当前主流的实现小样本音色克隆的可靠方式是说话人自适应(speaker adaption)技术,该技术通常通过在预训练的多说话人文语转换 (TTS) 模型上使用少量的目标说话人数据进行微调而获得目标说话人的TTS模型。在这一任务上已经有很多相关工作,然而很多时候说话人自适应模型需要运行在手机等资源有限的设备上,需要轻量化的方案。
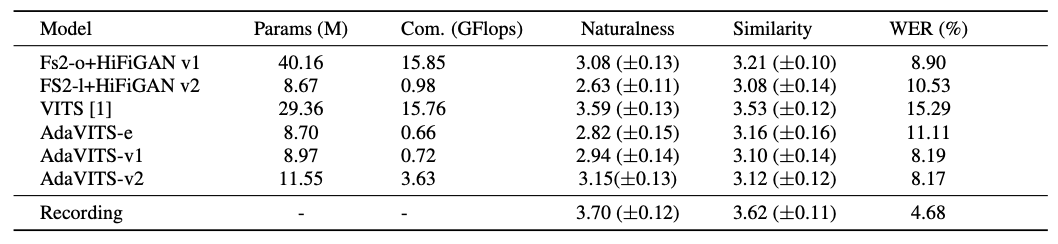
近期,由西工大音频语音与语言处理研究组 (ASLP@NPU) 和腾讯 CSIG 合作的论文“AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation”被语音旗舰会议 ISCSLP 2022 接收。该论文提出一种基于VITS模型的轻量化说话人自适应模型AdaVITS。在说话人自适应任务上,AdaVITS可以基于少量目标说话人录音样本构建TTS系统,合成稳定自然的目标说话人语音,并且模型参数量仅有8.97M ,计算量为 0.72 GFlops。

论文题目: AdaVITS: Tiny VITS for Low Computing Resource Speaker Adaptation
作者列表: 宋堃,薛鹤洋,王新升,从坚,张雍茂,谢磊,杨兵,张雄,苏丹
论文原文: https://arxiv.org/abs/2206.00208

论文截图
1. 背景动机
说话人自适应(speaker adapation)技术重要的应用场景是针对普通说话人的小样本音色克隆任务。由于针对大量目标说话人,因此需要考虑自适应模型的计算、存储和训练时间成本。当前有很多工作集中在优化模型的说话人存储成本 [1]和训练时间成本 [2]上,而对于模型的计算成本没有重点关注。可行的方法有量化蒸馏和神经架构搜索,但前者有明显的效果损失,而后者的搜索过程本身需要消耗更多的计算和时间成本。因此,我们从对模型的先验知识角度出发,减少其中不必要的计算和参数量,实现减少计算成本的同时尽可能保证合成效果。但减少计算和参数量本身是一个挑战性任务,这是因为:(1)当前主流的说话人自适应框架包括声学模型与声码器两部分,两部分在推理时可能存在误差,而这种误差在小型化结构的普通说话人自适应场景会更明显,导致瑕疵明显增多。(2)声学模型中语言学特征与声学特征存在耦合,模型小型化导致的建模能力下降会加重这一现象,不利于说话人自适应任务。
针对以上问题,我们引入基于VITS [3]的说话人自适应框架以解决声学模型和声码器的误差问题,并使用音素后验图特征 (PPG) 作为中间语言学表征约束文本到隐变量z的建模过程。因为PPG由大量说话人数据训练的语音识别声学模型提取,与说话人无关,因此可以实现语言学特征与声学特征的解耦。在此框架基础上,我们针对其中部分结构进行了优化,其中包括在解码器中结合逆傅立叶变换 (iSTFT)、正则化流层 (flow) 中引入共享层嵌入 (embedding)、线性注意力机制等方面。
2. AdaVITS方案
为了实现轻量化说话人自适应任务,我们使用基于VITS的端到端架构,引入PPG作为语言学表征。其优势如下:
-
使用PPG:没有语言学特征和声学特征的耦合,可以更直接的将内容和语言信息分别建模,更有利于小型化。同时可以实现克隆结果的风格可控,不会受到普通说话人录音语速和错读的影响。另外,PPG作为帧级语言学表征,可以显著解决VITS模型在多说话人上的发音不稳定问题。
-
使用VITS:VITS作为当前主流的端到端TTS框架,实现声学模型和解码器部分统一建模,避免两段式框架中声学模型与声码器共用基于梅尔谱中间表征引入的误差问题。
本文AdaVITS系统的整体模型架构如图1所示,由prior encoder、posterior encoder和decoder组成。posterior encoder用于从线性谱生成后验分布z,通过PPG约束音素到先验分布的生成过程,并通过flow使先验分布拟合z;decoder通过z合成语音波形。在prior encoder中,音素到PPG的生成过程采用类似FastSpeech的模型结构,PPG encoder采用FFT Block结构,其他模块遵循VITS的设置。
