
文章目录
- 一、前言
- 二、安装
- 1.解压后点击启动器运行依赖,然后点击A启动器
- 2.更新本体和扩展
- 3.把controlnet1.1放入stable diffusion 中
- 三、使用界面参数
- 1.提示词
- 2.采样和迭代步数
- 3.修复和图片相关设置
- 四、使用界面模型
- 1.Controlnet
- 五、模型下载放置
- **1.模型下载**
- **2.模型安装**
- **3.模型使用**
- 六、使用技巧(探索中)
- 1.放大算法BSRGAN
- 2.LORA模型使用
- 3.大模型介绍(秋叶大佬提供)
- 4.如何使用C站复刻别人的图
- 5.最后提供一个插件
- 七、总结
个人网站 :界面图片更清晰,创作不易,麻烦点个赞!!!!感谢
进阶版: https://blog.csdn.net/weixin_62403633/article/details/130748157?spm=1001.2014.3001.5501
模型最终版: https://blog.csdn.net/weixin_62403633/article/details/131089616?spm=1001.2014.3001.5501
一、前言
稳定扩散算法(stable diffusion)可以应用于图像处理中的许多问题,例如图像去噪、图像分割、图像增强和图像恢复等。在图像去噪方面,稳定扩散算法可以通过对图像进行平滑处理来减少噪声,并保留图像的细节信息。在图像分割方面,稳定扩散算法可以通过对图像进行聚类来将图像分成不同的区域。在图像增强方面,稳定扩散算法可以通过增加图像的对比度和亮度来使图像更加清晰。在图像恢复方面,稳定扩散算法可以通过重建缺失的像素来恢复图像的完整性。
再次感谢B站秋叶大佬的整合包,小白也能放心食用,B站秋叶大佬 一键三连
链接:https://pan.baidu.com/s/1r8nv5CbYRI4p6QSue5zeoA 提取码:lj33
下面介绍使用的细节
二、安装
1.解压后点击启动器运行依赖,然后点击A启动器

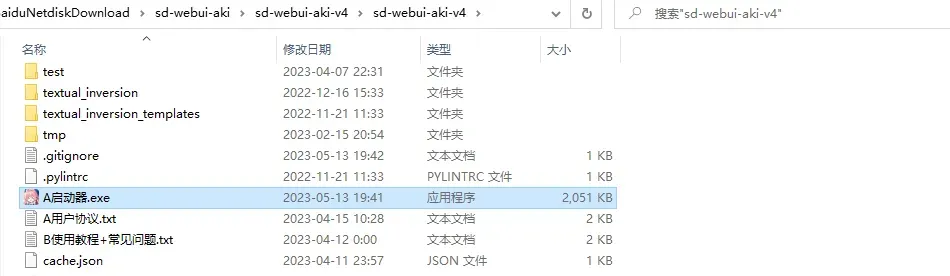
2.更新本体和扩展
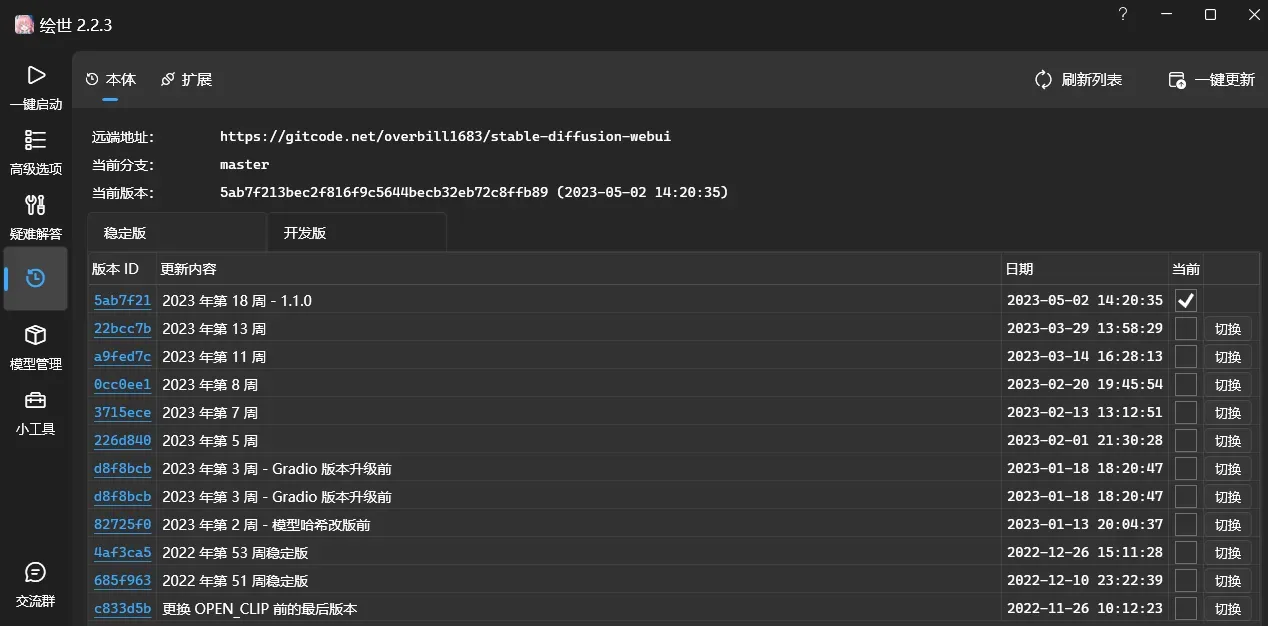
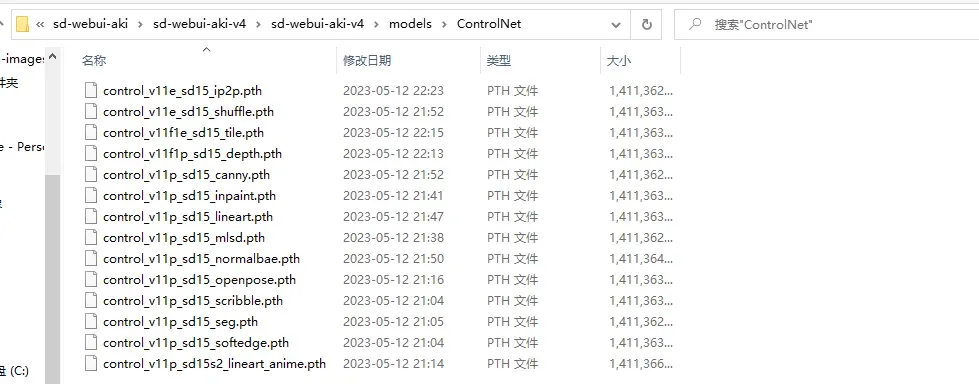
3.把controlnet1.1放入stable diffusion 中

