1、关联规则概述
关联规则(Association Rules)反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中 一个事物就能够通过其他事物预测到。
关联规则可以看作是一种IF-THEN关系。假设商品A被客户购买,那么在相同的交易ID下, 商品B也被客户挑选的机会就被发现了。

有没有发生过这样的事:你出去买东西,结果却买了比你计划的多得多的东西?这是一种被称为冲动购买的现象,大型零售商利用机器学习和Apriori算法,让我们倾向于购买更多的商品。

购物车分析是大型超市用来揭示商品之间关联的关键技术之一。他们试图找出不同物品和产品之间的关联,这些物品和产品可以一起销售,这有助于正确的产品放置。
买面包的人通常也买黄油。零售店的营销团队应该瞄准那些购买面包和黄油的顾客,向他们提供报价,以便他们购买第三种商品,比如鸡蛋。因此,如果顾客买了面包和黄油,看到鸡蛋有折扣或优惠,他们就会倾向于多花些钱买鸡蛋。这就是购物车分析的意义所在。

2、置信度、支持度、提升度的概念
- 置信度: 表示你购买了A商品后,你还会有多大的概率购买B商品。
- 支持度: 指某个商品组合出现的次数与总次数之间的比例,支持度越高表示该组合出现的几率越大。
- 提升度: 提升度代表商品A的出现,对商品B的出现概率提升了多少,即“商品 A 的出现,对商品 B 的出现概率提升的”程度。

提升度:(苹果的出现对啤酒出现的概率提升程度)

3、关联规则挖掘问题
关联规则挖掘问题:给定事务的集合T,关联规则发现是指找出支持度大于等于minsup并且置信度大于等于minconf的所有规则,minsup和minconf是对应的支持度和置信度阈值。
| 事务Id | 项集合 |
|---|---|
| 10 | A,B,C |
| 20 | A,C |
| 30 | A,D |
| 40 | B,E,F |
设置最小支持度50%,最小置信度50%
| 频繁模式 | 支持度 |
|---|---|
| {A} | 75% |
| {B} | 50% |
| {C} | 50% |
