本文首发于公众号【DeepDriving】,欢迎关注。
0. 引言
我之前写的文章《基于YOLOv8分割模型实现垃圾识别》介绍了如何使用YOLOv8分割模型来实现垃圾识别,主要是介绍如何用自定义的数据集来训练YOLOv8分割模型。那么训练好的模型该如何部署呢?YOLOv8分割模型相比检测模型多了一个实例分割的分支,部署的时候还需要做一些后处理操作才能得到分割结果。
本文将详细介绍如何使用onnxruntime框架来部署YOLOv8分割模型,为了方便理解,代码采用Python实现。
1. 准备工作
-
安装onnxruntime
onnxruntime分为GPU版本和CPU版本,均可以通过pip直接安装:pip install onnxruntime-gpu #安装GPU版本 pip install onnxruntime #安装CPU版本注意:
GPU版本和CPU版本建议只选其中一个安装,否则默认会使用CPU版本。 -
下载
YOLOv8分割模型权重Ultralytics官方提供了用COCO数据集训练的模型权重,我们可以直接从官方网站https://docs.ultralytics.com/tasks/segment/下载使用,本文使用的模型为yolov8m-seg.pt。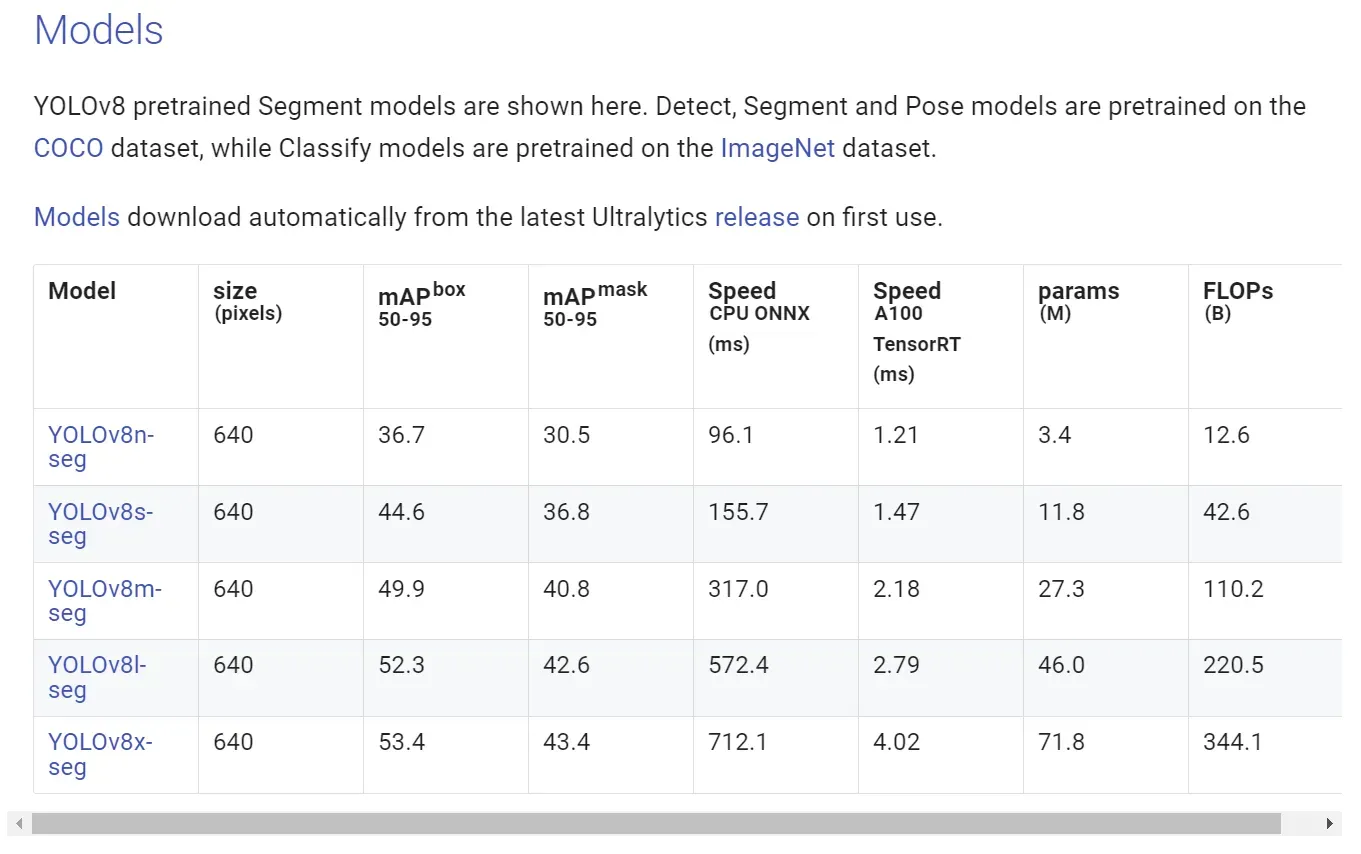
-
转换onnx模型
调用下面的命令可以把
YOLOv8m-seg.pt模型转换为onnx格式的模型:yolo task=segment mode=export model=yolov8m-seg.pt format=onnx转换成功后得到的模型为
yolov8m-seg.onnx。
2. 模型部署
2.1 加载onnx模型
首先导入onnxruntime包,然后调用其API加载模型即可:
import onnxruntime as ort
session = ort.InferenceSession("yolov8m-seg.onnx", providers=["CUDAExecutionProvider"])
因为我使用的是GPU版本的onnxruntime,所以providers参数设置的是"CUDAExecutionProvider";如果是CPU版本,则需设置为"CPUExecutionProvider"。
模型加载成功后,我们可以查看一下模型的输入、输出层的属性:
for input in session.get_inputs():
print("input name: ", input.name)
print("input shape: ", input.shape)
