
图像分类特征的适当重用改善了目标检测
摘要
迁移学习中的一个常见做法是通过对数据丰富的上游任务进行预训练来初始化下游模型权重。具体而言,在对象检测中,特征主干通常用ImageNet分类器权重来初始化,并在对象检测任务中进行微调。最近的研究表明,在长期的训练体制下,这并不是绝对必要的,并提供了从零开始训练骨干的方法。我们研究了这种端到端训练趋势的相反方向:我们表明,知识保留的一种极端形式——冻结分类器初始化的主干——持续改进许多不同的检测模型,并带来可观的资源节省。我们假设并通过实验证实,剩余的探测器组件容量和结构是影响冻结主干的关键因素。我们的发现的直接应用包括对长尾对象类的检测等困难情况的性能改进,以及计算和存储资源的节省,这有助于使该领域更容易被使用较少计算资源的研究人员访问。
1.介绍
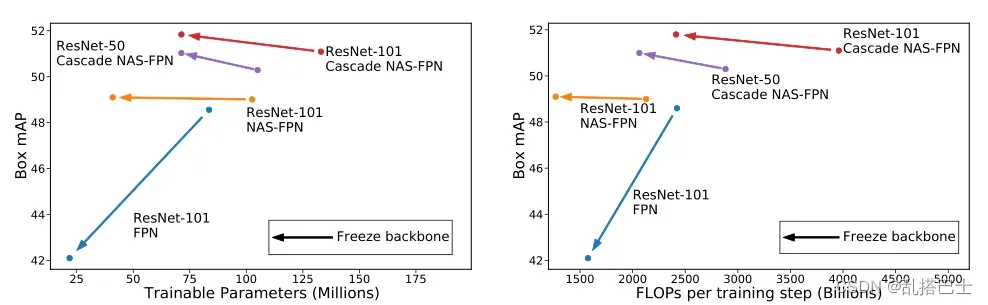
图1. 保留和不微调在ImageNet上学习的特征对物体检测性能的影响。箭头表示用冻结的骨干权重训练时对每个模型的影响。只要剩余的检测器组件有足够的容量(左),冻结就能提高性能,同时大大减少训练期间使用的资源(右)。
迁移学习[35]是深度学习中广泛采用的实践,尤其是当目标任务具有较小的数据集时;该模型首先针对上游任务进行预训练,上游任务中有大量数据可用,然后针对目标任务进行微调。从ImageNet甚至更大的[5,16,47]或弱标记的[33]数据集进行迁移学习被反复证明能够在各种视觉任务、架构和训练程序中产生性能改进[23,33,47]。
对于对象检测[20],通常的做法是使用通过图像分类任务(如ImageNet [44])的预训练获得的权重值来初始化模型的主干(模型图见图2)。传统上,在从头开始训练其他检测器组件的同时,对主干进行微调。最近有两种工作路线对物体检测的迁移学习进行了看似矛盾的观察。一方面,Sun等人[47]表明,目标检测器受益于预训练中使用的大量分类数据。另一方面,最近的论文报告称,从预先训练的主干初始化转移和使用较小的域内数据集从头开始训练主干之间的性能差距随着训练时间的延长而消失[8,14,26,45]。
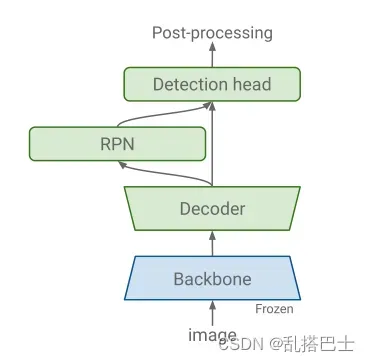
图2。作为示例的快速RCNN检测模型的草图。我们提出的训练过程在从分类任务初始化主干之后冻结主干,并从头开始训练其他组件。
我们以最简单的形式重新审视迁移学习,其中主干的分类器初始化在检测训练期间被冻结。这允许我们更好地理解预训练表示的有用性,而没有由微调导致的混淆因素。这种方法有很多优点:简单、节省资源、易于复制。
此外,使用这种方法,我们能够做出以下两个观察结果:
1 .在调查预训练表示的有用性时,较长的训练是一个混淆因素,因为微调主干的权重远离它们的预训练初始化.
