《繁凡的深度学习笔记》第 2 章 回归问题与神经元模型(DL笔记整理系列)
https://fanfansann.blog.csdn.net/
https://github.com/fanfansann/fanfan-deep-learning-note
作者:繁凡
version 1.0 2022-1-20
声明:
1)《繁凡的深度学习笔记》是我自学完成深度学习相关的教材、课程、论文、项目实战等内容之后,自我总结整理创作的学习笔记。写文章就图一乐,大家能看得开心,能学到些许知识,对我而言就已经足够了 ^q^ 。
2)因个人时间、能力和水平有限,本文并非由我个人完全原创,文章部分内容整理自互联网上的各种资源,引用内容标注在每章末的参考资料之中。
3)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除,非常感谢各位为知识传播做出的贡献!
4)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
5)本文由我个人( CSDN 博主 「繁凡さん」(博客) , 知乎答主 「繁凡」(专栏), Github 「fanfansann」(全部源码) , 微信公众号 「繁凡的小岛来信」(文章 P D F 下载))整理创作而成,且仅发布于这四个平台,仅做交流学习使用,无任何商业用途。
6)「我希望能够创作出一本清晰易懂、可爱有趣、内容详实的深度学习笔记,而不仅仅只是知识的简单堆砌。」
7)本文《繁凡的深度学习笔记》全汇总链接:《繁凡的深度学习笔记》前言、目录大纲 https://fanfansann.blog.csdn.net/article/details/121702108
8)本文的Github 地址:https://github.com/fanfansann/fanfan-deep-learning-note/ 孩子的第一个 『Github』!给我个 嘛!谢谢!!o(〃^▽^〃)o
9)此属 version 1.0 ,若有错误,还需继续修正与增删,还望大家多多指点。本文会随着我的深入学习不断地进行完善更新,Github 中的 P D F 版也会尽量每月进行一次更新,所以建议点赞收藏分享加关注,以便经常过来回看!
本章话题(点击即可跳转哟):
话题 11 :训练过程中如何避免陷入局部最优解?如何逃离鞍点?
话题 12 : 趣味话题:有时候我们没办法直接计算梯度,可以尝试估计梯度大小吗?- 有限差分法与对称导数法(选学)
话题 13 :什么是最小二乘法?如何使用最小二乘法解决线性回归问题?
话题 14 :道理我都懂,怎么用代码实现并解决神经元线性模型呢?
话题 15 :线性模型已经完全学会了!如果换成非线性的模型该怎么办呢?
《繁凡的深度学习笔记》第 2 章 回归问题与神经元模型
回归分析(Regression Analysis)是一种统计学上分析数据的方法,目的在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来 预测 (prediction)研究者感兴趣的变量。在自然科学和社会科学领域,回归经常用来表示 输入和输出之间的关系 。
在机器学习领域中的大多数任务通常都与 预测 有关。 当我们进行回归分析,想要预测一个预测值在连续的实数范围内时,我们称之为 回归问题 。常见的例子有:预测房价 / 股票、预测需求 / 销量等。但不是所有的 预测 都是回归问题。在下一章节中,我们将介绍 分类问题 。分类问题的目标是预测数据属于一组类别中的哪一种,也即预测预测值属于某一段连续的实数区间的方法。
统计学中的回归分析方法一般有 线性回归(简单线性回归、复回归、对数线性回归)、非线性回归、对数几率回归、偏回归、自回归(自回归滑动平均模型、差分自回归滑动平均模型、向量自回归模型)。本章主要探讨线性回归与非线性回归,对于其他更多的回归方法仅给出一些简单的介绍,更多详细讲解、代码实现及其应用,详见《繁凡的机器学习笔记》。
线性回归
在回归问题中,如果使用线性模型去逼近真实模型,那么我们把这一类方法叫做线性回归(Linear Regression),线性回归是回归问题中的一种具体的实现。
线性回归基于几个简单的假设:首先,假设自变量 和因变量
之间的关系是线性的,即
可以表示为
中元素的加权和,这里通常允许包含观测值的一些噪声;其次,我们假设任何噪声都比较正常,如噪声遵循正态分布 (NormalDistribution)
。
简单线性回归(simple linear regression),在统计学中指只有一个解释变量的线性回归模型。往往是以单一变量预测,用于判断两变量之间相关的方向和程度。
复回归分析(multiple regression analysis),也称多变量回归,是简单线性回归的一种延伸应用,用以了解一个因变量与两组以上自变量的函数关系。
对数线性回归(Log-linear model),是将自变量和因变量都取对数值之后再进行线性回归,所以根据自变量的数量,可以是对数简单线性回归,也可以是对数复回归。
非线性回归
非线性回归(non-linear regression),是回归函数关于未知回归系数具有非线性结构的回归。
对数几率回归
对数几率回归(Logistic Regression),又称逻辑回归,是一种对数几率模型(英语:Logit model,又译作逻辑模型、评定模型、分类评定模型)是离散选择法模型之一,属于多重变量分析范畴,是社会学、生物统计学、临床、数量心理学、计量经济学、市场营销等统计实证分析的常用方法。关于对数几率回归的更多讲解,详见**《繁凡的深度学习笔记》 第 3 章 分类问题与信息论基础 3.2 逻辑回归**。
