Q-learning
Q-learning是强化学习中一种入门级的经典算法。基本思想是对所有状态下的对应动作进行打分,依据最高的分值选择动作。打分的依据是Q表,其中存储了所有状态下动作的分值,Q表通过数据训练而来。Q-learning的优势在于融合了动态规划和蒙特卡洛,构造了时间差分的Q值更新公式,其更新公式如下:

走迷宫问题
问题
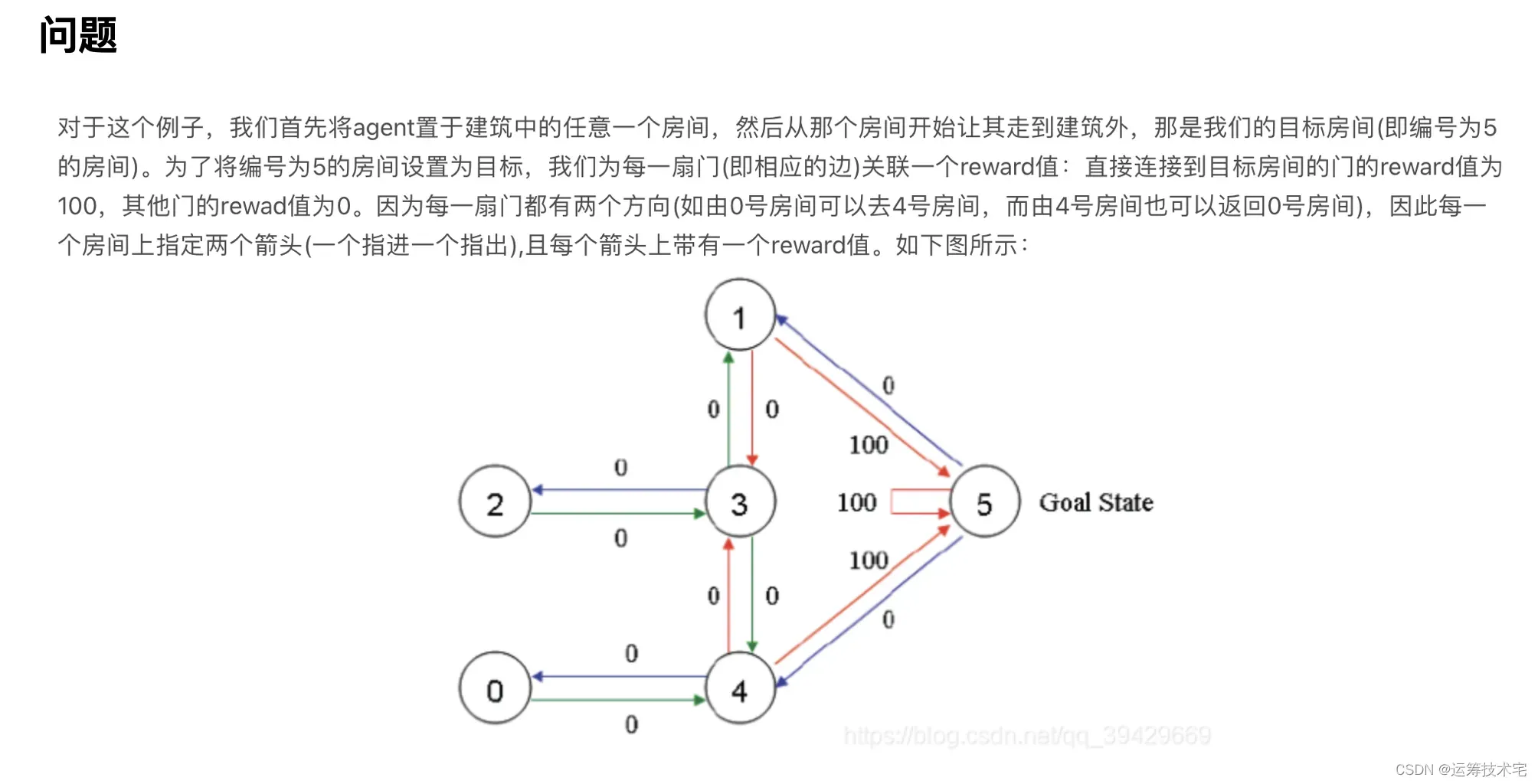
代码
#-----------------------------------调用模块-----------------------------------
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import random
#-----------------------------------Q表R表-----------------------------------
Q=np.array([[0 for i in range(6)] for j in range(6)])
Q[5][5]=100
R=np.array([[-100 for i in range(6)] for j in range(6)])
R[0][4]=0
R[1][3]=0
R[1][5]=100
R[2][3]=0
R[3][2]=0
R[3][1]=0
R[3][4]=0
R[4][0]=0
R[4][3]=0
R[4][5]=100
R[5][1]=0
R[5][4]=0
R[5][5]=100
#-----------------------------------基本参数-----------------------------------
samples=1000;#训练样本
lr=0.1#学习率
r=0.8#折扣系数
e0=0.5#决策贪婪参数
#-----------------------------------函数区域-----------------------------------
#随机策略训练模型
def Q_random_train(samples,lr,r):
for i in range(samples):
s1=random.randint(0,5)
s2=random.randint(0,5)
Q[s1][s2]+=lr*(R[s1][s2]+r*Q[s2].max()-Q[s1][s2])
#贪婪策略训练模型
def Q_greedy_train(samples,lr,r):
for i in range(samples):
s1=random.randint(0,5)
e_=random.random()
e=i/(1.1*samples)
if e_>e:s2=random.randint(0,5)
else:s2=Q[s1].argmax()
Q[s1][s2]+=lr*(R[s1][s2]+r*Q[s2].max()-Q[s1][s2])
#最优策略
def Q_optimal(s1,s2):
path=[s1]
while 1:
s1=Q[s1].argmax()
if s1==s2:
path.append(s1)
break
if s1 in path:
path.clear()
break
path.append(s1)
