机器学习深度学习面试题——Python基础知识
hint:
python 深拷贝与浅拷贝
python多线程能用多个cpu么?
python垃圾回收机制
python里的生成器是什么
迭代器和生成器的区别
decorator
python有哪些数据类型
Python 中列表( List )中的 del,remove,和 pop 等的用法和区别
python yeild 和return的区别
python set底层实现
python字典和set()的区别
如何对字典的值进行排序?
init和new和call的区别
import常用库
python的lamda函数
Python内存管理
python在内存上做了哪些优化?
Python中类方法和静态方法的区别
python多线程怎么实现
点积和矩阵乘法的区别?
Python中错误和异常处理
Python 的传参是传值还是传址?
什么是猴子补丁?
当退出 Python 时是否释放所有内存分配?
Python 中的 is 和 == 有什么区别?
gbk和utf8的区别
如何遍历字典
反转列表的方法
python 元组中元组转为字典
range在python2和python3里的区别
init.py 文件的作用以及意义
python 深拷贝与浅拷贝
**浅拷贝(copy):**拷贝父对象,不会拷贝对象的内部的子对象。共用内部的子对象。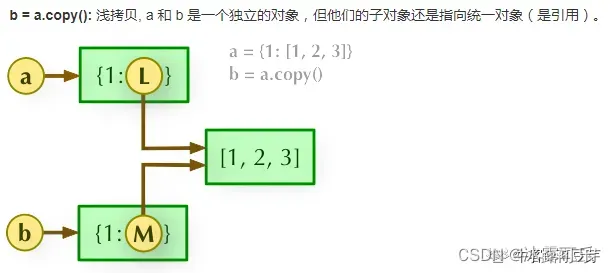
深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。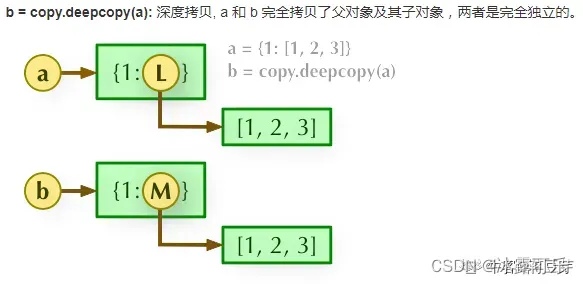
python多线程能用多个cpu么?
回答:不! ! !
python的多线程不能利用多核CPU
原因是python的解释器使用了GIL(Global Interpreter Lock),在任意时刻中只允许单个python线程运行。无论系统有多少个CPU核心,python程序都只能在一个CPU上运行。
GIL 中文译为全局解释器锁,其本质上类似操作系统的 Mutex。
GIL 的功能是:在 CPython 解释器中执行的每一个 Python 线程,都会先锁住自己,以阻止别的线程执行。
python垃圾回收机制
Python的垃圾回收机制是以:引用计数器为主【自动】,标记清除和分代回收为辅【手动】。
(1)主要的回收垃圾方式1:引用计数:每个对象内部都维护了一个值,该值记录这此对象被引用的次数,如果次数为0,则Python垃圾回收机制会自动清除此对象。
(2)辅助方式2:标记-清除(Mark—Sweep):被分配对象的计数值与被释放对象的计数值之间的差异累计超过某个阈值,则Python的收集机制就启动
(3)辅助方式3:当代码中主动执行 gc.collect() 命令时,Python解释器就会进行垃圾回收。
python里的生成器是什么
生成器是一种简单有效地创建迭代器的工具。
它们像常规函数一样撰写,但是在需要返回数据时使用yield语句。
每当对它调用next()函数,
发电机从它停止的地方重新启动
(它会记住所有数据值和最后执行的语句)。
迭代器和生成器的区别
迭代器有两个方法next方法和iter方法,
iter方法获取对象的迭代器,
next方法返回下一个迭代器。
生成器:使用了 yield 的函数被称为生成器(generator),在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值,
并在下一次执行 next() 方法时从当前位置继续运行。
调用生成器函数会返回一个迭代器对象。
区别
**语法上:**生成器是通过函数的形式中调用 yield 或()的形式创建的;
迭代器可以通过 iter() 内置函数创建
**用法上:**生成器在调用next()函数或for循环中,所有过程被执行,且返回值;
迭代器在调用next()函数或for循环中,所有值被返回,没有其他过程或说动作。
decorator
装饰器可以实现为具有附加功能,而无需更改函数或类的内部代码和调用。
应用场景:插入日志、性能测试、事务处理、缓存、权限验证
python有哪些数据类型
数字num,字符串string,列表list,元组tuple,字典dict,集合set
所有语言都类似,java也是
Python 中列表( List )中的 del,remove,和 pop 等的用法和区别
