一、大数据时代
- 短短几年间,大数据就以一日千里的发展速度,快速实现了从概念到落地,直接带动了相关产业井喷式发展。全球多家研究机构统计数据显示,大数据产业将迎来发展黄金期:IDC预计,大数据和分析市场将从2016年的1300亿美元增长到2020年的2030亿美元以上;中国报告大厅发布的大数据行业报告数据也说明,自2017年起,我国大数据产业迎来发展黄金期,未来2~3年的市场规模增长率将保持在35%左右。
- 数据采集、数据存储、数据挖掘、数据分析等大数据技术在越来越多的行业中得到应用,随之而来的就是大数据人才问题的凸显。麦肯锡预测,每年数据科学专业的应届毕业生将增加7%,然而仅高质量项目对于专业数据科学家的需求每年就会增加12%,完全供不应求。根据《人民日报》的报道,未来3~5年,中国需要180万数据人才,但目前只有约30万人,人才缺口达到150万之多。
二、大数据处理流程
数据采集[Data Collection](人工采集、网络爬虫、系统日志……)数据清洗[Data Cleaning]数据分析[Data Analysis](MapReduce、Spark、Flink、Numpy、Pandas)数据挖掘[Data Mining](算法 – 机器学习[Machine Learning])数据可视化[Data Visualization](Excel、ECharts、Matplotlib……)

三、可视化概述
- 一图胜千言,数据可视化在表述方面胜过千万条枯燥的数据。近年来,虽然数据思维已经深刻影响并改变了各行各业的传统思维方式,但现有的可视化技术还远远无法满足用户的期望。数据密集型科学研究已上升到与科学实验、理论分析、计算模拟并列的科学研究“第四范式”,也拓展了数据可视化学科的内涵和外延,大大推动了数据可视化学科向着更深层次不断迈进。
- 可视化技术为大数据分析提供了一种更加直观的挖掘、分析与展示手段,有助于发现大数据中蕴含的规律,有助于大数据应用落地。特别是一些监控中心、指挥中心、调度中心等重要场所,大屏幕显示系统已经成为大数据可视化不可或缺的核心基础系统。近年来,全球智能技术发展突飞猛进,发展人工智能已经提升到国家战略高度。大数据可视化在智慧城市、智慧交通、网络安全、航天领域等得到了更加广泛的应用。
- 可视化是对数据的一种完美的诠释。我们不仅要呈现出数据美好的一面,更重要的是要透过数据,理解数据的丰富内涵,洞察数据中蕴含的奥秘,为更深刻地理解世界、帮助辅助决策提供技术支持,在各行业及生活中,实现用数据说话,用数据讲道理。
- 数据既可以是抽象的,也可以是异常美丽的。例如,伦敦地铁图、拿破仑进军莫斯科流图及春运迁徙图等,都诠释了数据的美。可视化技术为大数据分析提供了一种更加直观的挖掘、分析与展示手段,有助于发现大数据中蕴含的规律。
- “可视化”是目的,其技术手段复杂多样。因此,数据可视化的概念应加以扩展,学习数据可视化不应仅仅局限于“可视化”,可视化过程中的数据采集、分析、治理、管理、挖掘等各个技术环节都要融会贯通。
- 数据是抽象的,有时也可以是异常美丽的。可视化技术为大数据分析提供了一种更加直观的挖掘、分析与展示手段,有助于发现大数据中蕴含的规律,在各行各业均得到了广泛的应用。可视化和可视分析利用人类视觉认知的高通量特点,通过图形和交互的形式表现信息的内在规律及其传递、表达的过程,充分结合人的智能和机器的计算分析能力,是人们理解复杂现象、诠释复杂数据的重要手段和途径。数据可视化是大数据的主要理论基础,也是大数据的关键技术,已经成为当前大数据分析的重要研究领域。因此,大数据可视化能力是大数据领域的科学家、工程技术人员的核心竞争力之一。
四、可视化原则
