Faster-RCNN模型搭建跑通总结
- 0、前言
- 1、准备操作系统
- 2、安装驱动及cuda
- 2.1、安装驱动
- 2.2、安装cuda
- 3、安装anaconda和pytorch
- 3.1 安装anaconda
- 3.1.1为什么推荐安装anaconda而不是pip安装?
- 3.1.2 安装anaconda
- 3.1.3 配置国内镜像源
- 3.2 安装pytorch
- 3.2.1 确认要安装的pytorch版本
- 3.2.2 安装pytorch
- 3.2.2.1 在conda中创建虚拟环境
- 3.2.2.2 激活该虚拟环境
- 3.2.2.3 在该环境中安装pytorch
- 3.2.2.4 确认安装的pytorch版本
- 4、训练faster-rcnn模型
- 4.1 下载模型到本地
- 4.2 安装所需的依赖包
- 4.3 编译cuda 依赖项
- 4.3.1 编译coco api
- 4.3.2 编译cuda 依赖项
- 4.3.3 验证是否编译成功
- 4.4 下载数据集
- 4.5 下载预训练模型
- 4.6 训练模型
- 5、总结
0、前言
最近在学习Faster-RCNN模型,想在自己个人的笔记本上复现代码,本以为没那么复杂,但过程中却没那么简单,反倒是十分波折😅从开始装ubuntu系统,到现在跑通模型代码,断断续续有两周了吧(中间还重装了2次系统),真可谓一波三折,踩了无数坑。
我觉得有必要总结一下整个过程,同时也希望能给学习AI领域的小伙伴一些帮助!
1、准备操作系统
我本来用的是windows系统,但听说工作时一般都用linux系统及服务器训练模型,因此转战linux。其实安装windows+linux双系统挺简单的,网上教程一大堆,在此不再赘述,我想重点强调以下两点:
- linux系统推荐选择ubuntu18.04版本。
