对您的时间序列异常不满意?合成它们!
生成您自己的具有真实异常的多元时间序列数据集

如果您处理过时间序列数据的异常检测问题,您可能已经搜索过包含相关异常的注释数据集。您可能在此搜索中遇到了困难,尤其是在寻找适合研究工业 IoT 用例的多元时间序列数据时。此外,即使您使用现实生活中的传感器数据,您仍可能难以找到根据定义在制造过程中很少见的异常情况。
在写一些关于异常检测的文章时,我搜索了这么好的数据集来说明我的思考过程。基本上,我需要:
- 包含多个传感器的多元数据集
- 跨越几个月(最好是一年)
- 以合理的采样率(大约 1 到 5 分钟)
- 包括一些已知的异常来验证我的结果
我发现满足所有这些标准的唯一数据集是 Kaggle 上可用的水泵数据集。不幸的是,没有与该数据集关联的许可证,因此无法在 Medium 等出版物上实际使用,因为这被认为是商业用途。[0]
因此,我决定尝试生成我自己的多元数据集,其中包含我在处理工业传感器和制造过程数据时遇到的异常类型……
我鼓励您通过浏览 GitHub 来关注这篇博文,以获取这一系列配套的 Jupyter 笔记本。您可以使用常用的 Jupyter 环境,也可以使用 Amazon SageMaker 启动一个。克隆 repo 后,您可以打开第一个 (synthetic_0_data_generation.ipynb) 并按照本文进行操作。[0]
Initialization
我们将从头开始构建我们的数据集,仅使用基本的 Python 库:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import random
from dateutil.relativedelta import relativedelta这里没什么特别的:数据处理库(numpy 和 pandas)、随机生成器库和 matplotlib 来可视化我们的时间序列。在处理日期操作时,我喜欢使用 relativedelta 方法:当涉及到在给定信号中组合多种类型的异常时,我们将使用它。
有了这个,我们准备好了!让我们从生成时间序列的基本信号开始……
Generating the baseline
我们将首先定义数据集的范围:
START = '2021-01-01 00:00'
END = '2021-12-31 23:50'
FREQ = '10min'
index = pd.date_range(start=START, end=END, freq=FREQ)
df = pd.DataFrame({'timestamp': index})
df = df.set_index('timestamp')我想以 10 分钟的常规采样率生成一年的数据。然后,我使用此日期时间索引生成一个空数据框。
随机生成值
您的第一反应可能是沿我们刚刚创建的日期时间轴生成随机值:
df['value'] = np.random.normal(0, 1, len(index))
fig = plt.figure(figsize=(16,4))
plt.plot(df)
plt.title('Random values')
plt.show()这段代码产生以下结果:
这种白噪声看起来并不真实:没有要寻找的模式,并且使用这种方法生成多个信号以合成多变量数据集对于模拟真实过程不是很有用。如果您正在测量机器的温度,则这些值不会如此混乱地演变。这就是随机游走发挥作用的地方……
利用随机游走过程
