【引言】上一篇文章总结了表格型强化学习的主要内容,从这篇文章开始将介绍深度学习相关内容。先从数值优化开始吧,因为不管看起来多么高端的神经网络模型,最终都需要通过数值优化这个工具去训练。本质上还是在寻找极值、可行解等。
中英文术语对照表
| 中文 | 英文 | 缩写或符号 |
|---|---|---|
| 优化 | optimization | – |
| 梯度 | gradient | |
| 梯度下降 | gradient descent | – |
| 拟合 | fitting | – |
1 函数拟合
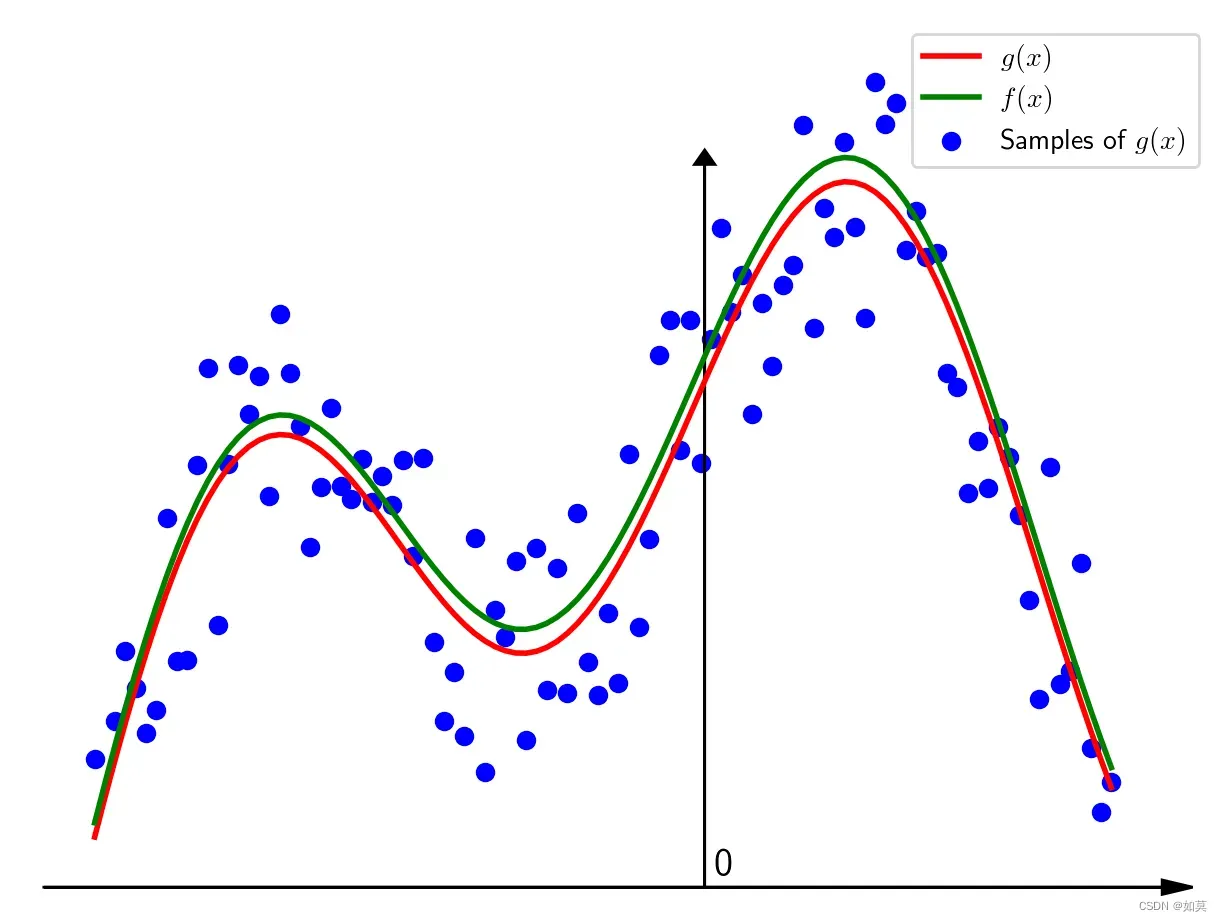