因为网上很多教程针对的是18.04版本(当然20.04也有不少,笔者没有尝试),并且物体检测领域经典模型的复现及讨论基本都处于2017-2019年,当时ubuntu系统版本没这么高,出现一些问题也好百度。
笔者曾经安装了两次最新的ubuntu22.04版本,安装软件经常出现“安装包依赖”,导致安装软件或者python包很麻烦,需要卸载一些高版本的包,但如果你不小心卸载了一些系统相关的包,系统就会崩溃(比如无法正常开机、开机键盘鼠标失灵等)。笔者作为一个小白,在这个上面吃了两次亏,以血泪的教训总结出最好安装低版本的,于是第三次安装的ubuntu18.04版本,基本没有出现大问题。 - linux系统可以不用分区。
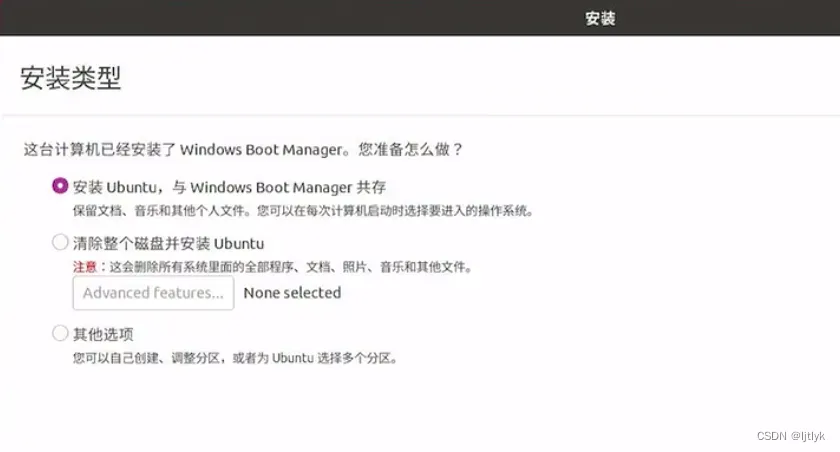
网上很多教程都建议给系统分区,什么引导区、内存交换分区等等,要分4个区,其实我认为大可不必,因为首先操作比较麻烦,其次如果你某个分区不是很大,后面装pytorch、anaconda、cuda等一系列软件,并且conda创建不同的环境跑不同模型容易出现空间不够的情况,那就十分蛋疼了。
所以,简单并且实用的策略是,不要分区,如下图,选择第一个
2、安装驱动及cuda
2.1、安装驱动
装好ubuntu系统后,第一件事就是给你的显卡安装合适的驱动,打开终端,输入以下命令查看显卡型号:
lshw -c video
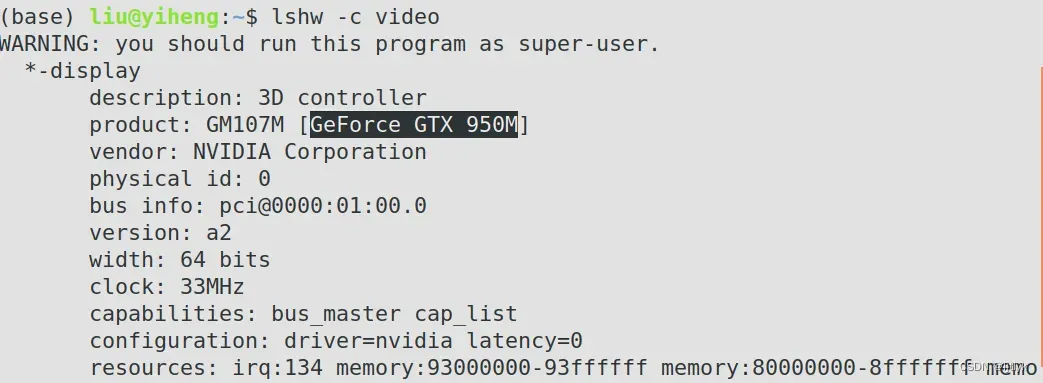
比如说我的笔记本显卡是 nvidia GeForce GTX950M,去官网上查找、下载并安装自己的驱动。在这篇博客里写的很详细,推荐参考。其中注意一点,安装驱动时可以不关闭图形界面,直接打开终端输入命令即可。
2.2、安装cuda
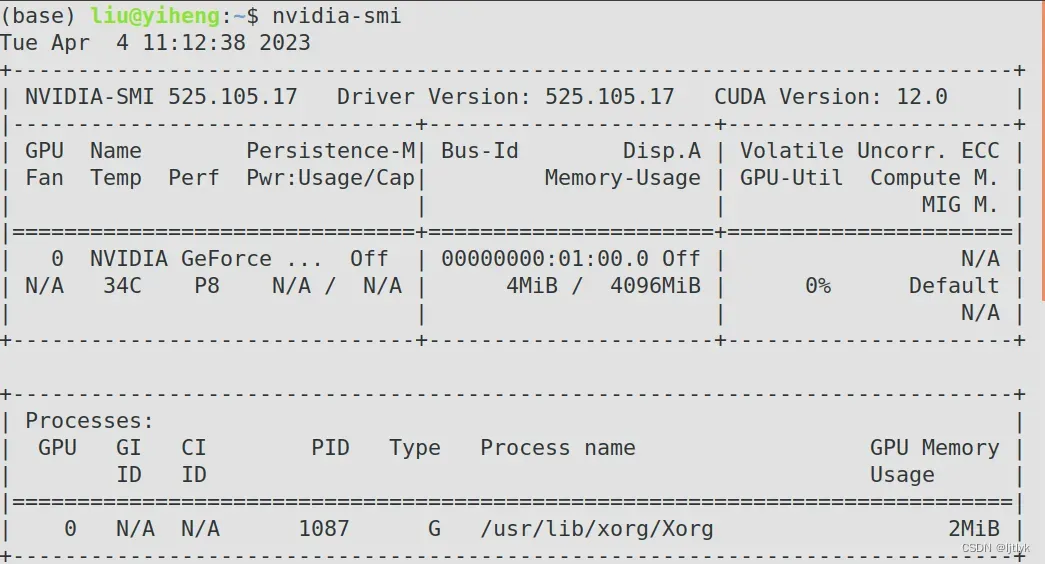
