文章目录
- Stable Diffusion 推理优化
- 背景
- 技术讲解:
- 异步优化方案思路:
- 异步推理优化原理
- OpenVINO异步推理Python API
- 同步和异步实现方式对比
- oneflow分布式调度优化
- 优势:
- 实现思路
- 总结:
Stable Diffusion 推理优化

背景
2022年,Stable Diffusion模型横空出世,其成为AI行业从传统深度学习时代走向AIGC时代的标志性模型之一,并为工业界,投资界,学术界以及竞赛界都注入了新的AI想象空间,让AI再次性感。
Stable Diffusion是计算机视觉领域的一个生成式大模型,能够进行文生图(txt2img)和图生图(img2img)等图像生成任务。与Midjourney不同的是,Stable Diffusion是一个完全开源的项目(模型,代码,训练数据,论文等),这使得其快速构建了强大繁荣的上下游生态(AI绘画社区,基于SD的自训练模型,丰富的辅助AI绘画工具与插件等),并且吸引了越来越多的AI绘画爱好者也加入其中,与AI行业从业者一起不断推动AIGC行业的发展与普惠。
也正是Stable Diffusion的开源属性,繁荣的上下游生态以及各行各业AI绘画爱好者的参与,使得AI绘画火爆出圈,让大部分人都能非常容易地进行AI绘画。可以说,本次AI科技浪潮的ToC普惠在AIGC时代的早期就已经显现,这是之前的传统深度学习时代从未有过的。而这也是最让Rocky振奋的AIGC属性,让Rocky相信未来的十年会是像移动互联网时代那样,充满科技变革与机会的时代。
Stable Diffusion 本质是基于扩散模型的高质量图像生成技术,可根据文本输入生成图像,广泛应用于CG、插画和高分辨率壁纸等领域。然而,由于其计算过程较为复杂,Stable Diffusion 的图像生成速度常常成为遏制其发展的限制因素。
优化AI生图模型在端侧设备上的 Pipeline性能,在保证生图效果的情况下,降低pipeline端到端延迟,降低pipeline峰值内存占用,也成了当下迫在眉前的大难题。契合本次大赛要求,我们团队计划在目标英特尔硬件上完成部署优化及指定的图片生成工作,利用 OpenVINO 的异步推理功能,实现了预处理、推理和后处理阶段的并行执行,从而提高了整体图像生成 Pipeline 的并行性。
技术讲解:
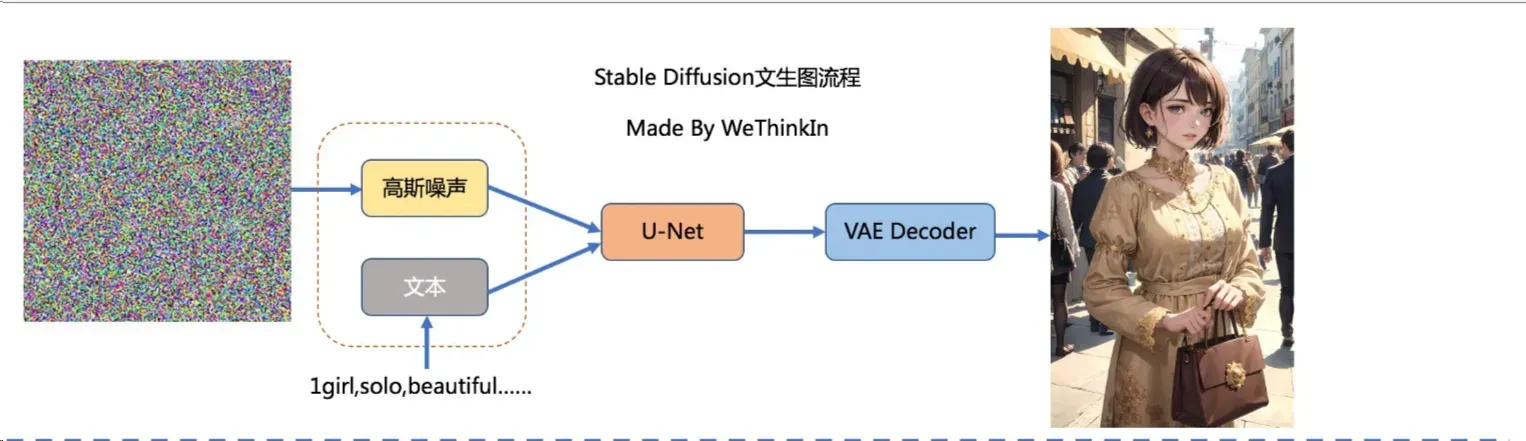
Stable Diffusion(SD)模型是由Stability