0. 前言
针对深度学习模型的边缘、移动端部署,模型量化已经成为必不可少的压缩手段。一方面,将模型权重量化为低比特,可缓解模型存储的负担(例如INT8量化的理论压缩比为4倍);另一方面,将W与A均量化为低比特,可通过专用整形计算单元或加速指令实现网络层的推理加速(例如NV GPU的TensorCore单元),并节省运行时内存的Overhead。
模型量化可分为QAT与PTQ两种实现方式,QAT依赖于训练集的感知微调(需要为Forward阶段设计低量化误差的Quantizer,为Backward阶段设计缓解Gradient mismatch的Estimator),PTQ则是训练后量化策略(包括Data-free与Label-free两种形式)。出于用户隐私与数据安全考虑,大多数应用场景提供少量无标注数据以支持Label-free PTQ,或者不提供任何数据仅支持Data-free PTQ。Data-free Quantization需要借助Pre-trained Model蕴含的信息执行有效量化,即达成量化目标的同时、尽量减少精度损失,典型代表为生成式方法(Generative Method)。生成式方法通过对抗样本生成方式,能够合成接近真实分布的数据(作为量化的数据基础),并进一步通过优化方式求解量化参数、微调权重参数,以实现有效量化。
生成式方法(如GDFQ、ARC、Qimera、AIT等)的基本架构,充分利用了深度学习的”搭积木原理”或”模块化编程方式”,发挥了每个模块应有的功能价值。例如样本生成器借助了对抗样本生成思路,BN层蕴含原数据集的统计信息(CNN模型通常包含BN层,但Transformer模型通常不具备),Pre-trained model能够为Quantized model提供Soft label,Gumbel softmax的随机采样与可微分特点,等等。
1. Generative Low-bitwidth Data Free Quantization
Paper地址:https://arxiv.org/abs/2003.03603v3
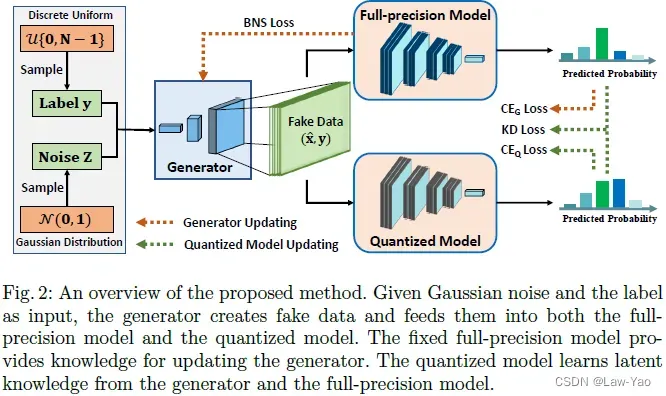
上图显示了GDFQ的基本原理,包含生成器训练与量化模型微调的联合实现。生成器产生合成数据,作为Pre-trained model与Quantized model的输入;Pre-trained model为生成器提供Classification boundary information与BN statistics,使合成样本接近真实数据分布;同时,Pre-trained model也为量化模型提供Soft-label,以增强量化训练;在生成器训练与量化模型微调期间,Pre-trained model的参数冻结。具体描述如下:
- GDFQ采用非对称均匀量化方式(Hard quantizer)实现W与A的k-bit量化:
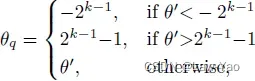
![]()
![]()
![]()
- 生成器以随机噪声矢量z与预设标签y作为输入,产生合成数据:
![]()
- 基于Cross entropy loss,Pre-trained model为生成器提供Classification boundary information matching:
![]()
- 基于BN statistics,Pre-trained model为生成器提供Distribution information matching,为此需要在线统计BN层的输入Feature maps的均值与方差:
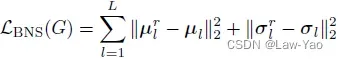
- 以生成器的合成数据作为输入,量化模型执行微调时,优化目标包括Cross entropy loss与KD loss,并且在微调期间冻结量化模型的BN层参数:
![]()
![]()
- 生成器训练与量化模型微调的Total loss与算法实现如下:
![]()
![]()

2. Qimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Paper地址:https://arxiv.org/abs/2111.02625