cuda准确来说是CUDA Toolkit,它是在利用GPU跑模型时必要的工具包,注意这里不要和驱动对应的cuda混淆,后者是显卡驱动对应的cuda,而不是利用GPU跑模型时的CUDA Toolkit,两者不是一个东西。通常,安装好显卡驱动后,即可在终端输入:
nvidia-smi
———————方法1(推荐)命令行安装(可能需要科学上网)
sudo apt install nvidia-cuda-toolkit
———————方法2(不推荐)下载安装包
右上角CUDA Version:12.0也就是我电脑显卡驱动对应的cuda版本,也通常是显卡支持的最高CUDA Toolkit版本,具体可在官网查询,如下图:
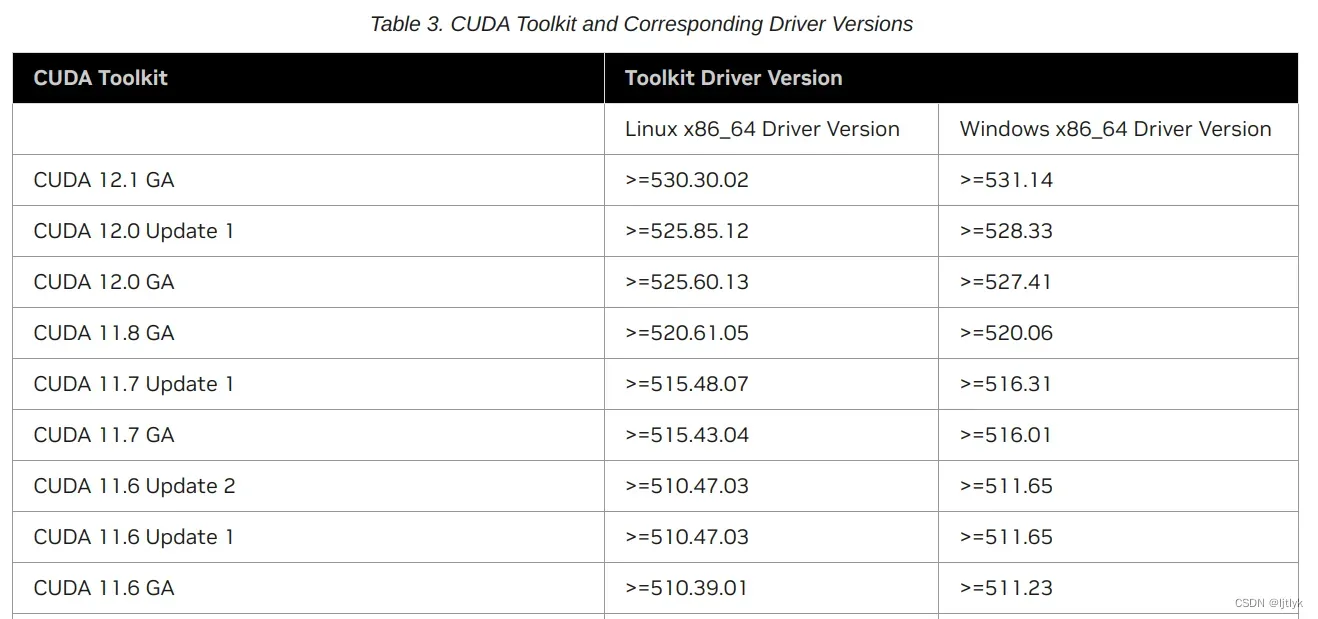
什么版本的CUDA Toolkit是合适的呢?其实要看你跑什么模型了,一般来说你去github上复现代码,都会有对应prerequisites(环境要求),你需要安装的CUDA Toolkit不低于推荐的就行,并且,因为cuda都是向下兼容的,高版本CUDA Toolkit可以跑低版本模型。
例如:jwyang的faster-rcnn.pytorch模型,CUDA Toolkit不低于8.0,要求比较低了。
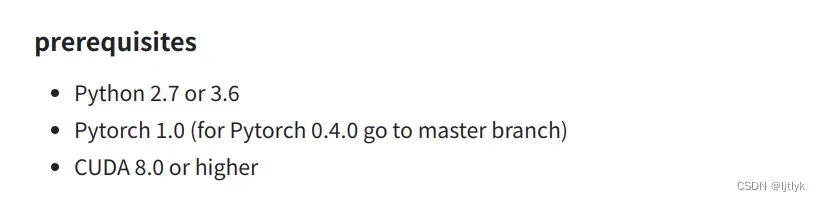
也就是说,在我电脑上跑这个模型,理论上CUDA Toolkit版本在8.0到12.0之间都行。
但是注意:由于8.0版本太低了,资源(尤其是镜像资源)不好找,目前亲测下载速度快的清华源,pytorch对应的cuda版本最低是10.2:
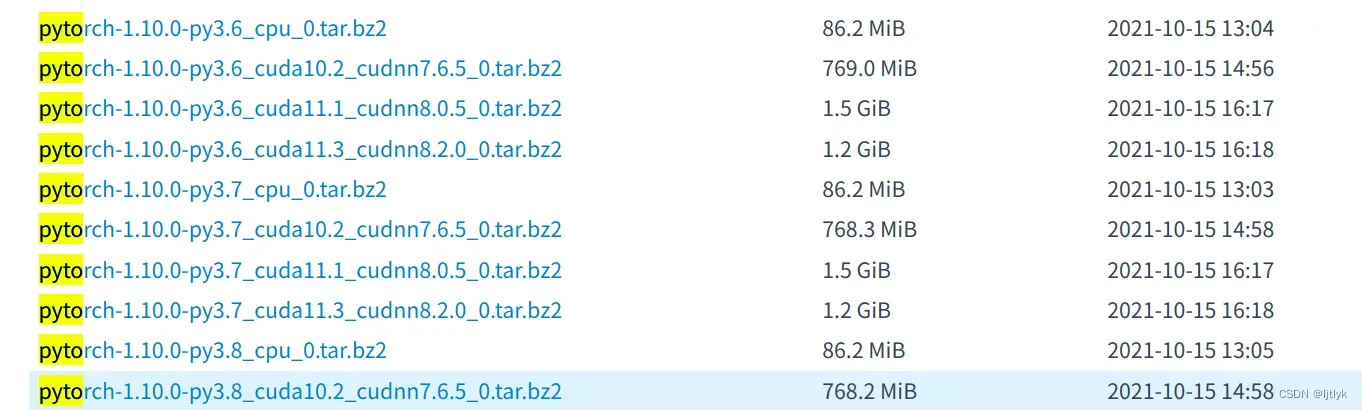
因此,笔者推荐在安装CUDA Toolkit版本时,一定要先看下镜像资源的具体情况,安装资源里是否有对应的CUDA Toolkit版本,否则就要跟笔者一样,到后面安装pytorch踩坑:conda安装pytorch找不到合适的版本(后面会细讲)。