自回归模型
自回归模型(Autoregressive model),简称AR模型,是统计上一种处理时间序列的方法,用同一变数例如 的之前各期,亦即
至
来预测本期
的表现,并假设它们为一线性关系。因为这是从回归分析中的线性回归发展而来,只是不用
预测
,而是用
预测
(自己);所以叫做自回归。
2.1 线性回归
我们在 话题 2 中已经讲解过了什么是线性回归,我们继续深入探讨,考虑如何解决线性回归问题。
2.1.1 线性模型
考虑一个实例:作为一个有志青年,我们想要预测未来的城市房价!我们希望可以根据房屋的面积和房龄来估算房屋的价格。为了开发一个能预测房价的模型,我们首先需要收集一个真实的数据集。这个数据集包括了房屋的销售价格、面积和房龄。在机器学习的术语中,通常将数据集称之为 训练数据集(training data set)或 训练集(training set)。其中数据集内的每行数据(这里就是与一次房屋交易相对应的各种数据)称为样本(sample),或 数据点(data point)或 数据样本(data instance)。将我们想要预测的目标(这里显然是房屋的价格)称之为标签(label)或目标(target)。预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
通常,我们使用 或者
来表示数据集中的样本数。对索引为
的样本,其输入表示为
,其对应的标签是
。
这里线性回归的线性假设指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:
式中的 和
称为权重(weight),
称为偏置(bias),或称为偏移量(offset)、截距(intercept)。
权重决定了每个特征对我们预测值的影响。偏置是指当所有特征都取值为 时,预测值应该为多少。如果没有偏置项,我们模型的表达能力将受到限制。 严格来说,上式是输入特征的一个仿射变换(affine transformation)。仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项来进行平移(translation)。
至此问题就变为了:给定一个数据集,我们的目标是寻找模型的权重 和偏置
,使得根据模型做出的预测大体符合数据里的真实价格。输出的预测值由输入特征通过线性模型的仿射变换决定,仿射变换由所选权重和偏置确定。显然我们只需要求出符合实际情况的模型参数
,就可以得到一个可以大致预测房屋价格的线性模型。这种模型被发现与人类的神经元模型十分吻合,我们考虑从神经元模型的角度出发解决上面的问题。
2.2 神经元模型
2.2.1 神经元
神经元(Neuron),即神经元细胞(Nerve Cell),是神经系统最基本的结构和功能单位。如图 2.1 所示,典型的生物神经元结构分为细胞体和突起两大部分。成年人大脑中包含了约 1000 亿个神经元,每个神经元通过树突获取输入信号,通过轴突传递输出信号,神经元之间相互连接构成了巨大的神经网络,从而形成了人脑的感知和意识基础。
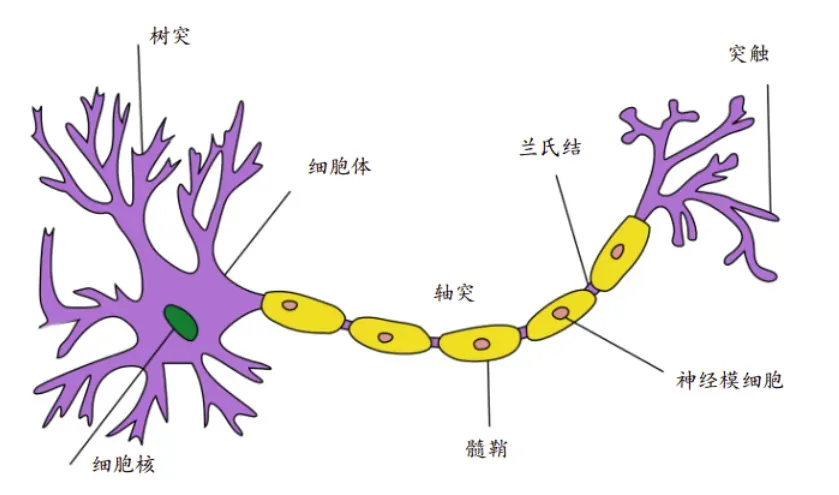
在神经元中,树突中接收到来自其他神经元或视网膜等环境传感器的信息 。该信息通过突触权重
来加权,以确定输入的影响(即通过设置突触权重的大小,使
与
相乘 来 激活 或 抑制该输入信息)。 来自多个源的加权输入以加权和
的形式汇聚在细胞核中,然后将这些信息发送到轴突
中进一步处理,通常会通过
进行一些非线性处理。之后,它要么到达目的地(例如肌肉),要么通过树突进入另一个神经元(一层又一层地组成神经网络)。
考虑将生物神经元 (Neuron) 的模型抽象成具体的数学模型得到 神经元模型:对于神经元的输入向量 ,经过函数映射:
后得到输出
,其中
为函数
自身的参数。考虑一种简化的情况,即线性变换,对于两个列向量
,我们希望可以计算得到类似神经元模型
的值,我们可以将其中一个列向量转置之后相乘:
,展开为标量形式:
上式可以直观地展示为如图 2.2 所示:
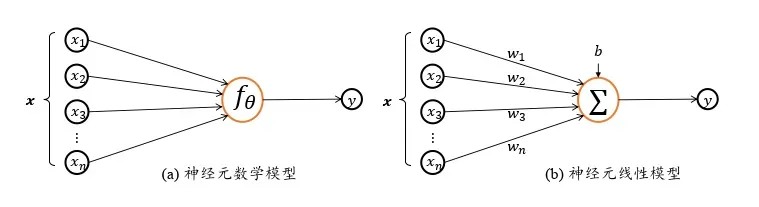
参数 确定了神经元的状态,通过固定 𝜃 参数即可确定此神经元的处理逻辑。当神经元输入节点数
也即单输入时,神经元数学模型可进一步简化为:
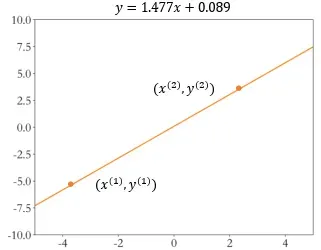
此时我们可以绘制出神经元的输出 和输入
的变化趋势,如图 2.3 所示,随着输入信号
的增加,输出电平
也随之线性增加,其中
参数可以理解为直线的斜率 (Slope),
参数为直线的偏置 (Bias)。
我们知道 个点确定
次项多项式,
个点确定
元一次方程(最小二乘法), 显然对于一个单输入向量,我们只需要观测得到两个不同数据点,就可求得单输入线性神经元模型的参数。同样的,对于
输入的现象神经元模型,只需要观测采样
组不同数据点即可得到所有参数,似乎就此线性神经元模型可以得到完美的解决。那么上述方法是否存在着什么问题呢?
考虑对于任何采样点,都有可能存在观测误差。我们假设观测误差变量 属于均值为
,方差为
的正态分布 (NormalDistribution) 或高斯分布 (Gaussian Distribution):
,那么我们观测采样得到的样本符合:
其中正态分布概率密度函数如下:
我们发现一旦引入观测误差以后,即使简单如线性模型,如果仅采样两个数据点,可能会带来较大 估计偏差 。如图 2.4 所示,图中的数据点均带有观测误差,如果基于蓝色矩形块的两个数据点进行估计,则计算出的蓝色虚线与真实橙色直线存在较大偏差。
