一、图像配准
图像配准是将 一个场景的不同图像变换到同一坐标系的过程。这些图像可以在不同的时间(多时间配准)、由不同的传感器(多模态配准)和/或从不同的视点拍摄。这些图像之间的空间关系可以是 刚性的 (平移和旋转)、 仿射 ( 例如 剪切)、单应性或复杂的大变形模型。
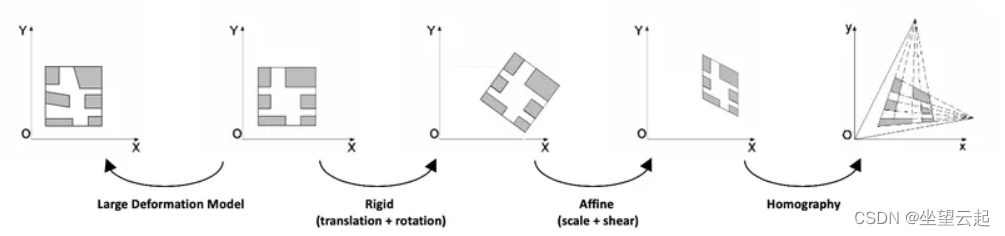
图像配准具有广泛的应用:当任务需要比较同一场景的多个图像时,它是必不可少的。 它在医学图像领域以及卫星图像分析和光流领域非常常见。
二、传统的基于特征的方法
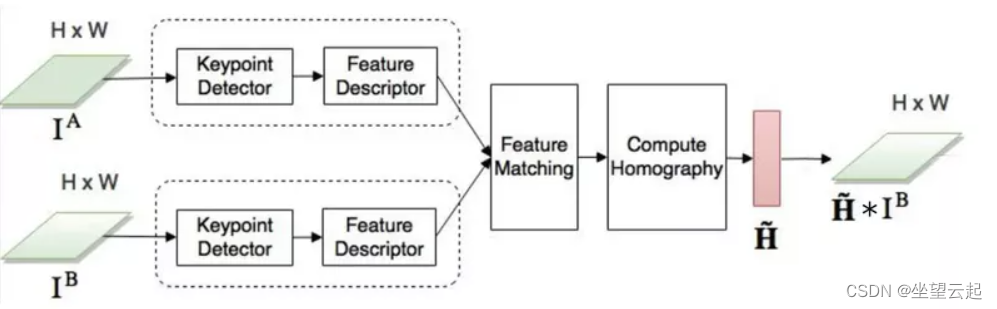
自 2000 年代初以来,图像配准主要使用传统 的基于特征的方法。这些方法基于三个步骤:关键点检测和特征描述、特征匹配和图像变形。简而言之,我们选择两个图像中的兴趣点,将参考图像中的每个兴趣点与其在感知图像中的等效点相关联,并转换感知图像以使两个图像对齐。
参考论文https://arxiv.org/pdf/1709.03966.pdf![]() https://arxiv.org/pdf/1709.03966.pdf
https://arxiv.org/pdf/1709.03966.pdf
1、关键点检测和特征描述
关键点定义了图像中重要和独特的内容(角落、边缘等)。每个关键点由一个 描述符表示:一个包含关键点基本特征的特征向量。描述符应该对图像转换(定位、比例、亮度等)具有鲁棒性。许多算法执行关键点检测和特征描述:
SIFT(尺度不变特征变换) 是用于关键点检测的原始算法,但它不能免费用于商业用途。SIFT 特征描述符对于均匀缩放、方向、亮度变化是不变的,并且对于仿射失真是部分不变的。
SURF (Speeded Up Robust Features)是一个受到 SIFT 启发的检测器和描述符。它具有快几倍的优势。
ORB FAST Brief(面向 FAST 和 Rotated Brief) 是基于 FAST (来自加速段测试的特征) 关键点检测器和 Brief (二进制鲁棒独立基本特征) 描述符的组合的快速二进制描述符。它是旋转不变的并且对噪声具有鲁棒性。它是在 OpenCV Labs 中开发的,它是 SIFT 的一种高效的替代品。
AKAZE (Accelerated-KAZE)是KAZE 的加速版本。它提出了一种用于非线性 尺度空间的快速多尺度特征检测和描述方法。它既是尺度不变的,也是旋转不变的。
这些算法在 OpenCV 中都是可用且易于使用的。在下面的示例中,我们使用了 AKAZE 的 OpenCV 实现。其他算法的代码大致相同:只需要修改算法的名称。
import numpy as np
import cv2 as cv
img = cv.imread('image.jpg')
gray= cv.cvtColor(img, cv.COLOR_BGR2GRAY)
akaze = cv.AKAZE_create()