给出下面这样一条曲线当
,函数图像如下:
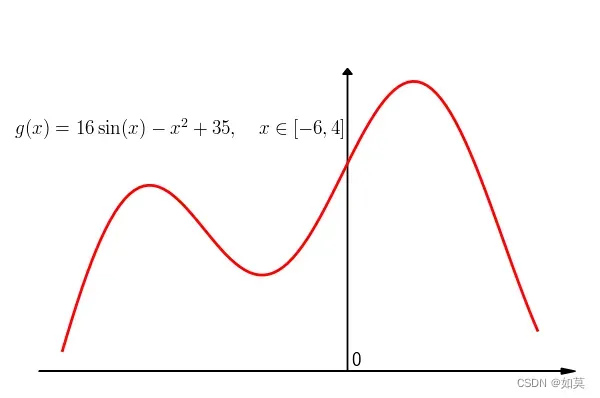
假设这是某个比较沙雕电阻的阻值随着电压而变化的函数,但是在测量的时候存在误差,因此若干次测量的结果如下图(在区间等间隔取样
个点)
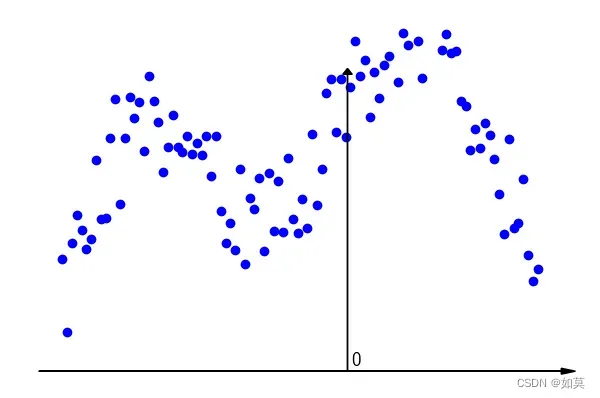
从这个三点图很难看出它们到底符合什么样的规律。假设根据先验知识,确定函数的形式为即用
去拟合采样自
的样点,其中
为待定函数参数。那么如何确定函数的
和
?
很自然的想法,猜!令,新得拟合曲线为如下,发现差异有点大。