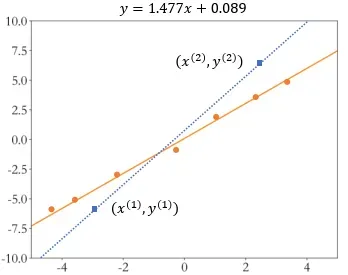
为了减少观测误差引入的估计偏差,可以通过采样多组数据样本集合 ,然后找出一条 “最好” 的直线,使得它尽可能地让所有采样点到该直线的 误差 (Error) 或 损失 (Loss) 之和最小即可。
也就是说,由于观测误差 的存在,当我们采集了多个数据点
时,可能不存在一条直线完美的穿过所有采样点。因此我们希望能找到一条比较 “好” 的位于采样点中间的直线,这个过程就叫做 拟合(fit)。
为了判别拟合出的直线是不是 “好” 的,我们需要确定一个拟合程度的度量,因此人们提出了 损失函数 来进行衡量。
损失函数(loss function),又称 代价函数(cost function),是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。损失函数 能够量化目标的实际值与预测值之间的差距。通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为 。
回归问题中常用的损失函数有平方和误差、均方根误差、平均绝对值误差、平滑平均绝对误差等。
均方误差 (Mean Squared Error, MSE)
首先一个很自然的想法就是,求出当前模型的所有采样点上的预测值 与真实值
之间的差的平方和作为总误差
。当样本
的预测值为
(通常使用“尖角”hat 符号表示估计值、预测值),其相应的真实标签为
时,平方和误差可以定义为:
在训练模型时,我们希望搜索到一组参数( ),这组参数能最小化在所有训练样本上的总损失
,其对应的直线就是我们要寻找的最优直线:
其中 表示采样点的个数。这种误差计算方法称为均方误差 (Mean Squared Error) 简称 MSE。
即:
均方根误差(Root Mean Square Error, RMSE)
均方根误差,也叫回归系统的拟合标准差,是 的平方根,容易受异常点(误差很大的点)影响,易朝减小异常点误差的方向行进而牺牲总体性能。
平均绝对误差(Mean Absolute Error, MAE)
绝对值误差的平均值,由于导数是常数,不利于梯度下降法更新。且该函数在 处不可微。
平滑平均绝对误差(HuberLoss)
Huber Loss 是一个用于回归问题的带参损失函数,结合了 和
的优点, 优点是能增强
对离群点的鲁棒性,对异常点不会特别敏感同时在
处也可微。当预测偏差小于
时,它采用平方误差,当预测偏差大于
时,采用的线性误差。也正因如此,我们需要不断地调整超参数
,也因此带来一些不便。
回到问题本身,我们这里选择均方差作为损失函数解决线性神经元模型问题。我们需要找出最优参数 (Optimal Parameter) ,使得输入和输出满足线性关系
。但是由于观测误差
的存在,需要通过采样足够多组的数据样本组成的数据集 (Dataset):
,来找到一组最优的参数
使得均方差
最小即可。
2.2.2 优化方法
经过上面内容的学习,我们对深度学习进行一次简单的总结。在传统的监督机器学习中,往往会给出训练数据集 ,如 (输入图像,输出标签) 对。我们希望训练一个预测模型
,参数化
,通过求解下式得到参数的全局最优解:
其中 是上一小节介绍的用于测量真实标签与
预测的标签之间的误差的损失函数。 我们通过评估具有已知标签的多个测试点来测量泛化能力。
如何求解最优化的参数是我们需要解决的问题。暴力查找最优的参数带来的时间空间复杂度显然是不能接受的,为此人们发明了无数种优化算法来予以解决。优化算法的功能是通过改善训练方式来最优化损失函数,可以加快收敛速度,使得训练的时间更短,还可以获得更优的损失函数。
深度学习中的优化算法有很多,例如梯度下降算法、动量法、AdaGrad算法、RMSProp算法、Adadelta算法、Adam算法等。我们这里着重介绍最简单的一种优化方法:梯度下降算法,以及另一种可以高效解决线性回归问题的经典算法:最小二乘法。其余优化算法详解详见 《繁凡的深度学习笔记》第 7 章 过拟合、优化算法与参数优化 7.9 优化算法
2.2.2.1 梯度下降算法
梯度下降算法(Gradient Descent)是神经网络训练中最常用的优化算法,配合强大的图形处理芯片 GPU 的并行加速能力,非常适合优化海量数据的神经网络模型,自然也适合优化我们这里的神经元线性模型。这里先简单地应用梯度下降算法,以及如何使用它解决神经元模型预测的优化问题。
我们在高中都学过导数 (Derivative) 的概念,如果要求解一个函数的极大、极小值,可以简单地令导数函数为 ,求出对应的自变量点 (称为驻点) ,再检验驻点类型即可。以函数
为例,我们绘制出函数及其导数在
的区间曲线,其中蓝色实线为
,黄色虚线为
。可以看出,函数导数为
的点即为
的临界点(critical point)或 驻点(stationary point),函数的极大值和极小值点均出现在驻点中。
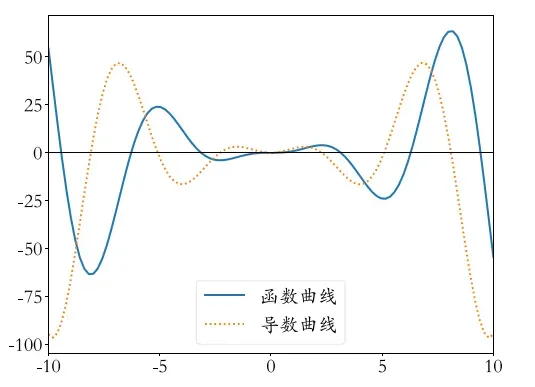
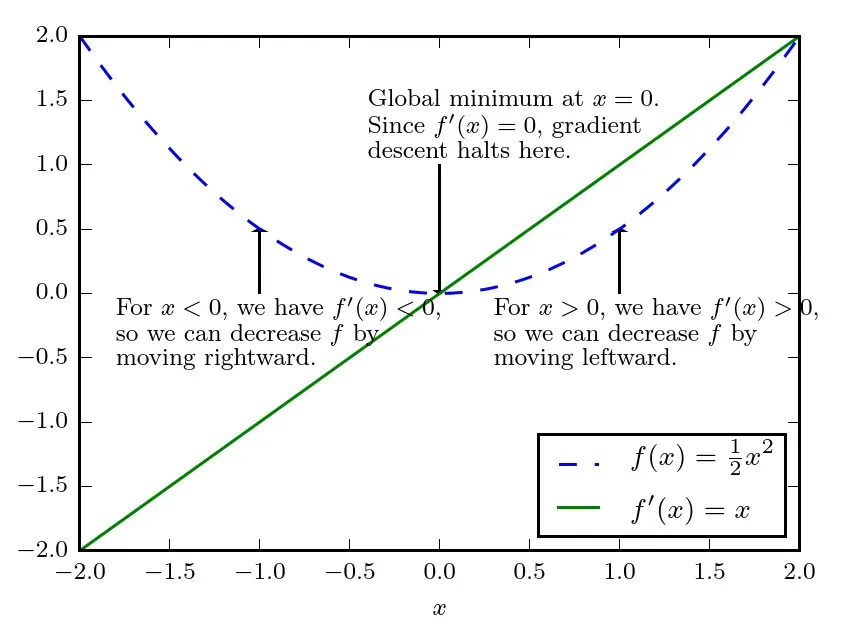
导数 代表
在点
处的斜率。换句话说,它表明如何缩放输入的小变化才能在输出获得相应的变化:
。因此导数对于最小化一个函数很有用,因为它告诉我们如何更改
来略微地改善
。例如,我们知道对于足够小的
来说,
是比
小的。因此我们可以将
往导数的反方向移动一小步来减小
。这种技术被称为 梯度下降(gradient descent)。