AI和LAION等公司共同开发的生成式模型,总共有1B左右的参数量,可以用于文生图,图生图,图像inpainting,ControlNet控制生成,图像超分等丰富的任务,本节中我们以**文生图(txt2img)和图生图(img2img)**任务展开对Stable Diffusion模型的工作流程进行通俗的讲解。

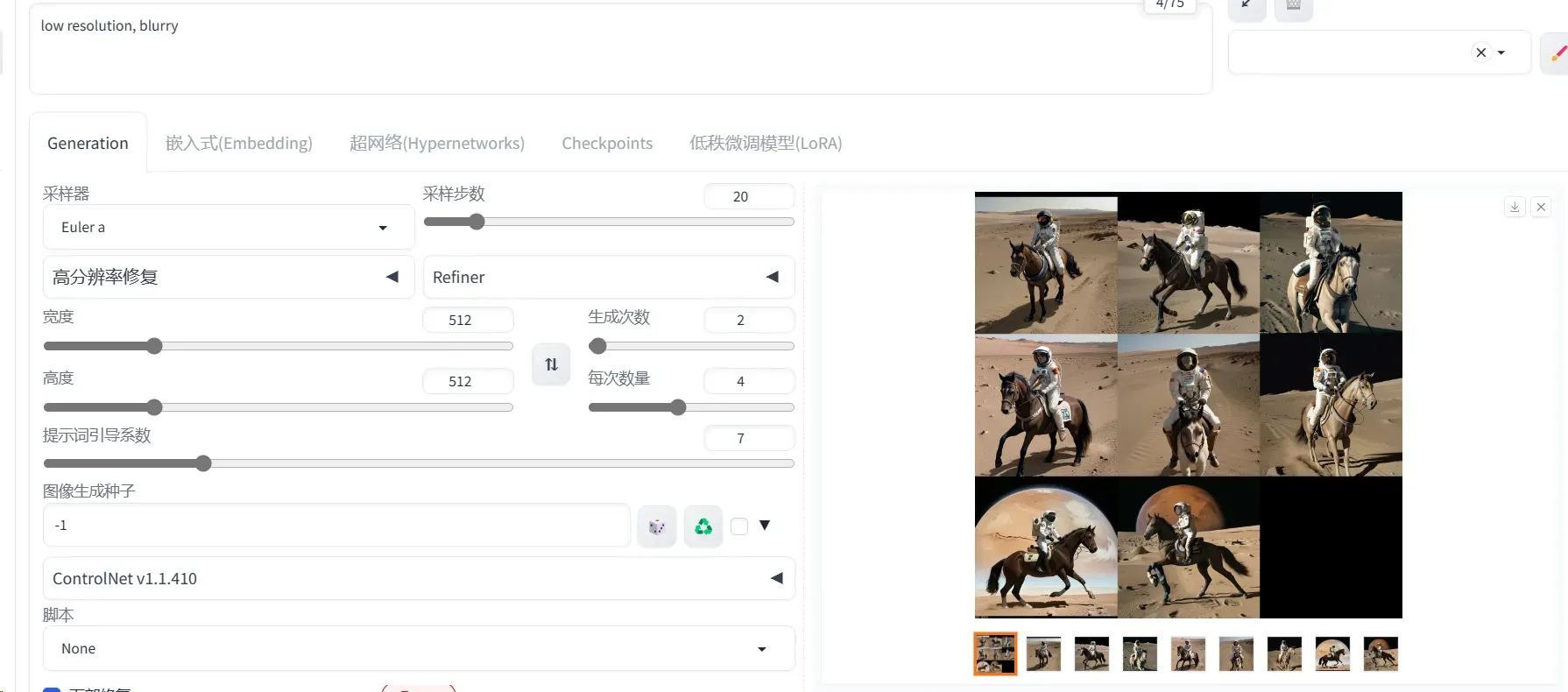
文生图任务是指将一段文本输入到SD模型中,经过一定的迭代次数,SD模型输出一张符合输入文本描述的图片。比如按照赛题要求输入关键字:
- Prompt输入:“a photo of an astronaut riding a horse on mars”
- Negative Prompt输入:“low resolution, blurry”
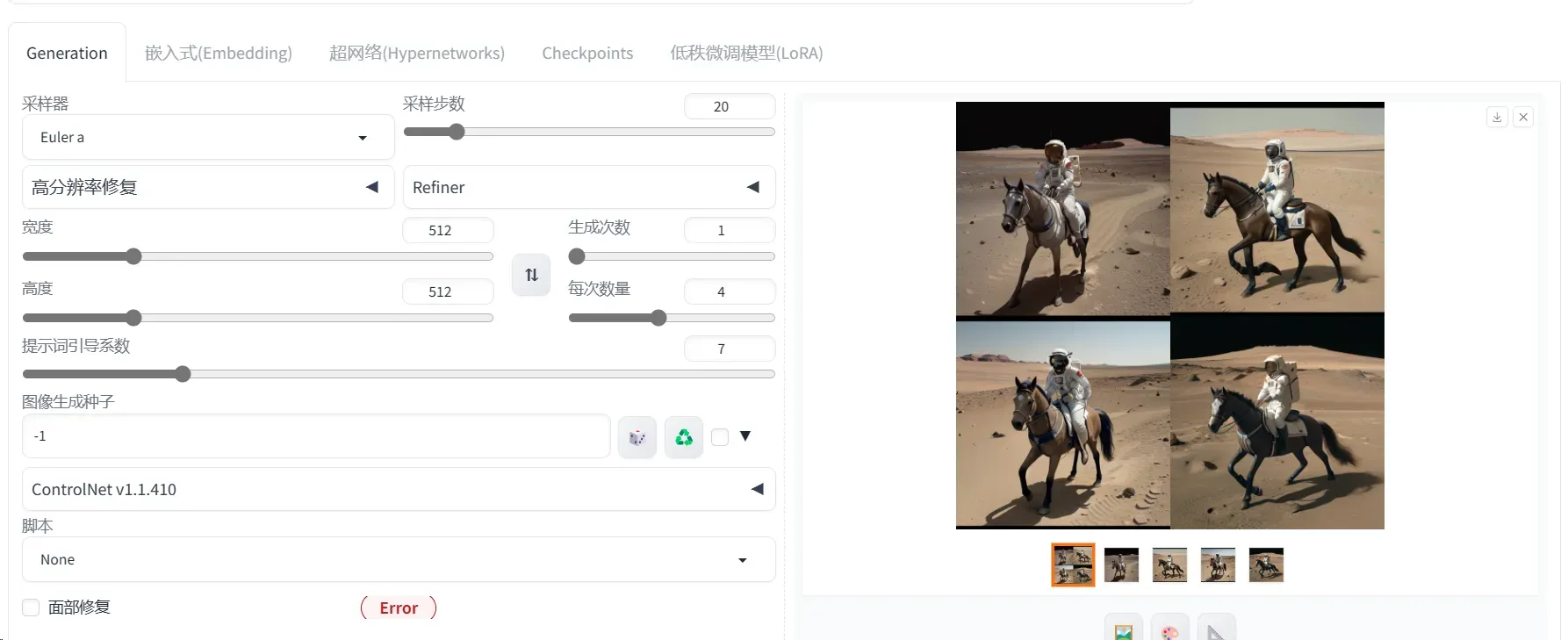
其本质就是给SD模型一个文本信息与机器数据信息之间互相转换的“桥梁”——CLIP Text Encoder模型。如下图所示,我们使用CLIP Text Encoder模型作为SD模型的前置模块,将输入的人类文本信息进行编码,输出特征矩阵,这个特征矩阵与文本信息相匹配,并且能够使得SD模型理解:

完成对文本信息的编码后,就会输入到SD模型的“图像优化模块”中对图像的优化进行“控制”。
“图像优化模块”作为SD模型中最为重要的模块,其工作流程是什么样的呢?