模型里面的文件复制放入
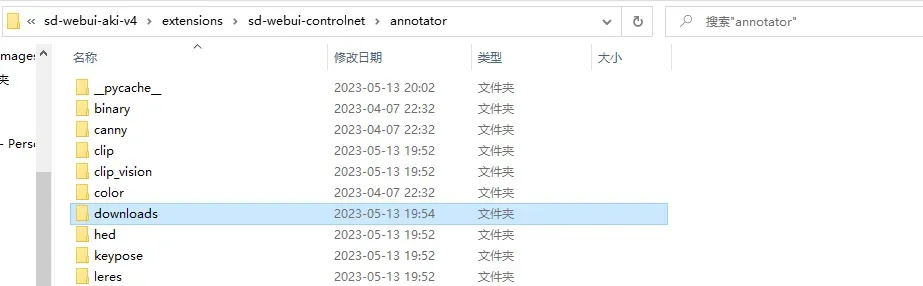
预处理器里的download放入
三、使用界面参数
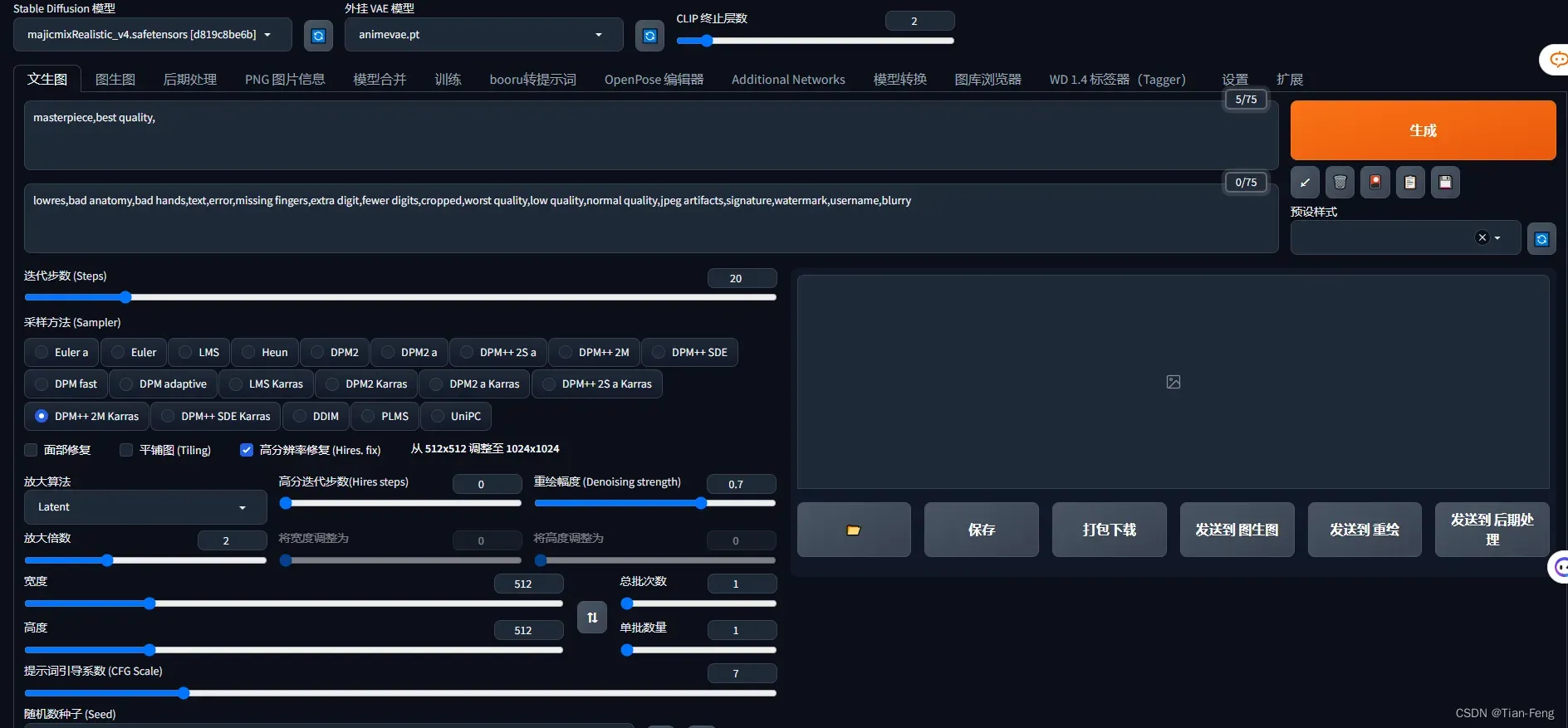
1.提示词
masterpiece,best quality,
lowres,bad anatomy,bad hands,text,error,missing fingers,extra digit,fewer digits,cropped,worst quality,low quality,normal quality,jpeg artifacts,signature,watermark,username,blurry
正向反向提示词,如果要加大提示词比重,(word:1.5) – 将权重提高 1.5 倍
2.采样和迭代步数
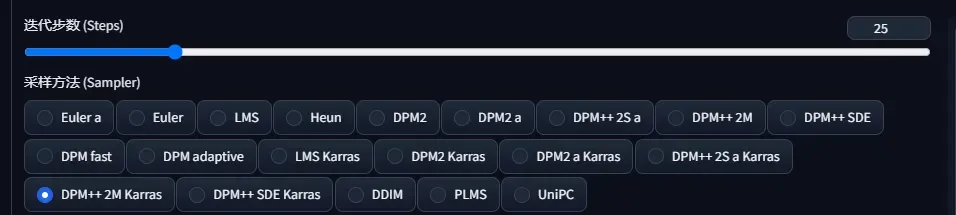
- Sampler(采样器/采样方法)
Euler a(Eular ancestral)可以以较少的步数产生很大的多样性,不同的步数可能有不同的结果。
DPM 相关的采样器通常具有不错的效果,但耗时也会相应增加。
Euler 是最简单、最快的
Euler a 更多样,不同步数可以生产出不同的图片。但是太高步数 (>30) 效果不会更好。
DDIM 收敛快,但效率相对较低,因为需要很多 step 才能获得好的结果,适合在重绘时候使用。
LMS 是 Euler 的衍生,它们使用一种相关但稍有不同的方法(平均过去的几个步骤以提高准确性)。大概 30 step 可以得到稳定结果
PLMS 是 Euler 的衍生,可以更好地处理神经网络结构中的奇异性。
DPM2 是一种神奇的方法,它旨在改进 DDIM,减少步骤以获得良好的结果。它需要每一步运行两次去噪,它的速度大约是 DDIM 的两倍,生图效果也非常好。但是如果你在进行调试提示词的实验,这个采样器可能会有点慢了。