函数的梯度(Gradient)定义为函数对各个自变量的偏导数(Partial Derivative)组成的向量。考虑 维函数
,函数对自变量
的偏导数记为
可以衡量点
处只有
增加时
如何变化。 梯度是相对一个向量求导的导数:
的导数是包含所有偏导数的向量,记为
。函数对自变量y的偏导数记为
,则梯度
为向量
。对于多维的情况下,梯度的第
个元素是
关于
的偏导数。此时的临界点是梯度中所有元素都为零的点。我们通过一个具体的函数来感受梯度的性质。
如图 2.2.7 所示, ,图中
平面的红色箭头的长度表示梯度向量的模,箭头的方向表示梯度向量的方向。可以看到,箭头的方向总是指向当前位置函数值增速最大的方向,函数曲面越陡峭,箭头的长度也就越长,梯度的模也越大。
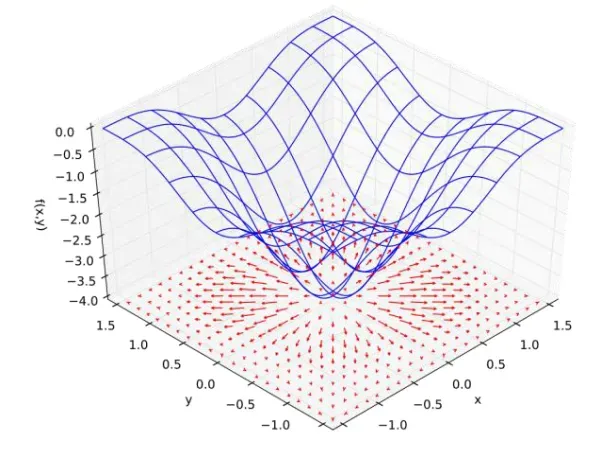
通过上面的例子,我们能直观地感受到,函数在各处的梯度方向 总是指向函数值增大的方向,那么梯度的反方向
应指向函数值减少的方向。
我们规定在 (单位向量)方向的 方向导数(directional derivative)是函数
在
方向的斜率。也即方向导数是函数
关于
的导数(在
时取得)。使用链式法则,我们可以发现当
时,
。
为了最小化 ,我们希望找到使
下降得最快的方向。计算方向导数:
其中 是
与梯度的夹角。将
代入,并忽略与
无关的项,就能简化得到
。这在
与梯度方向相反时取得最小。换句话说,梯度向量指向上坡,
负梯度向量指向下坡。我们在负梯度方向上移动可以减小 。这被称为最速下降法(method of steepest descent)或 梯度下降(gradient descent)。
综上所述我们按照
来迭代更新 ,即可获得越来越小的函数值,其中
是一个确定步长大小的正标量,用来缩放梯度向量,被称为 学习率(learning rate)。
学习率决定了目标函数能否收敛到局部最小值,以及何时收敛到最小值。 学习率 可由算法设计者设置。一般设置为某较小的值,如
等。 请注意,如果我们使用的学习率太小,将导致
的更新非常缓慢,需要更多的迭代。
例如,考虑同一优化问题中 的进度。 如图 2.8 所示,尽管经过了
次训练,我们仍然离最优解很远。
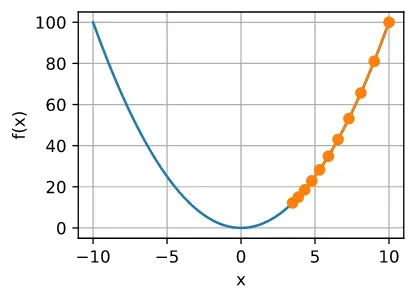
相反,如果我们使用过高的学习率,对于一阶泰勒展开式可能太大。在这种情况下,
的迭代不能保证降低
的值。 例如,当学习率为
时,
超出了最优解
并逐渐发散。

我们可以通过几种不同的方式选择 。普遍的方式是选择一个小常数。有时我们通过计算,选择使方向导数消失的步长。还有一种方法是根据几个
计算
,并选择其中能产生最小目标函数值的
。这种策略被称为 线搜索 (line search)。
对于一个一维函数而言,选择好学习率 之后,向量形式的
就退化成了标量形式:
通过上式迭代更新 若干次,这样得到的
处的函数值
,总是更有可能比在
处的函数值
小。
通过上面公式优化参数的方法称为梯度下降算法,它通过循环计算函数的梯度 并更新待优化参数
,从而得到函数
获得极小值时参数
的最优数值解。需要注意的是,在深度学习中,一般
表示模型输入,模型的待优化参数一般用
等符号表示。
现在我们将应用梯度下降算法来求解 参数。这里要最小化的是均方差误差函数
:
需要优化的模型参数是 和
,因此我们按照
的方式循环更新参数即可。
梯度下降算法为什么可以优化目标函数呢?下面给出简单证明:
考虑一类连续可微实值函数 , 利用泰勒展开,我们可以得到
即在一阶近似中, 可通过
处的函数值
和一阶导数
得出。 我们可以假设在负梯度方向上移动的
会减少
。 为了简单起见,我们选择固定步长
,然后取
。 将其代入泰勒展开式我们可以得到
如果其导数 没有消失,我们就能继续展开,这是因为
。 此外,我们总是可以令
小到足以使高阶项变得不相关。 因此,
这意味着,如果我们使用
来迭代 ,函数
的值可能会下降。 因此,在梯度下降中,我们首先选择初始值
和常数
, 然后使用它们连续迭代
,直到停止条件达成,达到全局最小值(全局最优解)或局部最小值后停止。表现在图像上如图 2.10 所示:
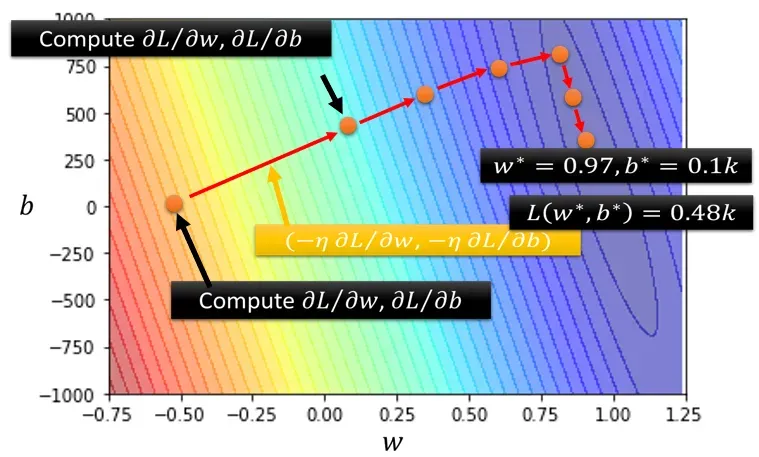
局部最优解
注意到我们刚刚提到了全局最优解与局部最优解的概念,那么他们分别是什么意思呢?全局最优解可以理解为我们需要解决的问题,在全值域范围内最优。那么局部最优解就是指对于一个问题的解在一定范围或区域内最优,或者说解决问题或达成目标的手段在一定范围或限制内最优。我们显然更希望得到全局最优解而不是局部最优解:
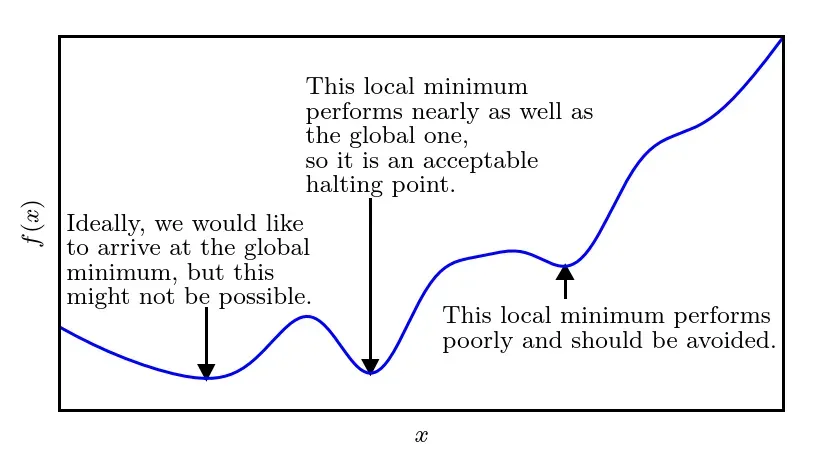
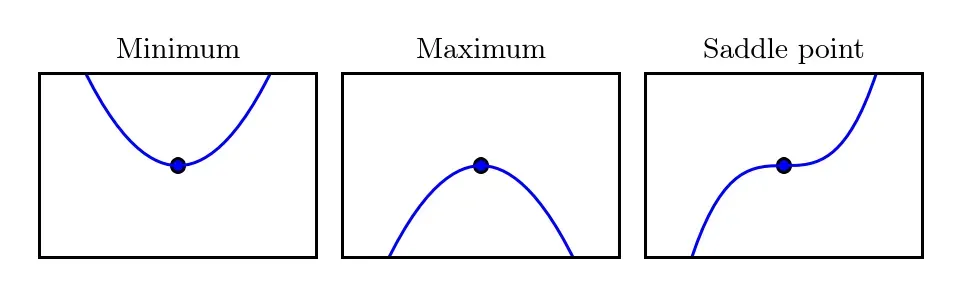
在梯度下降的过程中,如果落入局部最优解之中,将会陷入其中无法脱出。根据上图我们可以很清晰地发现,局部最优解处正是 的临界点,此时的导数无法提供往哪个方向移动的信息。一个 局部极小点(local minimum)意味着这个点的
小于所有邻近点,因此不可能通过移动无穷小的步长来减小
。一个 局部极大点(local maximum)意味着这个点的
大于所有邻近点,因此不可能通过移动无穷小的步长来增大
。更可怕的是,有些临界点既不是最小点也不是最大点,由于这个临界点特殊的地形,同样会导致梯度下降算法被困在其中,这些点被称为 鞍点(saddle point)。各种临界点如下图所示:
话题 11 :训练过程中如何避免陷入局部最优解?如何逃离鞍点?