return path
#-----------------------------------结果区域-----------------------------------
Q_greedy_train(samples,lr,r)
Q_optimal(0,5)
最短路径问题
问题
求0-4的最短路径
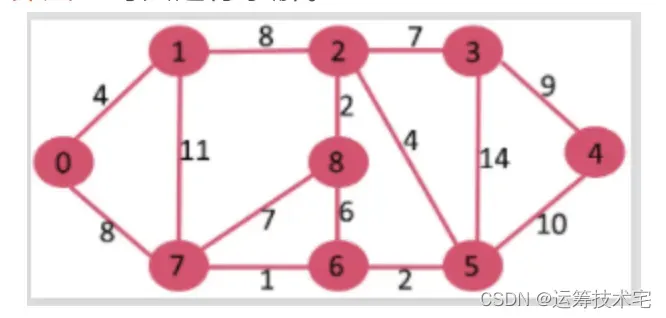
代码
#-----------------------------------调用模块-----------------------------------
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import random
#-----------------------------------Q表R表-----------------------------------
Q=np.zeros([9,9])
for i in range(9):Q[4][4]=100
R=dict()
R[(0,1)]=R[(1,0)]=-4
R[(0,7)]=R[(7,0)]=-8
R[(1,2)]=R[(2,1)]=-8
R[(1,7)]=R[(7,1)]=-11
R[(2,3)]=R[(3,2)]=-7
R[(2,5)]=R[(5,2)]=-4
R[(2,8)]=R[(8,2)]=-2
R[(3,4)]=R[(4,3)]=-9
R[(3,5)]=R[(5,3)]=-14
R[(4,5)]=R[(5,4)]=-10
R[(5,6)]=R[(6,5)]=-2
R[(6,7)]=R[(7,6)]=-1
R[(6,8)]=R[(8,6)]=-6
R[(7,8)]=R[(8,7)]=-7
#-----------------------------------基本参数-----------------------------------
samples=10000;#训练样本
lr=0.1#学习率
r=1#折扣系数
#-----------------------------------函数区域-----------------------------------
#随机策略训练模型
def Q_random_train(samples,lr,r):
for i in range(samples):
act=random.choice(list(R.keys()))
s1=act[0]
s2=act[1]
Q[s1][s2]+=lr*(R[act]+r*Q[s2].max()-Q[s1][s2])
#最优策略
def Q_optimal(s1,s2):
path=[s1]
while 1:
s1=Q[s1].argmax()
if s1==s2:
path.append(s1)
break
if s1 in path:
path.clear()
break
path.append(s1)
return path
#-----------------------------------结果区域-----------------------------------
Q_random_train(samples,lr,r)
Q_optimal(0,4)
文章出处登录后可见!
已经登录?立即刷新