作者文章:地址
github代码:地址
一、作者的motivation
在自动驾驶中往往需要更大尺度的场景,面对大尺度场景需要克服两个限制:
(1)Non-representative数据集
当前存在的数据集在大尺度实际场景应用,无法表现的太好,主要原因:
- 覆盖的地理区域太小
- 场景图片地理分布太稀疏,如下图中MSLS
- 当前存在的数据集都是分割成地理位置不相交的集合,用于训练和推理
弊端:在这些数据集进行训练,没有找到真世界中场景的相关性
(2)Scalability of training
- 当前热门的方法大都使用对比学习(大多数依赖三元损失函数triplet loss),挖掘negative examples是一个很昂贵的操作
- 现有的挖掘方法,也存在收敛速度慢,数据使用有效性差的缺点
贡献:
- 稠密大尺度数据集SF-XL,大约是当前存在数据集规模的30倍,并且包括Crowd-sourced(i.e., multi-domain)
- 提出一个CosPlace方法,利用图像分类任务的方法训练模型,提取有区分性的描述子,该方法相当简单,不需要挖局负例,就可以从大量数据中完成有效的学习
- 与当前SOTA方法相比,GPU显存大约减少80%,embeddings也要小8倍,在其他数据集也有很好的泛化能力
二、相关工作
-
Visual geo-localization – 看成图像检索任务
缺点:由于挖掘负例代价昂贵,导致训练时间长;Netvlad,PCA减少描述子维度,会导致表现退化。
-
Visual geo-localization – 看成图像分类任务
缺点:精度太差
-
本文方法结合这两种方式:
利用不需要挖掘负例的分类任务训练模型,分类策略旨在利用稠密数据的可用性,并确保如果两个图像来自同一个类,它们将显示相同的场景。此外,与以前任务不同的是,经过训练后,本文方法可以通过对任何给定地理区域的图像检索来执行地理定位。
三、旧金山SF-XL数据集

-
数据库:Database
– 训练集:整座旧金山城市41.2M图片,包括6DOF的GPS信息和朝向方位角度,从2009年至2021年。
– 测试集:仅有2.8M图片,从2013年开始,仍然覆盖整个几何区域
– 验证集:8K数据库图片,8K查询图片
-
查询:Queries
思想:数据库和查询集合的拆分需要合适的分割方法,否则会影响结果。test queries不应该和Database来自相同的域,因为真实世界测试总是来自未见过的区域,本文的test queries包含两部分:
test set v1: 从Flicker收集1000张图片,给出不精确的GPS坐标,所有图片都是手工选择,定位已经被验证
test set v2: 从San Francisco Landmark Dataset选取598张图片,利用方法生成6DOF坐标。
四、方法
首先简单批评一下现有的比较好的方法的缺点:
(1)训练的时候需要定期计算所有数据库图片的特征,时间和空间复杂度,仅适用于小数据集。
(2)基于NetVLAD和其变体的方法,描述子向量维度过高,推理阶段需要大量的内存占用,PCA减少维度,会导致结果退化。
受到人脸识别的启发,cosFace和arcFace是其实现最佳结果的关键,需要把训练集分类。但是SX-XL数据集标签空间是连续的,分类并不直观,所以引入下面方法:
-
数据集分类:
利用UTM坐标
将数据库分成正方形地理单元格,然后根据每张图片的方位/朝向
,进一步把每个单元格分成一组类。定义类
内的图片集合为
其中和
分别表示确定类单元格范围位置和朝向的长度(米)和角度(度)。
虽然这种解决方案可以从数据集创建一组类,但它有一个很大的局限性:由于量化误差,几乎相同的图像(例如,以相同的方向拍摄,但相距几厘米)可能被分配到不同的类如下图,会妨碍分类方法的训练。
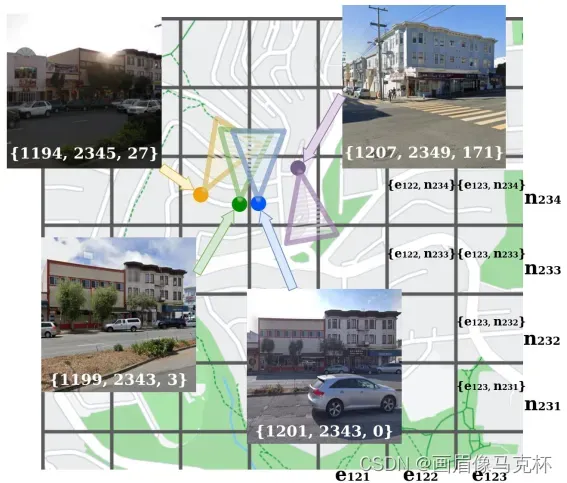
本文的方法是不一次性训练所有类,而是仅训练不相邻的类(如果位置或朝向上的微小差异,可以将图片从一个类带到另一个类,则两个类是相邻的),这些组称为CosPlace Groups,类似于单独的数据集,每一次训练一个group。