print("input type: ", input.type)
for output in session.get_outputs():
print("output name: ", output.name)
print("output shape: ", output.shape)
print("output type: ", output.type)
结果如下:
input name: images
input shape: [1, 3, 640, 640]
input type: tensor(float)
output name: output0
output shape: [1, 116, 8400]
output type: tensor(float)
output name: output1
output shape: [1, 32, 160, 160]
output type: tensor(float)
从上面的打印信息可以知道,模型有一个尺寸为[1, 3, 640, 640]的输入层和两个尺寸分别为[1, 116, 8400]和[1, 32, 160, 160]的输出层。
2.2 数据预处理
数据预处理采用OpenCV和Numpy实现,首先导入这两个包
import cv2
import numpy as np
用OpenCV读取图片后,把数据按照YOLOv8的要求做预处理
image = cv2.imread("soccer.jpg")
image_height, image_width, _ = image.shape
input_tensor = prepare_input(image, model_width, model_height)
print("input_tensor shape: ", input_tensor.shape)
其中预处理函数prepare_input的实现如下:
def prepare_input(bgr_image, width, height):
image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (width, height)).astype(np.float32)
image = image / 255.0
image = np.transpose(image, (2, 0, 1))
input_tensor = np.expand_dims(image, axis=0)
return input_tensor
处理流程如下:
1. 把OpenCV读取的BGR格式的图片转换为RGB格式;
