源代码:
因为刚开始写,所以只写了一部分。
简易KNN
def GetKNNSoreByN(X, y, n_neighbors):
"""
:param X: data 特征值
:param y: aim 目标值
:param n_neighbors K值
:return: score 预测结果
"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
transform = StandardScaler()
X_train = transform.fit_transform(X_train)
X_test = transform.fit_transform(X_test)
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
y_pre = clf.predict(X_test)
return sum(y_pre == y_test) / y_pre.shape[0]
解释:这里数据标准化使用的是StandardScaler、对传进来的数据集进行了切割,实际上数据足够多的话没必要进行切割,但这里考虑到数据较少的情况进行了切割。
网格搜索版KNN
def GetKNNScoreByGridSearchCV(X, y, param_grid: dict={'n_neighbors': [i for i in range(1,10,1)]}):
"""
:param X:data 特征值
:param y:aim 目标值
:param param_grid: GridSearchCV param 传递给GridSearchCV的参数
:return: best params and best score for KNN最好的参数表以及最佳准确率
"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
transform = StandardScaler()
X_train = transform.fit_transform(X_train)
X_test = transform.fit_transform(X_test)
estimator = KNeighborsClassifier()
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=5, verbose=0)
estimator.fit(X_train, y_train)
return estimator.best_params_, estimator.best_score_
说明:默认的CV为5,verbose=0,这个是经验判断,若有好的建议,可以一起讨论
补充:一般情况K值不超过10,所以默认值给的1到10
正则版线性回归
def linear_model_regular(data):
"""
regular
:param data: data 数据
:return: coef 系数列表, intercept 截距, error 均方误差
"""
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=0)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = LinearRegression()
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
error = mean_squared_error(y_test, y_predict) # 均方误差
return estimator.coef_, estimator.intercept_, error
梯度下降版线性回归:
def linear_model_gradient(data):
"""
gradient descent
:param data: data 数据
:return: coef 系数列表, intercept 截距, error 均方误差
"""
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=0)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = SGDRegressor(max_iter=1000)
estimator.fit(x_train, y_train)
y_predict = estimator.predict(x_test)
error = mean_squared_error(y_test, y_predict) # 均方误差
return estimator.coef_, estimator.intercept_, error
防止重复库
def setup_module(module):
"""
Prevent multiple uses of the same library
"""
# Check if a random seed exists in the environment, if not create one.
_random_seed = os.environ.get('SKLEARN_SEED', None)
if _random_seed is None:
_random_seed = np.random.uniform() * np.iinfo(np.int32).max
_random_seed = int(_random_seed)
print("I: Seeding RNGs with %r" % _random_seed)
np.random.seed(_random_seed)
random.seed(_random_seed)
安装方法和更新命令
安装
pip install techlearn
更新
pip3 install --upgrade techlearn
测试代码和截图(部分)
KNN&鸢尾花
X, y = datasets.load_iris(return_X_y=True)
param_grid = {'n_neighbors': [1, 3, 5, 7]}
print(GetKNNSoreByN(X, y, 3))
print(GetKNNScoreByGridSearchCV(X, y, param_grid=param_grid))
print(GetKNNScoreByGridSearchCV(X, y))

线性回归&波士顿房价预测
data = load_boston()
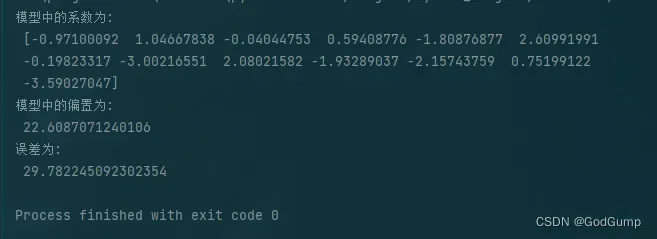
coef_, intercept_, error = linear_model_gradient(data=data)
print("模型中的系数为:\n", coef_)
print("模型中的偏置为:\n", intercept_)
print("误差为:\n", error)
文章出处登录后可见!
已经登录?立即刷新