生成groups的原则是:一个group中的任意两个类,在平移和朝向上有一个最小的间隔数值。引入两个超参数,
控制同一group中的任意两个类之间最小单元格数量,
表示同一个单元格内相隔多少个
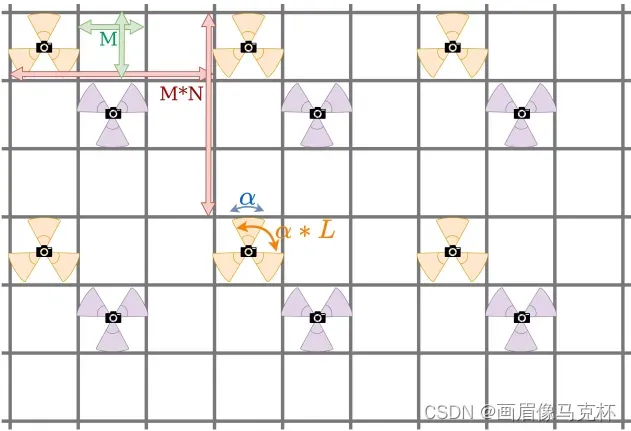
根据上述解释定义CosPlace Group
为:
每个CosPlace Group之间都是非连通集合。性质如下:(1) 每一个类别都明确一个群组(我认为应该是一个类别单元格会明确分给
(2) 同一个群组,如果两张图片属于不同的类,它们至少相隔
米,或者相隔
度
(3) CosPlace Groups总数目为
(4) 没有任何两个连通的类属于同一个群组(除非
或者
)
-
训练网络:
受到LCML也被称为cosFace的启发,但是原本的LCML不能直接应用到该数据集,因为图像数据没有被分成有限数量的类。然而通过上述的数据集分区方法,可以在每个CosPlace groups上顺序执行LCML(其中每个组可以被视为一个单独的数据集),并在许多组上进行迭代。由于LCML需要全连接层对应类别数,训练阶段每一个群组都需要一个全连接层,在验证和测试阶段不需要全连接层。注意并不是所有群组都是需要的,单一一个群组也可以训练,文章中图10消融实验证明,多于一个群组,效果会更好一点。按顺序训练每个群组:
是LCML loss,
就按照
的顺序依次迭代群组。
五、实验
-
实施细节:
架构:一个标准的CNN backbone(VGG16) + GeM pooling + fully connected layer(output 512)。在消融实验和预实验也使用了ResNet18,结果差不多,也在各个框架都试了一下,其中ResNet101+128-D描述子结果表现超过当前使用4096-D描述子的SOTA方法。
训练:超参数设置,
. 每个epoch执行一个群组迭代10k次,一个群组一个epoch,一共50个epochs(例如:batchsize = 32,500k次迭代)。在训练期间,为了每个群组可以多次看到,仅使用8个groups(50个群组中的8个,代码中是0~7)。每训练一次验证一次,训练结束,测试集在验证集表现最好的模型上测试。更多的细节看附录。
-
方法比较:
比较25米阈值的recall@N,结果更好。还比较了内存占用,描述子维度,都是最佳的,具体看文章。
-
计算效率:
内存占用;GPU需求,CosPlace只需要7.5GB、单GPU2080Ti训练;描述子维度和其他方法相比非常小;训练测试速度更快。
-
消融实验:
超参数
;backbone和描述子维度等等,具体结果看文章附录。
-
限制:
使用了Heading labels,Pitts30K和MSLS没有该数据,CosPlace无法在上面训练;研究了较小训练集的训练,但是并没有达到SOTA的结果,所以该方法并不适合在小训练集训练。
六、附录:B.2 进一步实施细节
- 为了更好的表示每个类,对于训练期间的数据,保证每个单元格内至少10张全景图,抛弃了大约15%的图片
- 超参数
得到50个群组,每个组大概35k个类,每个类平均包含19.8张图片
- 训练阶段仅训练50个群组中的8个,包含大约5.6M张图片,将来的工作也可以修改这个参数
- 优化器:Adam optimizer,lr = 0.00001,batchsize = 32,数据增强采用color jittering,random cropping
- cosFace loss 的 margin = 0.04
以上就差不多是这篇文章的全部内容,其实主要思想还是利用heading labels对稠密的图片进行数据划分,来更好的提取特征,但是文章中的数据集主要集中在旧金山城镇街道,一些户外数据集或者相似区域的图像检索,效果如何不能确定,但这种思想值得借鉴,为数据集进行非连通的分类分组。
最后欢迎大家留言讨论!
文章出处登录后可见!