RAT-GAN提出了一种用于生成对抗网络的递归仿射变换 (RAT),将所有融合块与递归神经网络连接起来,以模拟它们的长期依赖关系,跟DF-GAN很类似。文章发表于2022年4月。
论文地址:https://arxiv.org/pdf/2204.10482.pdf
代码地址:https://github.com/senmaoy/Recurrent-Affine-Transformation-for-Text-to-image-Synthesis
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、原文摘要
文本到图像合成旨在生成基于文本描述的自然图像。这项任务的主要困难在于将文本信息有效地融合到图像合成过程中。现有的方法通常通过多个独立的融合块(例如,条件批量归一化和实例归一化)自适应地将合适的文本信息融合到合成过程中。然而,孤立的融合块不仅相互冲突,而且增加了训练的难度。为了解决这些问题,我们提出了一种用于生成性对抗网络的递归仿射变换(RAT),它将所有融合块与一个递归神经网络连接起来,以模拟它们的长期依赖性。此外,为了提高文本和合成图像之间的语义一致性,我们在鉴别器中加入了空间注意模型。由于知道匹配的图像区域,文本描述监督生成器合成更多相关的图像内容。在CUB、Oxford-102和COCO数据集上进行的大量实验表明,与最先进的模型相比,该模型具有优越性。
二、为什么提出RAT-GAN
GANs通常通过多个独立的融合块(如条件批量归一化(CBN)和实例归一化(CIN))自适应地将合适的文本信息融合到合成过程中,DFGAN、DT-GAN、SSGAN都使用CIN和CBN将文本信息融合到合成图像中,但有一个严重的缺点,即它们被隔离在不同的层中,忽略了在不同层中融合的文本信息的全局分配。孤立的融合块很难优化,因为它们彼此不相互作用。
因此,作者提出了一种**递归仿射变换(RAT)**来一致地控制所有融合块。RAT使用相同形状的标准上下文向量表达不同层的输出,以实现对不同层的统一控制。然后使用递归神经网络(RNN)连接上下文向量,以检测长期相关性,通过RNN,融合块不仅在相邻块之间保持一致,而且降低了训练难度。
三、RAT-GAN
3.1、整体框架
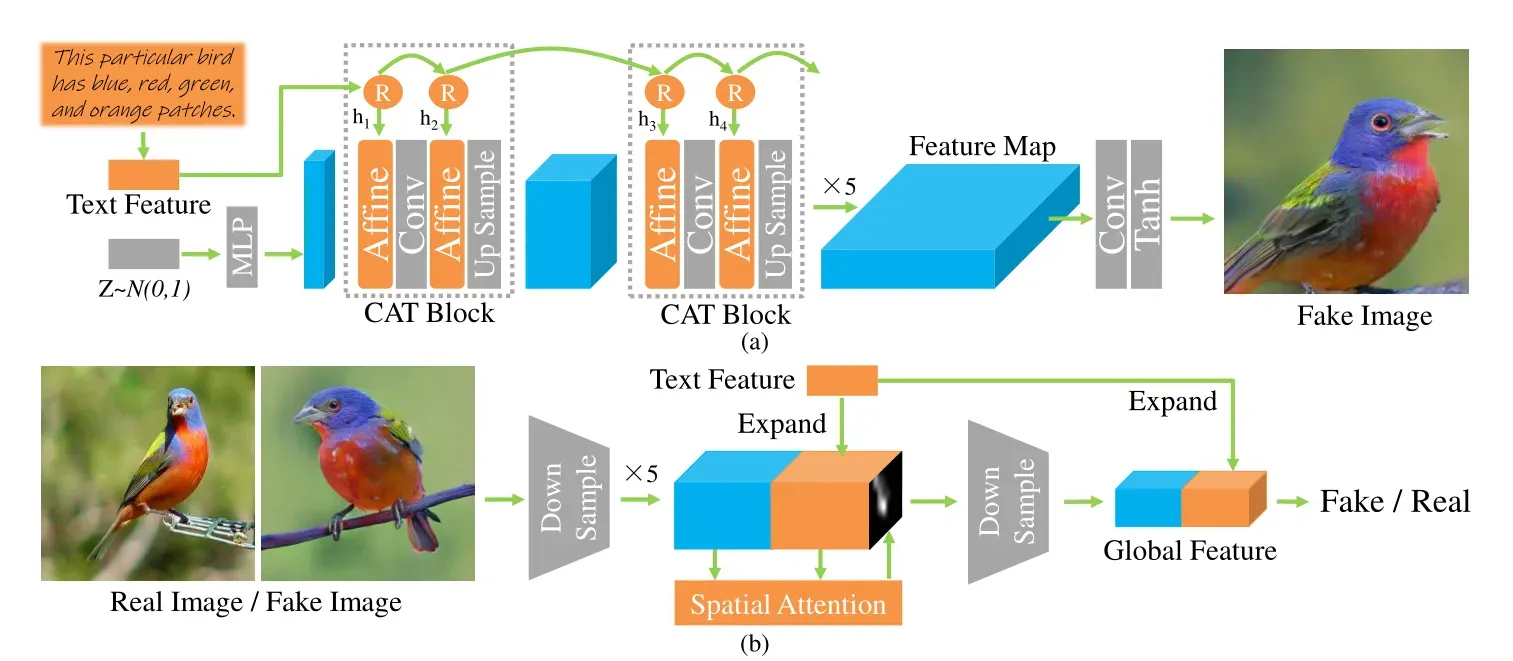