我们在训练的过程中,肯定想要避免陷入局部最优解,及时逃离鞍点。对于梯度下降算法而言,可以通过自适应学习率、动量等方法进行优化,进而衍生出了各种优化算法如:Adagrad、RMSprop、stochastic GD(SGD)等方法。他们逃离鞍点的效果如下图所示:
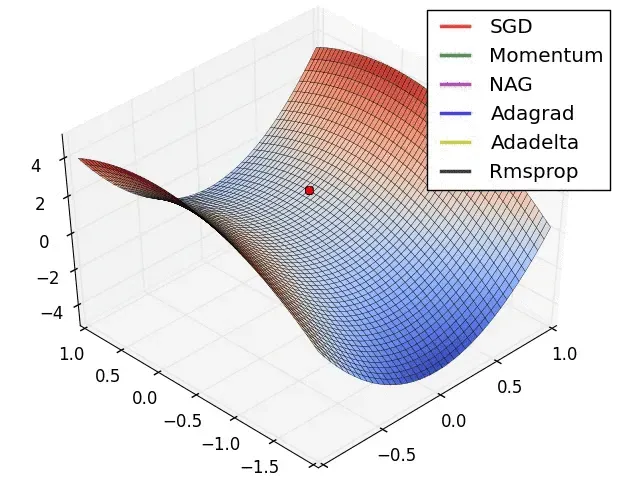
我们将在 《繁凡的深度学习笔记》第 7 章 过拟合、优化算法与参数优化 7.9 优化算法 中对这些拓展的优化算法进行进一步的深入探讨。
2.2.2.1.1 Jacobian 和 Hessian 矩阵(选学)
我们将在 《繁凡的深度学习笔记》第 7 章 过拟合、优化算法与参数优化 7.9 优化算法 中更进一步地深入探讨梯度下降算法,并对Jacobian 和 Hessian 矩阵进行详细讲解。
2.2.2.1.2 有限差分法与对称导数法估计梯度大小(选学)
话题 12 : 趣味话题:有时候我们没办法直接计算梯度该怎么办呢?可以尝试估计梯度大小吗?- 有限差分法与对称导数法(选学)
有限差分法
在数学中,有限差分法(finite-difference methods,FDM),是一种微分方程数值方法,是通过有限差分来近似导数,从而寻求微分方程的近似解。有时我们不能直接获取梯度值,就可以使用有限差分法,根据导数的定义,取极限的方法来获得对梯度的估计。
有限差分法的推导
首先假设要近似函数的各级导数都有良好的性质,依照泰勒定理,可以形成以下的泰勒展开式:
其中 表示是
的阶乘,
为余数,表示泰勒多项式和原函数之间的差。可以推导函数
一阶导数的近似值:
设定 ,可得:
除以 可得:
求解:
假设 相当小,因此可以将 “f” 的一阶导数近似为:
对称导数
在数学中,对称导数(symmetric derivative)是对普通导数的推广。它被定义为:
极限下的表达式有时称为对称差商(symmetric difference quotient.)。如果函数的对称导数存在于该点, 则称该函数在点 处 对称可微。 如果一个函数在一点上是可微的(在通常意义上),那么它也是对称可微的,但反之则不成立。
二阶对称导数
二阶对称导数定义为
如果存在(通常的)二阶导数,则二阶对称导数存在并且等于它。然而,即使(普通)二阶导数不存在,二阶对称导数也可能存在。例如,考虑符号函数 ,其定义为
符号函数在零处不连续,因此对于 不存在。但是二阶对称导数存在于
:
估计梯度
在论文 CCS 2017 ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models[14]中,对于待攻击的黑盒模型,无法获得被攻击模型的损失函数的梯度 ,作者提出可以使用有限差分法来估计梯度。
首先我们先对输入 进行扰动:
,其中常量
。
是标准单位向量。记模型的输出为
,文中利用对称差商得到梯度的估计值:
在增加一次查询之后即可获得二阶信息:
获得了这两个梯度估计值以后,即可直接对 进行梯度下降优化。
利用牛顿法:
其中 是学习率(步长)。
实现的伪代码如下图所示:

论文 ICLR 2019 Prior convictions: Black-box adversarial attacks with bandits and priors. [15] 中提出使用有限差分法估计某个函数 在向量
方向上的点
处的方向导数
为:
为步长,控制梯度估计的质量。 由于精度和噪声等问题,步长更小会得到更准确的估计,但同时也会降低可靠性。 因此,在实践中,将
作为一个可调参数使用。
我们使用有限差分来构建梯度的估计,可以通过使用所有标准基向量 估计梯度的内积来找到梯度的
个分量:
2.2.2.2 最小二乘法
话题 13 :什么是最小二乘法?如何使用最小二乘法解决线性回归问题?
最小二乘法
最小二乘法是由勒让德在19世纪发现的,形式如下式:
观测值就是我们的多组样本,理论值就是我们的假设拟合函数。目标函数也就是在机器学习中常说的损失函数,我们的目标是得到使目标函数最小化时候的拟合函数的模型。
举一个最简单的线性回归的简单例子,比如我们有 个只有一个特征的样本:
。样本采用一般的
为次
的多项式拟合,
,其中
为参数。最小二乘法就是要找到一组
使得
最小,即求解
。
我们发现这是一个二次函数,我们对其求导,在导数为 的时候取得最小值即可。
回到我们之前讨论的神经元问题,求解 和
是使损失函数最小化的过程,在统计中,称为线性回归模型的最小二乘参数估计 (parameter estimation)。我们可以将
分别对
和
求偏导,得到:
以及
令上述两式为 ,即可得到
和
最优解的闭式(closed-form)解。
最小二乘法的矩阵法解法(选学)
最小二乘法的代数法解法就是对 求偏导数,令偏导数为 0,再解方程组,得到
。矩阵法比代数法要简洁。
这里用多元线性回归例子来描述:假设函数 的矩阵表达方式为:
其中, 假设函数 为
的向量,
为
的向量,里面有
个代数法的模型参数。
为
维的矩阵。
代表样本的个数,
代表样本的特征数。
损失函数定义为
其中 是样本的输出向量,维度为
。
在这主要是为了求导后系数为
,方便计算。
根据最小二乘法的原理,我们要对这个损失函数对 向量求导取
。结果如下式:
整理可得:
最小二乘法的局限性和适用场景
-
最小二乘法需要计算
的逆矩阵,有可能它的逆矩阵不存在,这样就没有办法直接用最小二乘法了,此时梯度下降法仍然可以使用。当然,我们可以通过对样本数据进行整理,去掉冗余特征。让
,然后继续使用最小二乘法。
-
当样本特征
非常的大的时候,计算
的逆矩阵是一个非常耗时的工作(
的矩阵求逆),甚至不可行。而此时以梯度下降为代表的迭代法仍然可以使用。有时可以通过主成分分析降低特征的维度后再用最小二乘法。
-
如果拟合函数不是线性的,这时无法使用最小二乘法,需要通过一些技巧转化为线性才能使用,此时梯度下降仍然可以用。
2.2.3 神经元线性模型实战
话题 14 :道理我都懂,怎么用代码实现并解决神经元线性模型呢?