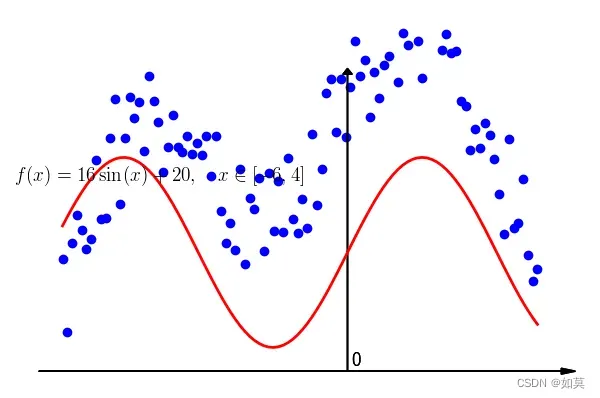
1.1 损失函数
那么怎么准确衡量拟合得好不好呢?这里将问题形式化,以便于准确描述。对自变量的不同取值
对应的函数值进行测量,得到
。
我们用于拟合的曲线,称为拟合曲线,用表示,将各个点到拟合曲线的纵轴距离均值用
表示,即
在测量数据确定的情况下,它只和参数
有关,因此可以写成
它反映了当前这组参数确定的拟合曲线与散点之间的符合程度,值越大,说明差异越大,拟合能力越差。因此,上面的式子称为损失函数(loss function)。
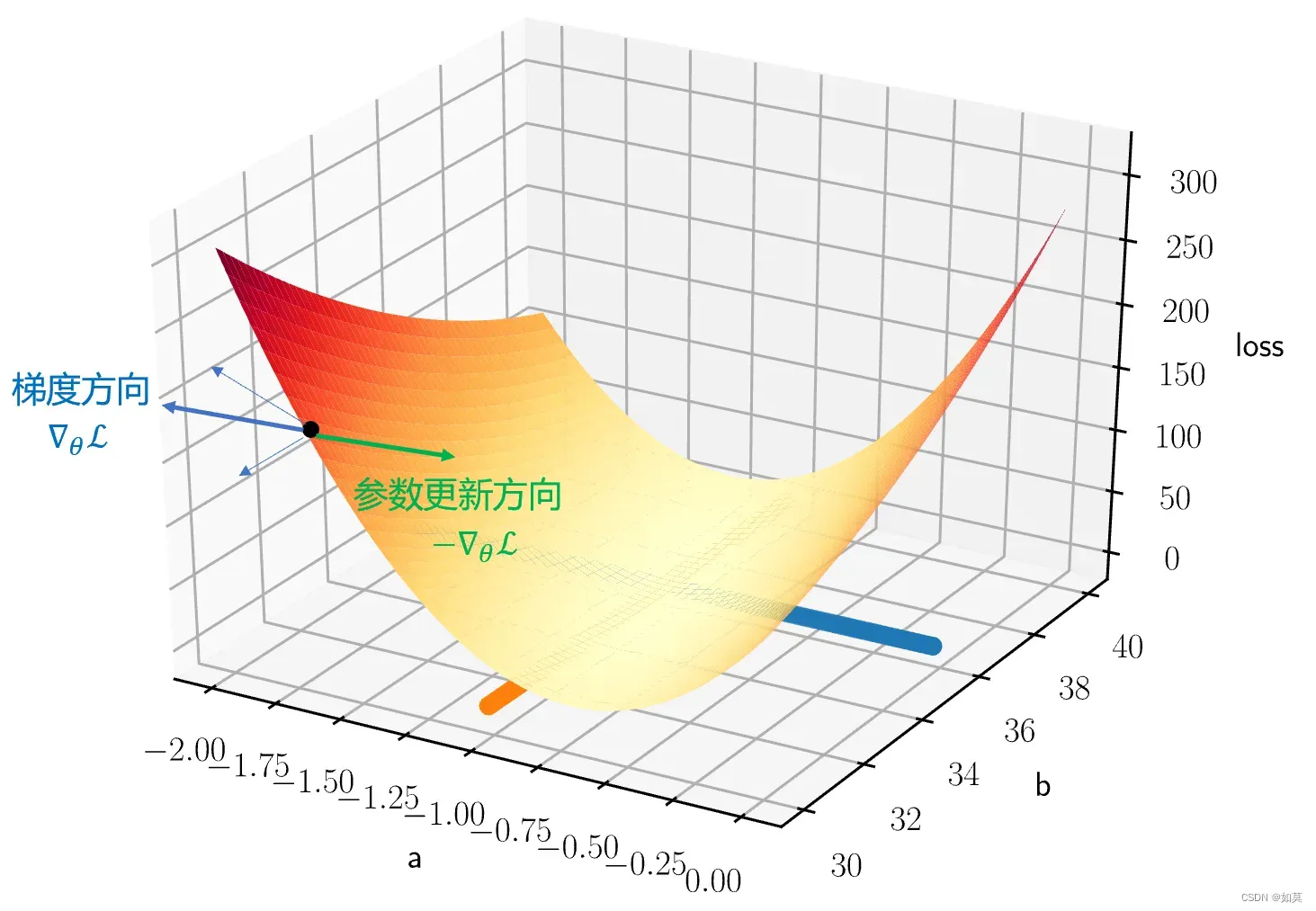