真实数据应该显示模式:在给定的时间点,一个值实际上与以前的值有某种程度的关系。在概率上,随机游走是在给定向某个方向移动的概率的情况下确定对象的可能位置(这里是我们的时间序列的值)的过程。
这是我用来生成随机游走的函数:我的时间序列从一个初始值(开始)开始,然后我随机添加一个数量(步长)。我可以使用 min_value 和 max_value 参数将我的时间序列限制在一定范围内。我还可以使用概率概率来为我的时间序列提供减少或增加的趋势:
def generate_random_walk(
num_values,
start=0,
step=1,
probability=0.5,
min_value=-np.inf,
max_value=np.inf
):
previous_value = start
array = np.zeros((num_values,))
for index in range(num_values):
if previous_value < min_value:
previous_value = min_value
if previous_value > max_value:
previous_value = max_value
p = random.random()
if p >= probability:
array[index] = previous_value + step
else:
array[index] = previous_value - step
previous_value = array[index]
return array让我们生成一些图来可视化我们可以获得的行为:
fig = plt.figure(figsize=(16,16))
ax = fig.add_subplot(3,1,1)
ax.plot(generate_random_walk(df.shape[0]))
ax.set_title('Example 1')
ax = fig.add_subplot(3,1,2)
ax.plot(generate_random_walk(df.shape[0], threshold=0.49), label='Bias toward increasing values', color=colors[1])
ax.plot(generate_random_walk(df.shape[0], threshold=0.51), label='Bias toward increasing values', color=colors[2])
ax.legend()
ax.set_title('Example 2')
ax = fig.add_subplot(3,1,3)
ax.plot(generate_random_walk(df.shape[0], threshold=0.5, start_value=100, min_value=90, max_value=150), label='Evolving around 100', color=colors[3])
ax.plot(generate_random_walk(df.shape[0], threshold=0.5, start_value=-150, min_value=-200, max_value=-120), label='Evolving around -150', color=colors[4])
ax.legend()
