机器学习简介 – Andrew Ng 的在线课堂笔记
sequence
本系列是我尝试在CSDN记录自己学习经历的第一步,希望能坚持下去。目前刚开始学机器学习不到一周,甚至还不能算入门,笔记其中包含了自己的一些理解,可能会有理解不恰当的地方,但我相信随着进一步的学习以后会更新目前的这些“幼稚”的理解。如有一些朋友有缘看到,还请见谅,可以评论区指出我的不足,互相学习,谢谢各位。
1.监督学习和无监督学习
监督学习:对输入的训练样本进行分类。比如训练肿瘤识别功能,会提前告诉机器哪些训练样本有癌症,哪些没有,提前分类。
无监督学习:与监督学习相反,只给机器一堆数据,机器可以自己分析数据结构,分离出不同的簇。
二、基本概念
1.假设函数
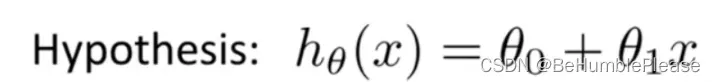
θ(θ0,θ1,…):参数
x:特征值
analogy
如同初中的数学题一样,解决数学问题的第一步,先设未知数和未知方程(形如:设y=ax+b),再通过已知的数据验证出参数(a和b),得到正确的y与 x的关系。
meaning
训练样本X和Y之间的关系,这里的X即机器学习中的特征。
Purpose
确定参数θ(θ0,θ1,…)的值:基于大量的训练样本,不断的改变θ的值,以得到最小的J(θ)。
2.代价函数
表示假设函数准确性的度量
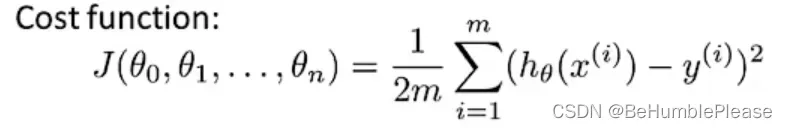
m:训练样本的数量
hθ(x(i)):第i个训练样本的特征值x在假设函数中的值,即估计值
y(i):第i个训练样本的y值,即实际值
代价函数由英文cost function翻译而来,从字面上来看感觉不太好理解,我认为代价函数是整个训练集上所有样本误差的平均,可以说明假设函数的准确程度,当代价函数值越小时,代表假设函数中参数θ(θ0,θ1,…)的值越准确,模型越准确(理想情况自然是J(θ)=0时)。
3.梯度下降算法
上边已经学习了如何定义模型(hθ(x))以及如何评价模型的准确率(J(θ)),那接下来顺理成章的应该学习如何得到最优的J(θ),以此来得到一个最优的模型。
梯度下降算法的目的能就是得到最优(小)的J(θ)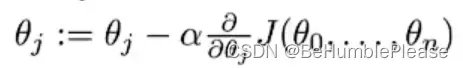
θj:第j个参数θ
α:学习率
α后边那一堆:j(θ0,θ1)对θj的偏导 (本图中j=0 或 j=1)
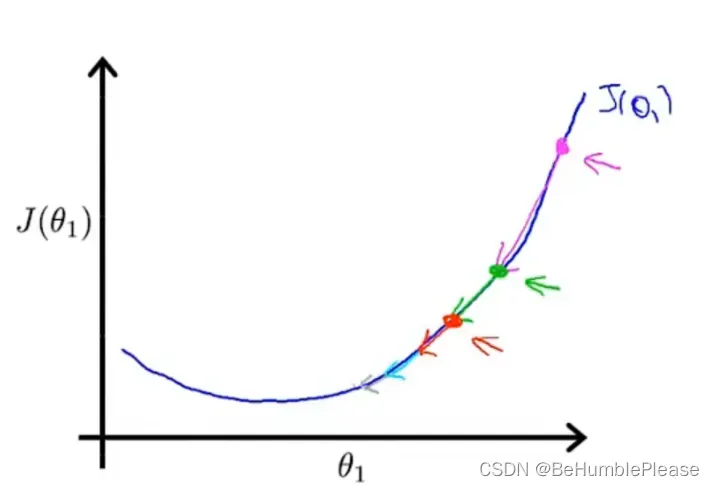
梯度下降算法使用迭代的思想,不断改变θ的值将J(θ)进行收敛,直到J(θ)为最小值,此时的θ就为最优θ。如上图所示,θ1在最低点的右侧,此时导数为正数,那么进行一次梯度下降算法公式的运算后,θ1减去一个正数得到更小的θ1。如此循环上一步(由于导数绝对值不断减小,θ1的收敛速度会如图所示的减小),当J(θ1)达到局部最小值时,由图像可知J(θ1)的导数为0,意味着θ1的值再经过梯度下降算法运算后不在改变,此时θ1即为最优θ1。若θ1在最低点的左侧,思想相同,只不过每次减去一个负数,即加上一个正数,每一次运算后θ1变大,但θ1的值依旧是向J(θ)的收敛方向“移动”。
关于学习率α的选择
尽可能选取更小的α,优秀的α会使J(θ)收敛并且收敛速度快。如果α选取太大,可能造成J(θ)收敛缓慢甚至可能不收敛。
文章出处登录后可见!