损失函数的值取决于参数,那么就固定间隔搜索吧。在区间[-2,0],
在区间[30,40]之间,按照步长为1进行搜索,那么组合起来就有400种情况。将所有情况下的损失计算出来,用三维图显示如下:
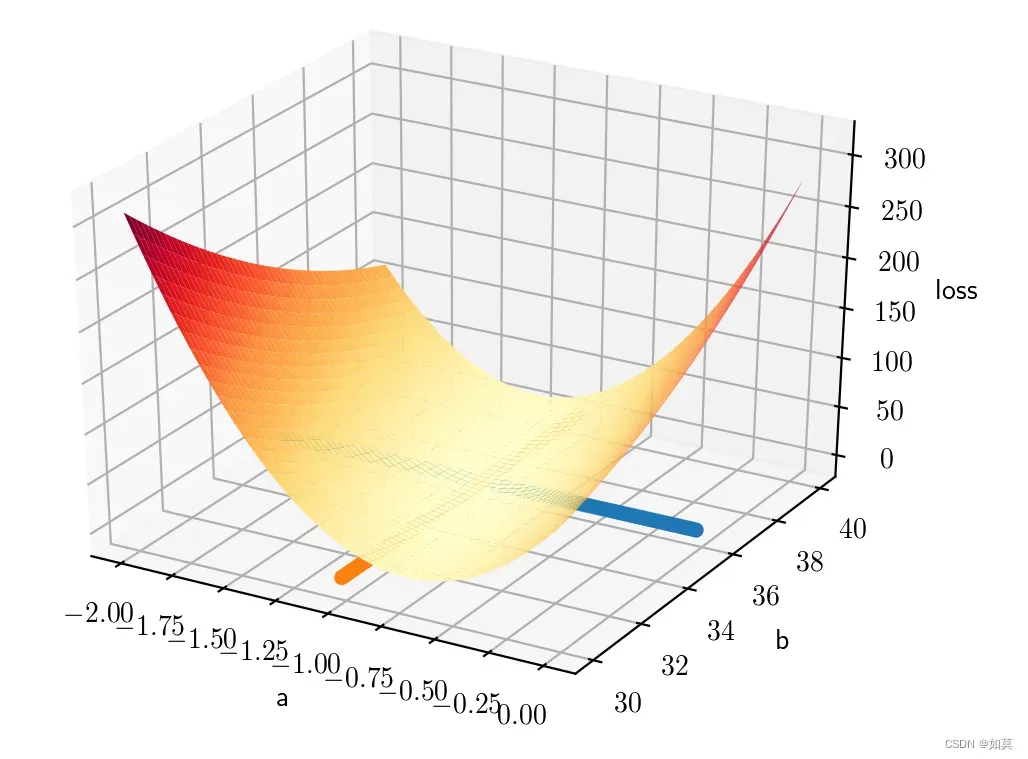
发现使得损失函数最小的参数为:。这和实际的参数已经非常接近了。
2 梯度优化
2.1 损失函数的梯度计算
损失函数
如果我们每次只用一个样本则
分别对两个参数求偏导:
令表示损失函数的参数,则损失函数对参数的梯度为
2.2 利用梯度寻找函数的极值
怎么调整和
才能让
变小呢?