以笔者为例,我安装的是CUDA Toolkit10.2版本(期望安装较低版本以免出错),首先在官网选择对应的版本,点击10.2版本链接

选择合适的系统,推荐“runfile[local]”模式,因为安装方便且下载速度快,具体安装和配置环境变量可参考该博客
![选择runfile[local]](https://aitechtogether.com/wp-content/uploads_new/2023/11/a3652717-df99-47a3-91b5-408586d19e35.webp)
注意以下几点:
1、安装cuda过程中,如果提示没有安装gcc,那就sudo apt-get install gcc,如果安装gcc出现包依赖无法安装,可参考这篇博客。
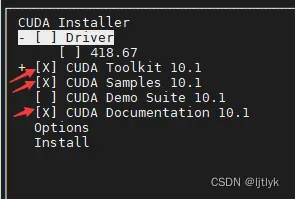
2、安装cuda一定不要选择第一个Driver选项,用空格键把该选项叉去掉(这里打叉表示安装此项),因为上一部我们已经安装好了驱动,无需再安装驱动(ps:这里借用了该博客的图)
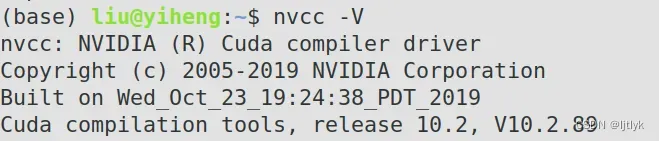
安装完CUDA Toolkit并配置好环境变量后,终端输入 nvcc -V,即可查看自己的CUDA Toolkit版本,再次强调这里是CUDA Toolkit版本,是利用GPU跑模型时的CUDA Toolkit,并不是显卡驱动对应的cuda,两者不是一个东西,版本不一样很正常,并且你也可以安装多个CUDA Toolkit版本。
所以,在安装pytorch版本需要选择对应的CUDA Toolkit版本时,一定要输入nvcc -V查看,而不是 nvidia-smi (切记,切记!!!)