(1)pop
value = List.pop(index)
1、pop按照索引位置删除元素;2、无参数时默认删除最后一个元素;3、返回删除的元素值
(2)remove
1、remove 按照值删除,删除单个元素;2、删除首个符合条件的元素;3、返回值为空 None
(3)del
根据索引位置删除单个值或指定范围的值。
del是删除**引用(变量)**而不是删除对象(数据),对象由自动垃圾回收机制(GC)删除
python yeild 和return的区别
(1)共同点:return和yield都用来返回值;
在一次性地返回所有值场景中return和yield的作用是一样的。
(2)**不同点:**如果要返回的数据是通过for等循环生成的迭代器类型数据(如列表、元组),return只能在循环外部一次性地返回,yeild则可以在循环内部逐个元素返回。
牛! ! !
python set底层实现
散列表。
与dict不一样,dict是字典,键值对,有key和value
set没有value,只有key【java中是这样的】
python字典和set()的区别
(1)字典是一系列无序的键值对的组合;集合里的元素不是键值对,是单一的一个元素key。
(2)从python3.6后,字典有序;集合无序
java找中的hashSet是有序的,不重复的。
(3)字典键不能重复;集合元素不能重复 ——都不能重复
如何对字典的值进行排序?
方法一:转化为元组,(91,“张三”)的形式 ,用sorted()函数进行排序
方法二 :设置sorted() 中key的参数的值
#-*-coding:UTF-8-*-
#先生成一个随机字典
from random import randint
d= {x:randint(60,101) for x in "abcdxyz"}
print(d)
#方法一:元组形式
#把值放前面是因为sorted()排序默认按从头比较
z = zip(d.values(),d.keys())
#x = zip(d.itervalues(),d.iterkeys()) 迭代类型,省空间
#排序
s = sorted(z)
print(s)
#方法二:sorted(key的设置)
a = d.items()
s = sorted(a,key= lambda x:x[1])
print(s)
init和new和call的区别
__init__和
__new__和
__call__的区别
(1)__init__是初始化方法,
(2)new实例化对象
(3)call:允许一个类的实例像函数一样被调用。
实质上说,这意味着 x() 与 x.call() 是相同的
import常用库
time, random, sys, os, math
numpy, pandas, torch, torchvision等
python的lamda函数
它是一个单表达式匿名函数,通常用作内联函数
为什么要使用Python Lambda函数?——它是一次性口罩,用完就扔。
匿名函数可以在程序的任何地方使用,但是这个函数只能使用一次,即一次性使用。
因此Python Lambda函数也称为丢弃函数,它可以与其他预定义函数(如filter(),map()等)一起使用。
与我们定义的可复用函数相比,这个函数更简单、更方便。
Python内存管理
Python的内存管理机制可以从三个方面来讲
(1)垃圾回收
(2)引用计数
(3)内存池机制
python在内存上做了哪些优化?
Python的内存管理机制可以从三个方面来讲
(1)垃圾回收
(2)引用计数
(3)内存池机制
Python中类方法和静态方法的区别
Python 类方法和实例方法相似,它最少也要包含一个参数,只不过类方法中通常将其命名为 cls,Python 会自动将类本身绑定给 cls 参数(注意,绑定的不是类对象)。也就是说,我们在调用类方法时,无需显式为 cls 参数传参。
静态方法没有类似 self、cls 这样的特殊参数,因此 Python 解释器不会对它包含的参数做任何类或对象的绑定。也正因为如此,类的静态方法中无法调用任何类属性和类方法。
跟c++很像,当然,python就是从c++封装过来的,只不过简单很多。
python多线程怎么实现
Python 提供多线程编程的模块有以下几个:
_thread
threading
Queue
multiprocessing
点积和矩阵乘法的区别?