UniPC 效果较好且速度非常快,对平面、卡通的表现较好,推荐使用。
推荐 Euler a ,DPM2++2M Karras,DPM2++SDE Karras
- 迭代步数
Stable Diffusion 的工作方式是从以随机高斯噪声起步,向符合提示的图像一步步降噪接近。随着步数增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间。增加步数的边际收益递减,取决于采样器。一般开到 20~30。
3.修复和图片相关设置
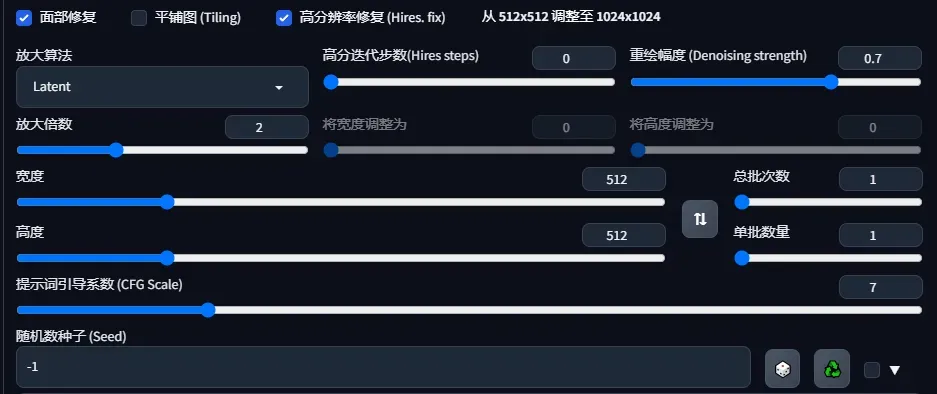
- 高清修复 默认情况下,文生图在高分辨率下会生成非常混沌的图像。如果使用高清修复,会型首先按照指定的尺寸生成一张图片,然后通过放大算法将图片分辨率扩大,以实现高清大图效果。最终尺寸为(原分辨率*缩放系数 Upscale by)。
- 面部修复 修复画面中人物的面部,但是非写实风格的人物开启面部修复可能导致面部崩坏。
- 放大算法中,Latent 在许多情况下效果不错,但重绘幅度小于 0.5 后就不甚理想。ESRGAN_4x、SwinR 4x 对 0.5 以下的重绘幅度有较好支持。
- Hires step 表示在进行这一步时计算的步数。
- Denoising strength 字面翻译是降噪强度,表现为最后生成图片对原始输入图像内容的变化程度。该值越高,放大后图像就比放大前图像差别越大。低 denoising 意味着修正原图,高 denoising 就和原图就没有大的相关性了。一般来讲阈值是 0.7 左右,超过 0.7 和原图基本上无关,0.3 以下就是稍微改一些。实际执行中,具体的执行步骤为 Denoising strength * Sampling Steps。