| {A,C} | 50% |
规则A=>C
其实我们感兴趣的就是买了A之后是否还会再买C
大多数关联规则挖掘算法通常采用的一种策略是将关联规则挖掘任务分解为如下两个主要的子任务:
- 频繁项产生:其目标是发现满足最小支持度阈值的所有项集,这些项集称作频繁项集。
- 规则的产生:其目标是从上一步发现的频繁项集中提取所有高置信度的规则,这些规则称作强规则。
挖掘关联规则的一种原始方法是:Brute-force approach:
- 计算每个可能规则的支持度和置信度。
这种方法计算代价太高,因为可以从数据集提取的规则的数量达到指数级。
4、Apriori算法
4.1 算法步骤
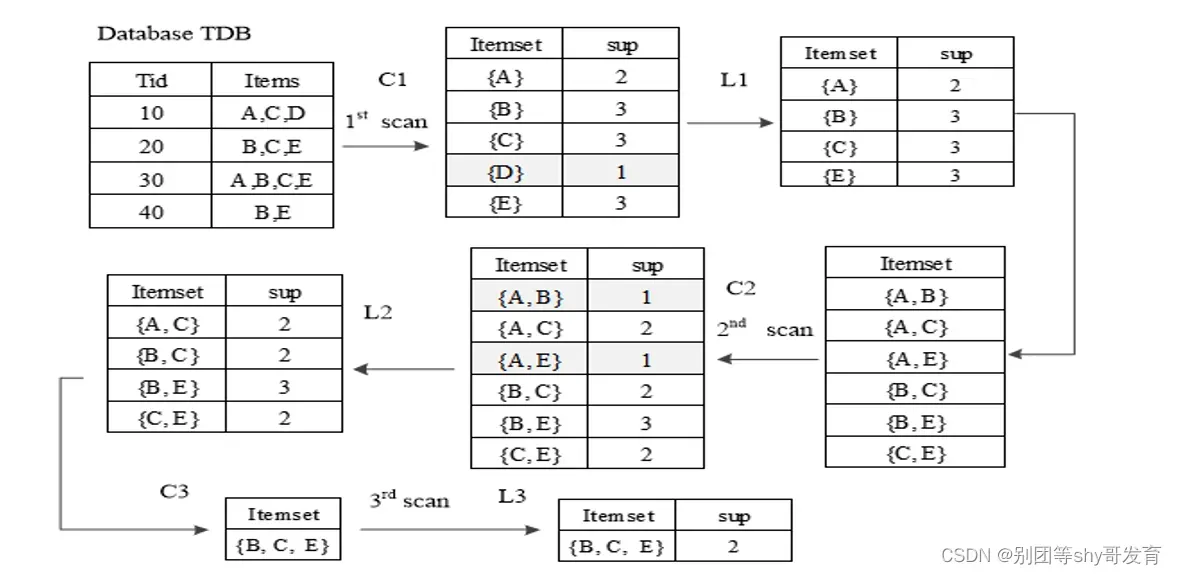
输入:数据集合D,支持度阈值𝛼
输出:最大的频繁k项集
- 1 扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
- 2 挖掘频繁k项集
(1) 扫描数据计算候选频繁k项集的支持度
(2) 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集
为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集
只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
(3) 基于频繁k项集,连接生成候选频繁k+1项集。
- 2 挖掘频繁k项集
- 3 令k=k+1,转入步骤2。
4.2 先验原理
- 如果一个项集是频繁的,则它的所有子集一定也是频繁的。
- 相反,如果一个项集是非频繁的,则它的所有超集也一定是非频繁的。
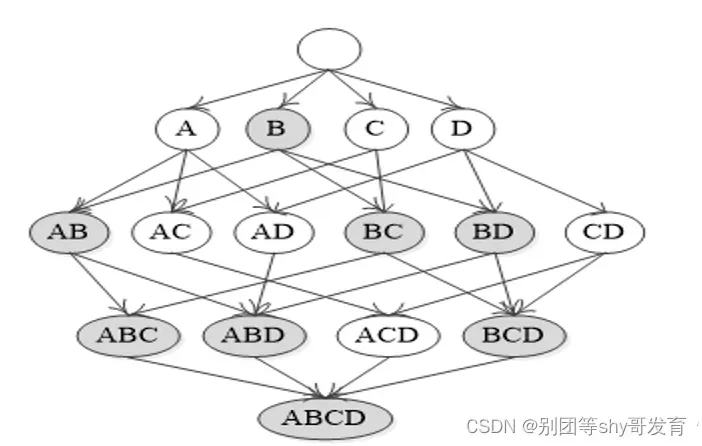
4.3 寻找最大频繁项的过程
尽管集合具有无序性,但是为了快速连接操作,通常对所有商品做一个默认的排序(类似于建立一个字典索引)
4.4 注意问题:项的连接
这里解释上图频繁2项集生成的候选3项集
项的连接准则的优点是降低候选项的生成。
对于任何2个需要连接的项集,