2. 把图片resize到模型输入尺寸640x640;
3. 对像素值除以255做归一化操作;
4. 把图像数据的通道顺序由HWC调整为CHW;
5. 扩展数据维度,将数据的维度调整为NCHW。
经过预处理后,输入数据input_tensor的维度变为[1, 3, 640, 640],与模型的输入尺寸一致。
2.3 模型推理
输入数据准备好以后,就可以送入模型进行推理:
outputs = session.run(None, {session.get_inputs()[0].name: input_tensor})
前面我们打印了模型的输入输出属性,可以知道模型有两个输出分支,其中一个output0是目标检测分支,另一个output1则是实例分割分支,这里打印一下它们的尺寸看一下
#squeeze函数是用于删除shape中为1的维度,对output0做transpose操作是为了方便后续操作
output0 = np.squeeze(outputs[0]).transpose()
output1 = np.squeeze(outputs[1])
print("output0 shape:", output0.shape)
print("output1 shape:", output1.shape)
结果如下:
output0 shape: (8400, 116)
output1 shape: (32, 160, 160)
处理后目标检测分支的维度为[8400, 116],表示模型总共可以检测出8400个目标(大部分是无效的目标),每个目标包含116个参数。刚接触YOLOv8分割模型的时候可能会对116这个数字感到困惑,这里有必要解释一下:每个目标的参数包含4个坐标属性(x,y,w,h)、80个类别置信度和32个实例分割参数,所以总共是116个参数。实例分割分支的维度为[32, 160, 160],其中第一个维度32与目标检测分支中的32个实例分割参数对应,后面两个维度则由模型输入的宽和高除以4得到,本文所用的模型输入宽和高都是640,所以这两个维度都是160。
2.4 后处理
首先把目标检测分支输出的数据分为两个部分,把实例分割相关的参数从中剥离。
boxes = output0[:, 0:84]
masks = output0[:, 84:]
print("boxes shape:", boxes.shape)
print("masks shape:", masks.shape)
boxes shape: (8400, 84)
masks shape: (8400, 32)
然后实例分割这部分数据masks要与模型的另外一个分支输出的数据output1做矩阵乘法操作,在这之前要把output1的维度变换为二维。