首先,“图像优化模块”是由一个U-Net网络和一个Schedule算法共同组成,U-Net网络负责预测噪声,不断优化生成过程,在预测噪声的同时不断注入文本语义信息。而schedule算法对每次U-Net预测的噪声进行优化处理(动态调整预测的噪声,控制U-Net预测噪声的强度),从而统筹生成过程的进度。在SD中,U-Net的迭代优化步数大概是50或者100次,在这个过程中Latent Feature的质量不断的变好(纯噪声减少,图像语义信息增加,文本语义信息增加)。整个过程如下图所示:
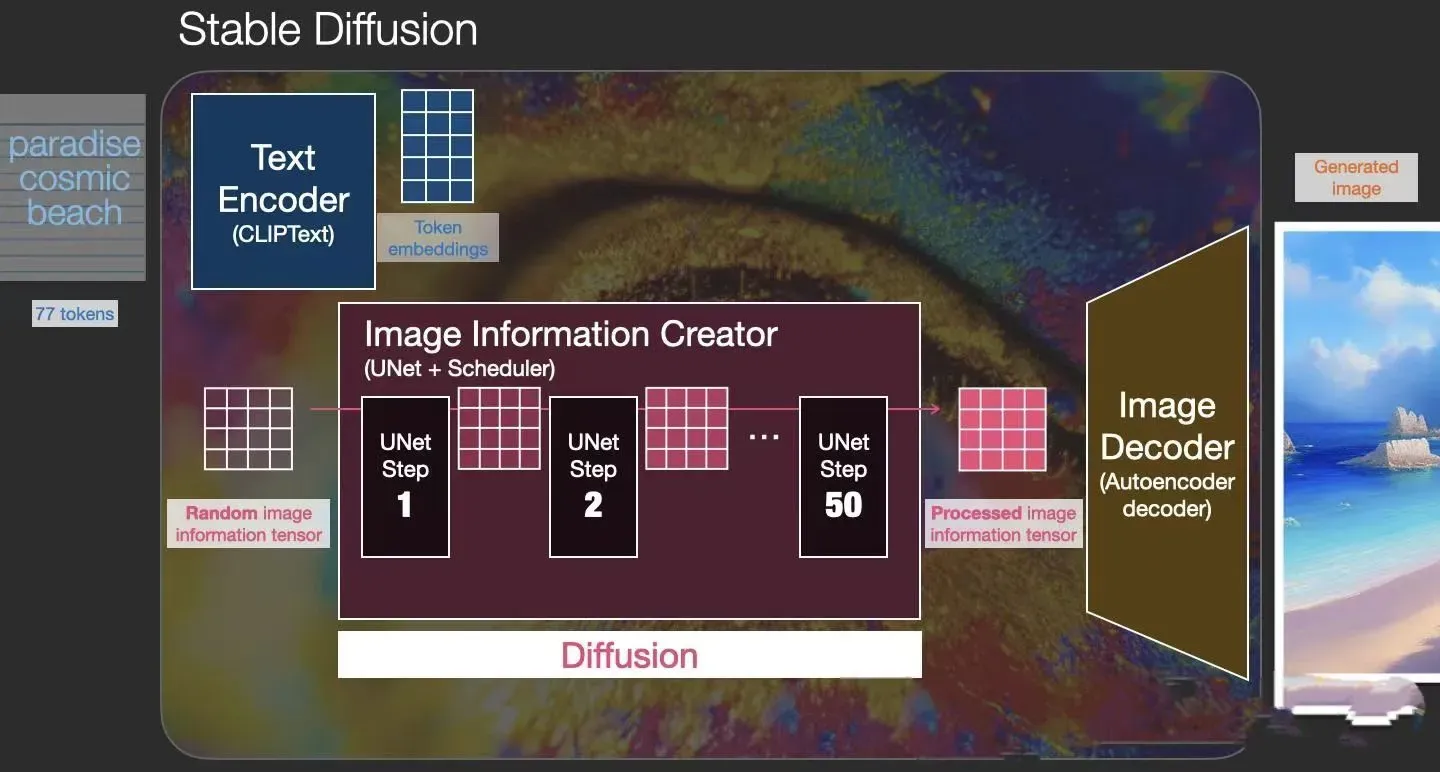
U-Net网络和Schedule算法的工作完成以后,SD模型会将优化迭代后的Latent Feature输入到图像解码器(VAE Decoder)中,将Latent Feature重建成像素级图像、迭代去噪。
异步优化方案思路:
我们是通过利用 OpenVINO 的异步推理功能,实现了预处理、推理和后处理阶段的并行执行,从而提高了整体图像生成 Pipeline 的并行性。具体使用 OpenVINO 异步推理功能创建独立的推理请求,将每个图像处理阶段异步化,使其在硬件上并行执行,最大程度发挥多核心处理器的优势,显著提升了整体性能。
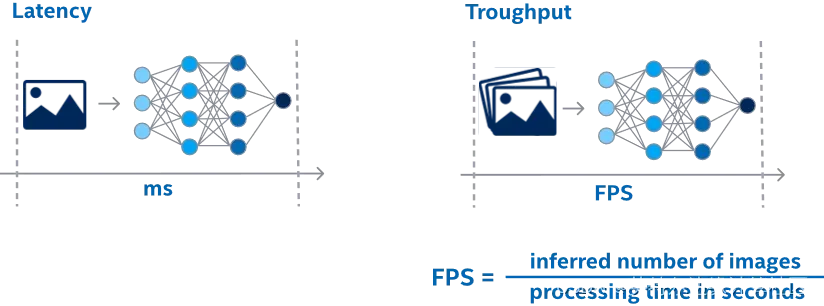
在提升SD文生图推理程序的性能前,先要理解评估AI推理程序性能的指标是什么。我们常用时延(Latency)和吞吐量(Throughput)来衡量AI推理程序的性能。
- 时延具体指讲数据输入AI模型后,多长时间可以从AI模型拿到输出结果
- 吞吐量具体指在单位时间能完成多少数据的AI推理计算
对于图像处理,吞吐量可以用单位时间内能完成多少张图片的AI推理计算来衡量,即FPS(Frame Per Second),如下图所示。
OpenVINO自带的性能评测工具的benchmark_app,主要用于单纯评价AI模型推理性能的场景。
这种优化方式主要有这几种优点,在保证生图效果的情况下,降低pipeline端到端延迟,降低pipeline峰值内存占用:
-
使得预处理、推理和后处理能够在硬件上并行执行,最大化利用多核心处理器的优势,提高整体 Pipeline 的效率。
-
减少等待时间: 异步化图像输入和输出处理,减少了数据传输的等待时间,降低了整体端到端的延迟,尤其在大规模推理任务中具有显著优势。
-
资源充分利用: 通过异步推理和异步化处理,确保硬件资源充分利用,提高了整个图像生成任务的吞吐量。
-
保持图像生成效果: 该优化方案在提高性能的同时,确保了生成图像的质量和一致性
异步推理优化原理
OpenVINO异步推理Python API
在对SD模型优化中,异步运行多个推理请求对于提高常规应用的效率而言很重要。每个设备都会在内部实施一个队列,充当缓冲区,存储推理请求,等待设备以固有速度检索。 设备实际上可能会并行处理多个推理请求,以提高设备利用率和总吞吐量。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
OpenVINOTM Runtime提供了推理请求(Infer Request)机制,来实现在指定的推理设备上以同步或异步方式运行AI模型。
在openvino.runtime.CompiledModel类里面,定义了create_infer_request()方法,用于创建openvino.runtime.InferRequest对象。
infer_request = compiled_model.create_infer_request()
当infer_request对象创建好后,可以用:
- set_tensor(input_node, input_tensor):将数据传入模型的指定输入节点
- start_async():通过**非阻塞(non-blocking)**的方式启动推理计算。