3、安装anaconda和pytorch
3.1 安装anaconda
3.1.1为什么推荐安装anaconda而不是pip安装?
首先,你可能不止训练一个模型,而不同的模型依赖的python或pytorch版本可能不同,因此需要一个软件来管理不同python版本下的运行环境,而anaconda可以满足该要求。利用conda命令来创建不同版本的python虚拟环境,并在指定环境下安装合适的pytorch及各种包,具体实现可参考该博客。
其次,利用anaconda可以自动安装跑模型相关的各类包,如numpy、cv等,而pip则需要手动安装这些包,比较繁琐。
3.1.2 安装anaconda
安装十分简单,去官网下载安装包,终端输入
bash AnacondaX-X.X.X-Linux-x86_64.sh
即可完成对应版本的安装
3.1.3 配置国内镜像源
为什么推荐配置国内镜像源?
在利用conda安装pytorch及各种包时,需要访问国外网站,下载速度kb级别,特别浪费时间,而国内国内镜像源很快,下载速度Mb级别,节约大把时间。
具体配置方法可参考该博客。
另外,也可以直接指定conda和pip下载的源,具体可参考该博客。
3.2 安装pytorch
3.2.1 确认要安装的pytorch版本
上面在2.2节介绍过,要依据你跑的模型确认要安装的pytorch版本,以笔者要复现的 jwyang的faster-rcnn.pytorch 模型为例,推荐安装pytorch1.0版本,否则有可能因为版本不同的原因,运行出现各种报错,令人头大,甚至百度谷歌半天都找不出解决方案。
其实,这个faster-rcnn模型的master分支依赖的是 Pytorch 0.4.0 版本,但由于该版本太老,利用conda安装找不到安装的资源,并且匹配的cuda版本也太低了,虽说是高版本cuda兼容低版本的,但就怕出bug不好解决。因此,推荐faster-rcnn模型的pytorch1.0分支运行代码,即笔者选择安装pytorch1.0版本。
但是,我去清华镜像源找了半天,没找到pytorch1.0版本,只找到pytorch1.10及以上版本,于是选择安装pytorch1.10版本。
(ps:也去pytorch官网找了1.0版本的conda安装命令,但conda还是找不到安装的源,遂放弃)
3.2.2 安装pytorch
3.2.2.1 在conda中创建虚拟环境
由于可能需要多个python版本环境跑多个模型,推荐新建一个虚拟环境,以笔者为例,新建一个python3.6版本的pytorch1.10环境,终端输入命令:
conda create -n pytorch110 python=3.6
3.2.2.2 激活该虚拟环境
conda activate pytorch110
激活以后就进入了名为pytorch110的环境,终端开头会显示(pytorch110)
3.2.2.3 在该环境中安装pytorch
前面3.1.3已提到,采用国内镜像源安装,在配置好了镜像源后,要输入安装命令,例如:
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=10.2
运行上述命令后,conda会检索对应的包,并提示你是否安装上述包,在检查无误后,输入y即可完成安装!
注意:
1、pytorch的版本和cudatoolkit的版本必须写上,因为要让conda识别出你要安装那个版本的,否则conda可能随便给你装个其他版本的;
2、指定的版本最好去镜像源网站确认下是否存在,例如清华镜像源有pytorch==1.10.0的cudatoolkit=10.2版本,否则conda可能随便给你装个其他版本的(笔者在此踩过坑,指定的1.0版本,但由于没有资源给我装了其他版本)
3、torchvision torchaudio是pytorch相关的包,要写上,但可不指定版本,conda应该会自动选择合适的版本;
4、安装命令最后不要出现-c pytorch,这个表示采用pytorch官方的源,而我们推荐国内镜像源。
3.2.2.4 确认安装的pytorch版本
终端输入python进入交互环境,并输入:
import torch
print(torch.__version__)
即可确认你安装的pytorch版本

4、训练faster-rcnn模型
很多人推荐github上 jwyang的faster-rcnn.pytorch 模型,下面以此模型为例,介绍如何跑通代码。
4.1 下载模型到本地
推荐直接采用git命令克隆代码(没有安装git参考该博客):
git clone git@github.com:jwyang/faster-rcnn.pytorch.git
cd faster-rcnn.pytorch
git checkout pytorch-1.0
注意:一定要git checkout !!!
