
>>>深度学习Tricks,第一时间送达<<<
目录
NAMAttention,一种新的注意力计算方式,无需额外的参数!
(二)YOLOv5/YOLOv7改进之结合NAMAttention
NAMAttention,一种新的注意力计算方式,无需额外的参数!
(一)前沿介绍
论文题目:NAM: Normalization-based Attention Module
论文地址:https://arxiv.org/abs/2111.12419
代码地址:https://github.com/Christian-lyc/NAM

作者提出了一种基于归一化的注意力模块(NAMAttention),可以降低不太显著的特征的权重,这种方式在注意力模块上应用了稀疏的权重惩罚,这使得这些权重在计算上更加高效,同时能够保持同样的性能。在ResNet和MobileNet上和其他的注意力方式进行了对比,该方法可以达到更高的准确率。
1.NAM结构图
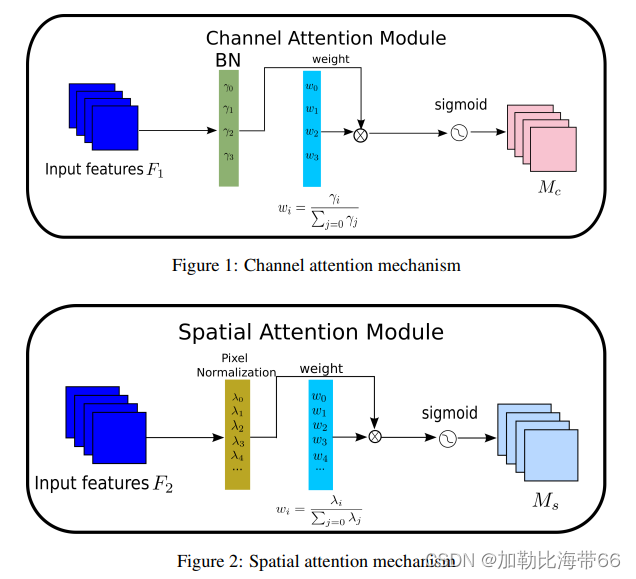
2.相关实验结果
作者将NAM和SE,BAM,CBAM,TAM在ResNet和MobileNet上,在CIFAR100数据集和ImageNet数据集上进行了对比,对每种注意力机制都使用了同样的预处理和训练方式,对比结果表示,在CIFAR100上,单独使用NAM的通道注意力或者空间注意力就可以达到超越其他方式的效果。在ImageNet上,同时使用NAM的通道注意力和空间注意力可以达到超越其他方法的效果。
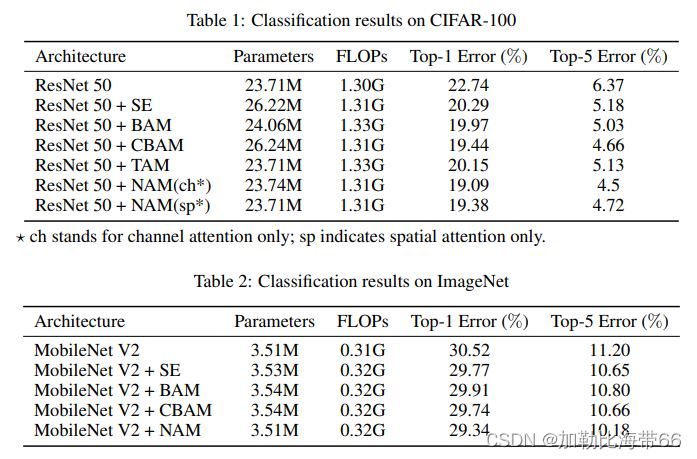
(二)YOLOv5/YOLOv7改进之结合NAMAttention
改进方法和其他注意力机制一样,分三步走:
1.配置common.py文件
加入NAM代码。
#NAM
class NAM(nn.Module):
def __init__(self, channels, t=16):
super(NAM, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x2.配置yolo.py文件
加入NAM模块。
3.配置yolov5_NAM.yaml文件
添加方法灵活多变,Backbone或者Neck都可。
关于算法改进及论文投稿可关注并留言博主的CSDN/QQ
>>>一起交流!互相学习!共同进步!<<<
文章出处登录后可见!
已经登录?立即刷新