kp, descriptor = akaze.detectAndCompute(gray, None)
img=cv.drawKeypoints(gray, kp, img)
cv.imwrite('keypoints.jpg', img)关于OpenCV的特征检测使用参考下面链接
2、特征匹配
一旦在形成一对的两幅图像中识别出关键点,我们就需要关联或“匹配”两幅图像中实际上对应于同一点的关键点。一种可能的方法是 BFMatcher.knnMatch()。 该匹配器测量每对关键点描述符之间的距离,并为每个关键点返回其 k 与最小距离的最佳匹配。
然后我们应用一个比率过滤器来只保留正确的匹配。事实上,为了实现可靠的匹配,匹配的关键点应该比最近的不正确匹配明显更接近。
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
img1 = cv.imread('image1.jpg', cv.IMREAD_GRAYSCALE) # referenceImage
img2 = cv.imread('image2.jpg', cv.IMREAD_GRAYSCALE) # sensedImage
# Initiate AKAZE detector
akaze = cv.AKAZE_create()
# Find the keypoints and descriptors with SIFT
kp1, des1 = akaze.detectAndCompute(img1, None)
kp2, des2 = akaze.detectAndCompute(img2, None)
# BFMatcher with default params
bf = cv.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# Apply ratio test
good_matches = []
for m,n in matches:
if m.distance < 0.75*n.distance:
good_matches.append([m])
# Draw matches
img3 = cv.drawMatchesKnn(img1,kp1,img2,kp2,good_matches,None,flags=cv.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
cv.imwrite('matches.jpg', img3)
3、图像变形
在匹配至少四对关键点之后,我们可以将一张图像相对于另一张图像进行转换。这称为 图像 变形。空间中同一平面的任何两个图像都通过 单应性相关联。单应性是具有 8 个自由参数并由 3×3 矩阵表示的几何变换。它们代表对整个图像造成的任何失真(与局部变形相反)。因此,为了获得变换后的感知图像,我们计算 单应矩阵 并将其应用于感知图像。