ax.set_ylim(-240, 160)
ax.set_title('Example 3')
plt.show()这是这段代码产生的图:
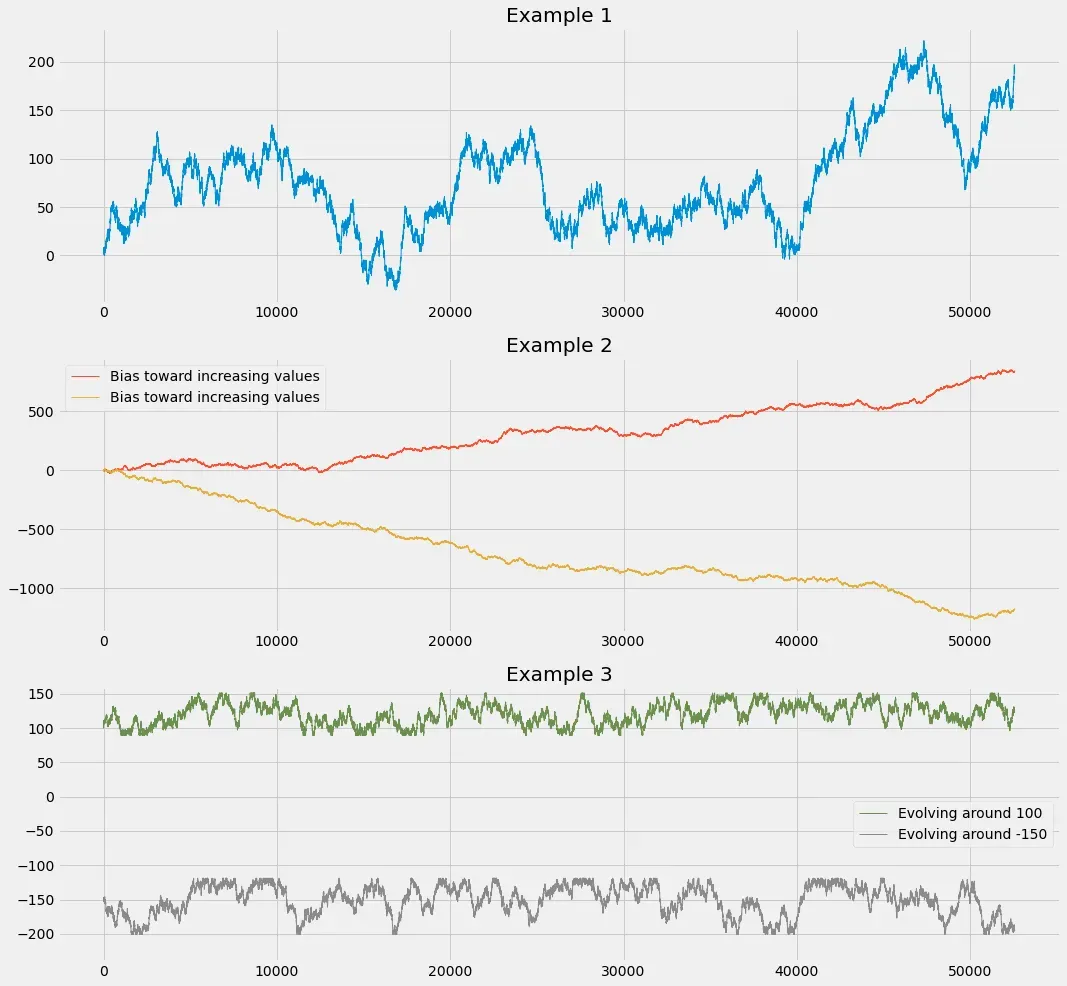
这看起来好多了:这些信号实际上看起来非常逼真!我现在将使用此函数为位于不同范围内的 20 个信号的多元数据集生成基线(为此我使用不同的起始值)。这将模拟测量过程不同维度的传感器数据(例如)。这是我得到的结果:
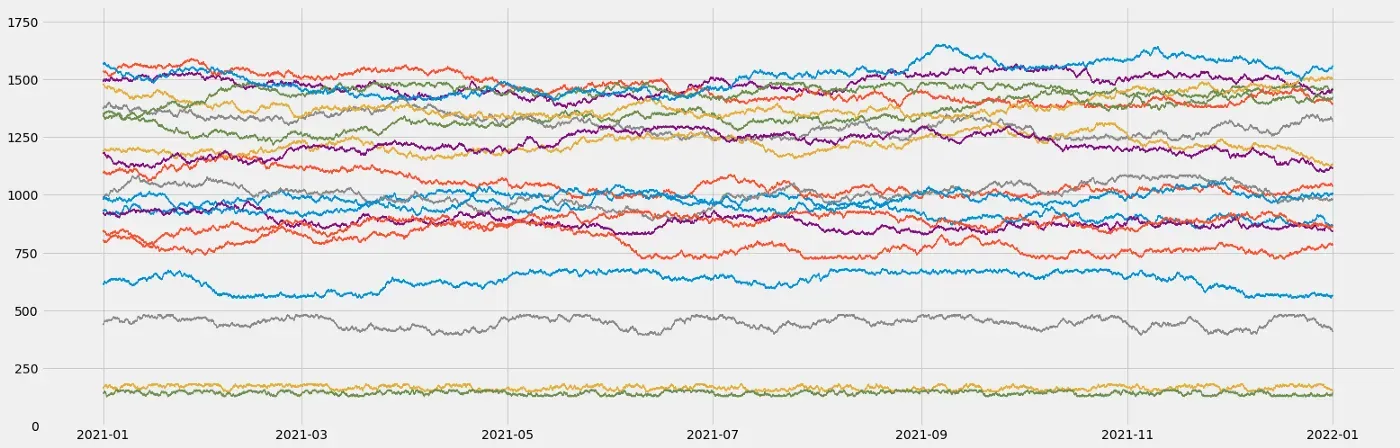
现在让我们在其中添加一些异常…
Adding anomalies
Adding level shifts
当一个过程或一系列设备经历不同的操作模式时,可以看到时间序列数据的水平变化。当环境条件发生突然变化时,也可能发生这种情况。这是我用来模拟作为 Pandas 系列输入的给定信号的电平转换的函数:
def add_level_shift(
series,
freq,
magnitude_shift,
magnitude_multiply=None,
start=None,
end=None,
duration=None
):
original_series = series.copy()
# Converting frequency in minutes:
freq = int(freq[:-3])
if start is None:
ANOMALY_START = original_series.index[
int(random.random() * original_series.shape[0] * 0.75)
]
else:
ANOMALY_START = start
if (end is None) and (duration is None):
# Durations unit are in number of datapoints. With a frequency of 5 minutes,
# we want to set a minimum duration of:
# 1 week = 7 days x 24 hours x 12 (=60 minutes / 5 minutes)
MIN_DURATION = 60 / freq * 24 * 7
MAX_DURATION = 60 / freq * 24 * 30
ANOMALY_DURATION = MIN_DURATION + int(random.random() * (MAX_DURATION - MIN_DURATION))
ANOMALY_END = ANOMALY_START + relativedelta(minutes=+ANOMALY_DURATION * freq)
elif end is not None:
ANOMALY_END = end
elif duration is not None:
ANOMALY_END = ANOMALY_START + relativedelta(minutes=+duration * freq)
index = pd.date_range(ANOMALY_START, ANOMALY_END, freq=f'{freq}min')
anomaly_df = pd.Series(
index=index,
dtype=np.float64
)