否则,就算你复制了pytorch-1.0分支的链接,在你的本地上仍然不是pytorch-1.0分支的代码,而是Pytorch 0.4.0!(笔者踩坑点)
4.2 安装所需的依赖包
需要在pytorch110环境中,利用pip安装依赖包
在requirements.txt所在文件夹进入终端,输入命令:
conda activate pytorch110 #激活pytorch110环境
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #采用清华源安装所需包
4.3 编译cuda 依赖项
注意:这一步非常重要,一定要按照顺序来!!!
笔者卡在这一步好几天,各种百度谷歌始终无法编译成功,最后终于在github-issue上找到了解决办法!
4.3.1 编译coco api
cd lib/pycocotools #进入coco文件夹
gedit setup.py #创建并编辑名为setup的编译文件
在创建了名为setup的编译文件后,复制以下代码并保存该文件:
# --------------------------------------------------------
# Fast R-CNN
# Copyright (c) 2015 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ross Girshick
# --------------------------------------------------------
import os
from setuptools import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
import numpy as np
# Obtain the numpy include directory. This logic works across numpy versions.
try:
numpy_include = np.get_include()
except AttributeError:
numpy_include = np.get_numpy_include()
ext_modules = [
Extension(
'_mask',
sources=['maskApi.c', '_mask.pyx'],
include_dirs = [numpy_include, '.'],
extra_compile_args=['-Wno-cpp', '-Wno-unused-function', '-std=c99'],
)
]
setup(
name='faster_rcnn',
ext_modules=ext_modules,
# inject our custom trigger
cmdclass={'build_ext': build_ext},
)
最后在终端运行如下代码:
python setup.py build_ext --inplace
4.3.2 编译cuda 依赖项
终端运行以下代码:
cd .. # 回到 lib 文件夹
python setup.py build develop # 编译cuda 依赖项
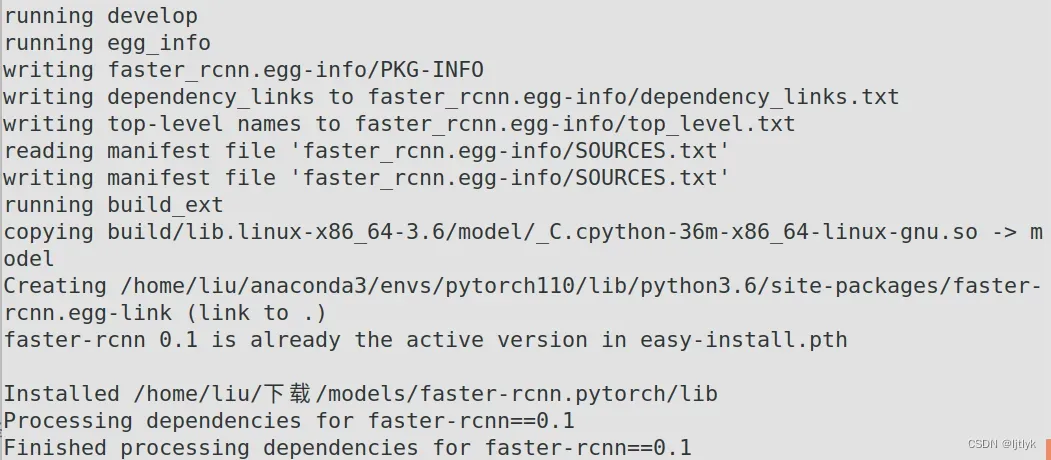
当出现上述Finished processing dependencies for faster-rcnn==0.1时,恭喜你,编译成功了!
4.3.3 验证是否编译成功
终端输入python进入交互界面,并输入以下代码
>>> import sys
>>> sys.path.append("/[location_to]/faster-rcnn.pytorch/lib")
>>> from model.roi_layers import ROIPool # PyTorch 1.0 specific!