为了确保最佳变形,我们使用 RANSAC 算法检测异常值并在确定最终单应性之前将其移除。它直接内置在 OpenCV 的 findHomography 方法中。存在 RANSAC 算法的替代方案,例如 LMEDS:最小中值鲁棒方法。
# Select good matched keypoints
ref_matched_kpts = np.float32([kp1[m[0].queryIdx].pt for m in good_matches])
sensed_matched_kpts = np.float32([kp2[m[0].trainIdx].pt for m in good_matches])
# Compute homography
H, status = cv.findHomography(sensed_matched_kpts, ref_matched_kpts, cv.RANSAC,5.0)
# Warp image
warped_image = cv.warpPerspective(img2, H, (img2.shape[1], img2.shape[0]))
cv.imwrite('warped.jpg', warped_image)三、深度学习方法
当今大多数图像配准研究都涉及深度学习的使用。在过去的几年里,深度学习在计算机视觉任务 (如图像分类、对象检测和分割)中实现了最先进的性能。没有理由不再图像配准的领域应用。
1、特征提取
深度学习用于图像配准的第一种方式是特征提取。 卷积神经网络的连续层设法 捕获越来越复杂的图像特征并学习特定任务的特征。研究人员已将这些网络应用于特征提取步骤,而不是 SIFT 或类似算法。
2014 年,Dosovitskiy 等人。建议仅使用未标记的数据来训练卷积神经网络。这些特性的通用性使它们对转换具有鲁棒性。这些特征或描述符在匹配任务方面优于 SIFT 描述符。
2018 年,杨等人。 基于相同的思想开发了一种非刚性配准方法。他们使用预训练的 VGG 网络层来生成一个特征描述符,该描述符同时保留了卷积信息和定位能力。这些描述符似乎也优于类似 SIFT 的检测器,特别是在 SIFT 包含许多异常值或无法匹配足够数量的特征点的情况下。

最后一篇论文的代码可以在这里找到。虽然我们能够在 15 分钟内在我们自己的图像上测试这种配准方法,但该算法比本文前面实施的类似 SIFT 的方法慢了大约 70 倍。
 https://github.com/yzhq97/cnn-registration
https://github.com/yzhq97/cnn-registration2、单应性学习
研究人员没有将深度学习的使用限制在特征提取上,而是尝试使用神经网络直接 学习几何变换来对齐两个图像。