GitHub链接:https://github.com/iamkanghyunchoi/qimera
处于决策边界的样本(Boundary supporting samples)属于Hard samples,其语义模棱两可,但有助于增强模型训练、提升模型鉴别力。GDFQ等生成式方法产生的合成数据,由于缺乏Boundary supporting samples,因此效果有限,如下图所示:
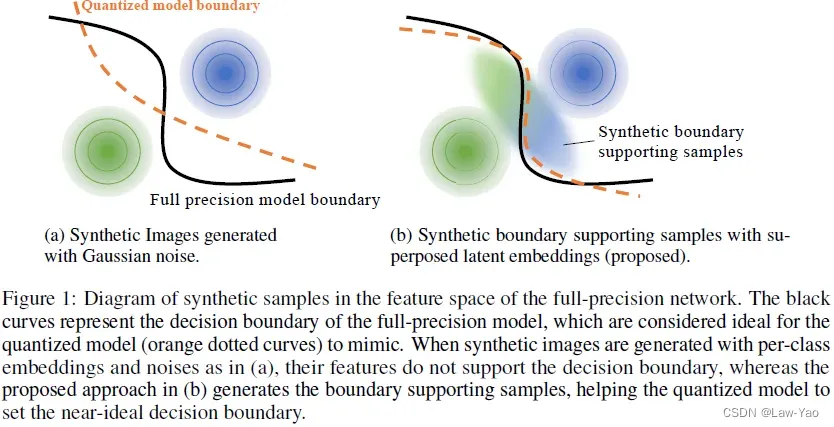
Qimera通过使用Superposed latent embeddings,能够使生成器合成Boundary supporting samples,从而增强Data-free quantization的量化效果,如下所示:
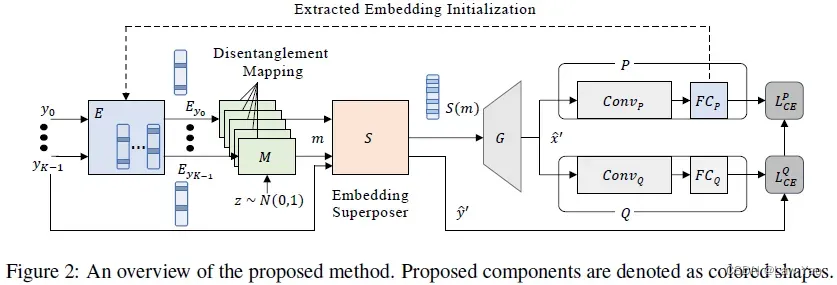
3. AutoReCon: Neural Architecture Search-based Reconstruction for Data-free
Paper地址:https://arxiv.org/abs/2105.12151
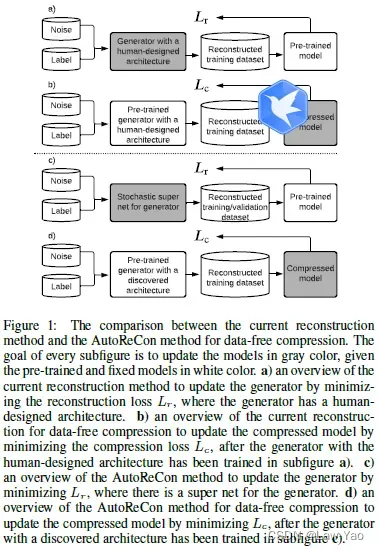
如上所示,AutoReCon通过将网络结构搜索(DARTS like method)引入到Generative Data-free Quantization的生成器训练环节,能够提升生成器合成样本的有效性,从而增强量化效果。具体原理如下:
- 与GDFQ相同,生成器训练的优化目标包含了Classification boundary information matching与BN statistics matching,Loss function如下:
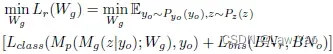
- 基于DARTS like method,生成器的结构搜索、按两步交替方式进行,分别优化结构参数Ag与权重参数Wg(优化Ag阶段合成验证集,优化Wg阶段合成训练集):
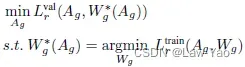
- 搜索空间:
- 生成器由Macro-architecture堆叠而成,每个Macro-architecture表示Convolutional Block,且内含5个Nodes;
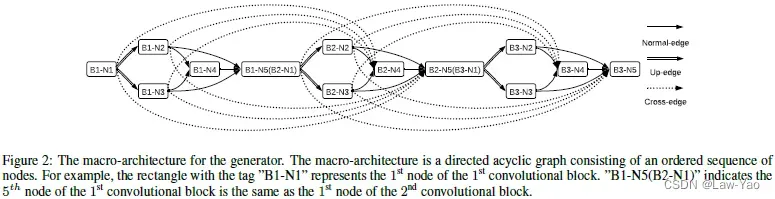
- 另外,又将生成器表示为
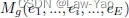 ,即包含E条Edge,不同的Edge各自连接至相应的Node,且每个Node负责将相连接Edges的输出予以累加;
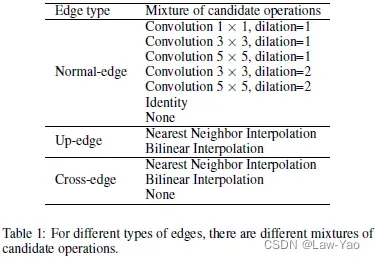
,即包含E条Edge,不同的Edge各自连接至相应的Node,且每个Node负责将相连接Edges的输出予以累加; - Edge类型包括Normal-edge(维度不变)、Up-edge(空间上采样)与Cross-edge(构造残差连接)。为了实现Layer-wise search,每条Edge表示不同Candidate operations的融合(表示第i条Edge的第j个Operation):
- 生成器由Macro-architecture堆叠而成,每个Macro-architecture表示Convolutional Block,且内含5个Nodes;
![]()
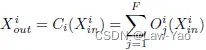
- 搜索策略:
- 采用DARTS-like method,为每条Edge的每个Operation、设定了可微分的结构参数
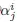 ,且Softmax概率为:
,且Softmax概率为: 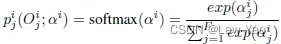
- 引入了Gumbel softmax采样,以确保可微分搜索、子网络采样的随机性/公平性、以及结构搜索的稀疏化:
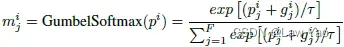
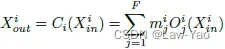