- 严复提出翻译三原则:信(Faithful)、达(Smooth)、雅(Elegant)
- 可视化在表达信息时应该遵循三个原则:正确(Correct)、清晰(Clear)、优雅(Elegant)
- 清晰而有效地在大数据与用户之间传递和沟通信息是数据可视化的重要目标。
- 数据可视化要达到真、善、美的平衡。信息设计的先驱者,耶鲁大学统计学和政治学教授爱德华·塔夫特(Edward Tufte)认为,好的可视化作品与好的翻译一样,应该做到三个标准:信、达、雅。简单地说就是:一是真实地表达丰富的数据,避免扭曲数据(Avoid distorting data);二是目的清晰,发人深省,激发观察者去比较不同的数据内容(Serve a clear purpose and encourage the eye to compare);三是有美感(Aesthetic)。
五、可视化工具
- 数据可视化分层:从市场上的数据可视化工具来看,数据可视化分为 5 个层级,即数据统计图表化、数据结果展示化、数据分析过程可视化、VR/AR 阶段虚拟现实的可视化、借助人工智能发现大数据背后隐含的规律并产生洞见。
(一)数据统计图表化工具
- 这个阶段是使用传统的统计性图表来展示数据,其特点是统计数据的表达都是历史发生的,把过程中的一些信息省略掉,有可能会给出正确的指导,也有可能会给出错误的指导,历史统计偶尔会骗人。所以“数据可视化”只能看历史数据的统计和解读,类似于盲人摸象,从而无法做出正确的决策。其中的代表作是Highcharts、Echarts 等图表库,甚至 Excel 也是典型的数据可视化工具。这类框架的优点:最成熟的可视化工具,包含的图表都是常见图表,易于用户理解和开发人员使用;开发成本低,对图形技术和数据知识的要求不高。其缺点同样明显:配置项复杂、扩展性差、图表表现单一;适用范围窄,对树状、网状结构支持差;数据维度和数据量的展示都受限。
(二)数据结果展示化工具
- 随着数据业务对可视化需求的要求越来越高,可视化的范围已经不仅仅限制于统计性图表,业务上需要显示更多维度的数据、更多样的图形展示数据。这就需要业务方能够根据自己的需求定制图表,这个阶段的工具主要有 D3.js、rapheal 等框架,这类框架提供了精细力度的图形工具和更多的图形算法。这类框架的优点:功能强大、交互性强、适用范围广;集成了大量的图形算法、可视化算法,降低复杂的图表的成本。此类框架同样存在一些共性的问题:需要细粒度的操作图形,学习、开发成本高;个性化需求多,复用性差。
- 当前,数据可视化技术正在迅速发展,已经出现了众多的数据可视化软件和工具,如Tableau、Datawatch、Platfora、R、D3.js、Processing.js、Gephi、Echarts、大数据魔镜等。许多商业的大数据挖掘和分析软件也包括了数据可视化功能,如 IBM SPSS、SAS Enterprise Miner等。数据可视化与信息图形、信息可视化、科学可视化及统计图形密切相关。数据可视化领域的起源,可以追溯到 20 世纪 50 年代计算机图形学的早期。当时,人们利用计算机创建出了首批图形图表。
六、案例演示
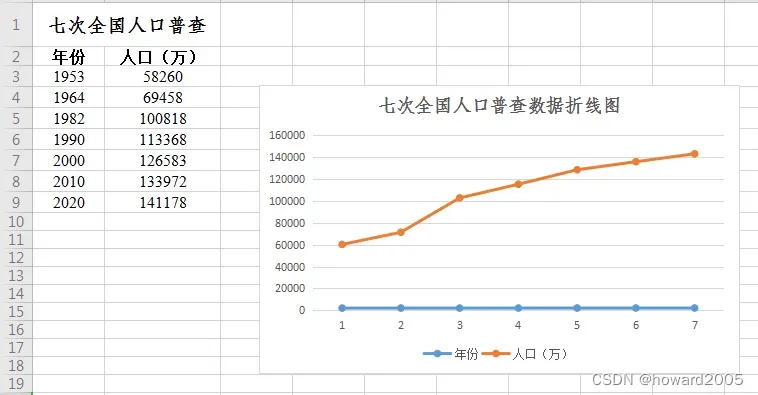
任务1、用文字、表格和图表三种方式来表达7次全国人口普查数据

1、文字方式
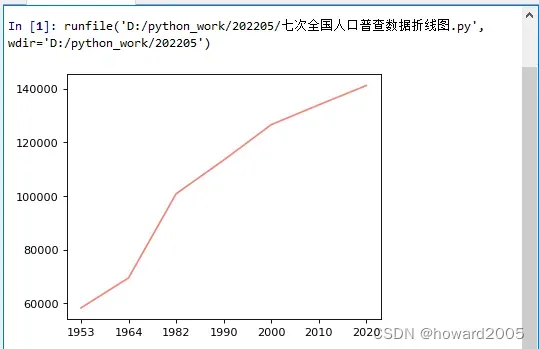
- 1953年第一次普查数据58260万
- 1964年第二次普查数据69458万
- 1982年第三次普查数据100818万
- 1990年第四次普查数据113368万
- 2000年第五次普查数据126583万
- 2010年第六次普查数据133972万