在理解了神经元线性模型的原理以及各种优化算法以后,我们来实战训练单输入神经元线性模型。
首先我们引入需要的包。
import numpy as np
import math
# cal y = 1.477x + 0.089 + epsilon,epsilon ~ N(0, 0.01^2)
1. 生成数据集
我们需要采样自真实模型的多组数据,对于已知真实模型的 玩具样例 (Toy Example),我们直接从指定的 的真实模型中直接采样:
为了能够很好地模拟真实样本的观测误差,我们给模型添加误差自变量 ,它采样自均值为
,方差为
的高斯分布:
我们通过随机采样 次,我们获得
个样本的训练数据集
,然后循环进行
次采样,每次从均匀分布
中随机采样一个数据
同时从均值为
,方差为
的高斯分布
中随机采样噪声
,根据真实模型生成
的数据,并保存为
数组。
def get_data():
# 计算均方误差
#保存样本集的列表
data = []
for i in range(100):
x = np.random.uniform(-10., 10.) # 随机采样 x
# 高斯噪声
eps = np.random.normal(0., 0.01) # 均值和方差
# 得到模型的输出
y = 1.477 * x + 0.089 + eps
# 保存样本点
data.append([x, y])
# 转换为2D Numpy数组
data = np.array(data)
return data
2. 计算误差
循环计算在每个点 处的预测值与真实值之间差的平方并累加,从而获得训练集上的均方差损失值。
最后的误差和除以数据样本总数,从而得到每个样本上的平均误差。
def mse(b, w, points) :
totalError = 0
# 根据当前的w,b参数计算均方差损失
for i in range(0, len(points)) : # 循环迭代所有点
# 获得 i 号点的输入 x
x = points[i, 0]
# 获得 i 号点的输出 y
y = points[i, 1]
# 计算差的平方,并累加
totalError += (y - (w * x + b)) ** 2
# 将累加的误差求平均,得到均方误差
return totalError / float(len(points))
3. 计算梯度
这里我们使用更加简单好用的梯度下降算法。我们需要计算出函数在每一个点上的梯度信息: 。我们来推导一下梯度的表达式,首先考虑
,将均方差函数展开:
由于:
则有:
根据上面偏导数的表达式,我们只需要计算在每一个点上面的 和
值,平均后即可得到偏导数
和
。
# 计算偏导数
def step_gradient(b_current, w_current, points, lr) :
# 计算误差函数在所有点上的异数,并更新w,b
b_gradient = 0
w_gradient = 0
# 总体样本
M = float(len(points))
for i in range(0, len(points)) :
x = points[i, 0]
y = points[i, 1]
# 偏b
b_gradient += (2 / M) * ((w_current * x + b_current) - y)
# 偏w
w_gradient += (2 / M) * x * ((w_current * x + b_current) - y)
# 根据梯度下降算法更新的 w',b',其中lr为学习率
new_b = b_current - (lr * b_gradient)
new_w = w_current - (lr * w_gradient)
return [new_b, new_w]
plt.rcParams['font.size'] = 16
plt.rcParams['font.family'] = ['STKaiti']
plt.rcParams['axes.unicode_minus'] = False
# 梯度更新
def gradient_descent(points, starting_b, starting_w, lr, num_iterations) :
b = starting_b
w = starting_w
MSE = []
Epoch = []
for step in range(num_iterations) :
b, w = step_gradient(b, w, np.array(points), lr)
# 计算当前的均方误差,用于监控训练进度
loss = mse(b, w, points)
MSE.append(loss)
Epoch.append(step)
if step % 50 == 0 :
print(f"iteration:{step}, loss:{loss}, w:{w}, b:{b}")
plt.plot(Epoch, MSE, color='C1', label='均方差')
plt.xlabel('epoch')
plt.ylabel('MSE')
plt.title('MSE function')
plt.legend(loc = 1)
plt.show()
return [b, w]
4. 主函数
def solve(data) :
# 学习率
lr = 0.01
initial_b = 0
initial_w = 0
num_iterations = 1000
[b, w] = gradient_descent(data, initial_b, initial_w, lr, num_iterations)
loss = mse(b, w, data)
print(f'Final loss:{loss}, w{w}, b{b}')
if __name__ == "__main__":
data = get_data()
solve(data)
iteration:0, loss:8.52075121569461, w:0.9683621336270813, b:0.018598967590321615
iteration:50, loss:0.0005939300597845278, w:1.477514542941938, b:0.06613823978315139
iteration:100, loss:0.00016616611251547874, w:1.4772610937560182, b:0.08026637756911292
iteration:150, loss:0.00010824080152649426, w:1.4771678278317757, b:0.08546534407456151
iteration:200, loss:0.00010039689211198855, w:1.4771335072140424, b:0.08737849449355252