- 通过两步交替方式进行优化求解:
- 采用DARTS-like method,为每条Edge的每个Operation、设定了可微分的结构参数
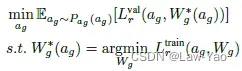
- 结合生成器的结构搜索、与Quantized model的量化微调,AutoReCon总体实现流程如下:

4. It’s All In the Teacher: Zero-Shot Quantization Brought Closer to the Teacher
Paper地址:https://arxiv.org/abs/2203.17008
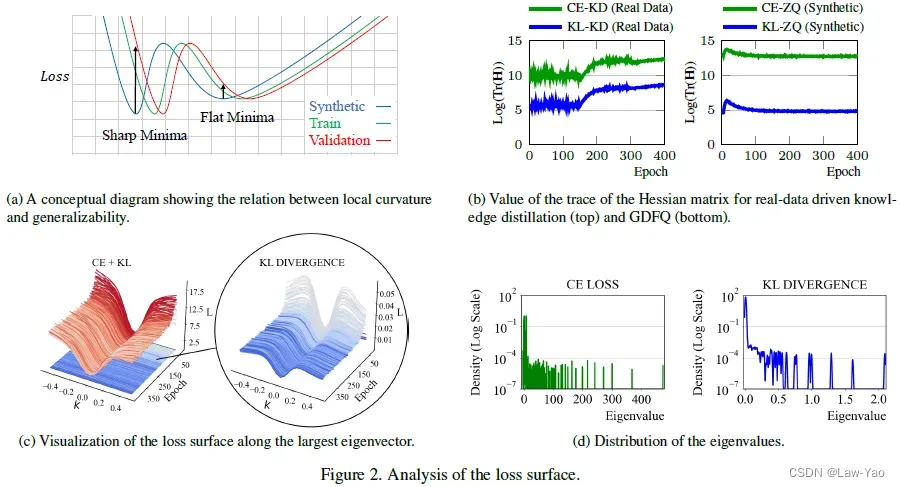
针对GDFQ的优化方式:
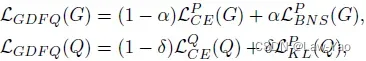
首先,量化模型训练的CE loss与KL loss,在梯度空间中存在较大的角度距离,因此较难同时优化两个Loss;其次,基于Hessian矩阵的分析,KL loss具备更平滑的Loss曲面,更易于收敛。因此,在执行量化模型训练时,仅采用了KL loss,即只基于Pre-trained model的Soft label执行蒸馏训练。然而在训练过程中,真正实现Cross the rounding threshold、完成量值变化的参数数量占比很低,且随着梯度变小,参数越难实现量值变化。
为了克服KL-only训练遇到的参数量值较难变化的问题,文章设计了Gradient inundation(GI)方法,本质上是一种基于Gradient scaling的梯度补偿方法:
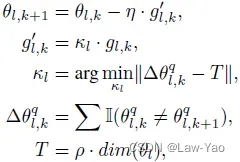
其中![]() 是预定义的比例系数,
是预定义的比例系数,![]() 表示参数数量,则
表示参数数量,则![]() 表示引起参数产生做够多的量值变化的阈值;
表示引起参数产生做够多的量值变化的阈值;![]() 表示指示函数,发生量值变化时取值为1,否则为0。目标便是通过寻找最佳的
表示指示函数,发生量值变化时取值为1,否则为0。目标便是通过寻找最佳的![]() ,使得足够多的参数能够实现Cross the rounding threshold,Two-step heuristic求解方法如下:
,使得足够多的参数能够实现Cross the rounding threshold,Two-step heuristic求解方法如下:
- 首先,从
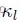 取值为1.0开始;当
取值为1.0开始;当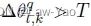 时,乘以2;
时,乘以2; - 然后,为满足
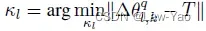 ,采用二分查找法在
,采用二分查找法在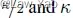 之间 搜索最佳的。另外,为了稳定早期训练的稳定,需要引入GI的Warm-up(处于Generator的Warm-up之后);
之间 搜索最佳的。另外,为了稳定早期训练的稳定,需要引入GI的Warm-up(处于Generator的Warm-up之后);
Gradient Inundation的代码实现如下:
@torch.no_grad()
def step(self, closure=None):
"""Performs a single optimization step.
Args:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
alpha_total = []
for group in self.param_groups:
params_with_grad = []
d_p_list = []
momentum_buffer_list = []
weight_decay = group['weight_decay']
momentum = group['momentum']
dampening = group['dampening']
nesterov = group['nesterov']