点积 = 内积:将两个维度完全相同的向量相乘得到一个标量
矩阵相乘: XN NY==>X*Y,得到的依然是一个矩阵
Python中错误和异常处理
python中会发生两种类型的错误。
**语法错误:** 如果未遵循正确的语言语法,则会引发语法错误。
比如少写了一个冒号:或少了tab。
编译器会为我们指出来,我们不必担心。
逻辑错误(异常):在运行时,通过语法测试后发生错误的情况称为异常或逻辑类型。
比如除数除以0,运行时就会抛出一个抛出一个ZeroDivisionError异常,叫处理异常。
处理方式为:通过 try…except…finally 代码块来处理捕获异常并手动处理。
Python 的传参是传值还是传址?
说按值传递或按引用传递是不准确的。
非要安一个确切的叫法的话,叫传对象(call by object)
什么是猴子补丁?
所谓猴子补丁,是指在动态语言中,在不改变源代码的情况下,增加和改变功能。
可扩展性强
当退出 Python 时是否释放所有内存分配?
答案是否定的。
那些具有对象循环引用或者全局命名空间引用的变量,在 Python 退出是往往不会被释放。另外不会释放 C 库保留的部分内容。
Python 中的 is 和 == 有什么区别?
is比较地址:比较的是两个对象的id值是否相等,
也就是比较两个对象是否是同一个实例对象,是否指向同一个内存地址。
==比较值:比较的是两个对象的内容是否相等,默认会调用对象的eq()方法。
gbk和utf8的区别
GBK是在国家标准GB2312基础上扩容后兼容GB2312的标准。
GBK编码专门用来解决中文编码的,是双字节的。
中英文都是双字节的。
UTF-8 编码是用以解决国际上字符的一种多字节编码,
它对英文使用8位(即一个字节),
中文使用24位(三个字节)来编码。
对于英文字符较多的论坛则用UTF-8 节省空间。
另外,如果是外国人访问你的GBK网页,需要下载中文语言包支持。
访问UTF-8编码的网页则不出现这问题。可以直接访问。
GBK包含全部中文字符;
UTF-8则包含全世界所有国家需要用到的字符。
如何遍历字典
4种:
for循环
键值对
键值对的值
键值对元素
dic1 = {'date':'2018.11.2','name':'carlber','work':"遍历",'number':3}
for i in dic1:
print(i)
for key in dic1.keys(): #遍历字典中的**键**
print(key)
for value in dic1.values(): #遍历字典中的**值**
print(value)
for item in dic1.items(): #**遍历字典中的元素**
print(item)
反转列表的方法
Reverse()
sorted()指定reverse
python 元组中元组转为字典
#create a tuple
tuplex = ((2, "w"),(3, "r"))
print(dict((y, x) for x, y in tuplex))
range在python2和python3里的区别
在py2中,range得到的是一个列表,
在py3中,range得到的是一个生成器,节约内存
init.py 文件的作用以及意义
这个文件定义了包的属性和方法,它可以什么都不定义;
可以只是一个空文件,但必须存在。
如果 init.py 不存在,这个目录就仅仅是一个目录,而不是一个包,它就不能被导入或者包含其它的模块和嵌套包。
或者可以这样理解。
这样,当我们导入这个包的时候,init.py文件自动运行。
帮助我们导入了这么多模块
我们就不需要将所有的 **import语句写在一个文件里了,也可以减少代码量 **
Summarize
提示:重要课程:
1)python的基础知识,虽然平时都在编代码,但是我们用的都是现成的深度学习模块啥的,里面的其他python知识不是非常了解
2)没事就来看看,互联网大厂的笔试题和面试题都会考,尤其像京东的笔试选择题,一定会考的。
文章出处登录后可见!