iteration:250, loss:9.933471542527609e-05, w:1.4771208776838989, b:0.08808250836281861
iteration:300, loss:9.919088162325623e-05, w:1.477116230185043, b:0.08834157608859644
iteration:350, loss:9.917140448460003e-05, w:1.4771145199673728, b:0.08843690956066241
iteration:400, loss:9.916876700352793e-05, w:1.477113890630052, b:0.08847199100845321
iteration:450, loss:9.916840985114966e-05, w:1.4771136590423013, b:0.08848490051392309
iteration:500, loss:9.916836148764827e-05, w:1.4771135738210939, b:0.08848965103996947
iteration:550, loss:9.916835493854371e-05, w:1.4771135424608248, b:0.08849139917027324
iteration:600, loss:9.916835405170177e-05, w:1.4771135309206636, b:0.08849204245893828
iteration:650, loss:9.916835393161082e-05, w:1.4771135266740378, b:0.08849227918059785
iteration:700, loss:9.916835391534817e-05, w:1.4771135251113363, b:0.08849236629101521
iteration:750, loss:9.916835391314785e-05, w:1.477113524536283, b:0.08849239834648838
iteration:800, loss:9.916835391284828e-05, w:1.477113524324671, b:0.08849241014247554
iteration:850, loss:9.916835391280702e-05, w:1.4771135242468005, b:0.08849241448324166
iteration:900, loss:9.916835391280325e-05, w:1.4771135242181452, b:0.08849241608058574
iteration:950, loss:9.916835391280336e-05, w:1.4771135242076006, b:0.08849241666838711

Final loss:9.916835391280157e-05, w1.4771135242037658, b0.08849241688214672
我们可以看到,第 次迭代时,
和
的值就已经比较接近真实模型了,更新
次后得到的
数值解与真实模型的非常接近。
完整代码详见:Github
2.3 再探回归
话题 15 :线性模型已经完全学会了!如果换成非线性的模型该怎么办呢?
我们来考虑一个回归预测问题:使用后台数据预测youtube账号第二天的观看量。
由于观看量有周期的变化,显然不是线性模型就可以表示的。线性模型是机器学习中间最简单的数学模型之一,参数量少,计算简单,但是只能表达线性关系。一条直线无论你怎样调整参数,都不能很好地拟合出真实的模型:
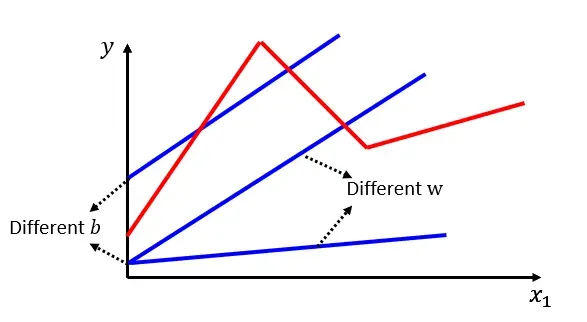
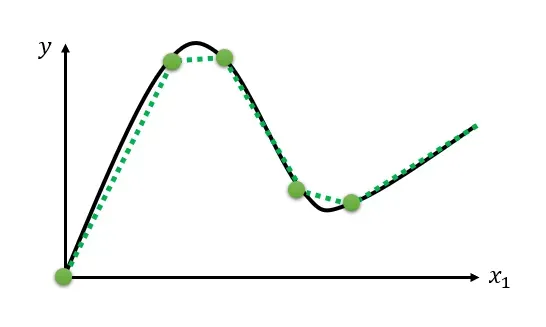
如何表示更加复杂的模型,最有弹性的模型就是连续曲线,它可以更加精准地描述复杂问题。显然只要有足够多的分段线性曲线就可以逼近连续曲线。
那么如何获得一个分段线性曲线呢?一个显然的思路是将若干线性曲线分段后合并并加上一个常数将曲线进行平移即可得到一个分段线性曲线:
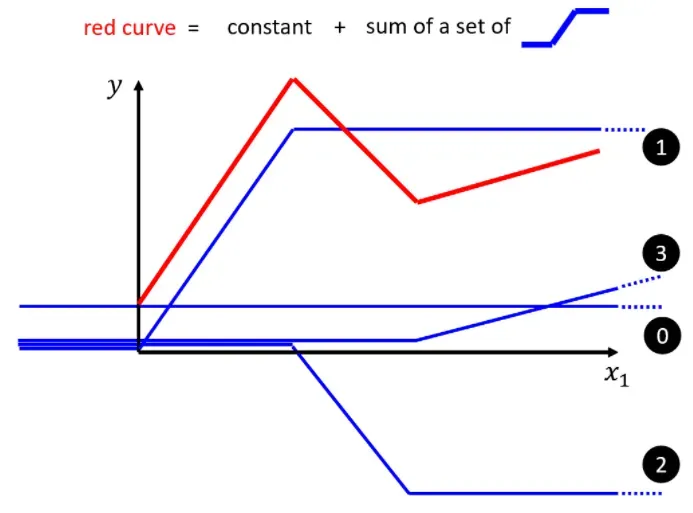
但是这里有一个问题,由直线组成的分段线性曲线,在转角处无法计算微分,也就不能使用梯度下降算法进行优化计算。
2.3.1 非线性模型
解决非线性模型
深度学习希望使用神经元得到想要的函数的大致的表达,通过使用大量的数据去反向拟合出这个函数的各个参数,最终勾勒出函数的完整形状。
为了能够拟合非线性的函数,我们可以为神经网络增加非线性因素,使其可以拟合任意的函数。也就是给原先的线性模型嵌套一个非线性函数,即可将线性模型转换为非线性模型。我们把这个非线性函数称为激活函数(Activation function),用 表示。线性模型就转换为了:
这里的 代表了某个具体的非线性激活函数,比如 Sigmoid 函数:
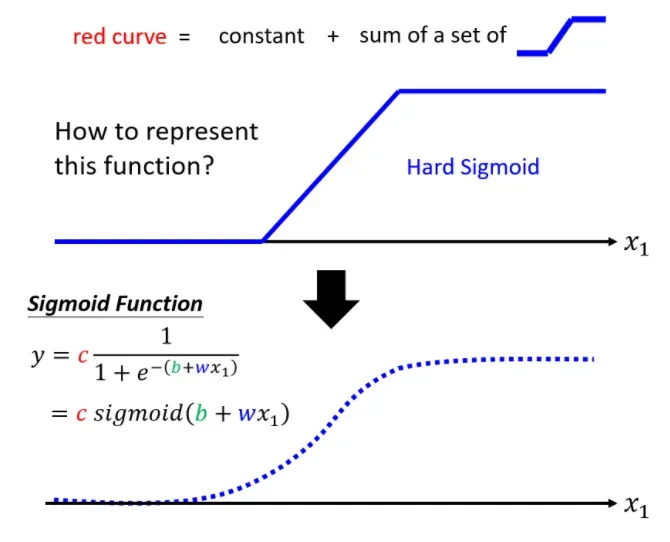
Sigmoid(S型曲线)
通过调整 Sigmoid 函数中的三个参数 足以实现各种各样的 S 型曲线。改变
可以改变 S 型曲线的坡度;改变
可以使 S 型曲线左右移动;改变
可以改变 S 型曲线的上下高度。
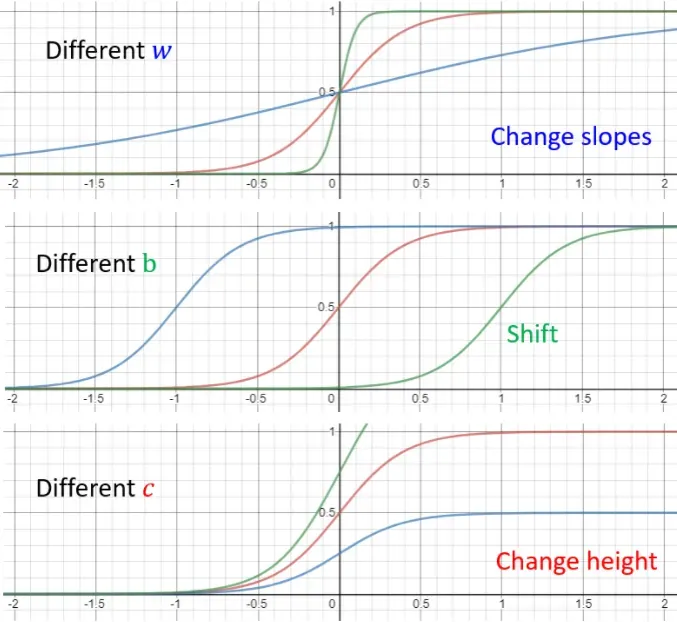
我们将分段直线在经过激活函数之后再进行组合即可得到非线性的模型。
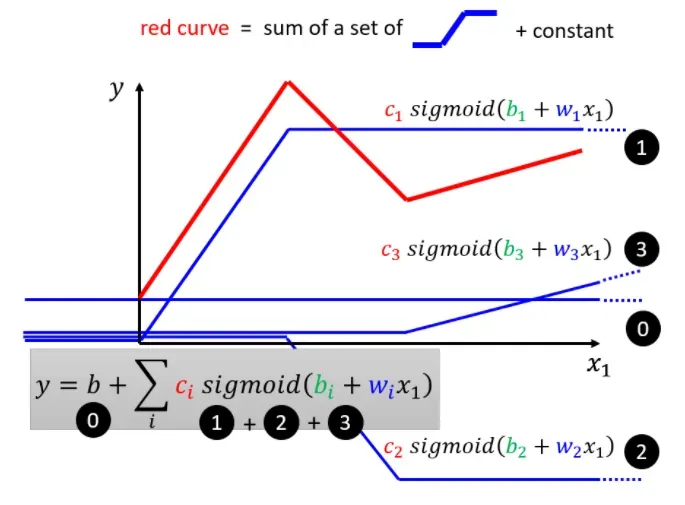
可以理解为将原来的折线替换为了曲线,大量的曲线拼接而成即可完美拟合一个非线性的函数。
2.4 面试题目集锦
本小节 2.4 面试题目集锦 中收集的题目和答案大多来自于网上的各大博客,具体链接详见 2.5 参考资料 [7] [8] [9]。
1. 简单介绍一下线性回归 (Linear Regression) 的原理。
线性关系就是两个或者多个变量之间的关系符合一次函数关系,对应到图像上就是一条直线。如果变量之间的关系不符合一次函数,图像就不是直线,也不满足线性关系。
回归是指预测,希望通过计算回归到真实值。
线性回归是用于预测问题的有监督学习,是一种利用线性回归方程的最小平方函数对一个或多个自变量和因变量之间映射关系进行建模并利用学习到的映射关系实现对未知的数据进行预测的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。另外线性回归还是一个连续值。
2.线性回归的假设函数是什么形式?
其中 也即直接加上偏置
,
都是列向量。
为特征,
为标签值,
为预测值,注意线性回归实际上既可以处理回归问题也可以处理分类问题,只是在针对分类问题的0-1这类的标签,线性回归会很难收敛。
3.线性回归的代价(损失)函数是什么形式?
默认是最小化损失函数:
4. 为什么线性回归使用的是平方差形式的损失函数?
