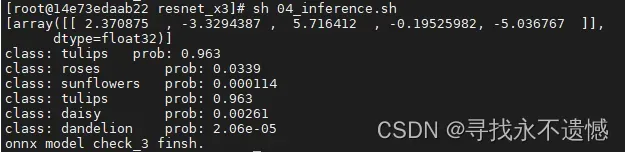
使用quantized_onnx_model模型推理: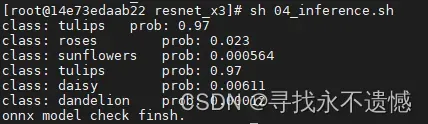
图片结果显示:
7 使用hb_perf工具估计在开发板上运行的性能
拿到了.bin文件,在上开发板运行前,预估一下能运行多少FPS等。
cd到与resnet34_224x224_rgb.bin同级,运行命令:
hb_perf resnet34_224x224_rgb.bin
生成hb_perf_result文件夹和hb_perf.log,打开输出的文件自己看两眼就明白了。
8 接下来工作
将转换得到的.bin模型在x3开发板上跑起来。
文章出处登录后可见!