>>> roi_pool = ROIPool((2,2), 1)
注意:sys.path.append中添加的地址要改为模型中lib地址。
如果上述命令没有报错,那么恭喜你,你快要成功了!
如果报错,检查上述步骤有没有按顺序一步一步来。
(ps:在此感谢Andrew Jong提供的帮助,详见该网页)
另外,编译过程中千万不要执行sh make.sh,这也是笔者踩的坑:
因为这是适用于Pytorch 0.4.0版本的,执行了也会出现如下报错:
“ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.”
该博客指出的方法:
将from torch.utils.ffi import create_extension改为:
from torch.utils.cpp_extension import BuildExtension
实测没用,以及再将文件下面的调用
ffi = create_extension(…)改为
ffi = BuildExtension(…)
实测也没有用,最后都会引起诸如_wrap_function等其他模块报错!!
from torch.utils.ffi import _wrap_function
ImportError: torch.utils.ffi is deprecated. Please use cpp extensions instead.
或者出现:TypeError: dist must be a Distribution instance
还有人建议降级到pytorch0.4.0版本,其实好像也没有用,大可不必!!
根本问题是coco api没有编译!!
4.4 下载数据集
1、下载pascal VOC2007数据集,可参考该博客;
2、在模型目录下创建data文件夹;
3、在data文件夹下创建指向pascal VOC2007数据集的软链接,如何创建参考该博客。
注意:软链接的文件夹名称必须为VOCdevkit2007,否则可能报错。
4.5 下载预训练模型
预训练模型是别人之前训练好的模型,里面含有大量权重参数,我们训练模型一般都需要在预训练模型的基础上二次训练(个人认为就是优化),这样模型更容易收敛。
在 jwyang的faster-rcnn.pytorch 上有不同模型的下载链接,我用的是VGG16,下载链接点此。

下载记得放在/faster-rcnn.pytorch/data/pretrained_model目录下。
4.6 训练模型
1、在训练之前,可以设置自己想要的目录来保存和加载训练好的模型。