2.这一点很重要,因为我们的消融研究表明,在上游分类任务中学习到的表示对于目标检测来说,比使用较小的域内数据集在目标检测任务本身上从零开始微调或训练获得的表示更好。
当我们通过冻结主干来保留预训练的表示时,我们观察到在较大数据集上的预训练的一致的性能改善。如果后续的检测器组件有足够的能力,用冻结的主干训练的模型甚至超过了它们的微调或“从零开始”的对应物的性能。
作为我们发现的直接贡献,我们表明,可以训练一个现成的对象检测模型,具有类似或更好的性能,同时显著降低对计算资源的需求,无论是在内存方面还是在计算方面(FLOPs)(图1)。当按类和可用注释的数量对结果进行分层时,所提出的上游任务知识保存的性能优势甚至更加明显。我们的结果表明,我们的模型重用的极端公式对具有少量注释的类有明显的积极影响,例如在长尾对象识别中发现的那些。
2.相关工作
目标探测器骨干预培训的好处。通过训练一个更好的基础模型来提高视觉任务的表现是可能的,这一假设已经得到了广泛的研究[23,29,42]。Huang等人[19]关注的是不同容量的架构之间的密切相关性、它们在ImageNet上的分类性能以及它们相应的对象检测性能。Sun等人[47]将讨论从模型比较转移到关注训练前数据的影响。他们将ImageNet上的主干预训练与JFT-300M分类任务进行对比,以证实大规模数据有助于表征学习,最终提高分类、检测、分割和姿态估计任务中的迁移学习性能的假设。对我们的讨论很重要的是,他们指出,从更大的数据集进行预训练的好处是有限的。
无监督、弱监督和自我监督预训练。减少对特定于任务的注释的需求尤其与需要细粒度注释的任务相关,例如检测和分段。这激发了无监督[1,6]、自监督[21,43,46,52]和弱监督对象检测(预)训练方法[24,27,34,39]的活跃研究领域。在自训练公式中,Barret等人[53]提出丢弃来自ImageNet的原始标签,并使用在MSCOCO上训练的检测器获得伪标签。然后将伪标记的ImageNet和标记的COCO数据组合起来以训练新的模型。与我们的工作更接近的是,Dhruv等人[34]使用社交媒体标签调查了数十亿弱标记图像的预训练。他们表明,当使用大量的预训练数据时,检测性能受到模型容量的限制。在较小的模型上的增益很小或者是负的,但是随着模型容量的增加,较大的预训练数据集产生一致的改进。关于使用有噪声标签的预训练的影响,他们推测,与监督预训练(ImageNet)相比,弱监督预训练的收益可能主要是由于提高了对象分类性能,而不是空间定位性能。AP与AP50的增益之间的对比被用作该分析的代理。
从零开始训练。He等人[14]表明,仅使用域内监督并使用更长的训练时间表以及适当的正则化和归一化,从随机初始化开始训练对象检测器是可能的。李等人[26]的目标是减少资源和增加稳定性,并提出将“从头训练”过程分为两个逐步增加输入分辨率的步骤,这两个步骤都在目标数据集上执行。[7,12]探讨了从零开始训练和数据扩充的结合。Ghiasi等人[12]表明,将对象随机粘贴到图像上的简单数据增强机制为MSCOCO和L VIS检测和分割提供了优于现有技术方法的可靠增益。在他们的消融研究中,较小的模型使用强大的数据增强进行训练,并从头开始训练,而较大的模型(表现出最佳性能)从ImageNet上预先训练的模型进行微调。Du等人[7]提出了一套训练策略,结合数据增强(大规模抖动[50])、平滑激活函数、正则化、主干架构变化和归一化技术来提高检测器的性能。
节约资源的重要性。深度学习领域正变得越来越资源敏感。从环境的角度来看,训练深度学习模型的碳足迹是不可忽略的[51],我们的研究结果有助于减少碳足迹。从社会的角度来看,奥班多-切隆和卡斯楚[4]注意到,大规模标准化深度强化学习基准,如街机学习环境[2],具有将领域划分为能够访问大规模计算资源的组和没有这种资源的组的不幸效果。他们认为,更小规模的环境仍然可以产生有价值的科学见解,同时可供更多的研究人员使用。最近的目标检测工作[8,12]中使用的大批量可以说具有类似的阻止效果。虽然我们不能声称完全解决了对象检测的问题,但我们的发现有助于减少实现强大的对象检测性能所需的计算资源,并朝着允许具有不同资源访问级别的研究人员为该领域做出贡献的方向迈出了一步。
