LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images
LANet: Local Attention Embedding to Improve the Semantic Segmentation of Remote Sensing Images | IEEE Journals & Magazine | IEEE Xplore[0]
1、创新点
提出了两种增强特征表示的方法:
1、基于局部注意分块计算,提出一种分块注意力模块(PAM)来增强上下文信息的嵌入;PAM附加在高级特征和低级特征之后,以增强他们的表示。
2、为了弥补高级特征和低级特征的差异,提出了注意力嵌入模块(AEM),通过嵌入高层特征的局部焦点来丰富底层特征的语义信息。可以使低级特征不丢失空间信息的情况下增强高级语义信息。
2、解决的问题
1、CNN 后期提取的高级特征具有丰富的语义信息,但是空间信息模糊;CNN早期的低级特征包含更多像素级别信息,但是是孤立的、有噪声的
2、问题:物理信息内容和空间分布的差异,难以弥合高层次和低层次特征之间的差异
3、编码器通过叠加卷积和池化,不断减小特征的空间大小,以增强语义信息,虽然扩大了感受野,学习更多特征,但是丢失了空间信息。这样看来,语义分割是将大面积区域视为一个整体,而不是对像素进行精确分类,小物体可能会被忽略。为解决这个问题,引入了解码器,通过编码器的低级特征融合来弥补丢失的空间信息,但是低级特征和高级特征在语义信息和空间分布上都有显著差异,简单融合并不能提高分割精度。
![]() 例子:低层特征对梯度变化和差异敏感,高层特征在物体中心有更强的激活。
例子:低层特征对梯度变化和差异敏感,高层特征在物体中心有更强的激活。
4、特征嵌入能力和空间定位精度之间的权衡。
一方面,不同类别的物体可能具有相似的光谱,因此需要聚合背景信息。
另一方面,RSI分析应用需要高精度
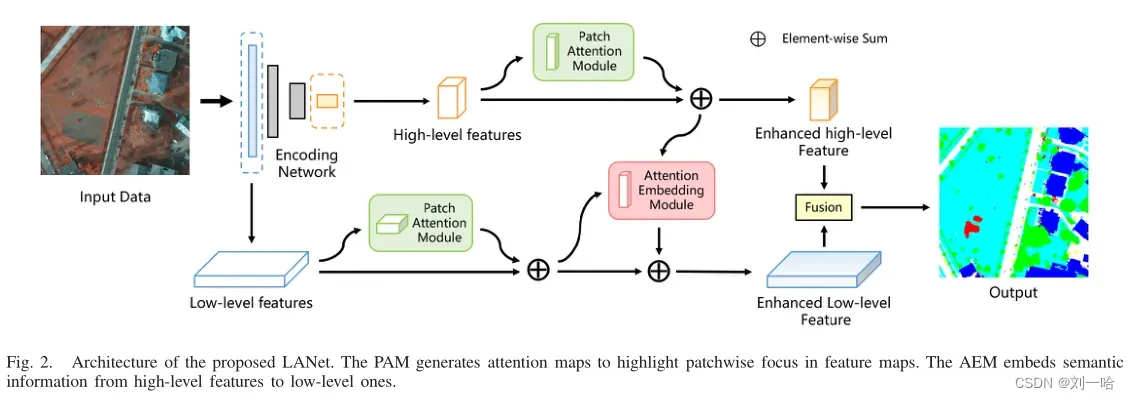
3、提出的模型
在上边的分支,高级特征(由CNN后期生成)通过PAM来增强其特征表示;较低的分支中,低级特征首先由PAM增强,然后通过AEM嵌入高层语义信息。
4、PAM
解决类内不一致:语义标签相同,但预测结果不同
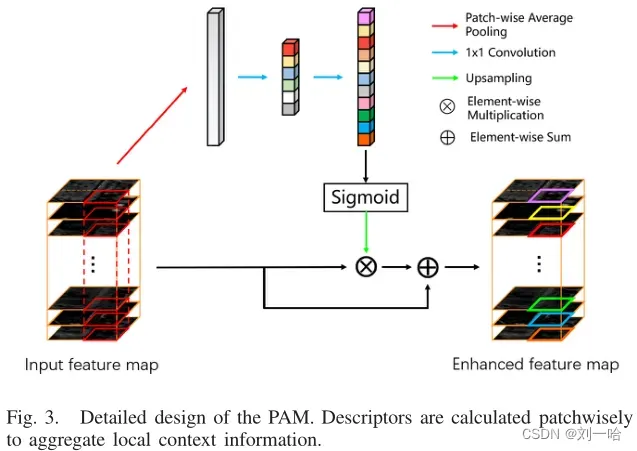
对每个patch——GAP(池化),1*1conv降维,ReLU,1*1conv升维,sigmoid
类似于SENet的瓶颈结构
class Patch_Attention(nn.Module):
def __init__(self, in_channels, reduction=8, pool_window=10, add_input=False):
super(Patch_Attention, self).__init__()
self.pool_window = pool_window
self.add_input = add_input
self.SA = nn.Sequential(
nn.Conv2d(in_channels, in_channels // reduction, 1),
nn.BatchNorm2d(in_channels // reduction, momentum=0.95),
nn.ReLU(inplace=False),
nn.Conv2d(in_channels // reduction, in_channels, 1),
nn.Sigmoid()
)
def forward(self, x):
b, c, h, w = x.size()
pool_h = h//self.pool_window
pool_w = w//self.pool_window
A = F.adaptive_avg_pool2d(x, (pool_h, pool_w))
A = self.SA(A)
A = F.upsample(A, (h,w), mode='bilinear')
output = x*A
if self.add_input:
output += x
return output5、AEM
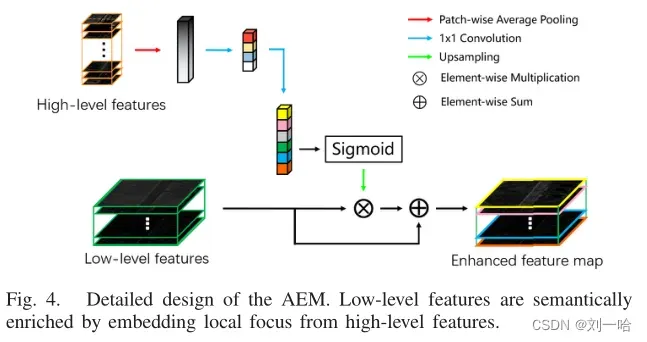
将高级特征的局部注意力嵌入到低级特征中。
class Attention_Embedding(nn.Module):
def __init__(self, in_channels, out_channels, reduction=16, pool_window=6, add_input=False):
super(Attention_Embedding, self).__init__()
self.add_input = add_input
self.SE = nn.Sequential(
nn.AvgPool2d(kernel_size=pool_window+1, stride=1, padding = pool_window//2),
nn.Conv2d(in_channels, in_channels//reduction, 1),
nn.BatchNorm2d(in_channels//reduction, momentum=0.95),
nn.ReLU(inplace=False),
nn.Conv2d(in_channels//reduction, out_channels, 1),
nn.Sigmoid())
def forward(self, high_feat, low_feat):
b, c, h, w = low_feat.size()
A = self.SE(high_feat)
A = F.upsample(A, (h,w), mode='bilinear')
output = low_feat*A
if self.add_input:
output += low_feat
return output文章出处登录后可见!