那自然是 朝梯度的反方向! 只有朝梯度的反方向才能找到最低点,参考下面这个图。用公式表示就是其中
为更新步长。这就是 梯度下降(Gradient descent) 的核心公式了。
3 实验验证
梯度下降能不能找到极值点?按道理来说是可以的,只要损失函数的曲面是光滑的,而且步长合适。但是极值点可能不是最值点,因为对于多峰函数,用梯度下降找最值的时候,初始参数的选取也很关键。
用Python写几段代码来验证一下前面说的梯度下降吧。
- 导入几个计算和画图用的包
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
- 数据服从的原始函数
def g(x):
y = 16*np.sin(x) - x**2 + 35
return y
- 定义梯度下降函数
def GD(X, Y, a, b, alpha):
n_samples = len(X) # 样点数量
grad_a, grad_b = 0, 0
for i in range(n_samples):
# 计算样本梯度
grad_a += X[i] ** 2 * 2 * (16 * np.sin(X[i]) + a * X[i] ** 2 + b - Y[i]) / n_samples # 累积梯度
grad_b += 2 * (16 * np.sin(X[i]) + a * X[i] ** 2 + b - Y[i]) / n_samples
a = a - alpha * grad_a # 更新参数
b = b - alpha * grad_b
return a, b
- 现在可以使用梯度下降法寻找最优参数来最小化损失函数了:
#设定随机数种子,以便复现
np.random.seed(10)
#准备数据
X = np.linspace(-6,4,100)
Y = g(X) + 20*(np.random.rand(len(X))-0.5)
plt.scatter(X,Y)
plt.show()
#初始化参数
a, b = 0, 0
alpha = 1e-4
n_epoch = 60000 # 训练轮次
loss_list = [] # 用来记录loss下降的过程
for i in range(n_epoch):
a, b = GD(X, Y, a, b, alpha) # 使用梯度下降更新损失函数的参数
loss = np.mean((16*np.sin(X) + a*X**2 + b - Y-Y)**2) # 计算新参数下的损失函数值
if (i+1)%3000 == 0:
loss_list.append(loss)
print('第',i,'次迭代:a=%.5f,b=%.5f,loss=%.2f'%(a,b,loss))

第 2999 次迭代:a=0.34909,b=9.04097,loss=2196.10
第 5999 次迭代:a=0.00090,b=15.69549,loss=1824.62
第 8999 次迭代:a=-0.25661,b=20.61685,loss=1578.61
第 11999 次迭代:a=-0.44705,b=24.25645,loss=1412.39
第 14999 次迭代:a=-0.58789,b=26.94811,loss=1298.05
第 17999 次迭代:a=-0.69205,b=28.93873,loss=1218.19
第 20999 次迭代:a=-0.76908,b=30.41090,loss=1161.70
第 23999 次迭代:a=-0.82605,b=31.49964,loss=1121.33
第 26999 次迭代:a=-0.86818,b=32.30481,loss=1092.25
第 29999 次迭代:a=-0.89934,b=32.90029,loss=1071.15
第 32999 次迭代:a=-0.92238,b=33.34067,loss=1055.79
第 35999 次迭代:a=-0.93942,b=33.66635,loss=1044.55
第 38999 次迭代:a=-0.95202,b=33.90721,loss=1036.30
第 41999 次迭代:a=-0.96134,b=34.08534,loss=1030.24
第 44999 次迭代:a=-0.96824,b=34.21707,loss=1025.78
第 47999 次迭代:a=-0.97333,b=34.31450,loss=1022.50
第 50999 次迭代:a=-0.97710,b=34.38655,loss=1020.07
第 53999 次迭代:a=-0.97989,b=34.43983,loss=1018.28
第 56999 次迭代:a=-0.98195,b=34.47924,loss=1016.96
第 59999 次迭代:a=-0.98348,b=34.50838,loss=1015.98
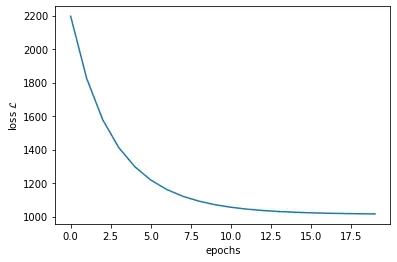
- 再来看看损失函数是如何变化的:
plt.plot(loss_list)
plt.xlabel('epochs')
plt.ylabel('loss $\mathcal{L}$')
plt.show()
文章出处登录后可见!