anomaly_df.loc[:] = magnitude_shift
if np.max(index) > np.max(original_series.index):
anomaly_df = anomaly_df[:np.max(original_series.index)]
if magnitude_multiply is not None:
min_value = original_series[index].min()
avg_value = original_series[index].mean()
original_series[index] -= avg_value
original_series[index] *= magnitude_multiply
original_series[index] += avg_value
new_series = original_series.add(anomaly_df, fill_value=0)
return new_series此功能允许您在给定时间点(开始和结束之间)沿方向(magnitude_shift)移动给定时间序列的一部分。当发生变化时,您的信号也可能更平滑(magnitude_multiply < 1.0)或更混乱(magnitude_multiply > 1.0)。
以下是此函数生成的电平转换的两个示例:
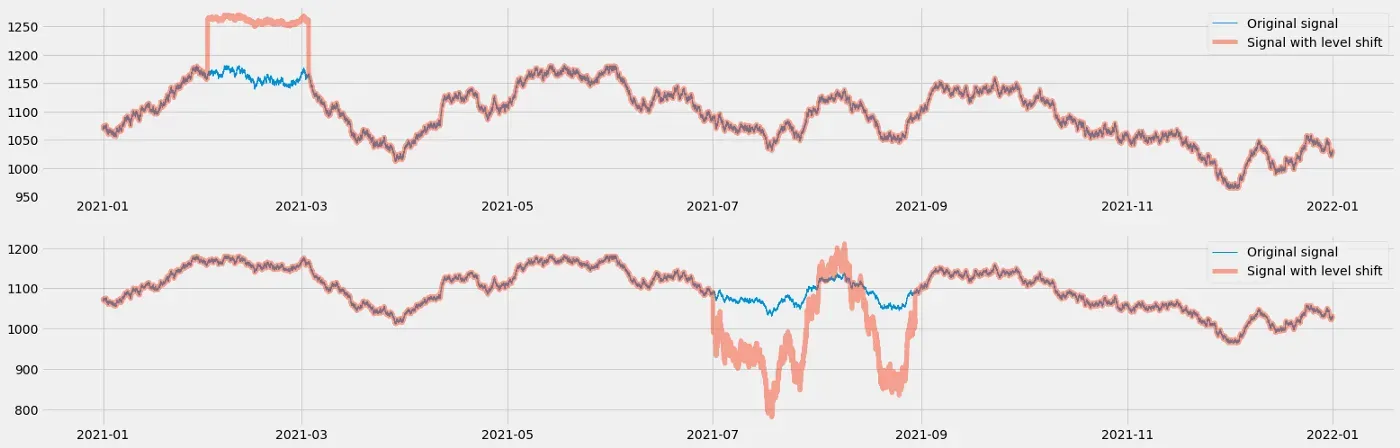
在第一个信号上,我们添加了一个具有更平滑信号的正电平偏移。其次,电平偏移为负,我们在此时间范围内模拟更混乱的行为。
以下是生成此图的相关代码:
tags_list = list(df.columns)
tag = tags_list[0]
level_shift_start = pd.to_datetime('2021-02-01')
level_shift_duration = (60 / int(FREQ[:-3])) * 24 * 30
new_tag = add_level_shift(
df[tag], freq=FREQ, magnitude_shift=100, magnitude_multiply=0.5,
duration=level_shift_duration, start=level_shift_start
)
fig = plt.figure(figsize=(24,8))
ax = fig.add_subplot(2, 1, 1)
ax.plot(df[tag], linewidth=1.0, label='Original signal')
ax.plot(new_tag, linewidth=5.0, alpha=0.5, label='Signal with level shift')
ax.legend()
level_shift_start = pd.to_datetime('2021-07-01')
level_shift_duration = (60 / int(FREQ[:-3])) * 24 * 60
new_tag = add_level_shift(
df[tag], freq=FREQ, magnitude_shift=-100, magnitude_multiply=4.0,
duration=level_shift_duration, start=level_shift_start
)
ax = fig.add_subplot(2, 1, 2)