- CFG Scale(提示词相关性) 图像与你的提示的匹配程度。增加这个值将导致图像更接近你的提示,但它也在一定程度上降低了图像质量。 可以用更多的采样步骤来抵消。过高的 CFG Scale 体现为粗犷的线条和过锐化的图像。一般开到 7~11。 CFG Scale 与采样器之间的关系:
- 生成批次 每次生成图像的组数。一次运行生成图像的数量为“批次* 批次数量”。
- 每批数量 同时生成多少个图像。增加这个值可以提高性能,但也需要更多的显存。大的 Batch Size 需要消耗巨量显存。若没有超过 12G 的显存,请保持为 1。
- 尺寸 指定图像的长宽。出图尺寸太宽时,图中可能会出现多个主体。1024 之上的尺寸可能会出现不理想的结果,推荐使用小尺寸分辨率+高清修复(Hires fix)。
- 种子 种子决定模型在生成图片时涉及的所有随机性,它初始化了 Diffusion 算法起点的初始值。 理论上,在应用完全相同参数(如 Step、CFG、Seed、prompts)的情况下,生产的图片应当完全相同。
四、使用界面模型
1.Controlnet
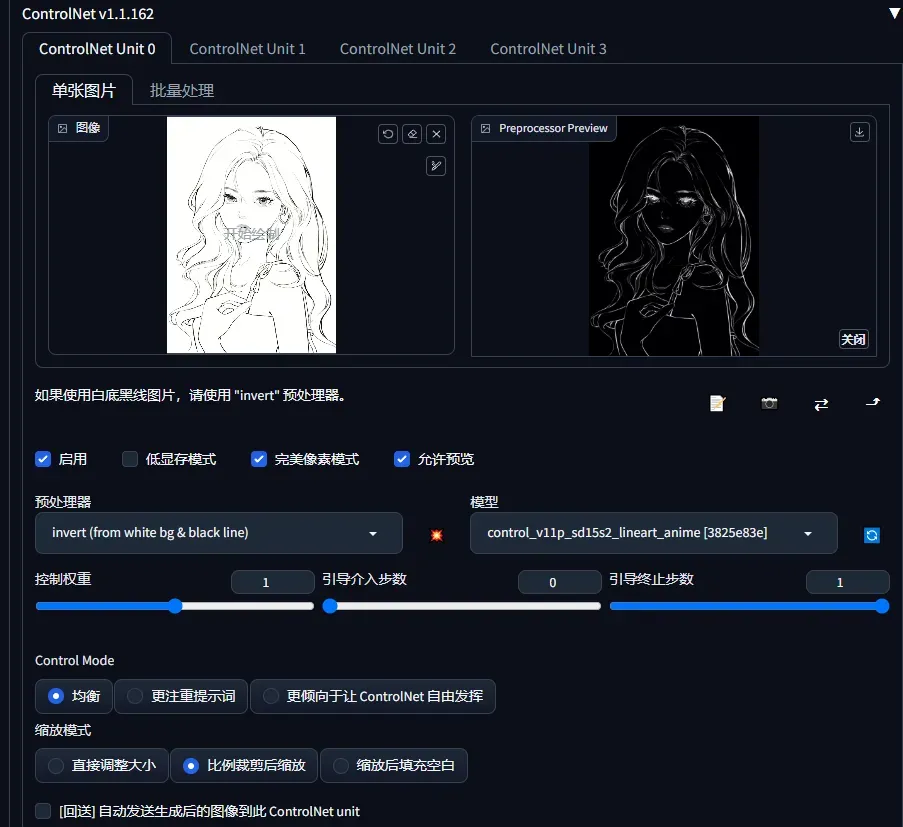
Controlnet 允许通过线稿、动作识别、深度信息等对生成的图像进行控制。
- 点击 Enable 启用该项 ControlNet
- Preprocessor 指预处理器,它将对输入的图像进行预处理。如果图像已经符合预处理后的结果,请选择 None。譬如,图中导入的图像已经是 OpenPose 需要的骨架图,那么 preprocessor 选择 none 即可。
- 在 Weight 下,可以调整该项 ControlNet 的在合成中的影响权重,与在 prompt 中调整的权重类似。Guidance strength 用来控制图像生成的前百分之多少步由 Controlnet 主导生成,这点与[:]语法类似。
