逻辑回归(logistic regression)属于机器学习中的监督算法.
虽然名字中带有“回归”二字,但却干着分类的活~这主要是由于sigmod和softmax函数的特点,可以将任意实数映射到(0,1)区间,这样我们就可以得到一个概率值,根据概率的大小,再结合定下的阈值,就可以进行分类。
具体的理论就不多说啦,这里主要介绍Python中的sklearn如何实现二分类逻辑回归。来,话不多说,上代码~
一、导入各种包
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris # 导入鸢尾花数据集
from sklearn.model_selection import train_test_split # 导入数据划分函数
from sklearn.linear_model import LogisticRegression # 导入逻辑回归
# 导入评价指标
from sklearn.metrics import accuracy_score
二、数据处理(鸢尾花的label原本是3类,这里为了展示二分类,我只取了鸢尾花的前100个数据,也就是label只有0和1)
iris = load_iris()
iris_X = iris.data[:100, ] # x有4个属性,共有100个样本
iris_X

iris_y = iris.target[:100, ] # y的取值有2个,分别是0,1
iris_y
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.3) # 划分训练/测试集
print(X_train.shape)
print(X_test.shape)![]()
三、训练模型
model = LogisticRegression() # 选逻辑回归作为分类器
model.fit(X_train, y_train) # 训练模型
四、评估模型
y_test_pred = model.predict(X=X_test) # 预测测试集的label
print(y_test_pred) # 模型预测的测试集label
print(y_test) # 测试集实际label 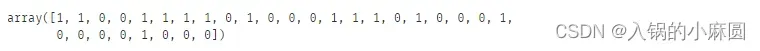
![]()
对比测试集本来的label和我们用模型预测的测试集label,不能说非常相似,只能说一模一样hhhhh,emmm可能是数据集太简单了,哦不对是算法很强大。。。
好,继续,接下来查看准确率accuracy_score,也就是所有数据被预测正确的百分比,毫无疑问accuracy_score=1,但是流程还是要走完的,还是看一下吧
accuracy_score(y_test, y_test_pred) # 查看模型预测的准确率 ![]()
接下来看具体的预测概率值,啥意思呢,就是现在结果只展示了样本被分到0或者是1类的结果,但是按照逻辑回归算法的原理,其实是预测得到的是一个概率值,然后根据阈值的大小(一般设为0.5),来划分类别,sklearn也封装了这个功能,查看概率值
pred = model.predict_proba(X_test) # 查看测试集样本对应的概率值
pred
这里我只截取了部分概率值,我们这里有30个测试样本,也就会有60个概率值,因为每个样本又会有俩概率,属于类别0的概率和属于类别1的概率,结果展示了两列数据,第一列是每个样本属于类别0的概率,第二列是每个样本属于1的概率,横着看的话俩概率相加是为1的。可以对着上面预测的类别结果去看,测试集第一个样本属于1的概率0.9983,大于0.0016,所以认为它类别为1,这个我们上面预测测试集的结果是一样的。
最后就是可以查看每个属性的权重,也就是系数,还有我们的常数项
print(model.coef_) # 查看变量参数
print(model.intercept_) # 查看常数参数项![]()
我们有四个属性,对应4个系数,还有一个常数项。
可以根据这个去自己写方程,然后用sigmod函数转化一下就会输出概率值了
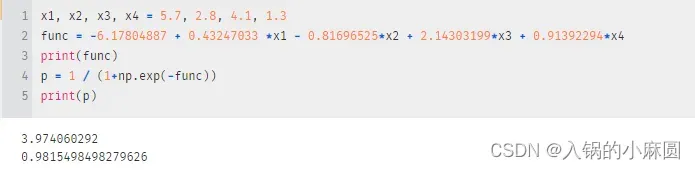
x1,x2,x3,x4是你想要测试的四个属性值,带到func里去,会得到y=3.9740,再把y用sigmod函数映射一下,得概率值p=0.9815
ok~感恩的心!
文章出处登录后可见!