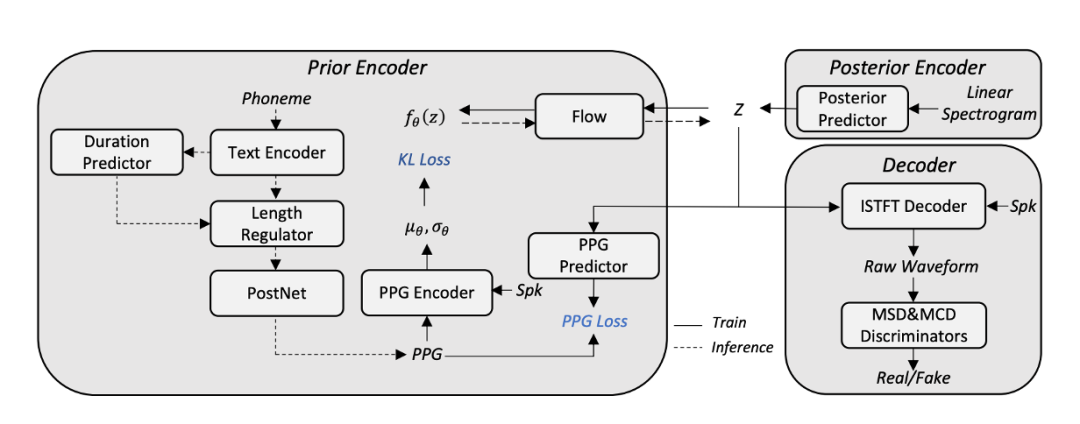
图1 AdaVITS模型架构
为了改善基于中间表征z的发音稳定性问题,在使用PPG作为中间表征外,还同时增加PPG预测的辅助任务,如图1所示,通过增加PPG predictor从z中预测PPG,保证z中包含完整的语言学信息,而PPG predictor不参与模型推理。
在此基础上,我们采用多种方法减少此框架的计算和参数量。首先,由于建模时域特征,解码器占据了整个框架中最多的的计算量。由于VITS框架不存在声学模型和声码器间的误差,对于解码器的建模压力相对较小;且z不像梅尔谱一样限制为幅度谱,因此建模相位的压力分散在整个模型中。因此我们引入iSTFT替代上采样结构,由于iSTFT在帧级别建模,可以极大减少解码器的计算量。如图2(a),我们提出了decoder-v1版本,直接通过一维卷积和残差模块建模实部和虚部并通过iSTFT生成语音波形。与此同时,为了实现语音质量和计算量的平衡,如图2(b),我们提出了decoder-v2版本。我们使用iSTFT替代上采样结构建模高频;而子带分解方法可以将语音划分为高低频,同时也是主流的降低解码器计算复杂度的方法。为此我们使用decoder-v1版本生成高频并使用上采样结构生成低频,通过子带合并最终生成语音信号。
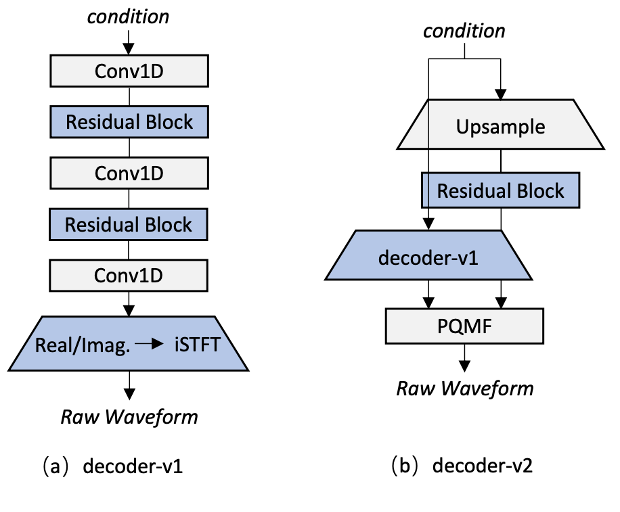
图2 两种Decoder架构
上述简化方案不可避免带来了解码器能力的下降,为了弥补这个问题,我们针对性的进一步修改了判别器。具体来说,我们采用多尺度梅尔谱 [4]和多尺度复数谱判别器。同时由于解码器建模能力的下降,时域判别器生成隐层特征的过程受到影响,而采用频谱替代时域判别器中的隐层特征有利于模型的收敛,与此同时由于直接建模实虚部,我们另外使用复数谱并利用复数卷积做判别。
我们同时在flow中引入flow indication embedding [5]共享flow参数。我们发现在VITS中,flow层数的大规模增加并不能显著提高分布变换的效果,但仍需要一定的层数以保证模型的收敛。因此如图3所示,我们为每一层flow增加id并通过embedding控制,实现每一层flow的参数共享,减少模型的参数量。
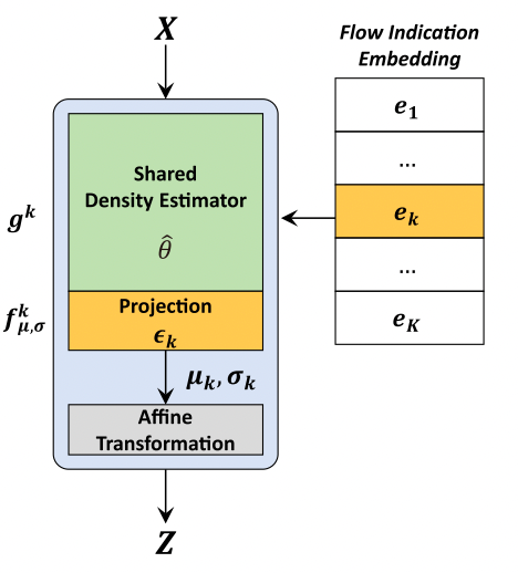
图3 flow indication embedding架构 [5]
另外由于原始FFT Block中,点积注意力机制的计算复杂度并不与输入文本长度线性相关,在长句上有非常明显的计算损耗增加,因此我们替换其为线性注意力机制 [6],使其计算复杂度与输入长度线性相关。
3. 实验验证
我们在英文开源数据集上进行实验验证。首先通过LibriTTS [7]进行多说话人模型训练,并通过VCTK [8]数据进行说话人自适应训练。前者包含来自1151个说话人的242小时数据,对于后者的每一个目标说话人,我们使用随机的20句话参与说话人自适应训练,并用10句进行测试。
我们在上述数据集上针对下列模型进行了对比验证。
-
VITS:原始论文版本的VITS
-
AdaVITSv1:使用decoder-v1的本文方案
-
AdaVITSv2:使用decoder-v2的本文方案
-
FS2-o+HiFiGAN v1:使用FastSpeech2和HiFi-GAN v1
-
FS2-l+HiFiGAN v2:使用小结构FastSpeech2和HiFi-GAN v2
-
AdaVITS-e:不使用PPG作为中间表征的AdaVITS版本