预处理器(只是一部分)
- Invert Input Color 表示启动反色模式,如果输入的图片是白色背景,开启它。
- RGB to BGR 表示将输入的色彩通道信息反转,即 RGB 信息当做 BGR 信息解析,只是因为 OpenCV 中使用的是 BGR 格式。如果输入的图是法线贴图,开启它。
- Low VRAM 表示开启低显存优化,需要配合启动参数“–lowvram”。
- Guess Mode 表示无提示词模式,需要在设置中启用基于 CFG 的引导。
- Model 中请选择想要使用解析模型,应该与输入的图像或者预处理器对应。请注意,预处理器可以为空,但模型不能为空。
- canny 用于识别输入图像的边缘信息。
- depth 用于识别输入图像的深度信息。
- hed 用于识别输入图像的边缘信息,但边缘更柔和。
- mlsd 用于识别输入图像的边缘信息,一种轻量级的边缘检测。 它对横平竖直的线条非常敏感,因此更适用于于室内图的生成。
- normal 用于识别输入图像的法线信息。
- openpose 用于识别输入图像的动作信息。
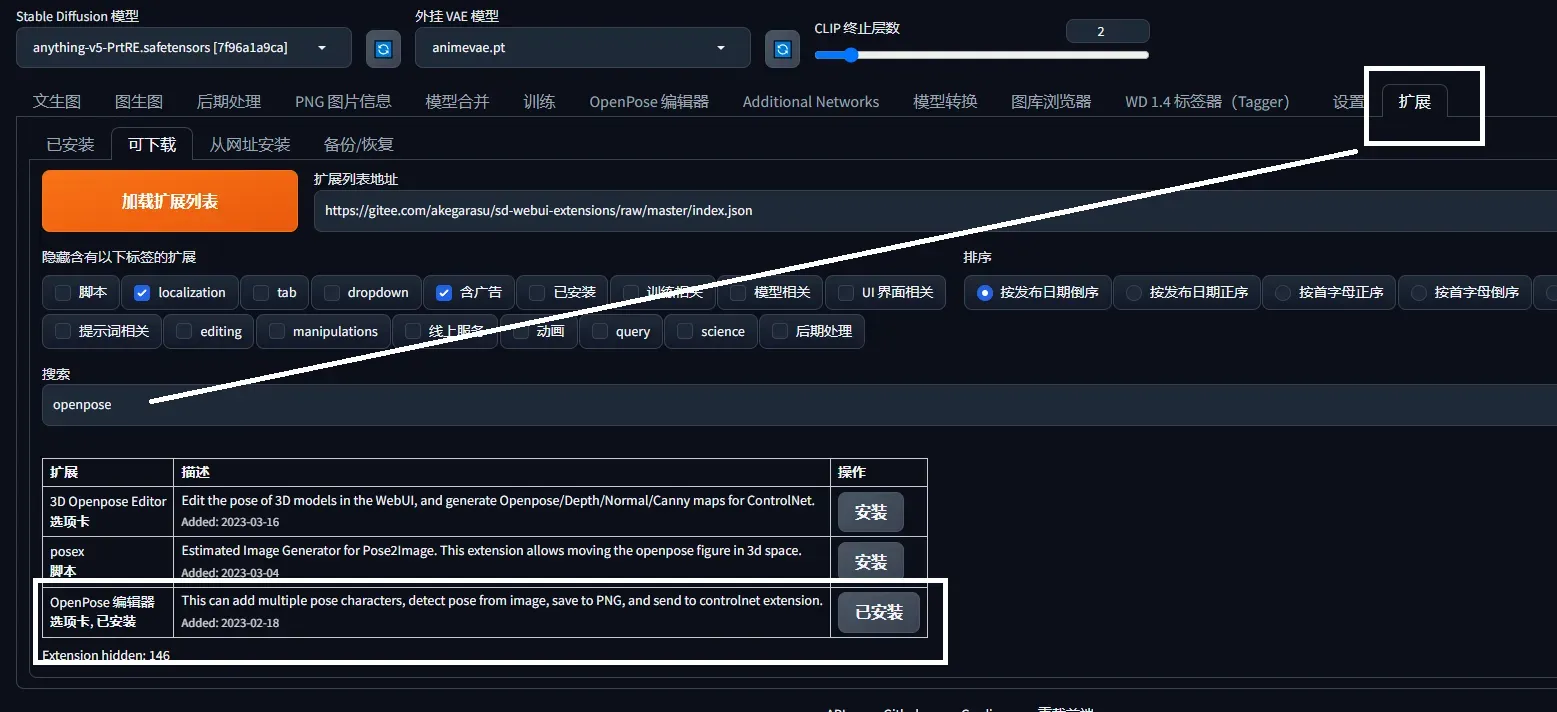
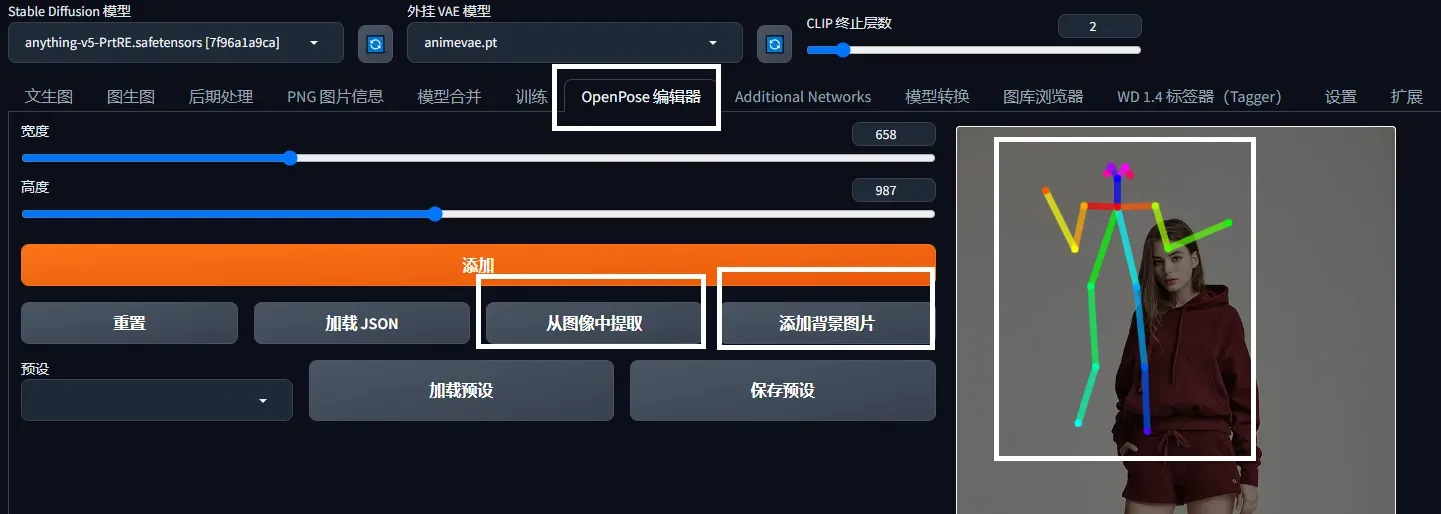
- OpenPose Editor 插件可以自行修改姿势,导出到文生图或图生图。
- scribble 将输入图像作为线稿识别。如果线稿是白色背景,务必勾选“Invert Input Color”
- fake_scribble 识别输入图像的线稿,然后再将它作为线稿生成图像。
- segmentation 识别输入图像各区域分别是什么类型的物品,再用此构图信息生成图像。
controlnet1.1模型
线稿上色
Invert Input Color
control_v11p_sd15s2_lineart_anime