监督学习 2016 年,DeTone 等人。发表 了描述 Regression HomographyNet的Deep Image Homography Estimation ,这是一种 VGG 风格的模型,可以 学习与两个图像相关的单应性。该算法具有 以端到端方式同时学习单应性和 CNN 模型参数的优势:不需要前面的两阶段过程!
https://arxiv.org/pdf/1606.03798.pdf![]() https://arxiv.org/pdf/1606.03798.pdf
https://arxiv.org/pdf/1606.03798.pdf

网络产生八个实数值作为输出。 由于 输出和 真实单应性之间的欧几里得损失 ,它以有监督的方式进行训练 。
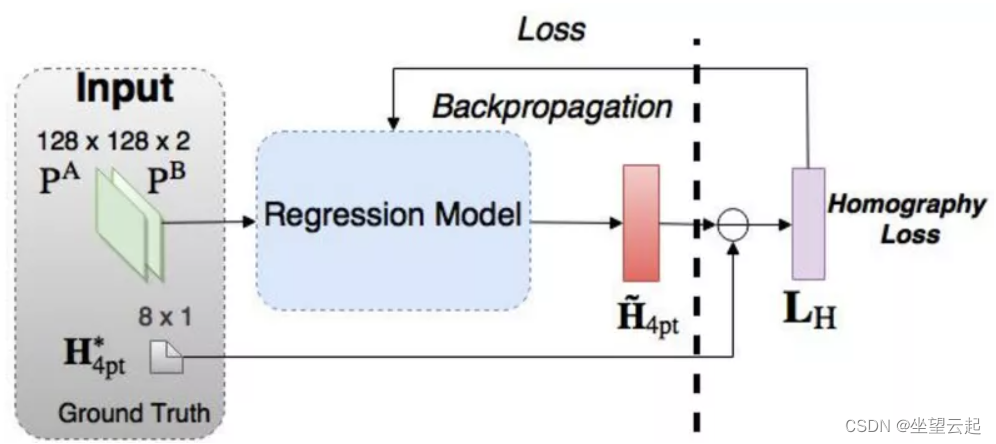
与任何监督方法一样,这种单应性估计方法 需要标记的数据对。虽然很容易获得人工图像对的地面实况单应性,但在真实数据上这样做的成本要高得多。
3、无监督学习
考虑到这一点,Nguyen 等人。提出了一种 无监督的深度图像单应性估计方法。他们保留了相同的 CNN,但必须使用 适应无监督方法的新损失函数:他们选择了 不需要真实标签的光度损失函数。相反,它计算参考图像和感测到的变换图像之间的相似性。
https://arxiv.org/pdf/1709.03966.pdf![]() https://arxiv.org/pdf/1709.03966.pdf
https://arxiv.org/pdf/1709.03966.pdf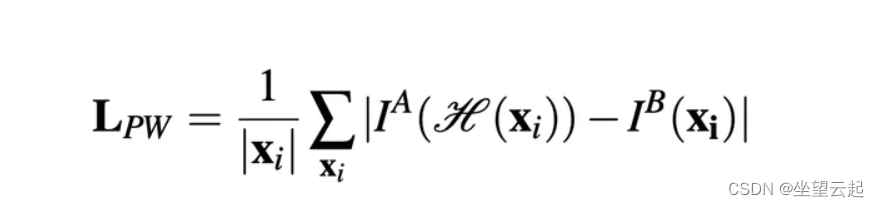
L1 光度损失函数
他们的方法引入了两种新的网络结构:张量直接线性变换和空间变换层。我们不会在这里详细介绍这些组件,我们可以简单地认为它们用于使用 CNN 模型的单应性参数输出来获得转换后的感知图像,然后我们使用它来计算光度损失。
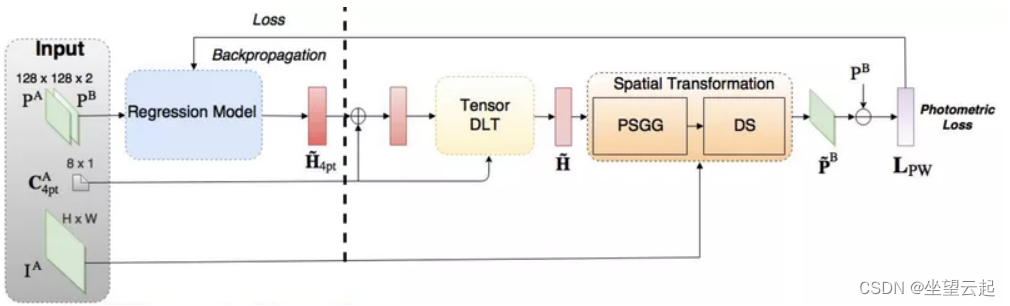
作者声称,与传统的基于特征的方法相比,这种无监督方法获得了相当或更好的精度和对光照变化的鲁棒性,推理速度更快。此外,与监督方法相比,它具有优越的适应性和性能。
四、其他方法
1、强化学习
深度强化学习作为一种医疗应用的配准方法正在获得关注。与预定义的优化算法相反,在这种方法中,我们使用 经过训练的代理来执行配准。
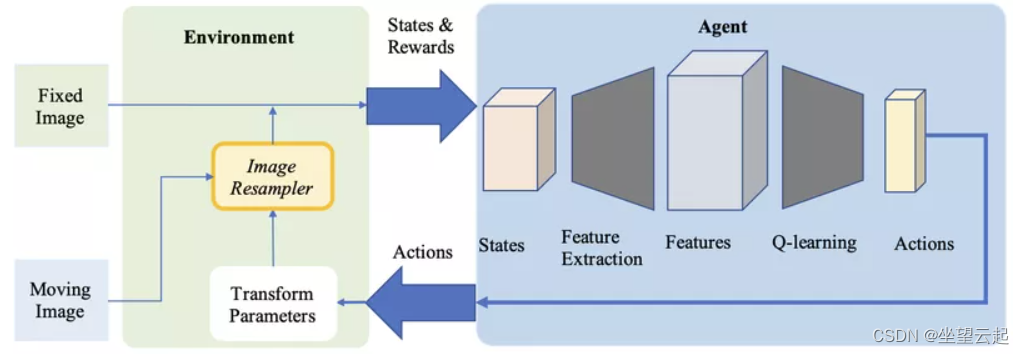
2016 年,廖等人。是第一个使用强化学习进行图像配准的人。 他们的方法 基于 端到端训练的贪心监督算法。它的目标是通过找到 最佳的运动动作序列来对齐图像。这种方法优于几种最先进的方法,但它 仅用于刚性转换。
https://arxiv.org/pdf/1611.10336.pdf![]() https://arxiv.org/pdf/1611.10336.pdf 强化学习也被用于更复杂的转换。在 通过基于代理的动作学习的鲁棒非刚性注册中,Krebs 等人。应用 人工代理来优化变形模型的参数。该方法在前列腺 MRI 图像的受试者间配准上进行了评估,并在 2-D 和 3-D 中显示出有希望的结果。