- wait():等待推理计算结束
- get_tensor(output_node):从模型的指定输出节点获取推理结果
同步和异步实现方式对比
| 同步实现方式伪代码 | 异步实现方式伪代码 |
|---|---|
| 创建一个负责处理当前文生图的推理请求即可… …While True:文生图预处理调用infer(),以阻塞方式启动推理计算对推理结果做后处理显示推理结果,生成图片结果 | 创建一个推理请求负责处理当前文生图请求创建一个推理请求负责处理下一请求模块… …采集当前图像关键字对当前图像做预处理调用start_async(),以非阻塞方式启动当前模型推理计算While True:采集下一次对下一步模型推算做预处理调用start_async(),以非阻塞方式启动下一帧推理计算调用wait()****,等待当前请求推理计算结束对当前推理结果做后处理交换当前推理请求和下一帧推理请求 |
# 创建一个负责处理当前文生图的推理请求
def process_inference_request(image):
# 文生图预处理
processed_image = preprocess_image(image)
# 调用infer(),以阻塞方式启动推理计算
inference_result = infer(processed_image)
# 对推理结果做后处理
postprocessed_result = postprocess_result(inference_result)
# 显示推理结果,生成图片结果
show_result(postprocessed_result)
# 创建一个推理请求类,负责处理当前文生图请求
class InferenceRequest:
def __init__(self, image):
self.image = image
self.result = None
def process(self):
# 对当前文生图做预处理,调用start_async(),以非阻塞方式启动当前模型推理计算
processed_image = preprocess_image(self.image)
start_async_inference(processed_image, self)
# 创建一个推理请求队列
inference_queue = []
# 创建一个推理请求负责处理下一请求模块
class NextInferenceRequest:
def __init__(self):
self.next_image = None
def process(self):
# 采集下一次文生图
self.next_image = capture_image()
# 创建一个推理请求,并加入推理请求队列
inference_request = InferenceRequest(self.next_image)
inference_queue.append(inference_request)
# 对下一次模型推算做预处理,调用start_async(),以非阻塞方式启动下一帧推理计算
processed_image = preprocess_image(self.next_image)
start_async_inference(processed_image, inference_request)
# 创建一个下一请求模块
next_request = NextInferenceRequest()
oneflow分布式调度优化
| oneflow | 一种基于异步并行计算的深度学习框架,可以实现分布式训练和推理 | 使用类似 PyTorch 的 API对模型进行编程;使用全局张量将模型扩展到 n 维并行执行 |
|---|
优势:
- 采用去中心化的流水架构,而非 master 与 worker 架构,最大程度优化节点网络通信效率