control_v1le_sd15_ip2p
提示词需要写指令,例如make it night变为夜晚同时,可以也增加一些夜晚的tag。这个需要调低CFG,低到5以下,不稳定,酌情使用

tile_resample
control_v11fle_sd15_tile
神必特性:
·忽略图像中的细节并生成新的细节
·如果局部的内容与全局提示词不匹配,则忽略掉提示词,根据周围的图片尝试去推断局部的内容
带来的效果:
·图生图的功能,让画面更好的融合的功能(比如P上去一个物品,Tie可以推断周围融合)
·增加细节的功能
如果你直接拉大分辨率再用Tle,那他就可以有放大图片的功能
·配合其他图片放大器(例如后处理里面的放大,可以很好的修复因为放大导致的细节问题


姿态控制
openpose + control_openpose
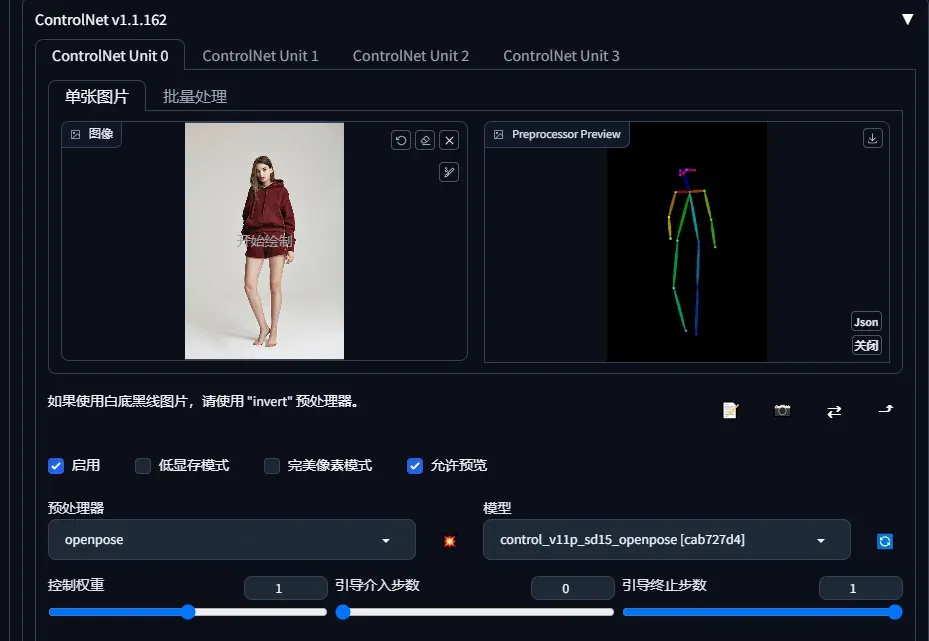

还可以对姿态编辑,在扩展下载openpoe,对姿态图关键点拖动成自己想要的姿势
嵌入式(Embedding)模型:yaguru magiku +LORA:GuoFeng3.2 Lora

五、模型下载放置
1.模型下载
模型能够有效地控制生成的画风和内容。 常用的模型网站有:
Civitai | Stable Diffusion models, embeddings, hypernetworks and more Models – Hugging Face SD – WebUI 资源站 元素法典 AI 模型收集站 – AI 绘图指南 wiki (aiguidebook.top) [AI 绘画模型博物馆 (subrecovery.top)]
2.模型安装
下载模型后需要将之放置在指定的目录下,请注意,不同类型的模型应该拖放到不同的目录下。 模型的类型可以通过Stable Diffusion 法术解析检测。
- 大模型(Ckpt):放入 models\Stable-diffusion
- VAE 模型: 一些大模型需要配合 vae 使用,对应的 vae 同样放置在 models\Stable-diffusion 或 models\VAE 目录,然后在 webui 的设置栏目选择。
- Lora/LoHA/LoCon 模型:放入 extensions\sd-webui-additional-networks\models\lora,也可以在 models/Lora 目录
- Embedding 模型:放入 embeddings 目录
- hypernetwork中文名:超网络。它的功能与embedding、lora类似,都是会对图片进行针对性的调整,可以简单的理解为低配版的lora,所以它的适用范围比较窄,但是它对画面风格的转换是easy的,也可以生成特定的模型和人物。在C站右侧筛选列筛选hypernetwork,就可以看到所有的超网络模型了,在其中挑选自己喜欢的就好。models\hypernetworks
3.模型使用
- Checkpoint(ckpt)模型 对效果影响最大的模型。在 webui 界面的左上角选择使用。一些模型会有触发词,即在提示词内输入相应的单词才会生效。
- Lora 模型 / LoHA 模型 / LoCon 模型,
对人物、姿势、物体表现较好的模型,在 ckpt 模型上附加使用。 在 webui 界面的 Additional Networks 下勾线 Enable 启用,然后在 Model 下选择模型,并可用 Weight 调整权重。权重越大,该 Lora 的影响也越大。 不建议权重过大(超过 1.2),否则很容易出现扭曲的结果。
多个 lora 模型混合使用可以起到叠加效果,譬如一个控制面部的 lora 配合一个控制画风的 lora 就可以生成具有特定画风的特定人物。 因此可以使用多个专注于不同方面优化的 Lora,分别调整权重,结合出自己想要实现的效果。
LoHA 模型是一种 LORA 模型的改进。
LoCon 模型也一种 LORA 模型的改进,泛化能力更强。
- Embedding
对人物、画风都有调整效果的模型。在提示词中加入对应的关键词即可。大部分 Embedding 模型的关键词与文件名相同,譬如一个名为为“SomeCharacter.pt”的模型,触发它的关键词检索“SomeCharacter”。
六、使用技巧(探索中)
1.放大算法BSRGAN
栗子:1024×1024—》3072×3072