分别测试了各系统的自然度和音色相似度的MOS评分、WER,并计算了各系统的参数量和计算量。实验结果如表1所示。和具有与AdaVITSv1相似的模型大小的FS2-l+HiFiGAN v2相比,所提出的AdaVITS实现了更好的自然度和更少的计算复杂度。AdaVITS合成样本的WER比FS2-l+HiFiGAN v2更低,表明AdvaVITS具有良好的发音稳定性。与FS2-o+HiFiGAN v1相比,AdaVITS-v2具有相似的自然度,但模型尺寸小。我们也看到,与原始VITS相比,AdaVITS在自然度和说话人相似度方面仍有差距,但是计算复杂度方面有明显优势。与此同时,与其他方法相比,AdaVITS实现了更低的WER,这主要归功于基于PPG的语言特征的利用,这可以通过AdaVITS-e的性能来证明,其使用文本取代PPG作为输入的时候WER攀升。
表1 MOS和WER的实验结果及参数量/计算量
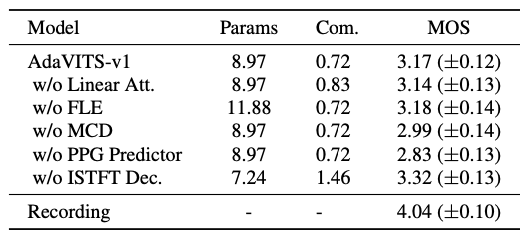
如表2的消融实验所示,复数谱判别器 (MCD) 和PPG预测器 (PPG Predictor) 在获得高质量语音中发挥了重要作用,而加入flow indication embedding (FLE)、线性注意力机制 (Linear Att.) 和iSTFT解码器 (iSTFT Dec.) 可以有效地减少参数数量和计算复杂度,而不会对MOS得分造成明显的影响。
表2 消融实验MOS分
4. 总结
本文提出了一种基于VITS的小型化说话人自适应TTS系统,简称AdaVITS,以满足基于说话人自适应方法进行轻量级目标说话人音色克隆的需求。与其他模型相比,AdaVITS在模型大小和计算复杂度方面具有明显的优势。与具有相似参数量的模型相比,AdaVITS具有较低的计算复杂度,可以获得更好的语音质量。进一步提升模型合成语音的韵律是下一步工作。
参考文献
[1] M. Chen, X. Tan, B. Li, Y. Liu, T. Qin, S. Zhao, and T. Liu, “Adaspeech: Adaptive text to speech for custom voice”, ICLR 2021.
[2] S. Liu, D. Su, and D. Yu, “Meta-voice: Fast few-shot style transfer for expressive voice cloning using meta learning”, CoRR, vol. abs/2111.07218, 2021.
[3] J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech”, ICML 2021.
[4] W. Jang, D. Lim, and J. Yoon, “Universal melgan: A robust neural vocoder for high-fidelity waveform generation in multiple domains”, CoRR, vol. abs/2011.09631, 2020.
[5] S. Lee, S. Kim, and S. Yoon, “Nanoflow: Scalable normalizing flows with sublinear parameter complexity”, NeurIPS 2020.
[6] A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention”, ICML 2020.
[7] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “Libritts: A corpus derived from librispeech for textto-speech”, Interspeech 2019.
[8] C. Veaux, J. Yamagishi, K. MacDonald et al., “Superseded-cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit”, 2017.
文章出处登录后可见!