output1 = output1.reshape(output1.shape[0], -1)
masks = masks @ output1
print("masks shape:", masks.shape)
masks shape: (8400, 25600)
做完矩阵乘法后,就得到了8400个目标对应的实例分割掩码数据masks,可以把它与目标检测的结果boxes拼接到一起。
detections = np.hstack([boxes, masks])
print("detections shape:", detections.shape)
detections shape: (8400, 25684)
到这里读者应该就能理解清楚了,YOLOv8模型总共可以检测出8400个目标,每个目标的参数包含4个坐标属性(x,y,w,h)、80个类别置信度和一个160x160=25600大小的实例分割掩码。
由于YOLOv8模型检测出的8400个目标中有大量的无效目标,所以先要通过置信度过滤去除置信度低于阈值的目标,对于满足置信度满足要求的目标还需要通过非极大值抑制(NMS)操作去除重复的目标。
objects = []
for row in detections:
prob = row[4:84].max()
if prob < 0.5:
continue
class_id = row[4:84].argmax()
label = COCO_CLASSES[class_id]
xc, yc, w, h = row[:4]
// 把x1, y1, x2, y2的坐标恢复到原始图像坐标
x1 = (xc - w / 2) / model_width * image_width
y1 = (yc - h / 2) / model_height * image_height
x2 = (xc + w / 2) / model_width * image_width
y2 = (yc + h / 2) / model_height * image_height
// 获取实例分割mask
mask = get_mask(row[84:25684], (x1, y1, x2, y2), image_width, image_height)
// 从mask中提取轮廓
polygon = get_polygon(mask, x1, y1)
objects.append([x1, y1, x2, y2, label, prob, polygon, mask])
// NMS