2.LORA模型使用
LOAR模型:就是别人训练好的模型,加载别人的模型就会使自己生成图片往别人训练好的风格上调整
启动器界面提供了LORA模型下载,或者去c站下载放到models/Lora 目录下,上面说过。重启客户端
随便写点提示词,之前的正反向提示词,使用一个国风模型,或者Additional Networks启用LORA
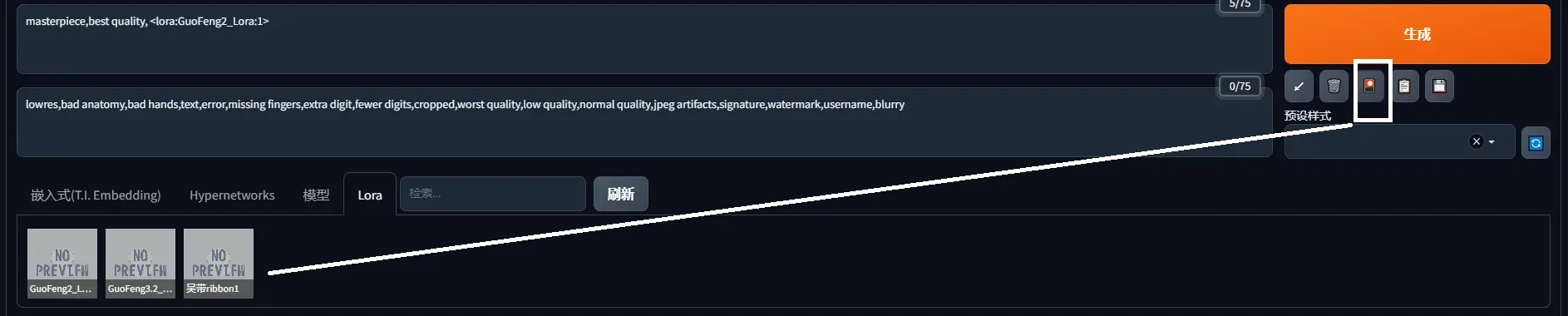
GuoFeng3.2 Lora 结果:为啥图片这么顶呢,绝对没有搞yellow

hanfu-v3.0-ming

hanfu-v3.0-song

MoXin-1.0

RainbowLinesStyle-linev1

Shukezouma-1.1

3.大模型介绍(秋叶大佬提供)
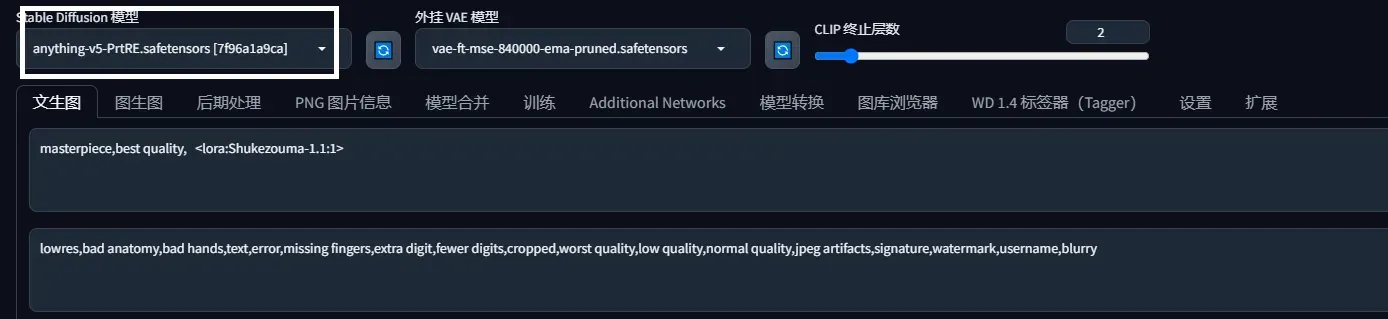
现在使用的大模型anything-v5-PrtRE