ax.plot(df[tag], linewidth=1.0, label='Original signal')
ax.plot(new_tag, linewidth=5.0, alpha=0.5, label='Signal with level shift')
ax.legend()
plt.show()现在我将使用此函数将两个随机电平转换添加到随机选择的三个信号中。我还将向其他五个信号添加另一个随机电平转换,这些信号也是随机选择的:
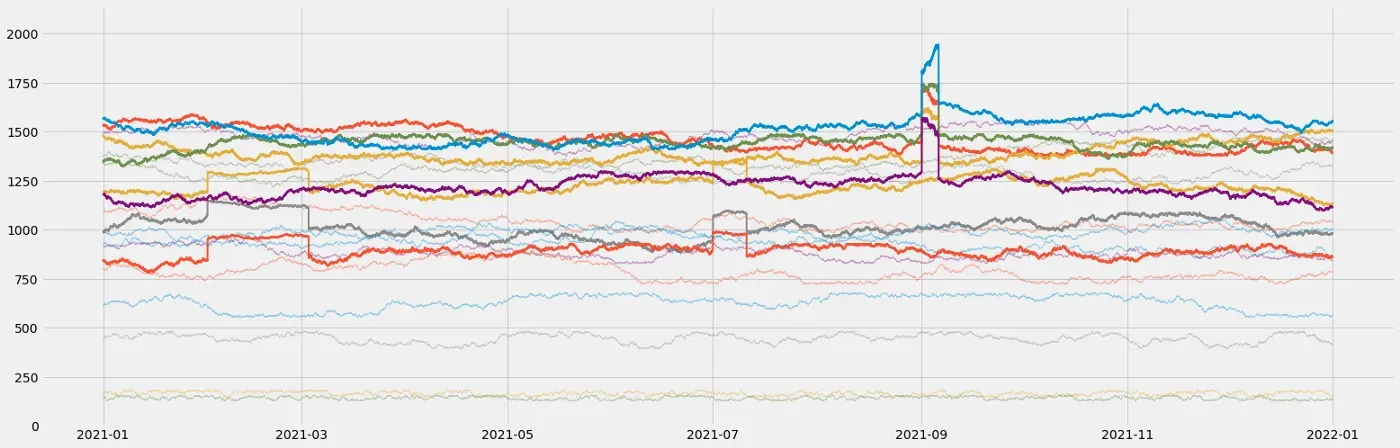
这种类型的异常很常见,但很容易发现。现在让我们看看如何向信号添加渐变以模拟过程的缓慢退化……
添加趋势或渐变
为了给时间序列添加渐变,我使用以下函数:
def add_degradation(
series,
freq,
start=None,
end=None,
duration=None,
degradation_speed=0.05,
degradation_slope=-0.05,
degradation_duration=None
):
original_series = series.copy()
# Converting frequency in minutes:
freq = int(freq[:-3])
# Defines the start of the anomaly:
if start is None:
ANOMALY_START = original_series.index[int(random.random() * original_series.shape[0] * 0.75)]
else:
ANOMALY_START = start
# Defines the end and the duration:
if (end is None) and (duration is None):
# Durations unit are in number of datapoints. With a frequency of 5 minutes,
# we want to set a minimum duration of:
# 1 week = 7 days x 24 hours x 12 (=60 minutes / 5 minutes)
MIN_DURATION = 60 / freq * 24 * 7
MAX_DURATION = 60 / freq * 24 * 30
ANOMALY_DURATION = MIN_DURATION + int(random.random() * (MAX_DURATION - MIN_DURATION))
ANOMALY_END = ANOMALY_START + relativedelta(minutes=+ANOMALY_DURATION * freq)
elif end is not None:
ANOMALY_END = end
elif duration is not None:
ANOMALY_END = ANOMALY_START + relativedelta(minutes=+duration * freq)
ANOMALY_DURATION = duration
# Generates a new random walk for the anomaly:
values = generate_random_walk(