3.方法
我们的主要假设是,通过对大规模图像分类任务进行训练而获得的特征比从相对较小的域内数据集获得的特征更适合于对象检测任务。我们考虑的分类数据集(ImageNet (1.2M)和JFT300M (300M))包含的图像比常见的检测数据集(如MSCOCO (118K)和LVIS (100 K))多几个数量级。我们提出的关键见解是冻结在分类任务中学习的权重,并选择剩余的组件,以便它们具有足够的能力来学习特定于检测的特征。
3.1.保留分类特征
为了保留在分类过程中学习到的知识,我们使用最自然和最明显的策略来冻结分类网络(也称为主干)的权重。文献[20,29,42]中的常见做法是在骨干网初始化后训练模型中的所有权重。相反,我们考虑冻结所有主干权重的替代策略。这不仅节省了计算并加快了训练,而且正如我们发现的那样,提高了许多现代检测架构的性能。
3.2.检测特定能力
使分类网络适应检测任务,通常需要添加检测特定组件(图2),如区域建议网络[42]、特征金字塔网络[28]和最近的检测级联[3]。我们观察到,检测组件的容量在网络的概括能力中起着很大的作用,特别是当我们从分类任务初始化时。我们表明,当特定于检测的组件具有足够的容量时,从分类任务初始化并冻结那些权重比微调或从头开始训练(如文献中常见的)执行得更好。此外,我们看到,当我们在更多样化的分类数据集上进行预训练时,性能增益会增加。
3.3.数据增强
我们使用大规模抖动(LSJ) [50]进行所有实验,并使用复制粘贴增强[12]以获得EfficientNet [49]的最佳结果。我们注意到我们提出的技术是对这两种数据扩充策略的补充。此外,对于具有冷冻主干的实验,数据增强技术仅能够通过帮助检测特定成分来改善结果。
4.实验
我们的实验连接了对象检测文献中两个明显矛盾的结论。Sun等人[47]主张对图像分类数据集进行预训练,并观察到随着预训练数据集的规模而增加的益处。反其道而行之,最近的论文趋势遵循He等人[14]的发现,支持在更长的训练体制下从头开始训练。
我们通过指出一个微调时间越长的主干会远离其预训练的初始化来解决这个矛盾。如果——正如我们的证据所表明的——微调在检测性能方面对习得的主干表示有害,那么这就可以解释为什么预训练的好处在更长的训练体系中似乎消失了。然而,如果预训练的主干在检测训练期间被冻结,这种退化是可以防止的。这让我们认识到预训练初始化的好处,即使在更长的训练时间表下这样做很简单,易于复制,在所有研究的架构上产生性能改进,加上足够表达的后续检测器组件(图1),并在训练期间节省大量计算资源。
4.1实验设置
…
5.结论
我们对从下游检测设置中的大规模分类任务中获得的预训练表示的再利用得到了新的进展。特别地,我们表明保留从大规模分类任务的训练中获得的主干表示有利于对象检测和实例分割。我们还展示了这是如何将[47]和[14]两个看似矛盾的观察联系在一起的,缺失的部分是较长的训练计划使骨干进一步远离良好的初始表现。
我们将主干冷冻作为一种简单的知识保存方法进行了研究,并通过主干、检测模型、数据集和训练计划的多种组合的广泛实验,证明了其在与足够的检测特异性组件容量相结合时的优势。这种方法易于实现和再现,并且在训练期间需要明显更少的计算资源。
虽然需要控制以前工作中使用的资源意味着大多数人还无法访问SOTA,但我们证明了在所有设置中计算和内存的节省,这意味着在给定相同数量的资源的情况下,实践者能够以更大的批量训练更大的模型,并且可访问性可以通过减少所需训练时期的数量的未来工作来进一步改善。我们还认为,挖掘邻近领域丰富的模型重用文献是未来工作的一个有希望的方向。最后,我们的发现可以用于未来的神经架构搜索工作,以利用预先训练和冻结的基于分类的特征,最终比NAS-FPN做得更好。
文章出处登录后可见!