Counterfeit-V2.5

Pastel-Mix

AbyssOrangeMix2

Cetus-Mix

4.如何使用C站复刻别人的图
https://civitai.com/
右上角可以选择不同的模型下载,然后放到模型文件路径下,前面讲过不同模型路径放置
将参数填入我们的界面中
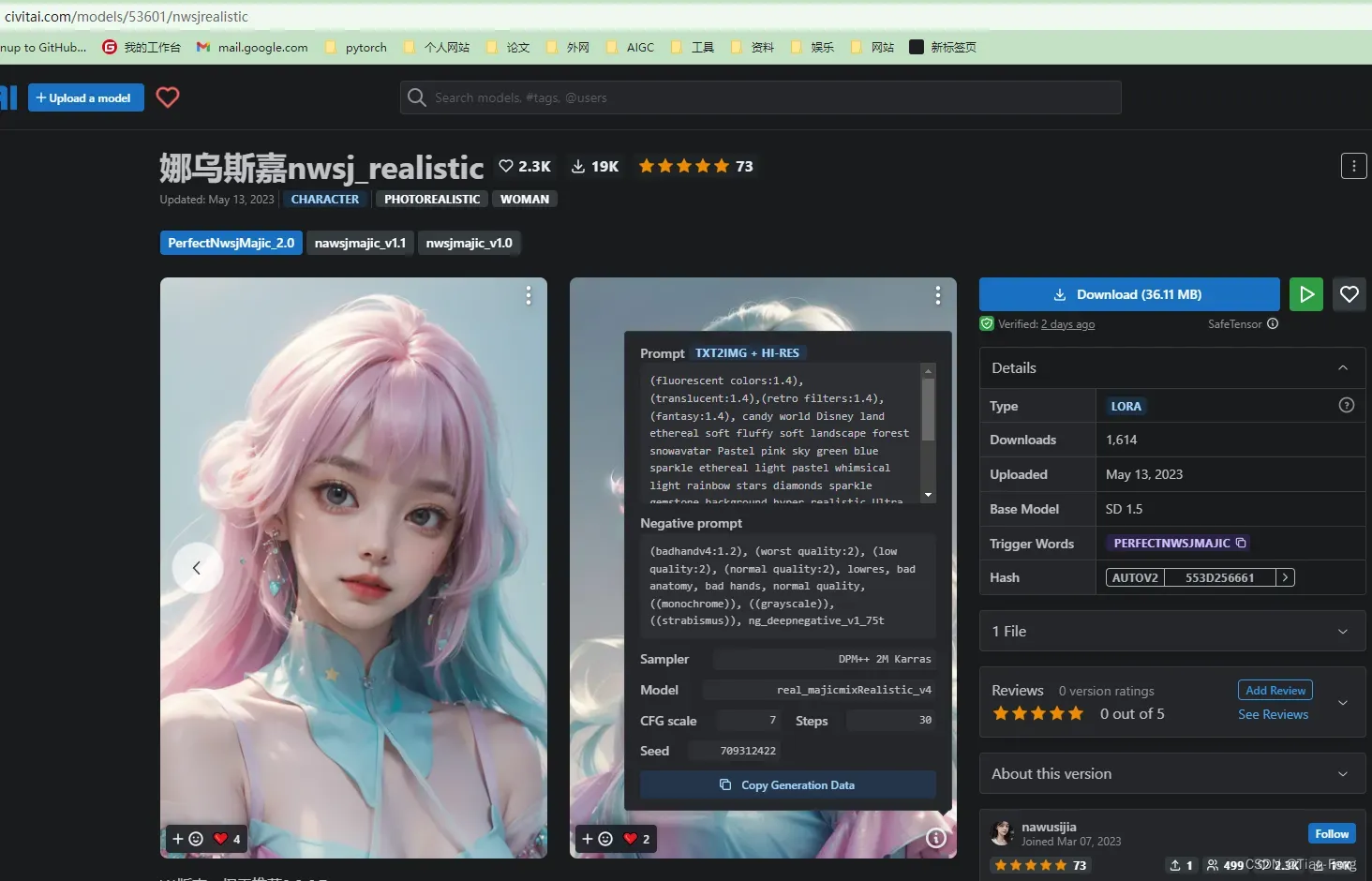
majicMIX realistic 大模型
如果你要图片信息,下图操作,然后发送到文生图
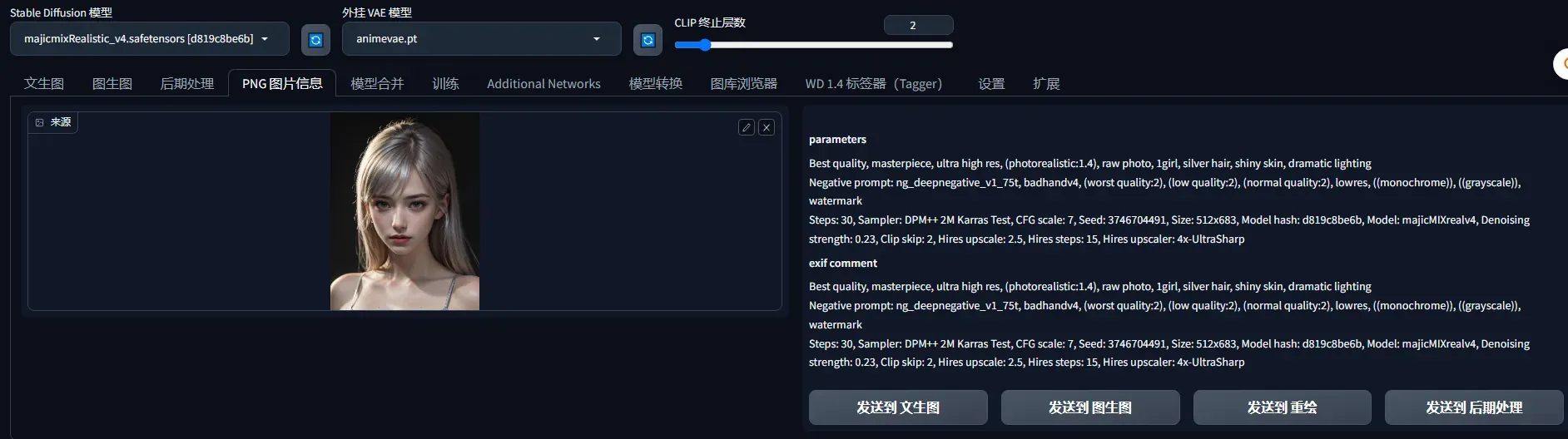


majicMIX realistic +FilmGirl(LORA)

majicMIX fantasy

nwsj_realistic

5.最后提供一个插件
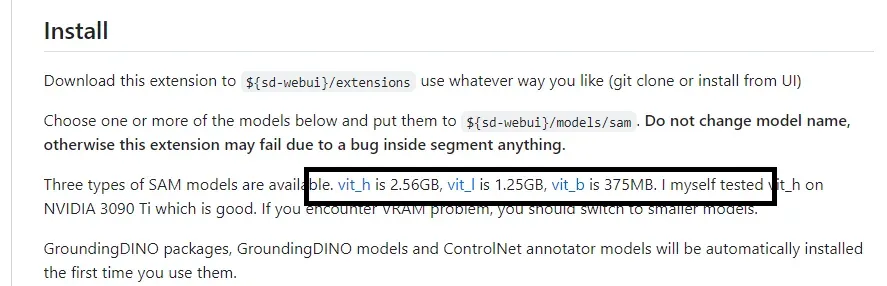
用于图像分割的然后可以输入提示词变成你想要的样子,类似于p图,下面是github地址,里面有详细文档,下载代码和权重文件即可,8G显存选vit_l 1.25GB,分别放入
\sd-webui-aki-v4\extensions
\sd-webui-aki-v4\extensions\sd-webui-segment-anything-master\models\sam
https://github.com/continue-revolution/sd-webui-segment-anything
七、总结
- 模型下载放入文件夹
- 就是把参数填入,做调整,每个参数都会影响结果
- 使用单独的LORA模型,大模型单独试试结果,然后融合看看有什么奇效
- controlnet用法其实非常多,在细节方面有很多体现,期待你去炼丹
- 后面持续更新
文章出处登录后可见!