更改 trainval_net.py 和 test_net.py 中的参数“save_dir”和“load_dir”以适应你的环境,具体可参考该博客。
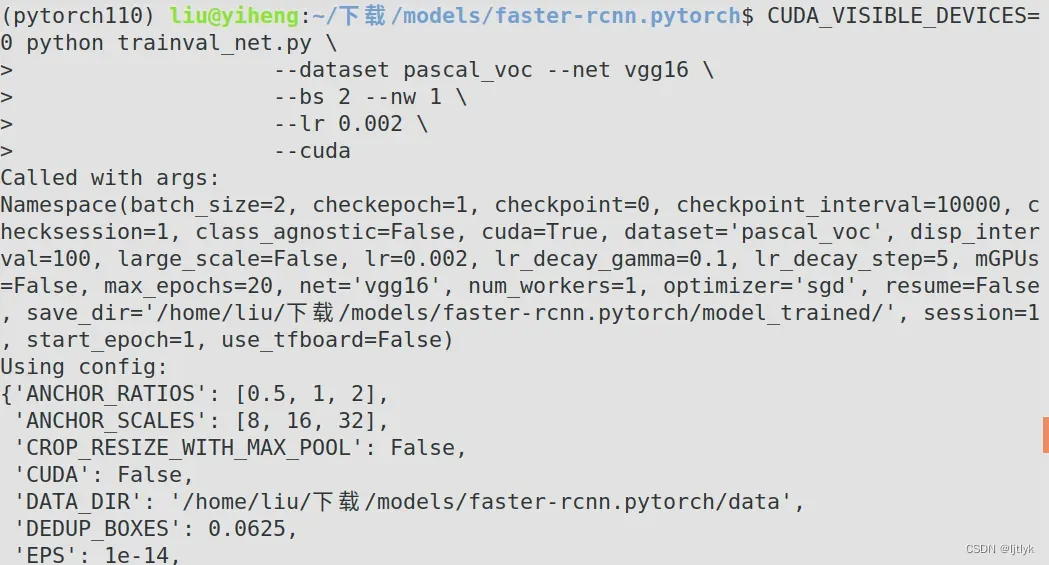
2、在终端中pytorch110的环境中,使用如下命令即可开始模型训练:
CUDA_VISIBLE_DEVICES=0 python trainval_net.py \
--dataset pascal_voc --net vgg16 \
--bs 2 --nw 1 \
--lr 0.002 \
--cuda
bs指的是 batch size,即每次前向传播送入的图片张数,可以设为4尝试以下,但由于我只有1个GPU并且显卡内存只有4个G,因此超内存报错了RuntimeError: CUDA out of memory,只好设置为2(也可参考此文章)。
其余参数具体介绍详见这篇博客。
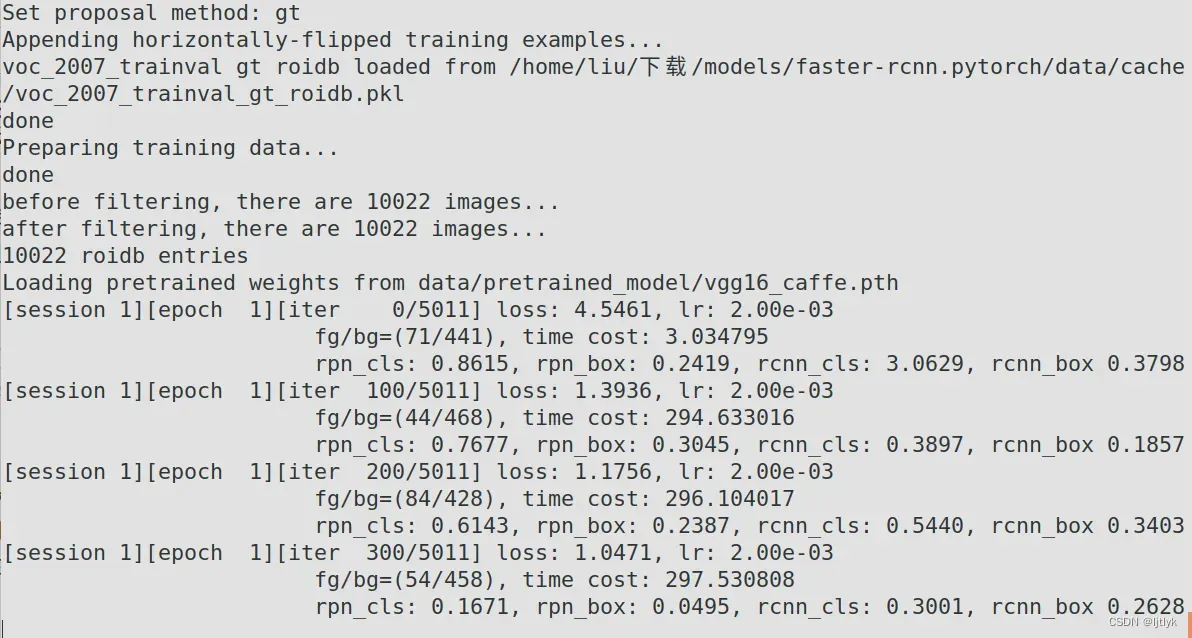
训练过程截个图供参考,也欢迎大家讨论,我的训练为什么这么慢:
一共10022张照片,每次送入2张图片,每个epoch需要10022/2=5011次计算量,这上面每100次计算约需要300秒(5分钟),完成一个epoch需要4.1个小时(汗–||)
3、如果出现以下报错:
(1)can’t import ‘imread’
是因为scipy1.0以上的版本里,不再使用imread,应安装imageio包(pip install imageio),并在出错的py文件里修改为
from imageio import imread # 修改解决ImportError: cannot import name 'imread' from 'scipy.misc'
(2)load() missing 1 required positional argument: ‘Loader‘
该错误原因是因为.yaml文件在load()时缺少必填的loader参数
解决方法:用safe_load()替换load()这个函数,详见该博客。
5、总结
模型跑通的确不容易,尤其是对于我这样的初学并且自学的小白,期间好几次都想放弃,但又不甘,过程中真不可谓不艰辛,尤其是编译cuda 依赖项这个最折磨人,今天抽出一天时间好好整理了一下,算是对这段时间的学习总结,并且期望能够帮助到大家,谢谢!
借用一句话:保持热爱,共赴山海!
有问题欢迎和我留言讨论!!
未完待续:有待补充模型测试及演示遇到的问题。
文章出处登录后可见!