对于任何2个需要连接的项集,

5、代码实战
数据集文件:
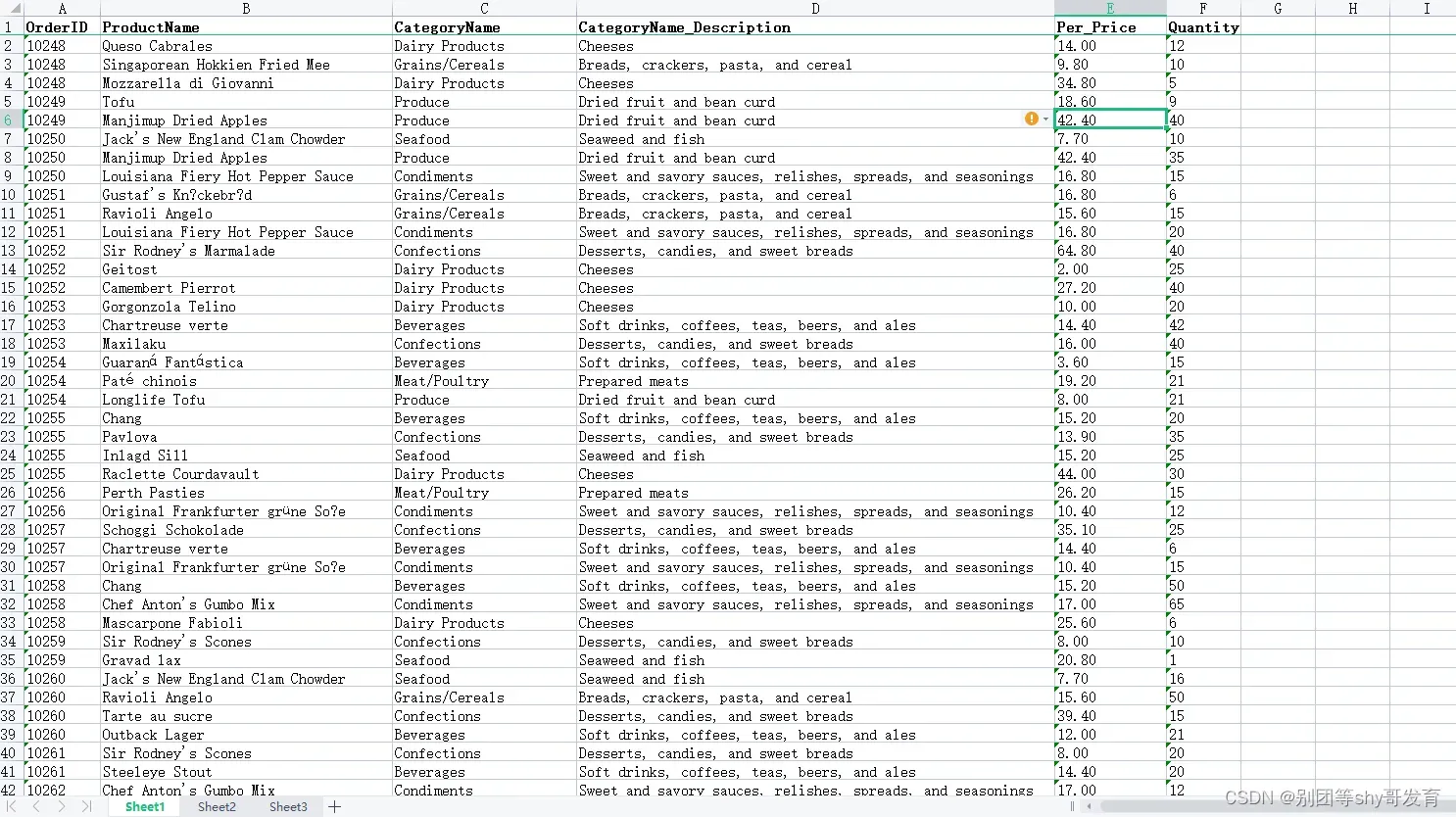
import pandas as pd
from apyori import apriori
df = pd.read_excel("data.xls")
df.head()
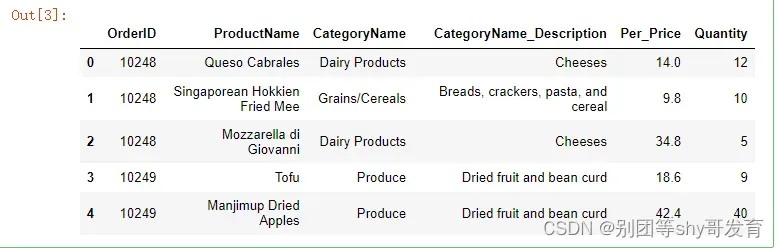
获取项集
transactions = df.groupby(by='OrderID').apply(lambda x: list(x.CategoryName))
transactions.head(6)

进行关联规则挖掘
min_supp = 0.1
min_conf = 0.1
min_lift = 0.1
result = list(apriori(transactions=transactions, min_support=min_supp,
min_confidence=min_conf, min_lift=min_lift))
result
返回结果result中的属性说明如下:
- items:项集,frozenset对象,可迭代取出子集。
- support:支持度,float类型。
- confidence:置信度或可信度,float类型。
- ordered_statistics:存在的关联规则,可迭代,迭代后其元素的属性如下:
(1)items_base:关联规则中的分母项集。
(2)confidence:上面的分母规则所对应的关联规则的可信度。
显示挖掘的关联规则
supports=[]
confidences=[]
lifts=[]
bases=[]
adds=[]
for r in result:
for x in r.ordered_statistics:
supports.append(r.support)
confidences.append(x.confidence)
lifts.append(x.lift)
bases.append(list(x.items_base))
adds.append(list(x.items_add))
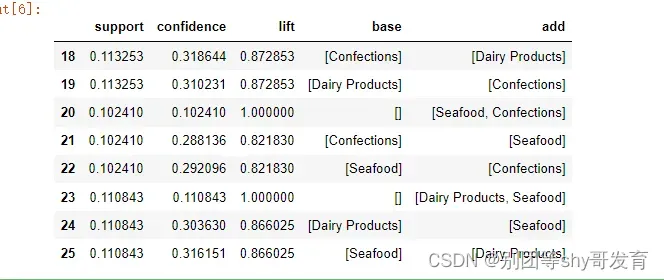
resultshow = pd.DataFrame({
'support':supports,
'confidence':confidences,
'lift':lifts,
'base':bases,
'add':adds})
resultshow.tail(8)
文章出处登录后可见!