https://arxiv.org/pdf/1611.10336.pdf 强化学习也被用于更复杂的转换。在 通过基于代理的动作学习的鲁棒非刚性注册中,Krebs 等人。应用 人工代理来优化变形模型的参数。该方法在前列腺 MRI 图像的受试者间配准上进行了评估,并在 2-D 和 3-D 中显示出有希望的结果。
https://hal.inria.fr/hal-01569447/document![]() https://hal.inria.fr/hal-01569447/document
https://hal.inria.fr/hal-01569447/document
2、复杂的转换
当前图像配准研究的很大一部分涉及医学图像领域。很多时候,由于对象的局部变形 (由于呼吸、解剖结构变化等),两个医学图像之间的转换不能简单地用单应矩阵来描述。更复杂的变换模型是必要的,例如可以用位移矢量场表示的微分同胚。

研究人员试图使用 神经网络来估计这些 具有许多参数的大变形模型。
第一个例子是上面提到的 Krebs 等人的强化学习方法。
2017 年,德沃斯等人。提出了 DIRNet。它是一个使用 CNN 预测控制点网格的网络,控制点用于 生成位移矢量场 ,以根据参考图像扭曲感测图像。
https://arxiv.org/pdf/1704.06065.pdf![]() https://arxiv.org/pdf/1704.06065.pdf
https://arxiv.org/pdf/1704.06065.pdf
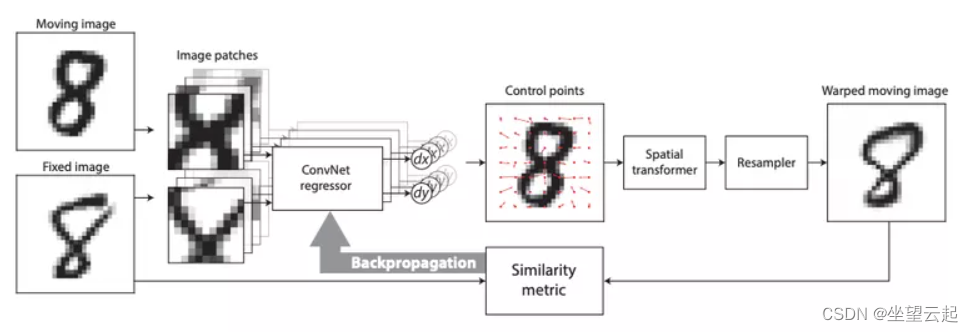
Quicksilver 注册 解决了类似的问题。Quicksilver 使用 深度编码器-解码器网络 直接在图像外观上预测补丁变形。
https://www.researchgate.net/publication/315748621_Quicksilver_Fast_Predictive_Image_Registration_-_a_Deep_Learning_Approach![]() https://www.researchgate.net/publication/315748621_Quicksilver_Fast_Predictive_Image_Registration_-_a_Deep_Learning_Approach 图像配准是一个拥有众多用例的广阔领域。关于这个主题还有很多其他的研究。
https://www.researchgate.net/publication/315748621_Quicksilver_Fast_Predictive_Image_Registration_-_a_Deep_Learning_Approach 图像配准是一个拥有众多用例的广阔领域。关于这个主题还有很多其他的研究。
文章出处登录后可见!