objects.sort(key=lambda x: x[5], reverse=True)
results = []
while len(objects) > 0:
results.append(objects[0])
objects = [object for object in objects if iou(object, objects[0]) < 0.5]
这里重点讲一下获取实例分割掩码的过程。
前面说了每个目标对应的实例分割掩码数据大小为160x160,但是这个尺寸是对应整幅图的掩码。对于单个目标来说,还要从这个160x160的掩码中去截取属于自己的掩码,截取的范围由目标的box决定。上面的代码得到的box是相对于原始图像大小,截取掩码的时候需要把box的坐标转换到相对于160x160的大小,截取完后再把这个掩码的尺寸调整回相对于原始图像大小。截取到box大小的数据后,还需要对数据做sigmoid操作把数值变换到0到1的范围内,也就是求这个box范围内的每个像素属于这个目标的置信度。最后通过阈值操作,置信度大于0.5的像素被当做目标,否则被认为是背景。
具体实现的代码如下:
def get_mask(row, box, img_width, img_height):
mask = row.reshape(160, 160)
x1, y1, x2, y2 = box
// box坐标是相对于原始图像大小,需转换到相对于160*160的大小
mask_x1 = round(x1 / img_width * 160)
mask_y1 = round(y1 / img_height * 160)
mask_x2 = round(x2 / img_width * 160)
mask_y2 = round(y2 / img_height * 160)
mask = mask[mask_y1:mask_y2, mask_x1:mask_x2]
mask = sigmoid(mask)
// 把mask的尺寸调整到相对于原始图像大小
mask = cv2.resize(mask, (round(x2 - x1), round(y2 - y1)))
mask = (mask > 0.5).astype("uint8") * 255
return mask
这里需要注意的是,160x160是相对于模型输入尺寸为640x640来的,如果模型输入是其他尺寸,那么上面的代码需要做相应的调整。
如果需要检测的是下面这个图片:

通过上面的代码可以得到最左边那个人的分割掩码为