整体框架图如上图所示,与DF-GAN较为相似,同样随机噪声经过MLP重塑成指定尺寸的特征向量,然后使用5个RAT Blocks,经过一系列仿射变换的操作,最终生成特征图。
鉴别器与DF-GAN稍有不同,通过下采样后,将图像与文本特征expand然后做空间注意力后生成一个全局特征(与AttnGAN的方法类似),然后判断生成的图像是否为真。
3.2 、RAT仿射块(Recurrent Affine Transformation)
3.2.1、RAT仿射块的结构
单个RAT仿射块的结构如下:
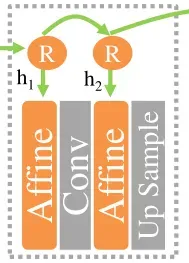
RAT仿射块主体与DF-GAN和SSAGAN中的差不多,也是两个MLP,一个带有缩放参数,对图像特征向量c进行通道缩放操作,另一个带有平移参数,对图像特征向量c进行通道平移操作:
3.2.2、LSTM循环控制器的引入
最主要的是其引入了循环控制器机制(Recurrent Controller),其使用LSTM连接上下文向量,以检测长期相关性,在相邻RAT块之间保持一致。
LSTM的初始状态是由噪声向量计算出的:,更新的规则如下:
其中,、
、
分别代表输入门、遗忘门和输出门,以上规则用的原理主要还是LSTM,第一步是遗忘门,就是决定细胞状态需要丢弃哪些信息,这部分操作是通过一个sigmoid单元来处理的,下一步是输入门决定给细胞状态添加哪些新的信息,最后是输出门,将输入经过一个igmoid层得到判断条件,然后将细胞状态经过tanh层得到一个-1~1之间值的向量,该向量与输出门得到的判断条件相乘就得到了最终该RNN单元的输出。看不懂可以学习一下LSTM再来进行理解(下附LSTM的结构图)。
3.2.3、RAT仿射块的创新点
RAT仿射块不再将仿射变换作为孤立的模块。相比之下,其使用RNN来建模融合块之间的长期依赖关系,这不仅迫使融合块彼此一致,而且还降低了跳跃连接训练的难度。
3.3、具有空间注意的匹配感知鉴别器
为了提高合成图像和文本描述之间的语义一致性,作者在鉴别器中加入了空间注意力机制,如下图所示:
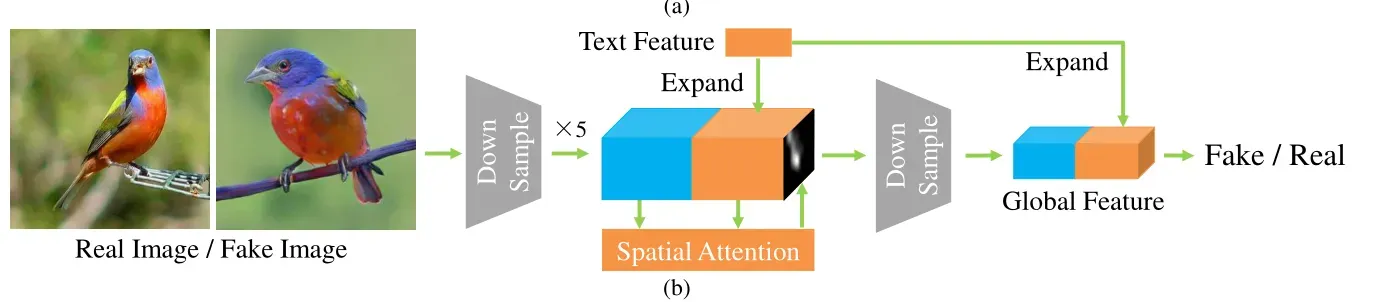
3.3.1 空间注意力