- 提供 consistent view ,整个节点网络中只需要逻辑上唯一的输入与输出
- 提供兼容其它框架的mirrored view,熟悉其它框架分布式训练的用户可直接上手
- 极简配置,由单一节点的训练程序转变为分布式训练程序,只需要几行配置代码
实现思路
首先需要准备训练和测试数据集,并定义一个适合该任务的神经网络结构,可以采用卷积神经网络(CNN)和循环神经网络(RNN)等结构。在OneFlow中,使用Parallelizer API配置分布式训练,自动处理任务调度、资源并行等问题。同时,为了进一步优化训练过程,在OneFlow中可以使用AutoMixedPrecision API自动进行混合精度训练,减少显存的使用量,提高训练速度。最后,使用Accuracy API计算模型在测试集上的准确率和Top-K准确率等指标。使用OneFlow框架可以简单、高效地实现Stable Diffusion模型文生图推理效率优化,提高训练速度和效果,加快模型迭代速度,从而更好地服务于实际业务需求。
通过 OneFlow 提供的分布式配置的接口,只需要简单的几行配置(指定分布式计算的节点 ip 以及每个节点使用 gpu 的数量)即可实现分布式的训练网络。例如下面这个例子,直接改写为分布式作业调度,来并行处理,针对于SD模型优化代码展示,请看模型压缩包:
import numpy as np
import oneflow as flow
import oneflow.typing as tp
BATCH_SIZE = 100
def mlp(data):
#构建网络...
@flow.global_function(type="train")
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
#作业函数实现...
#配置训练优化方法和参数
if __name__ == '__main__':
#调用作业函数,开始训练...
loss = train_job(images, labels)
#...
总结:
预测推理性能很困难,需要进行直接测量实验,才能找到最佳执行参数。 我们在此次大赛的硬件支持下和开发范围内进行了多次的性能测试,来确保验证应用的整体(端到端)性能。
针对于不同的参数和优化逻辑,设备的表现根据批次大小而异。总结任务最佳批次大小取决于模型、推理精度等因素。 同样 在某些情况下,可能需要将流和批处理结合起来才能尽力提高吞吐量。
还有一种可能的吞吐量优化策略是设置延迟上限,然后增加批次大小和/或流数,直到出现长尾延迟问题(即吞吐量不再增加)为止。这个我们会在之后对模型的推理优化继续深究。
总之,使用OpenVINO Runtime的异步推理API,将SD推理程序改造为异步推理的实现方式,可以看到明显的提升SD推理程序的吞吐量。由于本次的时间有限,优化效果并不大,我们之后时间充裕的情况下,还有下面几种优化方向,会一一尝试达到最大效率,
-
使用 NNCF 应用对训练时间压缩
-
模型压缩,通过过滤器剪枝:,逐步减小模型参数,并使用混合精度量化技术,减小模型存储需求。
这次大赛给我带来了许多的收获,包括技术学习和实践机会,英特尔技术和AI组件的深入学习了解,更多的是对自己能力的查漏补缺,认知到自己还有许多的不足,会加倍努力,自我锻炼,期待与大赛的下一次交手,我也会”王者归来“!
的吞吐量。由于本次的时间有限,优化效果并不大,我们之后时间充裕的情况下,还有下面几种优化方向,会一一尝试达到最大效率,
-
使用 NNCF 应用对训练时间压缩
-
模型压缩,通过过滤器剪枝:,逐步减小模型参数,并使用混合精度量化技术,减小模型存储需求。
这次大赛给我带来了许多的收获,包括技术学习和实践机会,英特尔技术和AI组件的深入学习了解,更多的是对自己能力的查漏补缺,认知到自己还有许多的不足,会加倍努力,自我锻炼,期待与大赛的下一次交手,我也会”王者归来“!
文章出处登录后可见!