但是我们需要的并不是这样一张图片,而是需要用于表示这个目标的轮廓,这可以通过OpenCV的findContours函数来实现。findContours函数返回的是一个用于表示该目标的点集,然后我们可以在原始图像中用fillPoly函数画出该目标的分割结果。

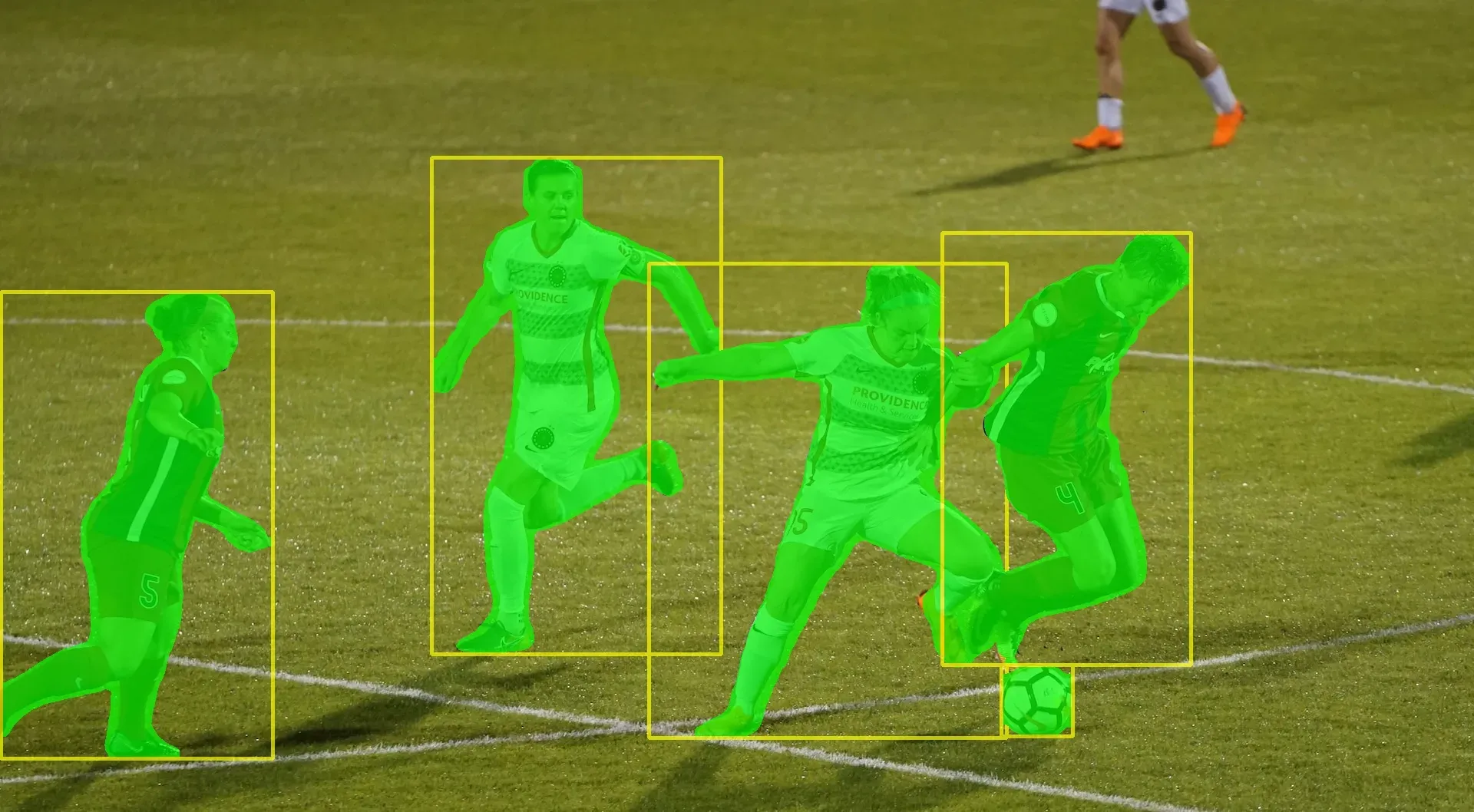
全部目标的检测与分割结果如下:
3. 一点其他的想法
从前面的部署过程可以知道,做后处理的时候需要对实例分割的数据做矩阵乘法、sigmoid激活、维度变换等操作,实际上这些操作也可以在导出模型的时候集成到onnx模型中去,这样就可以简化后处理操作。
首先需要修改ultralytics代码仓库中ultralytics/nn/modules/head.py文件的代码,把Segment类Forward函数最后的代码修改为:
if self.export:
output1 = p.reshape(p.shape[0], p.shape[1], -1)
boxes = x.permute(0, 2, 1)
masks = torch.sigmoid(mc.permute(0, 2, 1) @ output1)
out = torch.cat([boxes, masks], dim=2)
return out
else:
return (torch.cat([x[0], mc], 1), (x[1], mc, p))
然后修改ultralytics/engine/exporter.py文件中torch.onnx.export的参数,把模型的输出数量改为1个。
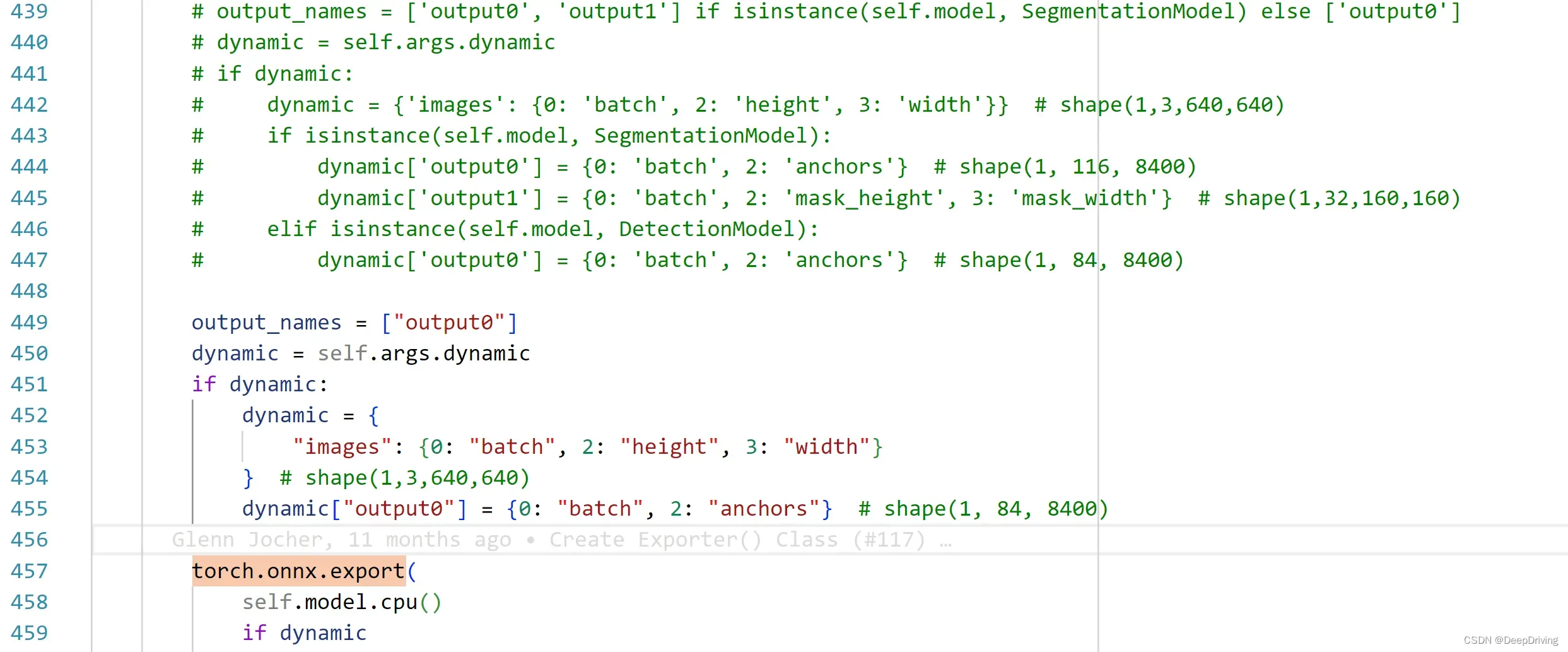
代码修改完成后,执行命令pip install -e '.[dev]'使之生效,然后再重新用yolo命令导出模型。用netron工具可以看到模型只有一个shape为[1,8400,25684]的输出。
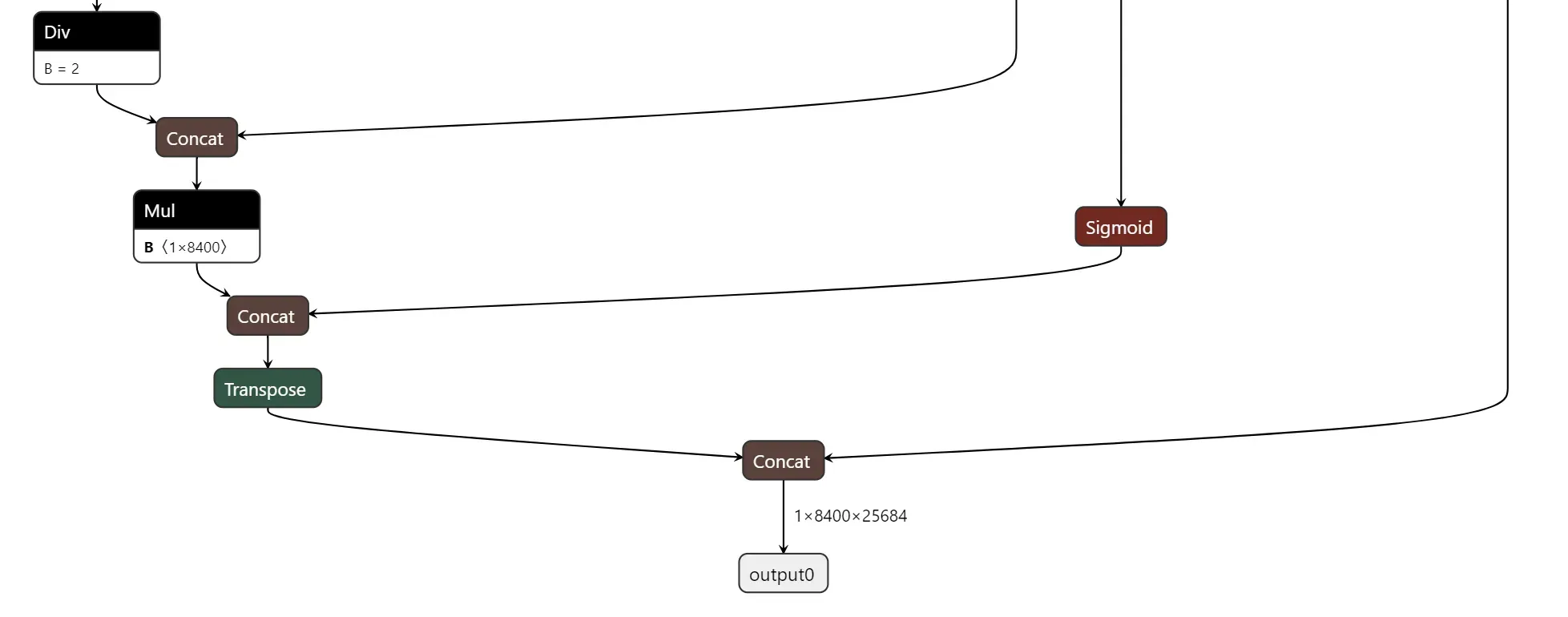
这样在后处理的时候就可以直接去解析box和mask了,并且mask的数据不需要进行sigmoid激活。
4. 参考资料
- How to implement instance segmentation using YOLOv8 neural network
- https://github.com/AndreyGermanov/yolov8_segmentation_python
版权声明:本文为博主作者:DeepDriving原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44613415/article/details/134822270