使用平方形式的时候,使用的是“最小二乘法”的思想,这里的“二乘”指的是用平方来度量观测点与估计点的距离(远近),“最小”指的是参数值要保证各个观测点与估计点的距离的平方和达到最小。最小二乘法以估计值与观测值的平方和作为损失函数,在误差服从正态分布的前提下(这一点容易被忽视),与极大似然估计的思想在本质上是相同。也就是说不是我们特意去选择mse作为线性回归的损失函数而是因为我们假设误差服从正态分布,使用极大似然法(最大化误差项目为εi的样本总体出现的概率最大)来求解参数,进一步经过推导之后得到的mse的公式而已,具体流程见下:
我们设观测输出与预估数据之间的误差为:
我们通常认为 服从正态分布,即:
我们求的参数 的极大似然估计
,即是说,在某个
下,使得服从正态分布的
取得现有样本εi的概率最大。也就是说实际上我们的最原始的目标是使得这个正态分布表达式的连乘的极大似然估计最大。
那么根据极大似然估计函数的定义,令:
取对数似然函数:
分别求 的偏导数,然后置
,最后求得参数
的极大似然估计为:
我们在线性回归中要求得最佳拟合直线:
实质上是求预估值 与观测值
之间的误差
最小(最好是没有误差)的情况下
的值。由于
是服从参数
的正态分布,因此最好是均值
和方差
趋近于
或越小越好,根据表达式可知,均值和方差越小,对数似然函数越大。即:
-
越趋近于
-
趋近于
这与最前面构建的平方形式损失函数本质上是等价的。
5. 线性回归为什么要求因变量符合正态分布
线性回归的假设前提是特征与预测值呈线性关系,误差项符合高斯 – 马尔科夫条件(零均值,零方差,不相关),这时候线性回归是无偏估计。噪声符合正态分布,那么因变量也符合分布。在进行线性回归之前,要求因变量近似符合正态分布,否则线性回归效果不佳(有偏估计)。
6. 下列关于线性回归说法错误的是(D)
A. 在现有模型上,加入新的变量,所得到的R^2的值总会增加。
B. 线性回归的前提假设之一是残差必须服从独立正态分布。
C. 残差的方差无偏估计是 。
D. 自变量和残差不一定保持相互独立。
A: 是拟合优度,
,
是总平方和,
是回归平方和,
是残差平方和,公式如下:
从公式上比较好理解, 表示的是自变量引起的变动占总变动的百分比,值越大,说明残差的影响越不明显,则权重部分的预测效果越好。从公式上可以看出,因为
是不变的,加入新的变量,则对于
,其中
就增加了新的变量进来,比如原来是
,如果新进的特征
实在太差,再不济我们也可以让其权重
从而训练出与加入
之前的模型一样的模型(也可以从 pac理论来进行分析),显然得到的
的值总会增加。
B:线性回归的前提假设之一是残差必须服从独立正态分布,线性回归的损失函数mse就是:在某个 下,使得服从正态分布的ε取得现有样本εi的概率最大从而推算出来的损失函数的表达式。
C:残差的方差无偏估计是 ,其中
是特征的数量,别问为什么,问就说这是公式(
D:错误,残差必须满足独立正态分布才符合线性回归的定义。
7. 在线性回归问题中,我们使用决定系数 (R-squared)来测量拟合优度。我们在线性回归模型中添加一个特征值,并保留相同的模型。下面说法正确的是(C)
A. 如果R-Squared增大,这个变量是显著的
B . 如果R-Squared减小,这个变量是显著的
C. 单独观察R-Squared的变化趋势,无法判断这个变量是否显著
D. 以上皆非
R-squared 就是上面说的 ,判断变量是否显著,需要根据变量对应的权重系数
,而与
无直接关系。
8. 请写出在数据预处理过程中如何处理以下问题
8.1 为了预测摩拜每天订单数,我们建立了一个线性回归模型,其中有一个自变量为天气类型(分类变量),分为晴、阴、雾霾、沙尘暴、雨、雪等6种类型,请问如何处理这种变量
8.2 仍然是 ① 中的线性回归模型,其中有一个自变量为每天红包车的数量,但是这个变量有1/4的数据是缺失值,请写出至少两种处理缺失值的方法
8.3 依然是 ① 中的模型,其中自变量有4个,他们的相关系数矩阵如下:
8.1:天气是离散变量,没有大小关系,并且类别只有 类,可以直接 one-hot 展开。
8.2: 的数据存在缺失值不能用简单的删除法或者是均值、中位数、众数插补的方法了因为都使用相同的数据进行这么大比例的插补太容易改变原始数据的分布情况了,所以比较好的方式有 1、通过模型插补;2、多重插补法等。
8.3:变量 2、3 存在较强的负相关性,也就是存在共线性的问题,而共线性会导致模型的效果变差,所以需要根据业务知识来进行处理,合并,或者删除等再观察处理之后的效果再决定采用哪一种处理方式(需要注意的是我们这里是针对仅仅使用线性回归的情况,如果是使用 gbdt 这类算法则不需要处理)。
9. 线性回归解析解的推导(三种方法)
10. 线性回归的基本假设?
-
假设特征与标签之间满足线性关系。
-
误差项(
)之间应相互独立。(比如时间序列数据常常发生误差项不是相互独立的情况,比如今天的数据会收到昨天和前天的数据的影响)。
-
自变量之间应相互独立。
-
误差项(
-
误差项(
11. 线性回归效果不好的原因
- 普通线性回归易过拟合,可以改用 LASSO 或者 RIDGE 回归。
- 数据不符合线性回归的假设。
- 特征工程有问题。
- 实际情况中基础假设难以得到满足(比如残差符合正态分布)从而影响最终模型的精度
12. 为什么进行线性回归前需要对特征进行离散化处理。
- 离散化操作简单,特征离散化之后易于模型的快速迭代。
- 稀疏矩阵计算快,省内存。
- 鲁棒性强。单个特征数值过大或者过小对结果的影响会被降低。
- 可以产生交叉特征(相当于非线性)
- 模型的稳定性加强了。
- 简化了模型,相当于降低了过拟合的风险。
13. 线性回归处理步骤,什么情况下可停止迭代,怎么避免过拟合情况?
处理步骤一般来说为缺失值处理、类别变量数值化,异常值处理,连续特征离散化等等。
当两次迭代所有参数的变化量小于事先给定的阈值时,或者达到事先设定的最大迭代次数,则停止迭代过程。
过拟合没法避免只能说是尽量降低过拟合的影响,通过 正则化、减少特征的数量、增大样本的数量等等。
14. 线性回归优缺点
优点:实现简单,建模快,是许多非线性模型的基础。
缺点:模型简单所以难以拟合复杂数据,对非线性的数据难以运用。
2.5 参考资料
[1] 《2021春机器学习课程》李宏毅 https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
[2] 《TensorFlow深度学习》(龙龙老师) https://github.com/dragen1860/Deep-Learning-with-TensorFlow-book
[3] 《神经网络与深度学习》Coursera吴恩达 https://www.deeplearning.ai/
[4] 《动手学深度学习》第二版 https://zh-v2.d2l.ai/
[5] 《深度学习》(花书) https://book.douban.com/subject/27087503/
[6] 最小二乘法(least sqaure method) https://zhuanlan.zhihu.com/p/38128785
[7] 线性回归面经总结——from 牛客 https://zhuanlan.zhihu.com/p/66519299
[8] 机器学习面试题之线性回归 https://blog.csdn.net/weixin_41761357/article/details/111589392](https://blog.csdn.net/weixin_41761357/article/details/111589392)
[9] RMSE(均方根误差)、MSE(均方误差)、MAE(平均绝对误差)、SD(标准差)https://blog.csdn.net/FrankieHello/article/details/82024526
[10] 机器学习-回归问题(Regression) https://zhuanlan.zhihu.com/p/127972563
[11] 为什么梯度下降能找到最小值? https://www.zhihu.com/question/24258023
[12] 有限差分法 https://zh.wikipedia.org/wiki/%E6%9C%89%E9%99%90%E5%B7%AE%E5%88%86%E6%B3%95
[13] Symmetric derivative https://en.wikipedia.org/wiki/Symmetric_derivative#Notes
[14] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, pages 15–26. ACM, 2017.
[15] Andrew Ilyas, Logan Engstrom, and Aleksander Madry. Prior convictions: Black-box adversarial attacks with bandits and priors. In International Conference on Learning Representations, 2019. 1, 2, 5, 7, 8, 11

转载请注明出处:https://fanfansann.blog.csdn.net/
版权声明:本文为 CSDN 博主 「繁凡さん」(博客),知乎答主 「繁凡」(专栏),Github 「fanfansann」(全部源码),微信公众号 「繁凡的小岛来信」(文章 P D F 版))的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
版权声明:本文为博主繁凡さん原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_45697774/article/details/120786508