原文摘要
主流的序列转录模型(由一个序列生成另外一个序列)主要依赖于RNN或CNN网络,其中也包括编码器-解码器的架构模型。性能较好的模型通常在编码器-解码器之间使用注意力机制。本文提出了一个简单的架构——Transformer。这个模型完全依赖注意力机制,并不依赖于循环或者卷积。通过两个实验证明该模型的并行度更好、可以使用更少的时间训练。
一、Transformer提出的意义
在时序模型中,此前最常用的是基于RNN的LSTM和GRU模型。对于RNN的序列计算,如果序列是一个句子,那么对于第t个词会计算出一个输出:隐藏状态ht,其中ht是由前一层隐藏状态ht-1和第t个词本身决定,而历史信息可以通过ht-1学习。但RNN具有两个缺点,首先RNN是一步一步进行的时序过程,难以并行,计算性能会变差。第二,因为历史信息是通过时序一步一步向后传递,如果时序较长,早期的时序信息容易丢失。本文提出的Transformer模型不再使用循环层而仅仅通过注意力机制完成学习。
二、模型架构
在序列模型中,编码器-解码器的使用具有很好的效果。对于编码器:将输入(x1,x2,…xn)编码为同样长度的Z=(z1,z2,…,zn),其中zt是第t个词的向量表示,也是编码器的输出。对于解码器:将编码器的输出作为输入生成序列(y1,y2,…,ym),n和m可以同样长度可以不同长度。在解码器中模型是自回归的,其中过去时刻的输出会作为当前时刻的输入。
Transformer使用编码器-解码器架构,将self-attention、point-wise和fully connected layers堆砌起来的。
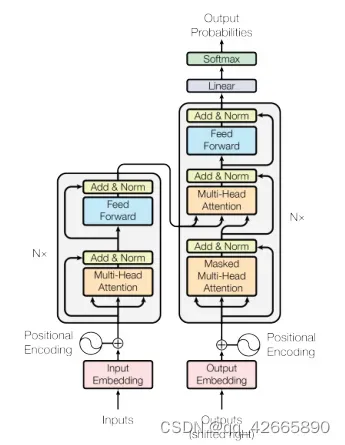
1.编码器
Input进入嵌入层将其表示为向量,编码器有N=6层垛在一起,每层中包括2个子层(1)multi-head self-attention (2)position-wise fully connected feed-forward network(MLP)。每个子层用残差链接,最后使用layer normalization。
公式:LayerNorm(x+Sublayer(x)).每层输出维度dmodel=512。
2.LayerNorm
变长应用中不使用BatchNorm。
二维:batch、feature
BatchNorm对每个batch 的feature的均值变0,方差变1。
LayerNrom对每个样本的均值变0,方差变1。
三维:batch、seq(n)、feature(512)
BatchNorm:在样本长度变化较大时,小批量计算时均值方差抖动较大。并且在遇到训练时没遇到的较长序列,使用预训练好的均值方差不能较好计算。
LayerNrom:每个样本自己算均值方差,不管样本长短,相对更稳定。
3.解码器
与编码器相同,同样有N=6层垛在一起,每层中包括3个子层,其中前两个层与编码器中一致,第三层是一个multi-head self-attention。每个子层用残差链接,最后使用layer normalization。有一点不同,解码器是自回归:当前的输入是上面时刻的输出,也就是说在预测时并不能看到后续时刻的输出。但在注意力机制中每次可以看到整个完整的输入,因此要通过带掩码的注意力机制(Masked)避免该情况发生。Masked保证在t时间不会看到t时间之后的输入,保证训练和预测行为一致。
4.具体定义注意力层
注意力函数是将一些query和一些key-value对映射成一个输出的函数。query、key、value都是向量,具体说output是value的加权和,因此output维度与value维度一致,其中value的权重由每个value对应的key与query的相似度(compatibility function)计算而来。
(1)Scaled Dot-Product Attention(点乘除根号dk)
query和key 维度等长等于dk,value维度等于dv,对query和key做内积作为相似度。除以根号dk,再放入softmax得到n个非负的加起来和为1 的权重,再将权重作用到value得到输出。其中query可以写成矩阵Q,Q=[n,dk],K=[m,dk]。–>nm。V=[m,dv]。–>ndv
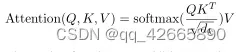
当dk较大时,计算得到的相对差距会变大,最大的值的softmax会更靠近1,剩下的值更加靠近0,值会像两端靠拢,梯度会比较小。
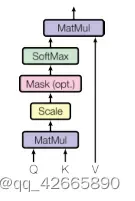
mask主要避免在t时间看到后面的内容,保证在计算权重时不用算后面的内容。
(2) Multi-Head Attention
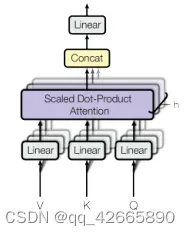
将query、key、value进入线性层投影到低维投影h次,再做h次的注意力函数,每个函数的输出合并再线性投影输出得到最终输出。计算公式:h=8

因为残差需要维度相同,所以投影的是输出维度/h:512/8=64。
5.在Transformer中如何使用注意力
(1)编码器的注意力:n个长为d的向量。注意力层由3个输入:query、key、value。(一根线复制三次代表同样内容既作为query又作为key还作为value–自注意机制),输入n个query会有n个输出,维度也为d。输出为value的加权和。输出:n个长为d的向量。
(2)解码器注意力(下):与编码器相同,添加一个masked,作用是使得后面的权重设为0。
(3)解码器注意力(上):不是自注意力,key和value来自编码器的输出, query来自解码器注意力(下)。输出:m个长为d的向量。得到的输出是value的加权和,加权是query和key的相似度。目的是在编码器中找到与query最相关的内容。
Position-wise Feed-Forward Networks
6.Position-wise Feed-Forward Networks
输入的序列有很多词,每个词是一个点,就是一个position。mlp对每个词作用一次,作用每个词的都是同一个mlp。MLP只作用在最后一个维度。线性-Relu-线性。512–>2048–>512

详解:输入为长为n的一些向量,进入attention后会得到同样长度的输出(attention就是对输入进行加权和),后进入MLP(权重相同),每个MLP对输入点运算得到整个transformer块的输出。
attention的作用是将序列中的信息抓取出来做汇聚。
7.Embeddings and Softmax
把输入的词映射成维度为dmodel=512的向量,其中两个嵌入层和预softmax线性变换之间共享相同的权重矩阵。在嵌入层中,我们将这些权重乘以根号dmodel,因为在学习embedding时,会把每个向量的L2Norm学成相对较小,如果学成1则不管维度多大都会等于1 ,如果维度大则学到的权重值会很小。目的是放大一下,保证与后面编码大小差不多。
8.Positional Encoding
attention不具有时序信息,因为输出是value的加权和,与序列信息无关。因此需要在输入加入时序信息。例如词在句子中的位置(1,2,3,4,5)。
一个词在嵌入层会表示为长为512维的向量,同样用512维向量表示数字1234567890。具体值由周期不一致的sin\cos函数计算出的。
将嵌入向量与位置向量相加
三、总结
(1)Transformer模型是第一个仅使用注意力进行序列转录的模型,通过使用multi-headed self-attention代替循环层。
(2)对于翻译任务,Transformer的训练速度比基于循环层或卷积层的结构快得多,并且效果较好。
(3)计划将Transformer模型扩展到其他任务中。
文章出处登录后可见!