- 2020年第七次普查数据141178万
2、表格方式
| 年份 | 人口(万) |
|---|---|
| 1953 | 58260 |
| 1964 | 69458 |
| 1982 | 100818 |
| 1990 | 113368 |
| 2000 | 126583 |
| 2010 | 133972 |
| 2020 | 141178 |
3、图表方式
(1)利用Excel
(2)利用ECharts
- 创建网页
七次全国人口普查.html

<!DOCTYPE html>
<html>
<head>
<title>七次全国人口普查数据</title>
<script src="js/echarts.min.js"></script>
<script src="js/jquery.min.js"></script>
<style>
#box {
width: 600px;
height: 400px;
border: 1px solid cornflowerblue;
}
</style>
</head>
<body>
<div id="box">
</div>
<script>
var chartDom = document.getElementById('box');
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: '七次全国人口普查数据折线图',
subtext: '官方数据',
left: 'center'
},
xAxis: {
'name': '年',
data: ['1953', '1964', '1982', '1990', '2000', '2010', '2020']
},
yAxis: {
'name': '万人'
},
series: [
{
data: [58260, 69458, 100818, 113368, 126583, 133972, 141178],
type: 'line' // 图表类型 - 折线图
}
],
tooltip: {
formatter: '[{b}年:{c}万人]'
}
};
option && myChart.setOption(option);
</script>
</body>
</html>
- 浏览网页,查看结果
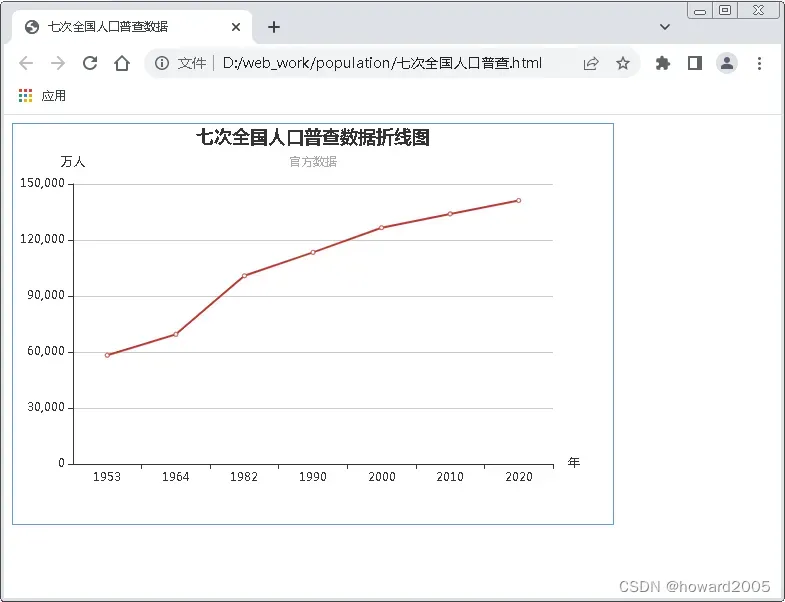
- 鼠标移到节点上,会有工具小贴士弹出

- 现在我们换一种方式,读取json文件中的数据来进行可视化
- 在
data目录下创建population.json
[
{
"year": "1953",
"population": 58260
},
{
"year": "1964",
"population": 69458
},
{
"year": "1982",
"population": 100818
},
{
"year": "1990",
"population": 113368
},
{
"year": "2000",
"population": 126583
},
{
"year": "2010",
"population": 133972
},
{
"year": "2020",
"population": 141178
}
]
- 创建
七次全国人口普查2.html
<!DOCTYPE html>
<html>
<head>
<title>七次全国人口普查数据2</title>
<script src="js/echarts.min.js"></script>
<script src="js/jquery.min.js"></script>
