背景
CRF和HMM是有相似性的,最后都是使用Verterbi算法来进行最优状态转移序列的确定。CRF主要用与序列的标注问题。
本质:通过1D卷机学习近邻信息,然后输入到CRF定义好的计算方式中
CRF原理理解
下图代表了我们的序列连接和预测。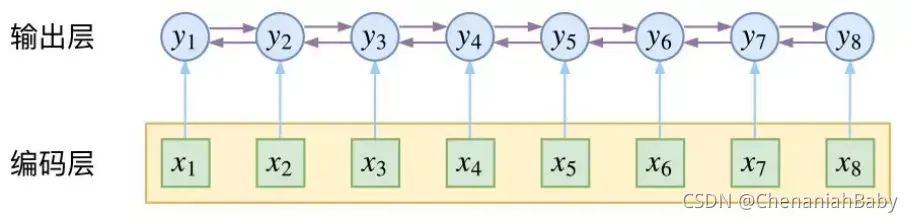
CRF是进行了假设,一共两个假设,如下:

在上述表示中,的相邻位置是
。
尽管已经做了大量简化,但一般来说,(3) 式所表示的概率模型还是过于复杂,难以求解。于是考虑到当前深度学习模型中,RNN 或者层叠 CNN 等模型已经能够比较充分捕捉各个 y 与输出 x 的联系,因此,我们不妨考虑函数 g 跟 x 无关,那么: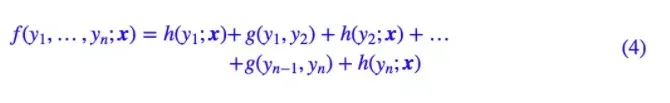
引入时间序列模型(RNN做卷积),与
之间的关系直接用
去考虑。 这时候
实际上就是一个有限的、待训练的参数矩阵而已,而单标签的打分函数
我们可以通过 RNN 或者 CNN 来建模。因此,该模型是可以建立的,其中概率分布变为:
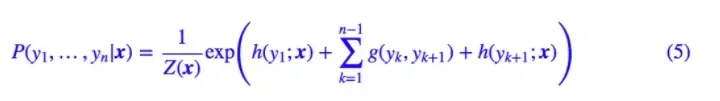
算法步骤
重点:相比于HMM,要进行模型训练。HMM直接打标签了,这里对每个句子中的词通过0,1,2,3,4打了标签。
具体步骤
卷积层:通过一维卷积获取邻域信息。
CRF层:训练概率转移矩阵(B,M,E,S), 概率矩阵被初始化得到。之后通过与ground true的lable相乘计算得到。
预测层:计算概率转移矩阵(B,M,E,S),总共16个值,这一步在代码分析中,是通过网路计算出来的, 在CRF自定义的网络层。
结果层:模型训练完成之后再通过verterbi算法找最优解。
代码理解
分子的计算
def path_score(self, inputs, labels):
"""计算目标路径的相对概率(还没有归一化)
要点:逐标签得分,加上转移概率得分。
技巧:用“预测”点乘“目标”的方法抽取出目标路径的得分。
"""
point_score = K.sum(K.sum(inputs * labels, 2), 1, keepdims=True) # 逐标签得分
labels1 = K.expand_dims(labels[:, :-1], 3)
labels2 = K.expand_dims(labels[:, 1:], 2)
labels = labels1 * labels2 # 两个错位labels,负责从转移矩阵中抽取目标转移得分
trans = K.expand_dims(K.expand_dims(self.trans, 0), 0)
trans_score = K.sum(K.sum(trans * labels, [2, 3]), 1, keepdims=True)
return point_score + trans_score # 两部分得分之和
这里的计算主要是公式的以下部分,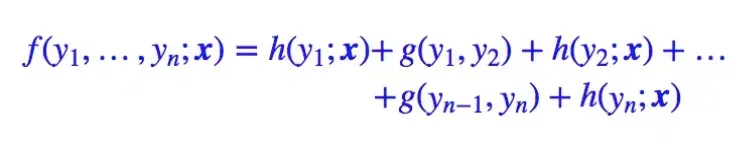
分母的计算

outputs = K.logsumexp(states + trans, 1)
这包含公式右半部分的两个元素的对应乘积。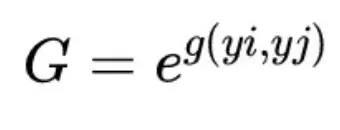
这里注意一下,这两个指数的相乘在代码中, 利用rnn的递归特性进行求解。
def log_norm_step(self, inputs, states):
"""递归计算归一化因子
要点:1、递归计算;2、用logsumexp避免溢出。
技巧:通过expand_dims来对齐张量。
inputs is predictive label, input is h
init_states (128, 4)
"""
#states[0] is (128,4)
inputs, mask = inputs[:, :-1], inputs[:, -1:]
#上边语句执行后 inputs shape is [128,4], mask shape is [128,1] 相当于每一个每一个句子中的第一个词
states = K.expand_dims(states[0], 2) # (batch_size, output_dim, 1) (128, 4, 1)
#print("states shape:", states.shape)
trans = K.expand_dims(self.trans, 0) # (1, output_dim, output_dim) (1, 4, 4)
# states+trans shape is (128,4,4), first exp, then sum, last to get log, 下面这一步表示了图转移
outputs = K.logsumexp(states + trans, 1) # (batch_size, output_dim)
#outputs is [128,4]
outputs = outputs + inputs
#outputs is [128,4], states[:,:,0] is [128,4]
outputs = mask * outputs + (1 - mask) * states[:, :, 0]
print("states[:,:,0].shape",states[:,:,0].shape)
return outputs, [outputs]
内容链接
https://www.cnblogs.com/gczr/p/10021249.html
https://www.jiqizhixin.com/articles/2018-05-23-3 (CRF实现附带链接)
https://blog.csdn.net/dianwei0041/article/details/101882673?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-2.control(为什么要用CRF)
https://zhuanlan.zhihu.com/p/29989121
文章出处登录后可见!