lr = group['lr']
for i, p in enumerate(group['params']):
if p.grad is not None:
state = self.state[p]
if 'momentum_buffer' not in state:
momentum_buffer_list.append(None)
b_t = p.grad
else:
momentum_buffer_list.append(state['momentum_buffer'])
b_t = self.settings.momentum * state['momentum_buffer'] + p.grad
g_t = p.grad + self.settings.momentum * b_t # Nesterov
x_transform = p.clone().contiguous().view(p.shape[0], -1) ## outchannels
w_min = x_transform.min(dim=1).values
w_max = x_transform.max(dim=1).values
scale, zero_point = asymmetric_linear_quantization_params(self.settings.qw, w_min, w_max)
new_quant_x = linear_quantize(p, scale, zero_point, inplace=False)
n = 2 ** (self.settings.qw - 1)
new_quant_x = torch.clamp(new_quant_x, -n, n - 1)
alpha = 1.0
num_param = p.numel()
perc = get_perc(p, new_quant_x, alpha, lr, g_t, num_param,self.settings.qw)
if perc < self.settings.passing_threshold:
while True:
alpha = alpha * 2
perc = get_perc(p, new_quant_x, alpha, lr, g_t, num_param,self.settings.qw)
if perc >= self.settings.passing_threshold:
break
if self.disable_adalr and alpha>100:
break
start = alpha / 2
end = alpha
for i in range(self.settings.alpha_iter):
mid = (start+end) / 2
perc = get_perc(p, new_quant_x, mid, lr, g_t, num_param,self.settings.qw)
if torch.abs(perc-self.settings.passing_threshold) < self.settings.passing_threshold/100:
break
if perc < self.settings.passing_threshold:
start = mid
else:
end = mid
alpha = mid
alpha_total.append(alpha)
params_with_grad.append(p)
d_p_list.append(p.grad)
gisgd(
params_with_grad,
d_p_list,
momentum_buffer_list,
weight_decay=weight_decay,
momentum=momentum,
lr=lr,
dampening=dampening,
nesterov=nesterov,
alpha_list=alpha_total,
)5. Miscellaneous
——– 模型压缩方面,更为详细的讨论,请参考:
深度学习模型压缩与优化加速(Model Compression and Acceleration Overview)_AI Flash-CSDN博客_深度学习模型压缩
文章出处登录后可见!