结合图像特征映射P和句子向量S中的信息,空间注意力生成一个注意力映射α,该注意映射α抑制无关区域的句子向量,公式如下:
其中,从上往下看,可以理解成在坐标(w,h)的图像特征,s是句子向量,将其共同输入到一个多层感知器MLP中,然后将计算出的
通过计算权重转换成注意概率
最后将α与句子向量再相乘,得到句子特征匹配图像特征的的权重。
3.3.2、软阈值函数
可以看到3.3.1的公式的α计算方式,在计算α时使用了软阈值函数方法:
作者并没有采用流行的softmax函数,因为它使最大概率最大化,并抑制其他概率接近0。极小的概率阻碍了梯度的反向传播,从而加剧了GAN训练的不稳定性。
软阈值函数可以防止注意概率接近零,并提高反向传播的效率。空间注意模型将更多的文本特征分配给相关的图像区域,这有助于鉴别器确定文本-图像对是否匹配。在对抗性训练中,更强的鉴别器迫使生成器合成更多相关的图像内容。
3.4、损失函数
鉴别器的训练目标将合成图像和不匹配图像作为负样本,在实文本对和匹配文本对上使用 hinge loss的MA-GP作为损失函数:
其中,s是给定的文本描述,是不匹配的文本描述,生成器的损失函数为:
四、实验
4.1、数据集
CUB、Oxford-102、MS-COCO
4.2、训练细节
文本编码器在训练时参数固定,优化器采用Adam,生成器学习率为0.0001,鉴别器学习率为0.0004。
在CUB和Oxford上,batchsize=24,epoch=600,单个RTX3090ti训练3天。
在COCO上,batchsize=48,epoch=300,使用两个RTX3090ti训练了两周。
4.3、实验结果
4.3.1、实验效果

在同一文本下生成的不同图像:

4.3.2、定量分析
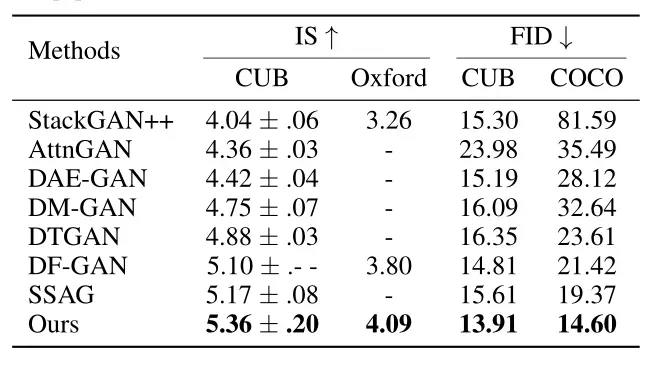
4.3.3、消融实验
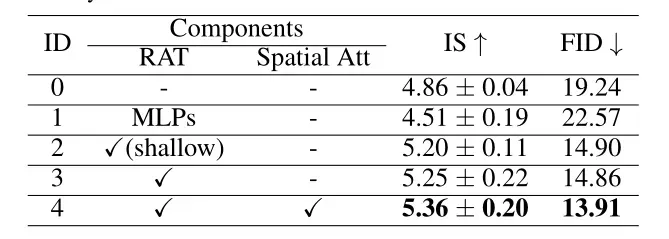
五、总结
RAT-GAN的创新点如下:
- 提出了一种递归仿射变换,将所有融合块连接起来,以便在合成过程中全局分配文本信息。
- 在鉴别器中加入空间注意,将注意力集中在相关的图像区域,因此生成的图像与文本描述更相关
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
文章出处登录后可见!