<style>
#box {
width: 600px;
height: 400px;
border: 1px solid cornflowerblue;
}
</style>
</head>
<body>
<div id="box">
</div>
<script>
var chartDom = document.getElementById('box');
// 读取JSON文件数据
$.get('data/population.json', function (data) {
// 定义两个数组
years = [];
populations = [];
// 将json数据写入数组
for (var i = 0; i < data.length; i++) {
years.push(data[i].year);
populations.push(data[i].population);
}
var myChart = echarts.init(chartDom);
var option;
option = {
title: {
text: '七次全国人口普查数据折线图',
subtext: '官方数据',
left: 'center'
},
xAxis: {
'name': '年',
data: years
},
yAxis: {
'name': '万人'
},
series: [
{
data: populations,
type: 'line' // 图表类型 - 折线图
}
],
tooltip: {
formatter: '[{b}年:{c}万人]'
}
};
option && myChart.setOption(option);
});
</script>
</body>
</html>
- 浏览网页,查看结果
- 按
F12,进入调试模式
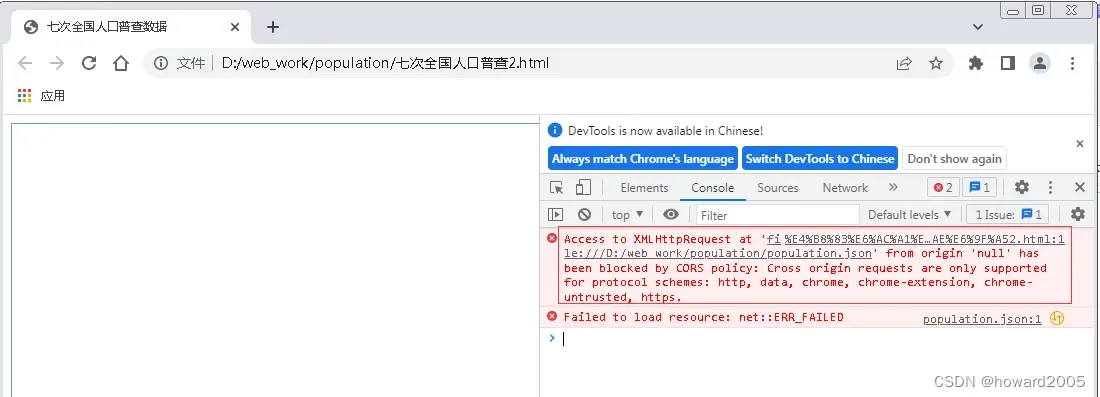
- 解决跨域问题(访问本地json文件,采用的是
file://文件协议,服务器启动采用的http或https协议,协议不同,Chrome认为是跨域,因而禁止) - 启动Chrome浏览器,添加参数
--allow-file-access-from-files

- 启动Chrome浏览器,浏览
七次全国人口普查2.html

(3)利用Matplotlib
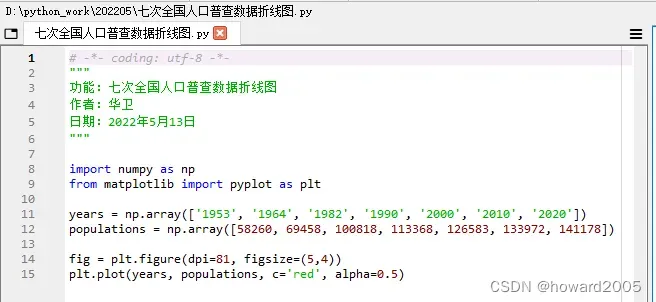
- 编写程序,实现功能
- 运行程序,查看结果
七、拓展阅读
(一)斯诺的霍乱地图
- 英国麻醉学家、流行病学家以及麻醉医学和公共卫生间医院的开拓者约翰·斯诺(John Snow,1813—1858)采用数据可视化的方法研究伦敦西部西敏市苏活区霍乱,并发现了霍乱的传播途径及预防措施。1854 年,霍乱在伦敦 Soho 区爆发,并迅速传播,当时对霍乱起因的主流意见仅仅是空气传播,斯诺通过研究霍乱病死者的日常生活情况找到他们的共同行为模式,在伦敦地图上手工绘制宽街水泵附近的霍乱爆发热点,将水质研究、霍乱死亡统计分布图与地图对比分析,发现霍乱可以由水源传播,并由此制作出世界上第一份统计地图——约翰·斯诺伦敦霍乱地图,发现了霍乱与饮用不洁水的关系。在斯诺的呼吁下,政府及时关闭了不洁水源,有效制止了霍乱的流行。斯诺还推荐了几种实用的预防措施,如清洗肮脏的衣被、洗手和将水烧开饮用等,效果良好。虽然约翰·斯诺没有发现导致霍乱的病原体,但他创造性地使用空间统计学找到了传染源,并以此证明了这种方法的价值。今天,绘制地图已成为医学地理学及传染学中一项基本的研究方法。“斯诺的霍乱地图”已成为一个经典案例。
文章出处登录后可见!
已经登录?立即刷新