ANOMALY_DURATION + 1,
start=0.0,
probability=0.5 - degradation_slope,
step=degradation_speed
)
index = pd.date_range(ANOMALY_START, ANOMALY_END, freq=f'{freq}min')
anomaly_df = pd.Series(index=index, dtype=np.float64)
anomaly_df.loc[:] = values
# Add
last_value = values[-1]
original_series.loc[ANOMALY_END + relativedelta(minutes=+freq):] = series.loc[ANOMALY_END:] + last_value
if degradation_duration is not None:
DEGRADATION_END = ANOMALY_END + relativedelta(minutes=+degradation_duration * freq)
original_series.loc[DEGRADATION_END:] = series.loc[DEGRADATION_END:]
new_series = original_series.add(anomaly_df, fill_value=0)
return new_series, anomaly_df基本上,我生成了一个新的随机游走,其中的 degrade_slope 修改了随机游走概率,degrade_speed 修改了随机游走步骤。使用此函数,我将为我的多元数据集中随机选择的一些信号添加一些降级(请参见下面的紫色和黄色信号):
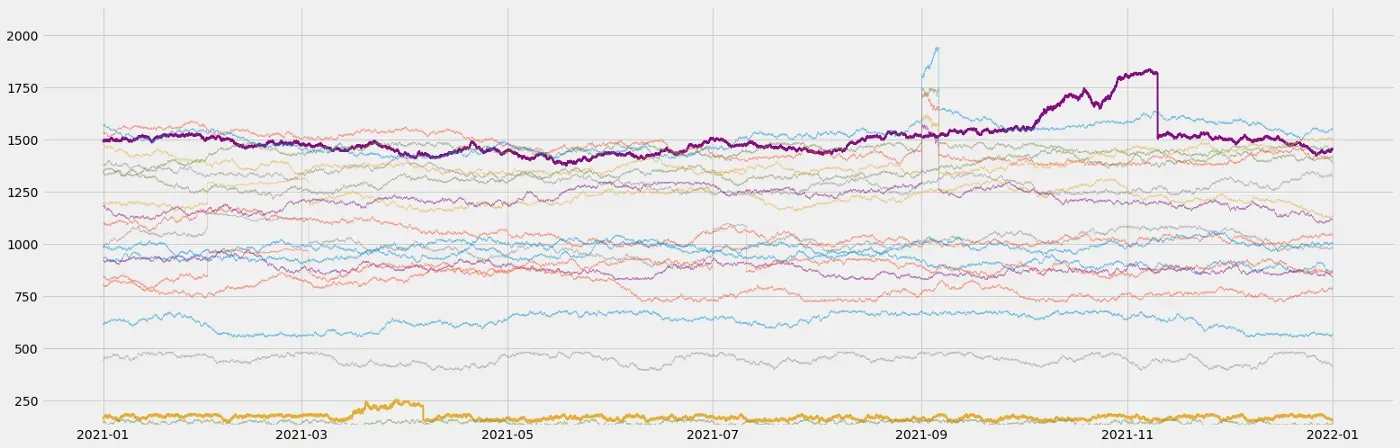
Adding catastrophic failures
通常,在数据集中出现缓慢退化模式后,可能会出现灾难性故障。为了模拟这一点,我将在退化模式之后立即将几个信号设置为 0.0。我有一个非常简单的功能:
def add_failure(series, start, duration, freq):
freq = int(freq[:-3])
original_series = series.copy()
ANOMALY_START = start
ANOMALY_DURATION = duration
index = pd.date_range(
ANOMALY_START,
periods=ANOMALY_DURATION,
freq=f'{freq}min'
)
original_series.loc[index] = 0.0
return original_series查看我的笔记本,看看我是如何在我们刚刚生成的降级模式之后立即添加这些故障的:
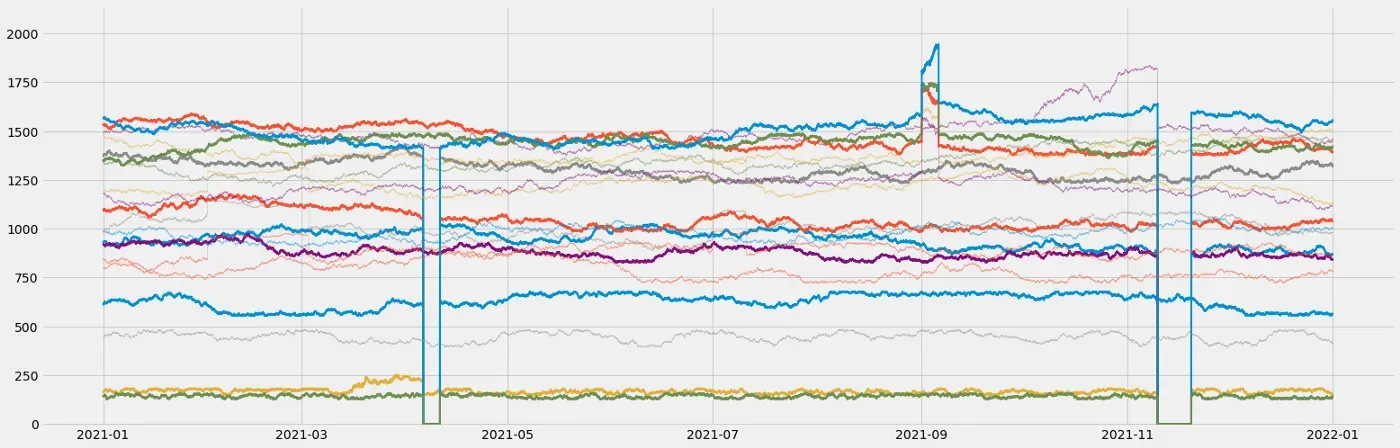
瞧!如果您想查看在此类数据集上训练和评估的异常检测模型示例,请查看以下文章:
Conclusion
在本文中,您了解了如何利用一些合成生成技术来创建具有真实外观的多元时间序列数据。
我希望您发现这篇文章很有见地:如果您不想错过我即将发布的帖子,请随时在此处给我留言,并随时订阅我的 Medium 电子邮件提要!想支持我和未来的工作吗?使用我的推荐链接加入 Medium:[0]
文章出处登录后可见!